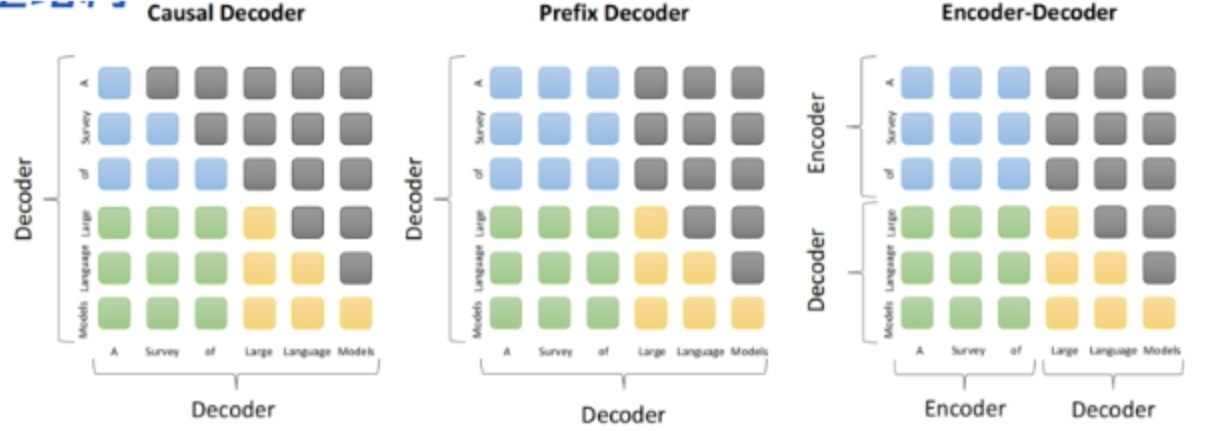
1 目前主流的开源模型体系有哪些?
Prefix Decoder 系列模型
核心点: 输入采用双向注意力机制,输出为单向注意力。双向注意力意味着输入的每个部分都可以关注到输入的所有其他部分,这在理解上下文时具有很强的优势。
代表模型:ChatGLM、ChatGLM2、U-PaLM
补充知识:Prefix Decoder 类的模型常用于对话生成任务,因为这种架构能够更好地捕捉输入的上下文信息,同时在输出时保留生成内容的顺序依赖性。ChatGLM 系列模型在中文对话生成任务中表现优异,特别是在对中文语义的理解和生成方面有较好表现。而 U-PaLM 则代表了一种基于 Google PaLM 的预训练模型优化版本,拥有强大的多任务、多语言处理能力。
Causal Decoder 系列模型
核心点: 输入和输出都采用从左到右的单向注意力机制。输入只能依赖于其之前的部分,输出也是逐步生成的。这种架构适合生成类任务,因为每一步的输出都依赖于前面的内容。
代表模型:LLama 系列模型
补充知识:Causal Decoder 是经典的自回归生成模型结构。LLaMA 模型通过减少参数规模,同时保持高质量的内容生成能力,成为了当前开源社区中非常受欢迎的轻量级大模型。自回归模型虽然计算开销较小,但由于只能逐步生成,对于长文本生成,速度可能会较慢。
Encoder-Decoder 系列模型
核心点: 输入使用双向注意力,输出则采用单向注意力。这种架构结合了双向注意力在理解输入上下文的优势和单向注意力在生成输出时的顺序依赖特性。
代表模型:T5、Flan-T5、BART
补充知识:Encoder-Decoder 结构在机器翻译、文本摘要、问答等任务中应用广泛。T5模型通过“Text-To-Text”框架,将几乎所有任务转化为文本生成问题,大大提升了其通用性和任务迁移能力。BART 则通过加入降噪自编码器的预训练方式,在生成过程中能够有效修复输入噪声,适合需要对输入进行修正的生成任务。
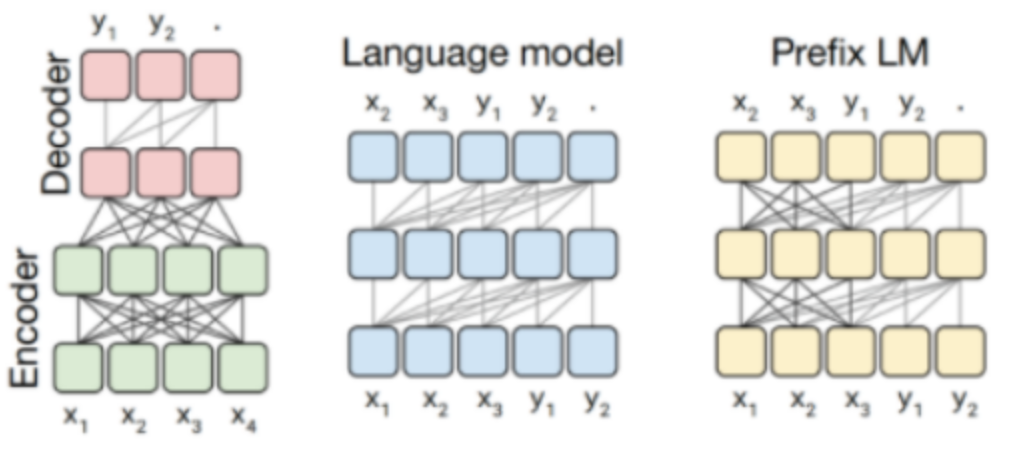
2 prefix Decoder 和 causal Decoder 和 Encoder-Decoder 区别是什么?
