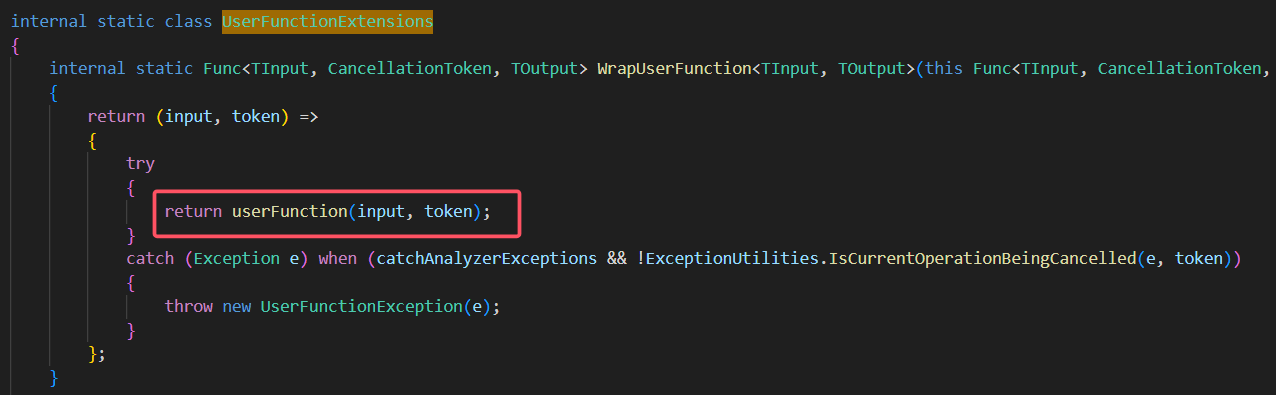
一、概述
NL2SQL(Natural Language to SQL)是一种将自然语言转换为结构化查询语言的技术。它可以帮助用户通过使用自然语言来与数据库进行交互,而无需了解复杂的SQL语法。
NL2SQL技术的背景:
随着人工智能的发展,越来越多的人开始尝试使用自然语言处理技术来解决实际问题。其中,NL2SQL就是一种非常重要的应用领域。它的目标是让用户能够通过简单的自然语言指令来访问和操作数据库中的数据,从而提高工作效率和用户体验。
NL2SQL技术的难点:
实现NL2SQL需要解决许多挑战性的问题。首先,自然语言具有高度的灵活性和多样性,因此需要设计出能够准确理解用户意图并将其转化为相应SQL语句的算法。其次,在处理复杂查询时,还需要考虑如何正确地解析和组合多个条件或操作符。最后,由于不同类型的数据库可能有不同的语法和功能,所以还需要针对特定场景进行定制化的开发工作。
NL2SQL技术的意义:
NL2SQL对于提升人机交互体验有着重要意义。它可以降低用户学习成本,使得更多非技术人员也能方便快捷地利用大数据资源。同时,它也为未来更加智能化的信息检索系统提供了基础支持。
二、整体结构
- 用户任务提示(User task prompt):用户提出一个需求,例如“合并报表、分析生产经营情况……”。
- 智能体(LLM Agents - ChatGLM LLAMA):这个部分是处理用户输入并生成代码的模型。它接收用户的自然语言指令,并将其转化为数据库表的操作命令。
- 表定义(table definitions):在执行操作之前,系统需要理解数据库表的结构和内容。这一步可能涉及到对数据库表的描述或示例数据。
- 代码写入代理(code write Agent):根据ChatGLM LLAMA生成的代码,编写具体的SQL语句来实现用户的需求。
- 迭代优化:通过不断调整和改进代码,以提高其准确性和效率。
- 代码执行代理(code excute Agent):执行编写的SQL语句,从数据库中获取所需的数据。
- 输出结果(Output):最后,将查询到的结果呈现给用户。

本文将基于前述篇章构建的数据多智能体协作平台,进一步优化NL2SQL在数据平台的应用。
1、优化点一:设置多个Agents切换
2、上传文件之后,可生成相关的数据分析建议

三、代码实践
(一)表结构解析
定义一个获取数据库表结构的描述性信息的SQLiteDB类
# SQLiteDB类
class SQLiteDB:
def __init__(self, db_file=None):
self.conn = None
self.cursor = None
if db_file:
self.connect_with_db_file(db_file)
def __enter__(self):
return self
def __exit__(self, exc_type, exc_val, exc_tb):
if self.conn:
self.conn.close()
def connect_with_db_file(self, db_file):
self.conn = sqlite3.connect(db_file)
self.cursor = self.conn.cursor()
def connect_with_url(self, url):
raise NotImplementedError("SQLite does not support connection via URL")
def upsert(self, table_name, _dict):
columns = ', '.join(_dict.keys())
placeholder = ', '.join('?' * len(_dict))
sql = f"INSERT OR REPLACE INTO {table_name} ({columns}) VALUES ({placeholder})"
self.cursor.execute(sql, list(_dict.values()))
self.conn.commit()
def delete(self, table_name, _id):
sql = f'DELETE FROM {table_name} WHERE id = ?'
