📢 大家好,我是 【战神刘玉栋】,有10多年的研发经验,致力于前后端技术栈的知识沉淀和传播。 💗
🌻 CSDN入驻不久,希望大家多多支持,后续会继续提升文章质量,绝不滥竽充数,欢迎多多交流。👍
文章目录
- 集合(Set)

集合(Set)
【简介】
Redis 中的 Set 类型是一种无序集合,集合中的元素唯一,也就是集合中的元素是无重复的,有点类似于 Java 中的 HashSet 。
【应用场景】
1、需要随机获取数据源中的元素的场景
● 举例 :抽奖系统、随机。
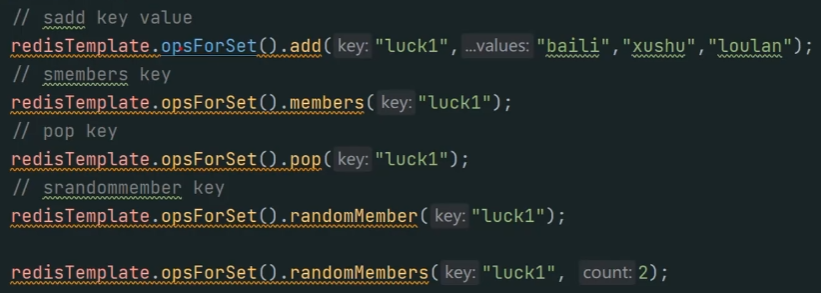
● 相关命令:SADD(加入抽奖系统)、SMEMBERS(查看所有抽奖用户)、SPOP(随机获取集合中的元素并移除,适合不允许重复中奖的场景)、SRANDMEMBER(随机获取集合中的元素,适合允许重复中奖的场景)。
2、需要存放的数据不能重复的场景
● 举例:文章点赞、动态点赞等场景。
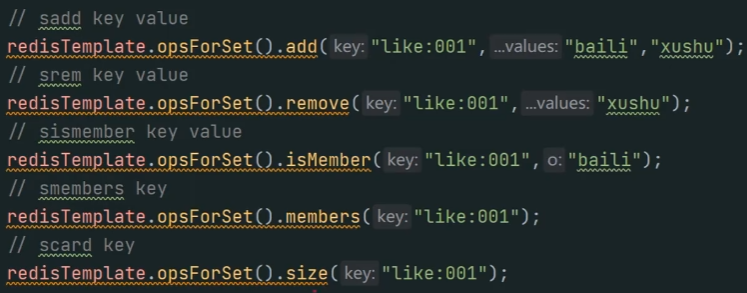
● 相关命令:SADD(点赞)、SREM(移除点赞)、SISMEMBER(检查用户是否点赞过)、SMEMBERS(获取点赞用户列表)、SCARD(获取点赞用户数量)
Tips:理论上,HashSet 适合的存储场景,这边也适合了。
【应用场景补充】
Redis Set 集合是一种无序且不重复的元素集合,适用于多种应用场景。
1、去重存储:使用 Set 存储唯一的用户 ID、邮箱地址等,确保没有重复数据。
2、标签系统:为用户、文章等对象存储标签,方便快速检索和去重。
3、社交网络:存储用户的好友列表、关注者、粉丝等,确保每个用户的关系是唯一的。
4、推荐系统:存储用户的历史行为、偏好等,便于进行个性化推荐。
5、实时统计:统计在线用户、活跃用户等,使用 Set 可以快速判断用户是否在线或活跃。
6、权限管理:存储用户的角色或权限,确保每个角色或权限是唯一的。
7、交集、并集、差集操作:Redis 提供了对 Set 的集合运算支持,可以方便地进行交集、并集和差集操作。
总之,Redis Set 集合在处理唯一性和集合操作方面非常高效,适用于多种场景。在使用时,需注意内存使用、数据持久化和操作性能等问题,以确保系统的稳定性和高效性。
@Component
public class RedisExample implements CommandLineRunner {
@Autowired
private UserService userService;
@Autowired
private TagService tagService;
@Autowired
private SetOperationsService setOperationsService;
@Override
public void run(String... args) throws Exception {
// 去重存储
userService.addUserId("user1");
userService.addUserId("user2");
userService.addUserId("user1"); // 重复的 ID 不会被添加
System.out.println("去重存储的用户 ID: " + userService.getUserIds());
// 标签系统
tagService.addTag("python");
tagService.addTag("coding");
tagService.addTag("python"); // 重复的标签不会被添加
System.out.println("标签系统中的标签: " + tagService.getTags());
// 集合操作示例
redisTemplate.opsForSet().add("setA", "1", "2", "3");
redisTemplate.opsForSet().add("setB", "3", "4", "5");
System.out.println("交集: " + setOperationsService.getIntersection("setA", "setB"));
System.out.println("并集: " + setOperationsService.getUnion("setA", "setB"));
System.out.println("差集: " + setOperationsService.getDifference("setA", "setB"));
}
}
@Service
public class UserService {
@Autowired
private RedisTemplate<String, String> redisTemplate;
public void addUserId(String userId) {
redisTemplate.opsForSet().add("user_ids", userId);
}
public Set<String> getUserIds() {