答:三者的主要区别在于 attention mask 不同。
- Encoder-Decoder
-
- 在输入上采用双向注意力,对输入的编码和理解更加充分
- 适用任务:在偏重文本理解的 NLP 任务上表现很好
- 缺点:在长文本生成任务上效果较差,且训练效率较低
- causal Decoder
-
- 自回归语言模型,预训练和下游应用是完全一致的,严格遵守只有后面的 token 才能看到前面的 token 的原则
- 适用任务:文本生成任务
- 缺点:训练效率高,zero-shot 能力强,具有涌现能力
- prefix Decoder
-
- prefix 部分的 token 能相互看到,属于是 causal Decoder 和 Encoder-Decoder 的折中方案
- 适用任务:机器翻译、文本摘要、问答
- 缺点:训练效率低。
3 大模型 LLM 的训练目标是什么?
- 最大似然函数
根据 已有词 预测下一个词,训练目标为最大似然函数:
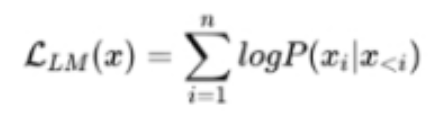
训练效率:Prefix Decoder < Causal Decoder
Causal Decoder 结构会在所有 token 上计算损失,而 Prefix Decoder 只会在 输出上计算损失。
- 去噪自编码器
随机替换掉一些文本段,训练语言模型去恢复被打乱的文本段。目标函数为:
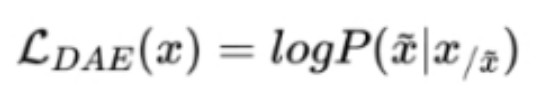
去噪自编码器的实现难度更高。采用去噪自编码器作为训练目标的任务有 GLM-130B、T5。
4 涌现能力是啥原因?
根据前人分析和论文总结,大致是2个猜想:
- 任务的评价指标不够平滑
- 复杂任务 vs 子任务。这个其实好理解,比如我们假设某个任务 T 有 5 个子任务 Sub-T 构成,每个 sub-T 随着模型增长,指标只是从 40% 提升到 60%(提升了 1.5 倍),但是最终任务的指标只从 1.1% 提升到了 7%(提升了了 7 倍),也就是说宏观上看到了涌现现象,但是子任务效果其实是平滑增长的。
5 为何现在的大模型大部分是 Decoder only 结构?
