本文作者:YashanDB高级服务工程师周国超
YashanDB共享集群是崖⼭数据库系统(YashanDB)的⼀个关键特性,它是⼀个单库多实例的多活数据库系统。⽤⼾可以连接到任意实例访问同⼀个数据库,多个数据库实例能够并发读写同⼀份数据,同时保证实例之间读写的强⼀致性。这种设计赋予了系统⾼可⽤性、⾼扩展性和⾼性能的特点。
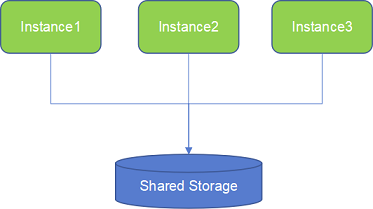
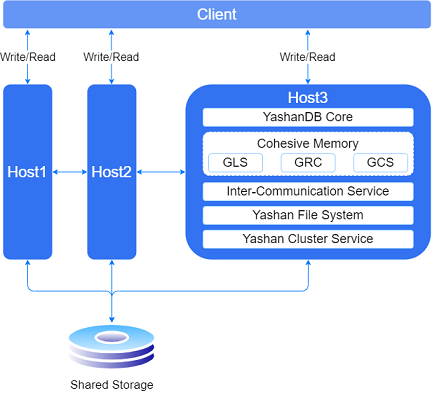
共享集群基于YashanDB内核持续演进,硬件上依赖共享存储实现shared-Disk的架构,同时引⼊了Cohesive Memory核⼼技术实现Shared-Cache能⼒。这使得集群数据库多个实例之间能够协同数据⻚的读写访问以及各种⾮数据类资源的并发控制。
共享集群的核⼼组件主要包括崖⼭集群内核(YCK,Yashan Cluster Kernel)、崖⼭集群服务(YCS,Yashan Cluster Service)和崖⼭⽂件系统(YFS,Yashan File System)。崖⼭集群内核通过聚合内存技术,聚合多实例对数据资源和⾮数据资源的并发访问。崖⼭集群服务负责管理共享集群数据库,包括集群服务器配置管理、资源配置管理、启停、监控服务器以及资源,并在故障时负责投票仲裁并重组集群。崖⼭⽂件系统是YashanDB的专⽤并⾏⽂件系统,提供存储设备管理、存储⾼可⽤、⽂件系统接⼝等功能。
崖山数据库(YashanDB)共享集群的独特性主要体现如下⽅⾯:
核心技术突破:YashanDB共享集群攻克了共享集群的关键技术瓶颈,实现了⾦融级⾼可⽤能⼒,RPO为0、RTO<10秒。
高可用性:YashanDB共享集群具备天然的⾼可⽤优势,任何实例故障后都不影响应⽤的连续性,采⽤了快速恢复和连接连续性技术保证服务端的透明接管和客⼾端的透明切换。
性能优化:YashanDB共享集群在性能⽅⾯有显著优势,经实测,在同等硬件条件下,其TPC-C基准测试表现⽐Oracle RAC⾼30%。
多实例读写:YashanDB⾃研了“七种武器”技术,包括⻚内锁技术、免锁读技术、去中⼼化的事务管理机制等,以解决读写冲突,提⾼读写性能。
自适应异步并⾏调度:YashanDB提出了⾃适应的异步并⾏任务调度机制,⼤幅度降低了多核之间的事务冲突协调开销,提⾼了性能。
共享集群架构:YashanDB共享集群基于YashanDB内核持续演进,引⼊了Cohesive Memory核⼼技术,实现Shared-Cache能⼒,⽀持在线故障⾃动切换和故障⾃动恢复。
全自研共享集群解决⽅案:YashanDB全⾃研共享集群解决⽅案为⽤⼾提供应⽤透明的⾼可⽤和⾼性能数据库能⼒,构建了基于国产应⽤/中间件、共享集群数据库、芯⽚/服务器/存储的⾼端全栈⽅案。
专用并行文件系统:YashanDB⾃研集群⽂件系统,采⽤In memory FAT + Direct access专利技术,实现文件系统元数据常驻内存,提供更⾼效的存储管理能⼒和效率。
原创理论与领先架构:YashanDB拥有世界领先的基础理论作为⽀撑,通过“原创理论+领先架构+⼯程能⼒”三位⼀体的⼯程研发体系,打造技术先进、性能稳定、持续创新的产品内核。
这些独特性使得YashanDB共享集群在数据库国产化替代的浪潮下,能够满⾜⾦融、电信等⾏业核⼼系统对关键技术的需求,推动核⼼系统国产化替换的规模化应⽤。
相对于Oracle数据库共享集群的关键技术总结如下:
1.Oracle RAC (Real Application Clusters):Oracle RAC是Oracle数据库中的⼀项核⼼技术,它允
许多个服务器节点共享访问相同的数据库⽂件,从⽽实现⾼可⽤性和负载均衡。
2. 缓存融合 (Cache Fusion):这是Oracle RAC的⼀个关键组件,它通过在节点之间共享缓存数据来
减少磁盘I/O,提⾼数据库性能。
3. 全局资源管理器 (Global Resource Manager, GRM):GRM负责管理集群中的资源,包括锁定和资
源的分配。
4. 投票磁盘 (Voting Disks):在Oracle RAC中,投票磁盘⽤于存储集群的配置信息和状态,帮助在节
点故障时进⾏决策。
5. Oracle Clusterware:这是Oracle RAC运⾏所依赖的中间件,负责集群的管理和协调。
6. 服务和实例:Oracle RAC可以配置多个服务和实例,它们可以在不同的节点上运⾏,以提供⾼可⽤
性和故障转移。
7. 存储系统:共享存储是Oracle RAC的基础,它允许多个节点访问相同的数据⽂件。
8. 网络:高速网络连接是Oracle RAC正常运⾏的关键,它⽀持节点之间的通信和数据共享。
Oracle RAC技术通过这些关键技术实现了数据库的⾼可⽤性、可扩展性和性能优化,使其成为企业级核⼼交易数据库领域的⼴泛应⽤解决⽅案。
共享集群技术最核⼼的难点在于实例间的交互,如何保证多个实例间数据的强⼀致性?如何协调数据之间发⽣的冲突?如何处理⽹络通信的各种异常情况?这对架构设计的挑战⾮常⼤,需要⼀整套协调机制来实现。
YashanDB共享集群中所有数据库实例共享缓存,本地访问⻚⾯时若未命中,可通过⽹络从其他实例拿到最新版本⻚⾯,实现数据交换,应⽤可以连接任意节点访问和使⽤数据库完整能⼒。为解决读写冲突,提⾼读写性能。
我们来初步探索下YashanDB⾃研了“武器”技术。
页内锁技术
在崖⼭数据库系统(YashanDB)中,⻚内锁技术是⼀种⽤于实现并发控制的技术。它通过在数据⻚级别上设置锁来控制对数据的访问和操作,以确保数据的⼀致性和并发性。当⼀个事务需要访问或修改某个数据⻚时,系统会根据事务的需求和当前数据⻚的锁状态来决定是否可以进⾏操作。这种技术可以有效地避免数据的冲突和混乱,保证事务的正确执⾏和数据的完整性。
在崖⼭数据库系统(YashanDB)中,可以通过以下步骤验证⻚内锁技术的有效性:
- 创建多个事务并访问同⼀个数据⻚:可以创建多个并发的事务,让它们同时访问同⼀个数据⻚,尝试进⾏读取或写⼊操作。
- 观察锁的状态:通过数据库系统的监控⼯具或查询系统视图,观察数据⻚上的锁状态,包括锁的类型、持有者、等待者等信息。
- 测试并发控制:在不同事务之间制造数据冲突,例如⼀个事务尝试修改数据⻚上的数据,⽽另⼀个事务同时也在尝试修改相同数据⻚的数据,观察系统如何处理并发访问。
- 检查事务的隔离级别:验证⻚内锁技术是否按照事务的隔离级别正确地处理并发访问,确保事务之间的数据操作不会相互⼲扰。
通过以上步骤可以验证⻚内锁技术在崖⼭数据库系统中的有效性,确保数据的⼀致性和并发控制机制的正确性。
通过以上步骤可以验证⻚内锁技术在崖⼭数据库系统中的有效性,确保数据的⼀致性和并发控制机制的正确性。
去中心化的事务管理机制
崖⼭数据库(YashanDB)采⽤了去中⼼化的事务管理机制,这是其共享集群技术的核⼼特点之⼀。这种机制避免了传统中⼼化事务管理可能带来的性能瓶颈和扩展性问题。在YashanDB共享集群中,所有数据库实例共享缓存,并且通过去中⼼化的事务管理,实现了多个实例间数据的强⼀致性,同时协调数据之间发⽣的冲突和处理⽹络通信的各种异常情况。