return redisTemplate.opsForSet().members("user_ids");
}
}
@Service
public class TagService {
@Autowired
private RedisTemplate<String, String> redisTemplate;
public void addTag(String tag) {
redisTemplate.opsForSet().add("tags", tag);
}
public Set<String> getTags() {
return redisTemplate.opsForSet().members("tags");
}
}
@Service
public class SetOperationsService {
@Autowired
private RedisTemplate<String, String> redisTemplate;
public Set<String> getIntersection(String setKey1, String setKey2) {
return redisTemplate.opsForSet().intersect(setKey1, setKey2);
}
public Set<String> getUnion(String setKey1, String setKey2) {
return redisTemplate.opsForSet().union(setKey1, setKey2);
}
public Set<String> getDifference(String setKey1, String setKey2) {
return redisTemplate.opsForSet().difference(setKey1, setKey2);
}
}
【注意事项】
- 数据类型: Set 集合只能存储字符串类型的元素,如果需要存储其他类型的数据,需要进行序列化和反序列化。
- 元素数量: Set 集合的元素数量有限制,具体取决于 Redis 实例的配置。
- 性能: Set 集合的添加、删除、判断元素是否存在等操作的性能都非常高,但如果元素数量非常多,可能会影响性能。
- 数据持久化: Set 集合的数据默认存储在内存中,如果需要持久化数据,需要配置 Redis 的持久化机制。
- 并发访问: Set 集合支持并发访问,但需要考虑并发访问带来的数据一致性问题。
【基础操作】
SADD key member1 [ member2 ]:向集合添加一个或者多个成员
SMEBERS key:返回集合中的所有成员
SISMEMBER key member:判断menber元素是否是集合key的成员
SPOP key:移除并返回集合中的一个随机元素
SREM key member1 [ member2 ]:移除集合中一个或者多个成员
● SADD key member1 [ member2 ]:向集合添加一个或者多个成员
● SCARD key:获取集合的成员数
● SMEBERS key:返回集合中的所有成员
● SPOP key:移除并返回集合中的一个随机元素(用户抽奖只能参加一轮)
● SRANDMEMBER key [ count ]:返回集合中一个或者多个随机数(用户抽奖可以参加多轮)
● SREM key member1 [ member2 ]:移除集合中一个或者多个成员
---------------------------------------------------分隔线---------------------------------------------------
● SUNION key1 [ key2 ]:返回所有给定集合的并集
● SINTER key1 [ key2 ]:返回所有给定集合的交集
● SDIFF key1 [ key2 ]:返回给定所有集合的差集
● SUNIONSTORE destination key1 [ key2 ]:所有给定集合的并集存储在destination集合中
● SDIFFSTORE destination key1 [ key2 ]:返回给定所有集合的差集并存储在destination中
● SINTERSTORE destination key1 [ key2 ]:返回给定所有集合的交集并存储在destination中
● SISMEMBER key member:判断menber元素是否是集合key的成员
● SMOVE source destination menber:将member元素从source集合移动到destination集合
● SSCAN key cursor [ MATCH pattem ] [ COUNT count ]:迭代集合中的元素
【代码实战】
命令和代码方法,大部分都是去掉首字母,比如set的sadd,就是add。
当然少部分换了单词。
=== 抽奖:
=== 点赞:
【扩展:实战文章点赞】
前言,下方位图结构也说适合点赞,那么哪个更适合呢?