因为 decoder-only 结构模型在没有任何微调数据的情况下,zero-shot 的表现能力最好。而 encoder-decoder 则需要在一定量的标注数据上做 multitask-finetuning 才能够激发最佳性能。
目前的 LargeLM 的训练范式还是在大规模语料上做自监督学习,很显然 zero-shot 性能更好的 decoder-only 架构才能更好的利用这些无标注的数据。
大模型使用 decoder-only 架构除了训练效率和工程实现上的优势外,在理论上因为 Encoder 的双向注意力会存在低秩的问题,这可能会削弱模型的表达能力。就生成任务而言,引入双向注意力并无实质的好处。而 Encoder-decoder模型架构之所以能够在某些场景下表现更好,大概是因为它多了一倍参数。所以在同等参数量、同等推理成本下,Decoder-only 架构就是最优的选择了。
6 Encoder 的双向注意力低秩问题
在 Encoder 结构中,双向注意力(Bidirectional Attention)允许每个输入的词(token)同时关注序列中的所有其他词。这意味着每个位置的词都可以在全局上下文中编码,不仅依赖它之前的词,还可以考虑之后的词。这种机制特别适合于理解任务(如句子分类、信息抽取等),因为它可以捕获丰富的全局上下文信息。
低秩问题可以从数学角度来理解:对于一个给定的序列,双向注意力的目的是将每个词的位置用高维向量表示(隐状态表示)。然而,由于模型在处理序列中的所有词时,同时关注了所有其他词,这种全局的注意力机制可能导致每个词的隐状态表示与其他词变得过于相似。
具体来说,双向注意力在将所有词的信息融合到每个词的表示时,可能会引入冗余信息,即不同位置的词向量变得高度相关或依赖于彼此。这样,生成的词向量矩阵(表示整个序列的矩阵)可能具有较低的秩(rank)。换句话说,模型最终生成的词向量表示空间的维度较低,导致表达能力受限。
- 秩(Rank):在矩阵表示中,秩代表矩阵列或行的线性独立性。如果矩阵秩较低,意味着其列向量或行向量之间高度相关,无法有效表示复杂的数据结构。
- 低秩的影响:对于 Encoder 的双向注意力,这种低秩现象意味着模型虽然处理了大量的信息,但最终得到的表示可能过于“压缩”或“概括”,不同词的表征变得过于相似,无法捕获微妙的差异。这在生成任务中尤为不利,因为生成任务要求模型能够细致地区分各个位置的词,并为每个位置生成不同的下一个词。
在生成任务中,模型需要根据已有的序列预测下一个词。由于双向注意力允许模型同时看到所有位置的词,可能会导致生成的序列缺乏顺序性和层次性(因为每个位置的信息被过度平均化)。这种过度“依赖全局上下文”的机制对于生成任务是不必要的,甚至是有害的,因为生成任务需要明确的前后顺序,而不是所有位置都看到相同的全局信息。
- 自回归生成任务的需求:在生成任务中,模型必须以自回归的方式逐步生成序列,即每个位置的输出应该仅依赖前面的词,而不是全局的信息。Decoder-only 模型通过自回归注意力(只关注之前的词)保证了生成的顺序性和一致性。而双向注意力会干扰这种顺序性,导致生成的内容可能缺乏前后衔接性。
- 表达能力的局限:由于双向注意力容易导致词向量的低秩现象,生成任务中的序列表示可能过于冗余,不能充分表达序列的复杂性,从而降低生成质量。
双向注意力的低秩问题本质上是因为它过于依赖全局上下文,导致词向量表示中的冗余信息增加,秩降低,表达能力受到限制。这对于需要逐步生成的任务(如自然语言生成)是一个劣势,因为生成任务更依赖词与词之间的局部顺序和细致的上下文差异。因此,Decoder-only 模型在生成任务中的表现更好,它通过自回归机制避免了这种全局注意力带来的低秩问题。
7 简单 介绍一下 大模型【LLMs】?
大模型一般指1亿以上参数的模型,但是这个标准一直在升级,目前万亿参数以上的模型也有了。大语言模型(Large LanguageModel,LLM)是针对语言的大模型。
8 大模型【LLMs】后面跟的 175B、60B、540B等 指什么?
175B、60B、540B等:这些一般指参数的个数,B是Bilion/十亿的意思,175B 是1750 亿参数,这是 ChatGPT 大约的参数规模。
9 大模型【LLMs】具有什么优点?
- 可以利用大量的无标往数据来训练一个通用的模型,然后再用少量的有标注数据来微调模型,以适应特定的任务。这种预训练和微调的方法可以减少数据标注的成本和时间,提高模型的泛化能力;
- 可以利用生成式人工智能技术来产生新颖和有价值的内容,例如图像、文本、音乐等。这种生成能力可以帮助用户在创意、娱乐、教育等领域获得更好的体验和效果;
- 可以利用涌现能力(Emergent Capabilities)来完成一些之前无法完成或者很难完成的任务,例如数学应用题、常识推理、符号操作等。这种涌现能力可以反映模型的智能水平和推理能力。
10 大模型【LLMs】具有什么缺点?