self.cursor.execute(sql, (_id,))
self.conn.commit()
def get(self, table_name, _id):
sql = f'SELECT * FROM {table_name} WHERE id =?'
self.cursor.execute(sql, (_id,))
return self.cursor.fetchone()
def get_all(self, table_name):
try:
sql = f'SELECT * FROM {table_name}'
return self.cursor.execute(sql).fetchall()
except sqlite3.OperationalError as e:
print(f"An error occurred: {e}")
return None
def run_sql(self, sql):
print('\n\n----- Entered into the run_sql --------\n\n')
return self.cursor.execute(sql).fetchall()
def get_table_definitions(self, table_name):
cursor = self.conn.cursor()
cursor.execute(f"PRAGMA table_info({table_name})")
columns = cursor.fetchall()
column_definitions = [f"{col[1]} {col[2]}" for col in columns]
return f"Table '{table_name}' has columns: {', '.join(column_definitions)}"
def get_all_table_names(self):
self.cursor.execute("SELECT name FROM sqlite_master WHERE type= 'table'")
return [row[0] for row in self.cursor.fetchall()]
def get_table_definitions_for_prompt(self):
table_names = self.get_all_table_names()
table_definitions = []
for table_name in table_names:
definition = self.get_table_definitions(table_name)
table_definitions.append(definition)
return '\n'.join(table_definitions)
上传多个csv文件,获取csv文件的基本信息
def get_csv_info(directory):
# 创建一个空字典来存储所有CSV文件的信息
csv_info_dict = {}
# 遍历指定的目录
for filename in os.listdir(directory):
if filename.endswith('.csv'):
# 构造完整的文件路径
filepath = os.path.join(directory, filename)
try:
# 使用pandas读取CSV文件
df = pd.read_csv(filepath)
# 获取基础描述信息
info = {
'filename': filename,
'shape': df.shape, # 行数和列数
'columns': list(df.columns), # 列名
'info': df.info(verbose=False) # DataFrame的基本信息
}
# 添加到总的字典中
csv_info_dict[filename] = info
except Exception as e:
print(f"Error processing {filename}: {e}")
return csv_info_dict```
(二)设计一个agents用于生成上传数据文件的信息解析及数据分析建议
```python
#获取上传文件表基本信息及分析概要
def get_table_info(llm , table_info):
messages = [
(
"system",
"You are a helpful assistant that summarize the content into a summary of 200 words."+table_info),
("human", "Summarize and analyze the information of the uploaded file and output analysis suggestions."),
]
ai_msg = llm.invoke(messages)
return ai_msg.content
嵌入到【数据多智能体协作平台】内:用户上传数据文件之后,系统将自动生成数据文件的描述性信息,数据分析建议及预期输出
#########################################
#生成一个【分析建议生成按钮】
if data_info_button:
# 在检测到文件已上传后的地方添加如下逻辑
table_info = "请上传相关文件,获取文件基础信息"
llm = ChatOpenAI(openai_api_base=base_url, openai_api_key=api_key, model=selected_model)
if selected_agent == "SQL DB 分析" and uploaded_files:
for uploaded_file in uploaded_files:
file_path = save_uploaded_file(uploaded_file, selected_agent)
with SQLiteDB() as db:
db.connect_with_db_file(file_path)
table_definitions = db.get_table_definitions_for_prompt()
# 获取文件的基本信息并分析
table_info = get_table_info(llm, str(table_definitions))
elif selected_agent == "CSV 数据分析" and uploaded_files:
for uploaded_file in uploaded_files:
file_path = save_uploaded_file(uploaded_file, selected_agent)
directory_path = os.path.dirname(file_path)
table_definitions = get_csv_info(directory_path)
