小波变换是一种先进的信号分析技术,它擅长捕捉信号的局部特征,但有时可能会忽略数据中的关键信息。为了克服这一局限,我们引入了注意力机制,这一机制能够强化模型对数据重要部分的关注。通过将小波变换与注意力机制相结合,我们能够更全面、更深入地挖掘数据特征,从而显著提升模型的性能和处理复杂数据的能力。
这种技术的融合不仅是技术上的突破,而且在实际应用中也为我们提供了新的解决方案和方法。例如,在滚动轴承故障分类领域,一种创新的方法通过结合一维改进的自注意力增强卷积神经网络和经验小波变换,实现了100%的分类准确率。这一成果不仅在学术界引起了广泛关注,也在工业界得到了实际应用,显示出在去噪、检测等任务中的巨大潜力。
为了帮助那些希望在这一领域发表论文的研究人员,我精心挑选了11篇最新的研究论文,这些论文探讨了小波变换与注意力机制的结合创新方案。这些论文的代码大多已经开源,便于大家复现实验并寻找新的灵感。
三篇论文详解
1、EDSNET: EFFICIENT-DSNET FOR VIDEO SUMMARIZATION
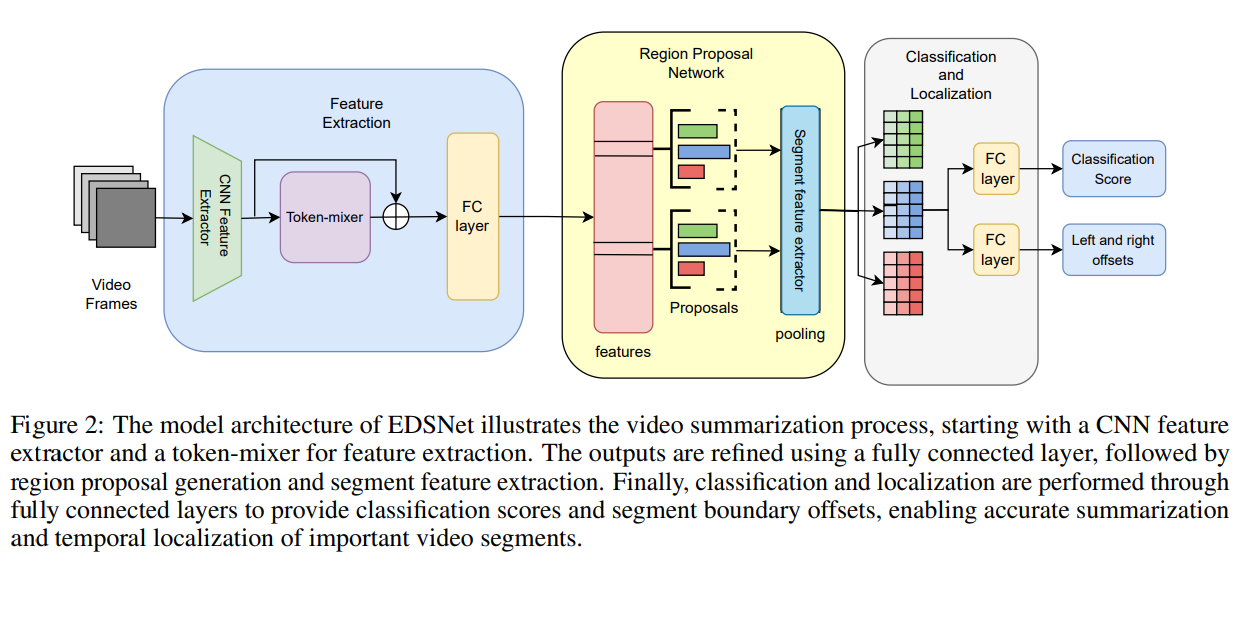
这篇文章介绍了一种名为EDSNet(Efficient-DSNet)的视频摘要方法,旨在通过改进直接总结网络(DSNet)来提高视频摘要任务的资源效率。视频摘要是一种从视频中提取关键信息的技术,对于管理信息过载、内容索引、增强搜索性等方面具有重要应用。现有的基于Transformer的视频摘要方法由于其二次复杂度,需要大量的计算资源,尤其是在处理长视频序列时。为了解决这一问题,文章提出了一种更高效的视频摘要方法。
研究方法:
文章中提出的方法主要包含以下几个关键步骤:
-
特征提取:使用GoogLeNet作为CNN特征提取器来提取视频帧的空间特征。
-
Token-mixing:文章提出了使用傅里叶变换、小波变换和Nyströmformer等替代传统的softmax自注意力机制,以降低计算复杂度。
-
区域提议网络(Region Proposal Network, RPN):在RPN中,文章探索了不同的池化策略,包括ROI池化、快速傅里叶变换池化和扁平池化。
-
分类和定位:使用全连接层对提议的视频片段进行二元分类,并通过回归来细化片段的选择和边界。
-
实验验证:在TVSum和SumMe数据集上进行实验,以验证所提出方法的有效性。
创新点:
文章的创新之处主要体现在以下几个方面:
-
高效的Token-mixing机制:通过使用傅里叶变换、小波变换和Nyströmformer等方法替代传统的自注意力机制,显著降低了计算复杂度,同时保持了摘要性能。
-
多样化的池化策略:文章探索了不同的池化策略,如ROI池化、FFT池化和扁平池化,以提取视频片段的特征,这些策略在不同的场景下表现出各自的优势。
-
全局和局部信息的结合:文章提出的方法模仿人类处理视频的方式,先通过高效的token-mixers理解全局上下文,然后通过时间区域提议网络识别关键片段。
-