- 需要消耗大量的计算资源和存储资源来训练和运行,这会增加经济和环境的负担。据估计,训练一个 GPT-3 模型需要消耗约 30 万美元,并产生约 284 吨二氧化碳排放;
- 需要面对数据质量和安全性的问题,例如数据偏见、数据泄露、数据滥用等。这些问题可能会导致模型产生不准确或不道德的输出,并影响用户或社会的利益;
- 需要考虑可解释性、可靠性、可持续性等方面的挑战,例如如何理解和控制模型的行为、如何保证模型的正确性和稳定性、如何平衡模型的效益和风险等。这些挑战需要多方面的研究和合作,以确保大模型能够健康地发展
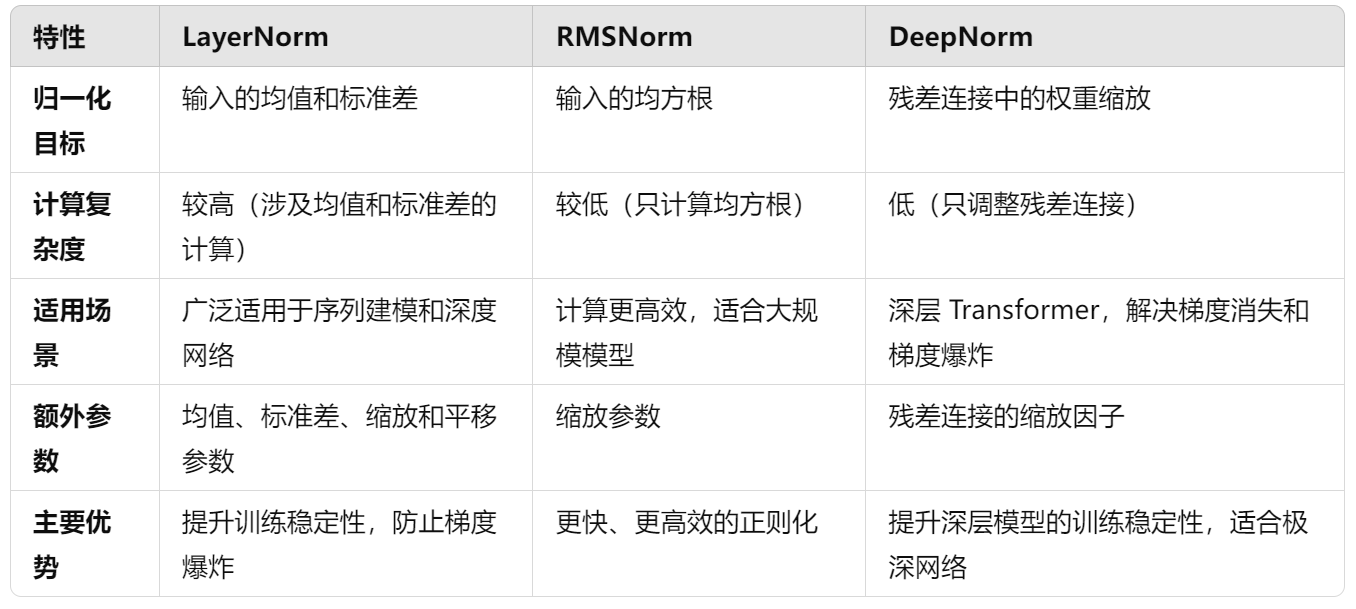
一、Layer normalization
Layer Norm 和 RMS Norm 是大型语言模型(LLM)中非常常见的归一化技术,用于加速训练过程、提高稳定性以及增强模型性能。这两种归一化方法本质上是对神经网络层的输出进行归一化处理,但它们的原理和应用略有不同。下面详细介绍二者,并对其进行对比分析。
二、Layer Norm 篇
2.1 概念
Layer Normalization(Layer Norm)由Ba等人于2016年提出,主要用于对神经网络每一层的输出进行归一化处理。它的目标是减小模型在不同层次上参数更新的方差,保持输出稳定,特别是在序列任务(如语言建模)中表现出色。
2.2 工作原理
Layer Norm 的基本思想是对每一个神经网络层的所有激活值进行归一化。具体地,它对每一层的所有特征进行均值和方差计算,然后利用这些统计量对层输出进行标准化。

2.3 Layer Norm 的计算公式写一下?


三、RMS Norm 篇 (均方根 Norm)
3.1 概念
RMS Normalization(RMS Norm)是一种简化的归一化技术,是对 Layer Norm 的一种改进,尤其适用于自回归语言模型,如 GPT 等。RMS Norm主要关注向量的二范数(Euclidean norm),而不是像Layer Norm那样对均值和方差进行归一化处理。
3.2 工作原理

