unordered系列关联式容器,我们曾在C++_map_set详解一文中浅浅的提了几句。今天我们来详细谈谈
本身在C++11之前是没有unordered系列关联式容器的,unordered系列与普通的map、set的核心功能重叠度达到了90%,他们最大的不同就是底层结构的不同,map和set的底层使用的是红黑树;unordered底层是用的hash结构,两者在使用上基本上没有什么不同,map和set使用方法那一套在unordered系列容器同样试用,这里不再赘述。本篇文章主要讨论一些哈希相关知识。
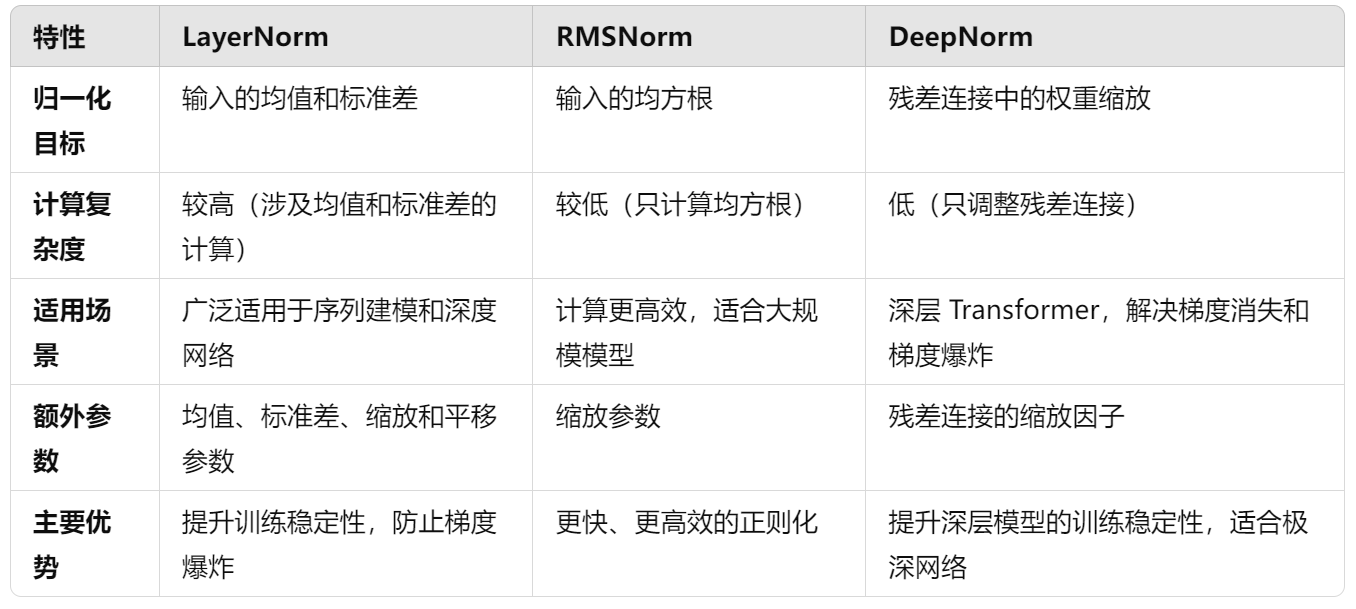
unordered系列与mapset的对比
| unordered系列 | map和set | |
| 对key的要求不同 | 支持key转成整形 + 比较相等 | 支持比较大小 |
| 遍历 | 遍历无序 | 遍历有序 |
| 迭代器 | 单向迭代器 | 双向迭代器 |
| 性能差异(插入删除等) | O(1) | O(logN) |
| 底层结构 | 哈希结构 | 红黑树 |
底层结构
哈希概念
在顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素时,必须要经过关键码的多次比较。所以顺序查找时间复杂度为O(N),平衡树中的时间复杂度为树的高度,即O(log N),搜索的效率取决于搜索过程中元素的比较次数。
在数组中,我们可以通过下标访问我们任何想访问的元素,即不经过任何比较,直接从表中得到要搜索的元素。如果构造出一种像数组一样的存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一一映射的关系,那么在查找时通过该函数可以很快找到该元素。
当向该结构中插入元素时:
根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放;
当在该结构中搜索元素时:
对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置取元素比较,若关键码相等,则搜索成功。
该方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表(Hash Table)(或者称散列表)。
上面啰啰嗦嗦一大堆概念,其实一个例子就可以搞定:

我们将元素的值映射到一个数组相应的位置,用该方法进行搜索不必进行多次关键码的比较,因此搜索的速度比较快。
哈希函数
常见的哈希函数
1. 直接定址法
取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B
优点:简单、快
缺点:只适合范围相对集中的一组元素
2. 除留余数法
key模上一个表的大小 N 以后,在映射到表中的一个位置,hash(key) = key % N (N是表的大小) <上例中使用的就是该方法>
我们再来思考一个问题:如果按照上述哈希方式,向集合中插入元素44,会出现什么问题?
如果插入44,即hash(44) = 44 % 10 = 4,与hash(4)映射到了相同的位置,也就是说一个位置映射了两个值,这种情况我们称为哈希冲突。
哈希冲突
对于两个数据元素的关键字 i 和 j ,有 i != j ,但有:Hash(i) == Hash(j),即:不同关键字通过相同哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。
哈希冲突的解决
解决哈希冲突两种常见的方法是:闭散列和开散列
闭散列
闭散列也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。就类似于大学上课,教室第一排的位置被占了,那我们可以选择第二排。现在的问题是如何找到下一个位置呢?
方法一:线性探测
从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
1. 通过哈希函数获取待插入元素在哈希表中的位置
2. 如果该位置中没有元素则直接插入新元素,如果该位置中有元素发生哈希冲突,使用线性探测找到下一个空位置,插入新元素
如上例中的插入元素44:

采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素会影响其他元素的搜索。比如删除元素4,如果直接删除掉,44查找起来可能会受影响,因为线性探测的查找规则是,从冲突位置开始向后查找,直到遇到空为止。如果直接把4删掉,4所在的位置就变为了空,查找44的时候,在还未找到44的情况下就直接停止查找了。因此线性探测采用标记的伪删除法来删除一个元素。
虽然线性探测可以解决哈希冲突,但是如果所有的冲突连在一起,容易产生数据“堆积”,即:不同关键码占据了可利用的空位置,使得寻找某关键码的位置需要许多次比较,导致搜索效率降低。如何缓解这种情况呢?我们看方法二
方法二:二次探测
如果说线性探测是 当前位置 +1,+2,+3.....的方式去探测;那么二次探测就是 当前位置 +1^2,+2^2,+3^2......的方式探测。也就是说二测探测是跳跃着进行探测的,该方法有效的解决了冲突连在一起,产生的数据“堆积”问题。
开散列
开散列法又叫哈希桶(拉链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。

从上图可以看出,开散列中每个桶中放的都是发生哈希冲突的元素。