资源效率和性能的平衡:实验结果表明,所提出的方法在显著降低计算成本的同时,保持了与现有技术相竞争的摘要性能。
-
实验验证:通过在TVSum和SumMe数据集上的实验,文章证明了其方法在资源效率和性能方面的优越性。
总结:
这篇文章通过引入高效的Token-mixing机制和多样化的池化策略,提出了一种资源效率高且性能良好的视频摘要方法。这种方法在处理大规模视频数据时,尤其是在资源受限的环境中,具有显著的优势。
2、Window-based Channel Attention for Wavelet-enhanced Learned Image Compression
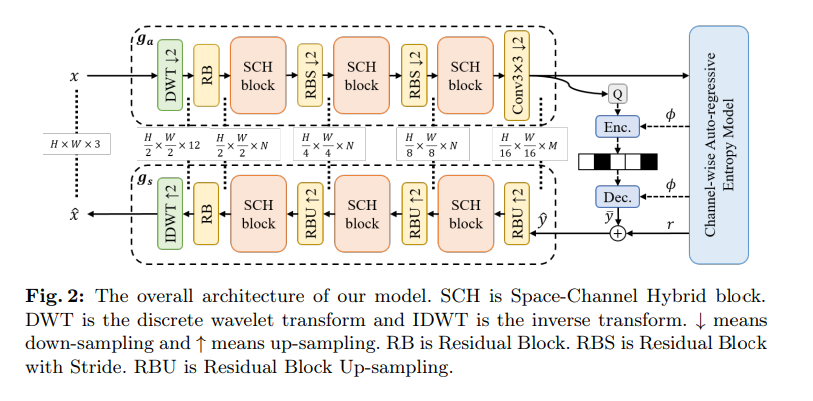
这篇文章提出了一种名为Space-Channel Hybrid(SCH)的新型框架,用于改进学习图像压缩(LIC)的性能。该框架结合了卷积神经网络(CNN)和Transformer的优势,通过引入窗口化的通道注意力机制和离散小波变换(DWT),有效地扩大了感受野,以捕获图像中的全局和局部信息。
研究方法:
文章中提出的方法包括以下几个关键步骤:
-
窗口化通道注意力(Window-based Channel Attention):首次将窗口分割融入通道注意力中,以获得更大的感受野并捕获更多全局信息。该机制通过计算不同窗口的不同通道注意力图来实现,从而学习更多样化的全局信息。
-
离散小波变换(DWT):将DWT集成到SCH框架中,通过在不同频率子图像上工作,实现高效的频率依赖下采样,并进一步扩大感受野。
-
空间-通道混合(SCH)框架:该框架包含用于局部信息学习的残差块和空间注意力模块,以及用于全局信息学习的通道注意力模块。
-
自回归熵模型:使用通道-wise自回归熵模型进行无损压缩的建模。
创新点:
文章的创新之处主要体现在以下几个方面:
-
窗口化通道注意力机制:通过在通道注意力中引入窗口分割,不仅扩大了感受野,还捕获了更多全局信息,这对于图像压缩尤其重要。
-
DWT的应用:通过引入Haar DWT,文章在不增加参数负担的情况下,有效地扩大了感受野,提高了频率相关特征的学习效率。
-
SCH框架:该框架有效地结合了CNN的局部特征学习能力和Transformer的全局特征学习能力,提高了图像压缩的性能。
-
实验结果:在多个标准数据集上进行的实验结果表明,提出的方法在压缩性能上达到了最先进的水平,与VTM-23.1相比,在四个标准数据集上降低了BD率18.54%至24.71%。
-
高效的压缩性能:文章提出的方法在保持较低的参数数量的同时,实现了与最新VTM-23.1相比的显著性能提升。
研究方法和创新点总结:
这篇文章的主要贡献在于提出了一种结合了CNN和Transformer优点的新型框架SCH,通过窗口化通道注意力机制和DWT,有效地扩大了模型的感受野,提高了学习图像压缩的性能。此外,该方法在保持计算效率的同时,实现了与现有技术相比的显著性能提升,这在图像压缩领域具有重要的应用价值。通过在不同分辨率的数据集上进行广泛的实验验证,文章证明了其方法的有效性和优越性。