3.3 RMS Norm 的计算公式写一下?
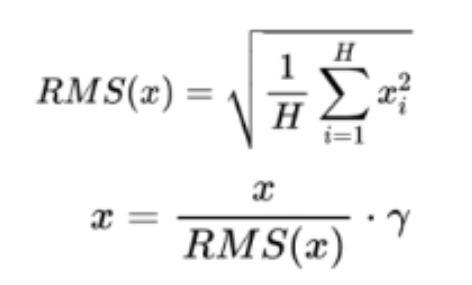

3.2 RMS Norm 相比于 Layer Norm 有什么特点?
RMS Norm 简化了 Layer Norm ,去除掉计算均值进行平移的部分。对比 Layer Norm,RMS Norm 的计算速度更快。效果基本相当,甚至略有提升。
- Layer Norm:
-
- 需要计算均值和方差,能够对每个特征进行更加精细的标准化,适合更复杂的上下文建模,特别适合双向模型(如 BERT)。
- 计算稍复杂,尤其在高维数据中开销较大。
- RMS Norm:
-
- 只需要计算均方根值,归一化方式更简单,尤其适合自回归生成任务(如GPT系列),在大规模模型中具备更高的计算效率。
- 由于省略了均值的平移,适合那些对输入均值变化不敏感的场景。
总体来说,Layer Norm 适用于需要精细控制特征间关系的任务,而 RMS Norm 则更加适合高效的生成任务。
四、Deep Norm 篇
4.1 Deep Norm 思路?
Deep Norm 方法在执行 Layer Norm 之前,up-scale 了残差连接(alpha>1);另外,在初始化阶段down-scale 了模型参数(beta<1)
4.2 写一下 Deep Norm 代码实现?
def deepnorm(x):
return LayerNorm(x * α + f(x))
def deepnorm_init(w):
if w is ['ffn', 'v_proj', 'out_proj']:
nn.init.xavier_normal_(w, gain=β)
elif w is ['q_proj', 'k_proj']:
nn.init.xavier_normal_(w, gain=1)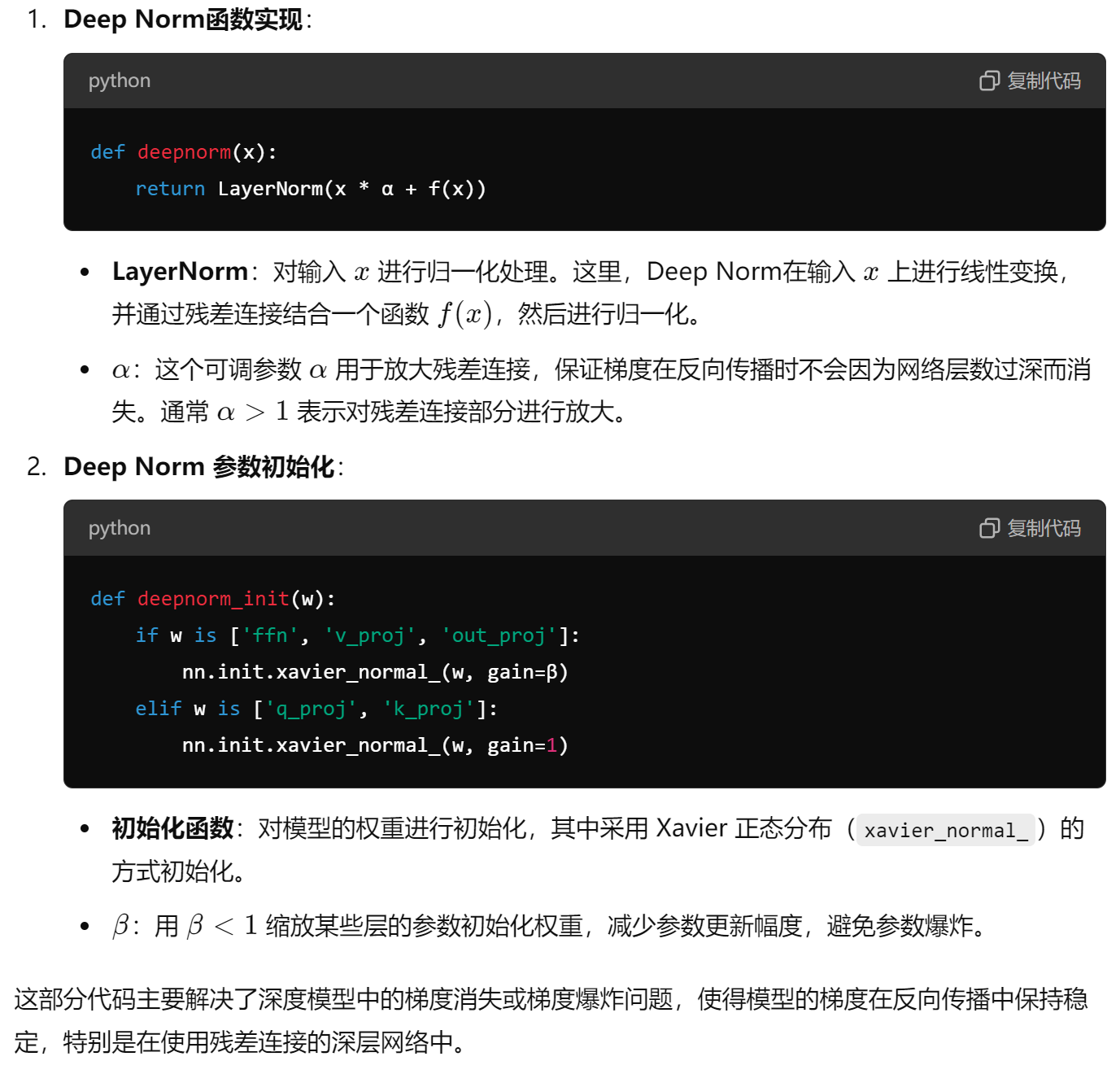
4.3 Deep Norm 有什么优点?
DeepNorm 是 Transformer 模型中的一种正则化方法,旨在解决深度 Transformer 网络中的训练不稳定问题,特别是在大规模和深层模型中。它的主要优点包括:
- 提高训练稳定性:在非常深的 Transformer 网络中,层数增加往往导致训练时梯度消失或梯度爆炸的问题。DeepNorm 通过对残差连接中的缩放因子进行调整,能够有效防止梯度异常,提升模型的训练稳定性。
- 加速收敛:DeepNorm 通过对每一层的缩放,使得更深的 Transformer 模型在训练初期能够更快收敛。相比标准的 Transformer,DeepNorm 能够在保持精度的同时减少训练所需的时间和计算资源。
- 支持更深层的模型架构:传统的 Transformer 在超过一定深度时,模型的性能往往不再提高甚至下降。而 DeepNorm 通过修改正则化策略,使得模型可以扩展到更多层,从而提升更大规模模型的表示能力。
- 提高模型性能:通过更有效的正则化,DeepNorm 帮助 Transformer 模型在处理大规模数据时获得更好的表现,尤其是在自然语言处理、图像生成等任务中,可以在保持训练稳定性的同时,提升模型性能和预测准确性。