这里补充一点,使用Set处理,还可以不一定用户ID一定是Long类型。
Tips:哈哈,这么一看,新增加的三个高级数据结构,貌似使用场景相当少。
对于文章点赞功能,使用 Redis 的 Set 结构更适合。
=== Set 结构的优势:
去重: Set 结构天生具有去重功能,可以确保每个用户只点赞一次。
高效查询: 可以使用 SISMEMBER 命令快速判断用户是否点赞过。
高效添加和删除: 可以使用 SADD 和 SREM 命令高效地添加和删除点赞记录。
获取点赞总数: 可以使用 SCARD 命令获取点赞总数。
=== 位图结构的优势:
节省空间: 位图结构可以高效地存储大量布尔值,节省存储空间。
高效统计: 可以使用 BITCOUNT 命令快速统计点赞总数。
=== 为什么 Set 结构更适合:
点赞功能更关注用户是否点赞,而不是点赞总数: Set 结构更适合存储用户点赞状态,而位图结构更适合统计点赞总数。
Set 结构更灵活: 可以使用 Set 结构存储其他信息,例如点赞时间、点赞类型等。
Set 结构更易于扩展: 可以使用 Set 结构实现更复杂的点赞功能,例如取消点赞、点赞排行榜等。
=== 总结:
对于文章点赞功能,使用 Redis 的 Set 结构更适合,因为它更灵活、更易于扩展,并且可以满足点赞功能的基本需求。
@Service
public class ArticleLikeService {
private static final String ARTICLE_LIKES_PREFIX = "article:likes:";
@Autowired
private RedisTemplate<String, String> redisTemplate;
// 点赞
public void likeArticle(String articleId, String userId) {
String key = ARTICLE_LIKES_PREFIX + articleId;
redisTemplate.opsForSet().add(key, userId);
}
// 取消点赞
public void unlikeArticle(String articleId, String userId) {
String key = ARTICLE_LIKES_PREFIX + articleId;
redisTemplate.opsForSet().remove(key, userId);
}
// 获取点赞用户列表
public Set<String> getLikes(String articleId) {
String key = ARTICLE_LIKES_PREFIX + articleId;
return redisTemplate.opsForSet().members(key);
}
// 获取点赞总数
public Long getLikeCount(String articleId) {
String key = ARTICLE_LIKES_PREFIX + articleId;
return redisTemplate.opsForSet().size(key);
}
}
【扩展:点赞想记录点赞时间】
Gpt给了两个方案,第一种还是用Set,但是存储的是Map。
@Service
public class ArticleLikeService {
private final RedisTemplate<String, Object> redisTemplate;
public ArticleLikeService(RedisTemplate<String, Object> redisTemplate) {
this.redisTemplate = redisTemplate;
}
// 添加点赞
public void addLike(Long articleId, String userId) {
String key = "article:likes:" + articleId;
Map<String, Object> likeData = new HashMap<>();
likeData.put("userId", userId);
likeData.put("timestamp", Instant.now().toEpochMilli());
redisTemplate.opsForSet().add(key, likeData);
}
// 取消点赞
public void removeLike(Long articleId, String userId) {
String key = "article:likes:" + articleId;
redisTemplate.opsForSet().remove(key, userId);
}
// 判断用户是否点赞
public boolean isLiked(Long articleId, String userId) {
String key = "article:likes:" + articleId;
return redisTemplate.opsForSet().isMember(key, userId);
}
// 获取点赞总数
public Long getLikeCount(Long articleId) {
String key = "article:likes:" + articleId;
return redisTemplate.opsForSet().size(key);
}
// 获取点赞时间
public Long getLikeTimestamp(Long articleId, String userId) {
String key = "article:likes:" + articleId;
Map<String, Object> likeData = (Map<String, Object>) redisTemplate.opsForSet().member(key, userId);
if (likeData != null) {
return (Long) likeData.get("timestamp");
}
return null;
}
}
继续追问:redisTemplate.opsForSet()的值可以直接存储Map对象吗?是会自动转换吗?那是根据什么判断重复,hashCode吗?
你问的很好!RedisTemplate 的 opsForSet() 方法确实可以存储 Map 对象,但它不会自动进行转换。
Redis 的 Set 数据结构只能存储字符串类型的元素。,因此,如果你直接将 Map 对象放入 opsForSet() 方法,Redis 会将它序列化成字符串,然后存储。
判断重复的依据是字符串的比较。 Redis 会使用字符串比较来判断两个元素是否重复,而不是使用 hashCode。
解决方法:
1、手动序列化和反序列化: 你需要在存储 Map 对象之前将其序列化成字符串,并在读取时将其反序列化回 Map 对象。可以使用 Jackson 或 Gson 等序列化库来完成这个过程。
2、使用 opsForHash() 方法: 如果需要存储 Map 对象,建议使用 opsForHash() 方法,它可以存储键值对,并支持直接存储 Map 对象。
总结一下,这种情况还是直接使用Hash处理好了,当然,也可以使用 ZSet 来存储点赞记录,并使用点赞时间作为分数,这样可以方便地获取点赞时间排序的列表。