3、Overcoming Data Limitations in Internet Traffic Forecasting: LSTM Models with Transfer Learning and Wavelet Augmentation
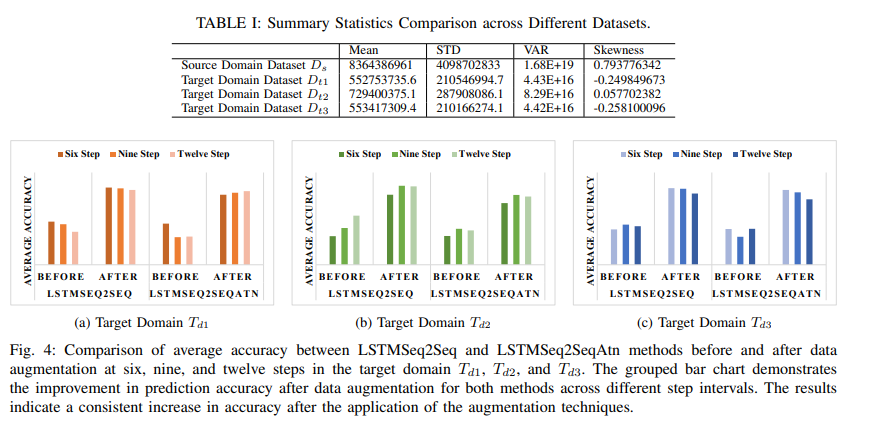
这篇文章提出了一种结合迁移学习和离散小波变换(DWT)增强的数据增强技术,用于解决小型ISP网络中互联网流量预测的数据限制问题。文章的主要贡献在于创新性地应用迁移学习来克服网络流量预测中的数据匮乏难题,并引入DWT数据增强技术来提升模型在数据有限情况下的性能。
研究方法:
文章中提出的方法包含以下几个关键步骤:
-
迁移学习:文章采用了迁移学习技术,将一个大且全面的数据集(源域)上预训练的LSTM模型迁移到数据量较小的目标域上。这种方法允许模型利用在数据丰富的环境中学到的知识,来提高数据有限环境中的预测性能。
-
数据增强:为了解决目标域数据不足的问题,文章引入了离散小波变换(DWT)作为数据增强手段,通过对原始数据进行变换和重构,生成新的数据样本,从而扩大了训练数据集。
-
LSTM模型:文章设计了两种基于LSTM的模型,分别是传统的序列到序列模型(LSTMSeq2Seq)和带有注意力机制的模型(LSTMSeq2SeqAtn),用于学习和预测时间序列数据。
-
模型训练与微调:在迁移学习的设置下,文章首先在源域上训练模型,然后在目标域上进行微调。在微调过程中,文章采用了不同的学习率策略,先冻结模型的大部分层,然后解冻所有层进行细粒度的调整。
创新点:
文章的创新之处主要体现在以下几个方面:
-
迁移学习的应用:文章创新性地将迁移学习应用于网络流量预测领域,特别是在数据较少的小型ISP网络中。
-
DWT数据增强技术的结合:文章提出将DWT用于数据增强,这在互联网流量预测的研究中较为新颖。
-
注意力机制的探索:文章在LSTM模型中引入了注意力机制,以期提高模型对时间序列数据中关键信息的捕捉能力。
文章的实验部分详细描述了数据集的准备、模型的训练过程、评估指标的选择以及实验结果。实验使用了来自Juniper Networks的真实互联网流量数据,包括一个源域数据集和三个目标域数据集。通过在这些数据集上应用迁移学习和DWT数据增强技术,文章验证了所提出方法的有效性。
实验结果:
实验结果显示,与没有使用数据增强的模型相比,经过DWT数据增强的模型在预测准确性上有了显著提升。此外,文章还对模型在不同预测步长下的性能进行了分析,发现所提出的模型在单步预测上表现良好,但在多步预测上存在挑战,尤其是在长期预测的准确性上。文章还探讨了模型在不同目标域中的性能变化,指出模型性能的差异反映了不同网络域的流量特性。
尽管文章提出了一些创新点,但在实验结果和实验验证方面,主要是验证了所提方法相对于现有技术的优势,并没有提出新的实验方法或验证技术。