1.添加参考图像(add_reference_frame)
1.1 生成位置编码和ID编码
具体操作见详情。

图1:如图所示,显示的是参考图像的位置编码和id编码的生成过程。对于id编码,将mask图像输入进conv2d卷积网络后,进行结构转换,得到相应的id编码。对于位置编码,①根据最后一个比例特征图的高度和宽度生成高宽位置索引,索引值是0~29。②根据高宽的位置缩影得到xy两个维度的位置编码,分别命名为grid_x和gird_y。③在位置编码的前后分别扩充一个维度后,将位置编码除以温度变量dim_t。④计算位置编码偶数位的sin值和奇数位的cos值。⑤合并两个位置编码
位置编码和ID编码的生成步骤如上图所示。
1.2 reference mask匹配和预测其余帧mask
1.2.1 LSTT输入数据

图2,如图所示,是LSTT结构输入的数据,它们分别为curr-enc-embs第一个列表(这个列表存储的是相关帧的图像特征)的最后一个特征图、最后一个特征图的位置编码矩阵以及one-hot-mask的ID编码矩阵。
1.2.2 LSTT整体结构

图3,如图所示,是LSTT结构的概览,接下来将会逐一分解各个模块。注意,图上的spilit是将shape为[900,4,256]的特征图分解为[4,256,30,30]。
1.2.3 self-attention结构

图4, 如图4所示是self-attnetion结构示意图。
在self-attention结构中,将当前特征图进行层归一化后,得到v分支;将当前特征图与位置编码进行相加后得到K和Q分支。
将K\Q\V分支的特征图经过Linear线性层和多头分割后,原本的[900,4,256]结构的特征图的第三个维度被切分成32*8,因此得到[4,8,900,32]大小的特征图。
再将K、Q分支的多头特征图进行相乘和softmask操作,得到包含自注意力权重的特征图atten,(自注意力权重即图像本身应重点关注的区域,这些区域的特征图权重高。反之不需要关注的区域权重低)。
最后将自注意力权重特征图atten与V分支的特征图相乘,得到经过自注意力权重加权后的特征图output。
关于自注意力权重部分,以两个相同的3*3的矩阵相乘为例(分别为矩阵A和矩阵B),A和B相乘后得到矩阵C。矩阵A和矩阵B的值在神经网络中是一个个向量,所以矩阵A和矩阵B中的值越相似,相乘后权重越高,反之权重越低。因此矩阵C中的值Cij可以看作矩阵A第i行和矩阵B的第j列的相关程度。
def forward(self, Q, K, V):
"""
:param Q: A 3d tensor with shape of [T_q, bs, C_q]
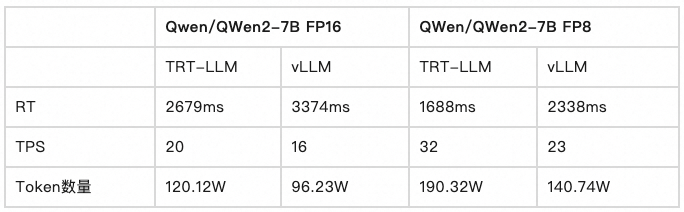
:param K: A 3d tensor with shape of [T_k, bs, C_k]
:param V: A 3d tensor with shape of [T_v, bs, C_v]
"""
num_head = self.num_head
hidden_dim = self.hidden_dim
bs = Q.size()[1]
# Linear projections
if self.use_linear:
Q = self.linear_Q(Q)
K = self.linear_K(K)
V = self.linear_V(V)
# Scale
Q = Q / self.T
if not self.training and self.max_mem_len_ratio > 0:
mem_len_ratio = float(K.size(0)) / Q.size(0)
if mem_len_ratio > self.max_mem_len_ratio:
scaling_ratio = math.log(mem_len_ratio) / math.log(
self.max_mem_len_ratio)
Q = Q * scaling_ratio
# Multi-head
Q = Q.view(-1, bs, num_head, self.d_att).permute(1, 2, 0, 3)
K = K.view(-1, bs, num_head, self.d_att).permute(1, 2, 3, 0)
V = V.view(-1, bs, num_head, hidden_dim).permute(1, 2, 0, 3)
# Multiplication
QK = multiply_by_ychunks(Q, K, self.qk_chunks)
if self.use_dis:
QK = 2 * QK - K.pow(2).sum(dim=-2, keepdim=True)
# Activation
if not self.training and self.top_k > 0 and self.top_k < QK.size()[-1]:
top_QK, indices = torch.topk(QK, k=self.top_k, dim=-1)
top_attn = torch.softmax(top_QK, dim=-1)
attn = torch.zeros_like(QK).scatter_(-1, indices, top_attn)
else:
attn = torch.softmax(QK, dim=-1)
# Dropouts
attn = self.dropout(attn)
# Weighted sum
outputs = multiply_by_xchunks(attn, V,
self.qk_chunks).permute(2, 0, 1, 3)
# Restore shape
outputs = outputs.reshape(-1, bs, self.d_model)
outputs = self.projection(outputs)
return outputs, attn
1.2.4 Fuse ID
if curr_id_emb is not None:
global_K, global_V = self.fuse_key_value_id(
curr_K, curr_V, curr_id_emb)
def fuse_key_value_id(self, key, value, id_emb):
K = key
V = self.linear_V(value + id_emb)
return K, V
如上代码可以发现global_k=curr_k。
global_v 等于curr_v和id编码矩阵相加后,再输入进linear层。

图5,如图所示是globalv和global k的生成步骤
1.2.5 Long term attention
Long term attention的结构和1.2.3节的self-attention结构一致,都是MultiHeadAttention结构。MultiHeadAttention的特色就在于将Q、K、V分支分解成多个Block后再计算注意力权重和加权后的特征图。
再Long term attention中,Q K V分支分别是 curr_Q, global_K, global_V。这里的原始特征图是经多头自注意力机制加权后的特征图tgt。将原始特征图经过LN和lnear层后得到curr_Q和curr_K,原始特征图先经过LN层得到curr_V,curr_V和ID编码矩阵相加后再输入进Linear层得到global_V。
这里的curr KQV和 global KQV被写的很复杂,但实际上就是:
KQV分支都是原始特征图经过LN+Linear层的结果,这里的是curr 信息
而V分支由于要添加ID编码矩阵,因此在LN层后,先添加ID矩阵,再进行Linear操作。因此添加了ID编码矩阵的V分支成为了global信息
值得注意的是,位置编码矩阵被添加到KQ分支,而ID编码矩阵被添加到V分支。这里我的理解是,有助于注意力理解的信息添加到KQ分支,用于计算相关性权重;而与注意力理解无关的,是特征图本身的信息被添加到V分支中。
由Long term attention的KQV分支的输入可知,Long Term Attention就是添加了位置编码和ID编码后,进行了两次自注意力操作。
1.2.6 Short term attention
Short Term Attention的KQV输入是,将Lone term attention的KQV输入分解成块后,再进行注意力计算。
因此在这里Lone term attention和Short Term Attention的区别在于,KQV分支的特征图是否被分解。
1.2.7 Feed - Forward
这里是将Short Term Attention的输出和Lone term attention的输出与原始特征图(原始特征图假设为tgt)相加后,再进行一些了LN、GN、Conv和线性操作(这里得到的假设为tgt2).最后将tgt与tgt2相加便完成了Feed Forward。