利⽤去中⼼化的事务管理机制,可以实现在分布式环境下对事务进⾏管理和控制,确保数据的⼀致性和可靠性。在YashanDB中,可以通过配置实例亲和性和分布式事务处理能⼒来实现去中⼼化的事务管理机制。具体步骤包括:
- 配置实例亲和性:根据业务需求和数据分布情况,设置数据表或数据⽂件在特定实例上的存储和处理,以确保相关数据在特定实例上进⾏操作。
- 分布式事务处理:利⽤YashanDB原⽣的分布式处理系统,⽀持分布式事务的提交、回滚和并发控制,保证跨多个节点的事务操作的⼀致性和隔离性。
- 实现事务ACID特性:通过YashanDB的事务管理功能,⽀持完整事务ACID特性,包括细粒度锁管理、语句读写⼀致性、UNDO⾃管理和多版本并发控制,确保事务的正确执⾏和数据的⼀致性。
- 配置⾼可⽤和备份策略:利⽤YashanDB提供的⾼可⽤能⼒,配置⼀主多备、级联备等⾼可⽤架构,保证系统的可⽤性和数据的安全性。
通过以上步骤,可以充分利⽤YashanDB的去中⼼化事务管理机制,实现分布式环境下的⾼效、可靠的事务处理。
此外,YashanDB还采⽤了基于时间戳的多版本并发控制(MVCC)机制,以及实例间通过Lamport消息⽅式实现时间戳同步,确保跨实例的数据交换不会影响事务的可⻅性。这些技术的结合,使得YashanDB能够在保持数据⼀致性的同时,提⾼系统的并发处理能⼒和整体性能。
实例亲和性的空间分配机制
崖⼭数据库(YashanDB)的实例亲和性的空间分配机制是其共享集群技术的⼀部分,旨在提⾼数据库的性能和效率。具体来说,这种机制允许实例间对同⼀张表并⾏导⼊数据时避免空间争⽤,从⽽优化了资源的分配和使⽤。
实例亲和性的空间分配机制是指在数据库系统中,可以通过设置实例亲和性来指定某个表或数据⽂件在特定实例上进⾏分配和存储。这种机制可以确保特定的数据在特定的实例上进⾏处理,提⾼数据访问的效率和性能。
在YashanDB中,配置实例亲和性的空间分配机制需要在建库时根据数据量、并发数、应⽤场景等因素来确定。对于不同⽤途的表空间,应根据数据库性能和每种类型的表空间的关联性来进⾏配置。在创建数据库时,应为所有内置表空间配置合理的初始⼤⼩,以满⾜实际需求。
对于临时类型表空间,建议初始⼤⼩不要配置过⼤,可以打开⾃动扩展功能,除⾮应⽤系统有明确的临时表需求。在YashanDB中,临时表的存储空间采⽤预占⽅式,只有在BUFFER不⾜需要换出时才会被使⽤,并且在数据库重启后会被重置。因此,⽤⼾可以根据需要通过RESIZE或ADD DATAFILE的⽅式增加临时表空间的容量,或者通过SHRINK来释放过剩的空间。
在初始化配置参数时,需要根据应⽤需求和环境资源,为性能参数赋予合适的初始值。⼀些重要的配置参数包括VM_BUFFER_SIZE、REDOFILE_IO_MODE、REDO_BUFFER_SIZE、REDO_BUFFER_PARTS等,这些参数的合理配置对数据库性能⾄关重要。在⾼可⽤的⾃动选举配置中,需要预先规划好参数以便⽇后扩展,确保Raft集群架构能够正常运⾏并实现⾃动选举。
在YashanDB中,可以通过设置实例亲和性来控制数据的分布和存储,以满⾜不同业务需求和性能要求。实例亲和性的空间分配机制可以通过物理属性和表空间设置来实现,确保数据在分布式部署环境中的合理分配和管理。
基于负载缓存⾃动调度策略