table_info = get_table_info(llm, str(table_definitions))
# 将描述信息输出到对话窗口
with st.chat_message("assistant", avatar="🤖"):
message_placeholder = st.empty()
with st.spinner("AI助手正在生成文件描述..."):
message_placeholder.markdown(f'<div style="background-color: #F5F5F5; padding: 10px; border-radius: 5px;">{table_info}</div>', unsafe_allow_html=True)
st.session_state.messages.append({"role": "assistant", "content": table_info, "avatar": "🤖"})
#message_placeholder.empty()
数据文件描述性信息及生成的数据分析建议:

(四)数据分析Agents设计
核心原理是:将获取到的数据文件的描述信息与用户任务结合在一起,送给数据分析Agents处理,本文采用AutoGen进行code 的编写和执行。
# 添加cap_ref
def add_cap_ref(prompt: str, prompt_suffix, cap_ref, cap_ref_content):
new_prompt = f"""{prompt} {prompt_suffix} \n\n {cap_ref} \n\n {cap_ref_content}"""
return new_prompt
SQLITE_TABLE_DEFINITIONS_CAP_REF = 'TABLE_DEFINITIONS'
SQLITE_SQL_QUERY_CAP_REF = 'SQL_QUERY'
TABLE_FORMAT_CAP_REF = 'TABLE_RESPONSE_FORMAT'
SQL_DELIMETER = 'SQLite'
def write_file(content, file_name):
file_path = os.path.join(OUTPUT_FOLDER, file_name)
with open(file_path, 'w') as f:
f.write(content)
def sql_data_analy(file_path, user_messages,OUTPUT_FOLDER):
with SQLiteDB() as db:
db.connect_with_db_file(file_path)
table_definitions = db.get_table_definitions_for_prompt()
user_messages = "The data file to be analyzed is located at:" + file_path + '\n' + user_messages
print("----------" +'\n' + table_definitions + "----------" +'\n')
prompt = add_cap_ref(user_messages, f"USE these {SQLITE_TABLE_DEFINITIONS_CAP_REF} to satisfy the database query", SQLITE_TABLE_DEFINITIONS_CAP_REF, table_definitions)
executor = LocalCommandLineCodeExecutor(
timeout=10, # 每次代码执行的超时时间,单位为秒
work_dir=OUTPUT_FOLDER, # 设置工作目录为输出文件夹
)
config_deepseek = {"config_list": [{"model": "deepseek-coder", "base_url": "https://api.deepseek.com", "api_key": "sk-12026c2831be49929da5ed7bda71ebfa"}], "cache_seed": None}
# 创建一个配置了代码执行器的代理
code_executor_agent = ConversableAgent(
"code_executor_agent",
llm_config=False, # 关闭此代理的LLM功能
code_execution_config={"executor": executor}, # 使用本地命令行代码执行器
human_input_mode="NEVER", # 此代理始终需要人类输入,以确保安全
is_termination_msg=lambda msg: "TERMINATE" in msg["content"].lower()
)
# 代码编写代理的系统消息是指导LLM如何使用代码执行代理中的代码执行器
code_writer_system_message = """You are a helpful AI assistant.
Solve tasks using your coding and language skills.
In the following cases, suggest python code (in a python coding block) or shell script (in a sh coding block) for the user to execute.
1. When you need to collect info, use the code to output the info you need, for example, browse or search the web, download/read a file, print the content of a webpage or a file, get the current date/time, check the operating system. After sufficient info is printed and the task is ready to be solved based on your language skill, you can solve the task by yourself.
2. When you need to perform some task with code, use the code to perform the task and output the result. Finish the task smartly.
Solve the task step by step if you need to. If a plan is not provided, explain your plan first. Be clear which step uses code, and which step uses your language skill.