总的来说,DeepNorm 通过改变残差连接中的缩放策略,帮助 Transformer 模型缓解模型参数爆炸式更新的问题,把模型更新限制在常数级,使得模型训练过程更稳定,同时提高模型性能。
五、Layer normalization-位置篇
5.1 LN 在 LLMs 中的不同位置 有什么区别么?如果有,能介绍一下区别么?
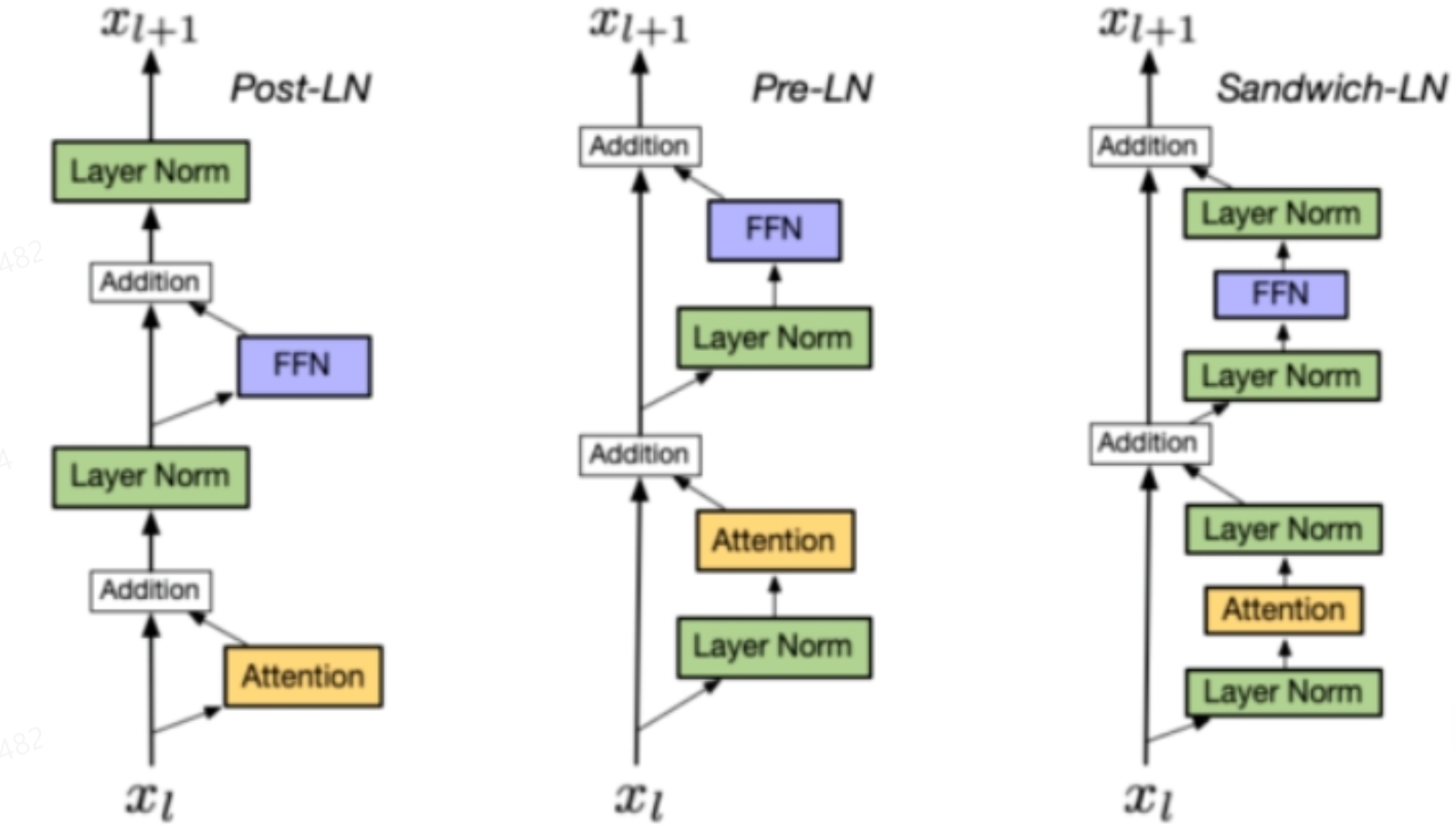
- Post-LN
-
- 位置:layer norm 在残差链接之后
- 缺点:Post-LN 在深层的梯度范式逐渐增大,导致使用 Post-LN 的深层 transformer 容易出现训练不稳定的问题
- Pre-LN
-
- 位置:layer norm 在残差链接中
- 优点:相比于Post-LN,Pre-LN 在深层的梯度范式近似相等,所以使用 Pre-LN 的深层transformer 训练更稳定,可以缓解训练不稳定问题
- 缺点:相比于 Post-LN,Pre-LN 的模型效果略差
- Sandwich-LN:
-
- 位置:在 pre-LN 的基础上,额外插入了一个 layer norm
- 优点:Cogview 用来避免值爆炸的问题
- 缺点:训练不稳定,可能会导致训练崩溃
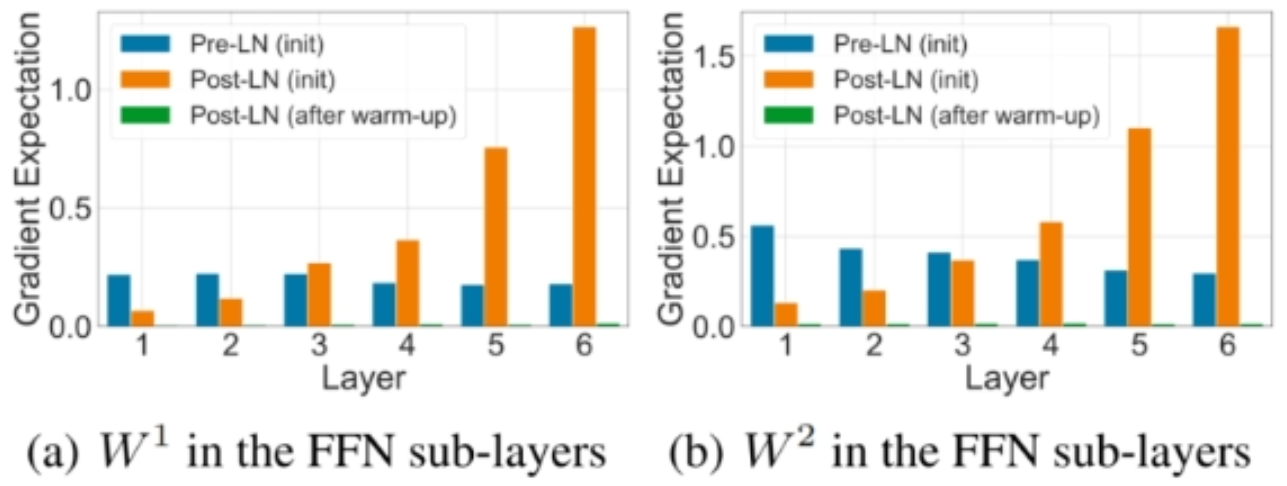
5.2 为什么说学习率决定了梯度更新的步长?