基于负载缓存⾃动调度策略是YashanDB共享集群中的⼀项技术,旨在提⾼数据库集群整体的缓存命中率和性能。这种策略通过动态调整和优化缓存资源的使⽤,以适应不断变化的负载情况,从⽽实现更⾼效的数据访问和处理。
以下是该策略可能包含的⼏个关键⽅⾯:
- 动态资源分配:根据当前的数据库负载情况,⾃动调整各个实例的缓存⼤⼩和资源分配,以确保资源被有效地利⽤。
- 负载预测:通过分析历史数据和实时监控数据,预测未来的负载变化,从⽽提前做出资源调整。
- 缓存置换算法:采⽤⾼效的缓存置换算法,确保最常访问的数据被保留在缓存中,减少对磁盘的访问次数。
- 并发控制:在多实例环境中,协调不同实例的缓存访问,避免缓存争⽤和冲突,提⾼并发处理能⼒。
- 数据局部性优化:通过优化数据存储和访问模式,增强数据的局部性,使得相关数据更可能被⼀起加载到缓存中。
- 故障恢复:在发⽣故障时,快速恢复缓存状态,确保系统的连续性和稳定性。
- 监控与调优:实时监控缓存的性能指标,根据监控结果动态调整调度策略,以适应不断变化的运⾏环境。
YashanDB通过实施基于负载的缓存⾃动调度策略,可以显著提⾼数据库系统的响应速度和吞吐量,同时降低延迟和系统资源的消耗。这对于需要处理⼤规模数据和⾼并发请求的企业级应⽤尤为重要。
脏页快传技术
脏⻚快传技术是YashanDB共享集群中⽤于提⾼性能的关键技术之⼀。这项技术主要针对在数据库操作过程中产⽣的脏⻚(即已修改但尚未持久化到磁盘的数据⻚)进⾏优化,以减少因脏⻚写回磁盘造成的延迟。
在传统的数据库系统中,脏⻚需要周期性地被刷新回磁盘以确保数据的持久性,这个过程称为Checkpointing。如果脏⻚数量较多,或者系统负载较⾼,这个过程可能会引⼊显著的延迟,影响数据库的性能。
YashanDB的脏⻚快传技术通过以下⽅式来提⾼效率:
1.遵从WAL协议:在确保遵循预写⽇志(Write Ahead Logging,WAL)协议的前提下⼯作,这是数据库保证事务持久性的关键机制。
2. 减少磁盘I/O等待:通过优化算法减少脏⻚写回操作时对磁盘I/O的等待时间,从⽽降低整体的事务处理延迟。
3. 快速传递:脏⻚快传技术允许脏⻚在实例间快速传递,⽽不是等待全部修改完成再统⼀写回,这样可以更快地释放内存资源并减少锁的竞争。
4. 优化的刷盘策略:YashanDB可能采⽤了⼀些智能的刷盘策略,⽐如根据当前系统负载动态调整刷盘频率,或者优先处理最有可能影响性能的脏⻚。
5. 异步处理:脏⻚的写回操作可能是异步进⾏的,这样就不会阻塞主数据库操作流程,提⾼了数据库的并发处理能⼒。
脏⻚快传技术是YashanDB共享集群技术优势的⼀部分,它帮助YashanDB在保持数据⼀致性和持久性的同时,提⾼了数据库的性能和响应速度。
除此之外,为了提⾼数据库的性能,YashanDB⾃研集群⽂件系统,采⽤ In memory FAT(AllocationTable, ⽂件分区表) + Direct access 专利技术,该技术能实现⽂件系统元数据常驻内存,提供更⾼效的存储管理能⼒和效率。⽂件系统客⼾端程序通过直连共享内存访问 FAT 数据,确保 YashanDB 针对所有持久化⽂件(包括但不限于控制⽂件、数据⽂件以及redo⽂件)的 read/write 操作,不涉及等待磁盘 IO 或⽹络 IO,实现性能最优。
YashanDB共享集群的这些先进性和特殊性机制,使其成为⾼端核⼼交易场景的有⼒竞争者,为⽤⼾提供了⼀个⾼性能、⾼兼容、更开放的数据库解决⽅案。我们对此有更⾼的要求和期待,共享集群后续发展如何,我们拭⽬以待。