When using code, you must indicate the script type in the code block. The user cannot provide any other feedback or perform any other action beyond executing the code you suggest. The user can't modify your code. So do not suggest incomplete code which requires users to modify. Don't use a code block if it's not intended to be executed by the user.
If you want the user to save the code in a file before executing it, put # filename: <filename> inside the code block as the first line. Don't include multiple code blocks in one response. Do not ask users to copy and paste the result. Instead, use 'print' function for the output when relevant. Check the execution result returned by the user.
If the result indicates there is an error, fix the error and output the code again. Suggest the full code instead of partial code or code changes. If the error can't be fixed or if the task is not solved even after the code is executed successfully, analyze the problem, revisit your assumption, collect additional info you need, and think of a different approach to try.
When you find an answer, verify the answer carefully. Include verifiable evidence in your response if possible.
Reply 'TERMINATE' in the end when everything is done.\n
""" + "The user's task is:\n" + prompt
# 创建一个名为code_writer_agent的代码编写代理,配置系统消息并关闭代码执行功能
code_writer_agent = ConversableAgent(
"code_writer_agent",
system_message=code_writer_system_message,
llm_config=config_deepseek, # 使用GPT-4模型
code_execution_config=False, # 关闭此代理的代码执行功能
is_termination_msg=lambda msg: "TERMINATE" in msg["content"].lower()
)
# 创建数据分析的prompt模板
prompt_hub = """
You are a professional data analyst. When users ask questions related to data,
your task is to understand their needs and write accurate Python code or SQL statements to address these queries.
After ensuring that the code or queries are syntactically correct,
you will be responsible for executing these scripts and presenting the final query results or execution outcomes.
The final summary output should include an introduction to the task and its solution method, the complete code output, and instructions on how to view the results.
If a data dashboard needs to be generated, please use the Streamlit framework, which means creating a py file that includes an executable main function.
Please ensure that your solutions consider both performance and readability.
Data Dashboard Design Tips:
If you use pyechart to create a data dashboard, you can use JsCode to inject custom CSS and HTML structures.
However, in reality, pyecharts' repr_html method does not directly generate the structure in an HTML file.
Therefore, CSS styles and HTML structures need to be manually added to the generated HTML file or implemented through other means.
You can consider dynamically inserting the generated chart option JSON data into a custom HTML template, or using front-end frameworks like React or Vue to more flexibly control the layout and styles.
Reply 'TERMINATE' in the end when everything is done.\n
"""
# 执行
chat_result = code_executor_agent.initiate_chat(
# name="Admin",
code_writer_agent,
message=prompt_hub,
is_termination_msg=lambda msg: "TERMINATE" in msg["content"].lower(),
summary_method="last_msg",
max_turns=3,
)
return chat_result.summary
结果:
-
任务一、抽取广东省、福建省、山东省商品猪生猪市场数据(Weekly price ofcommercialpigs),使用Ploty生成一个数据看板(生成一个htm文件)括:上述三个省的商品猪周度均值、月度均值、季度均值趋势图,三省价格差值分析趋势图等。

生成的数据看板:

-
任务二:抽取广东省生猪仔猪、育肥猪、母猪价格数据,计算月度价格、季度价格、年度价格均值,绘制一个数据看板,包含周度价格、月度价格、季度价格、年度价格均值数据趋势,相关数据报表等。

数据看板结果:

四、讨论
1、自然语言到SQL(NL2SQL)转换技术是简化数据库操作的关键环节,它降低了业务人员进行数据分析的技术门槛,使得不具备专业数据库知识的用户也能高效地进行数据查询。
2、当前,大型预训练模型在代码生成方面的能力正在迅速增强。随着这些模型技术的成熟,NL2SQL有望成为日常数据分析中的重要工具,显著降低数据查询、采集、整理、分析以及展示的难度。
3、随着预训练大模型在任务理解、任务分解与代码生成等方面能力的不断提升,建立以这些模型为中心的多智能体协作系统,以应对复杂任务的需求,变得越来越可行。未来的研究重点将是促进多智能体间的有效协作,并建立合理的协作机制。例如,可以设计一个多智能体投票机制,其中每个智能体不仅参与任务执行,还能对其他智能体的工作进行评估,从而选出执行特定子任务的最佳智能体。