在深度学习中,学习率(Learning Rate,通常记作 η\etaη) 是一个非常重要的超参数,它决定了每次梯度更新时,模型参数调整的幅度。学习率的大小直接影响到模型的训练过程中的收敛速度以及稳定性,因此学习率决定了 梯度更新的步长。下面从几个角度详细解释这个概念。
1. 梯度下降中的基本公式
在训练神经网络时,我们通过最小化损失函数(loss function)来更新模型的参数。更新参数的方式通常使用梯度下降法(Gradient Descent),其中梯度代表了损失函数对参数的导数,表示损失函数相对于模型参数的变化率。
参数更新的公式为:
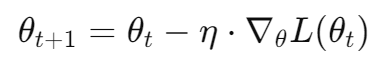

2. 学习率与步长的关系
在梯度下降算法中,学习率 η 控制了模型参数每次更新的步长。步长 可以理解为在梯度方向上参数的移动距离,也就是模型每次迭代时在参数空间中前进的幅度。
- 如果学习率很大:参数更新的步长就会很大,模型的参数会沿着梯度方向迅速移动。虽然这可能加快模型的收敛速度,但如果学习率太大,可能会导致模型跳过最优解,甚至在某些情况下可能会导致损失值震荡或发散。
- 如果学习率很小:参数更新的步长就会很小,模型的参数会缓慢调整。虽然这可能保证模型不会跳过最优解,但如果学习率太小,训练过程会非常缓慢,模型需要更多的迭代次数才能收敛,甚至可能陷入局部最优,难以进一步优化。
3. 学习率与梯度期望值的相互作用
在训练过程中,学习率和梯度期望值一起决定了参数更新的整体幅度。具体来说:

例如,在某些深层网络中,梯度消失问题会导致梯度非常小,此时,如果学习率太小,参数更新的步长会变得非常微弱,从而导致模型难以快速收敛;相反,如果学习率较大,尽管梯度较小,参数更新的步长依然能够保持适度,帮助模型更快收敛。
4. 动态调整学习率
由于学习率对训练过程至关重要,很多情况下,训练初期可能使用较大的学习率,以便模型快速调整参数接近最优解;在训练后期,则降低学习率,使模型更精细地优化参数。这种方法可以避免初期训练过慢以及后期收敛不稳定的问题。
常用的动态学习率调整策略包括:
- 学习率衰减(Learning Rate Decay):随着训练的进行,逐渐降低学习率。这样可以在模型接近最优解时减小步长,保证更稳定的收敛。
- 学习率调度器(Scheduler):根据模型在验证集上的表现或者训练的轮次来动态调整学习率。例如,训练的损失停滞时,可以自动减小学习率,帮助模型进一步优化。
5. 如何选择合适的学习率
选择合适的学习率是深度学习训练中的一个重要问题。一般来说:
- 在开始训练时,可以尝试用一个较大的学习率,以便模型快速下降,但如果发现模型发散或损失震荡,则需要减小学习率。
- 可以通过实验或者使用一些常用的学习率调度策略(例如线性衰减、余弦衰减)来找到合适的学习率。
六、Layer normalization 对比篇
6.1 LLMs 各模型分别用了哪种 Layer normalization?
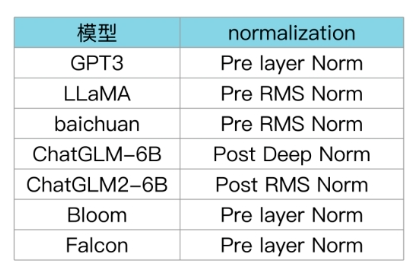
BLOOM 在 embedding 层后添加 layer normalization,有利于提升训练稳定性:但可能会带来很大的性能损失
6.2 LLMs 的 Layer normalization 对比分析