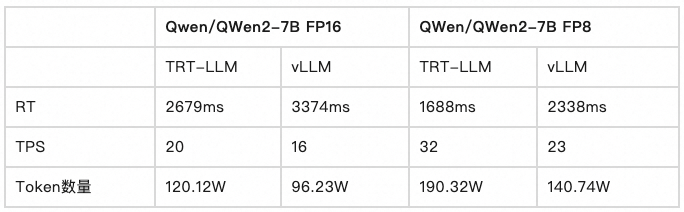
最近数字人越来越火,连互联网大佬都纷纷下场,比如360的周鸿祎,京东的刘强东等等。小伙伴可能也想拥有自己的数字人如果想用最简单的方式,那么可以用第三方的网站,例如 HeyGen平台、腾讯的智影等等。可这些网站都是收费的,而且价格也不便宜。如果我们只是想尝尝鲜,又想白嫖,那么有什么方法呢?
今天,我给大家安利一个SD插件,叫做SadTalker,这个插件可以实现让图片开口说话。操作简单之余,关键还是免费的。
使用
所需插件和模型
一、SadTalker插件
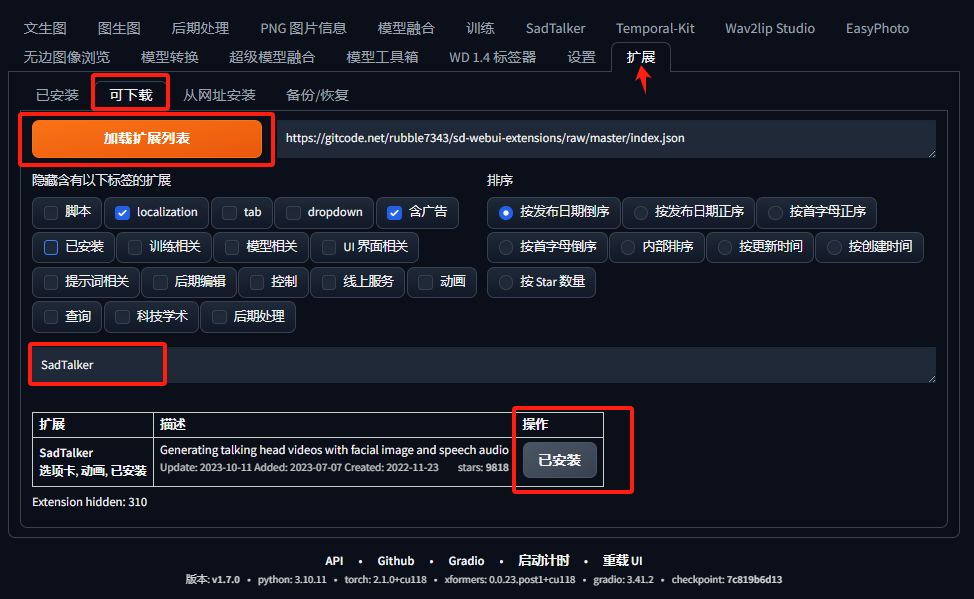
打开Stable Diffusion后,我们选择扩展选项。然后切换到可下载标签,点击加载扩展列表后,输入SadTalker ,就能看到插件,此时我们点击安装即可。
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。

二、所需模型
插件安装后,暂时还不能正常使用,还需手动下载几个模型,存放在指定的位置后才能使用,贴心的我早已为大家准备好了,文末会有说明,现在先接着往下看:
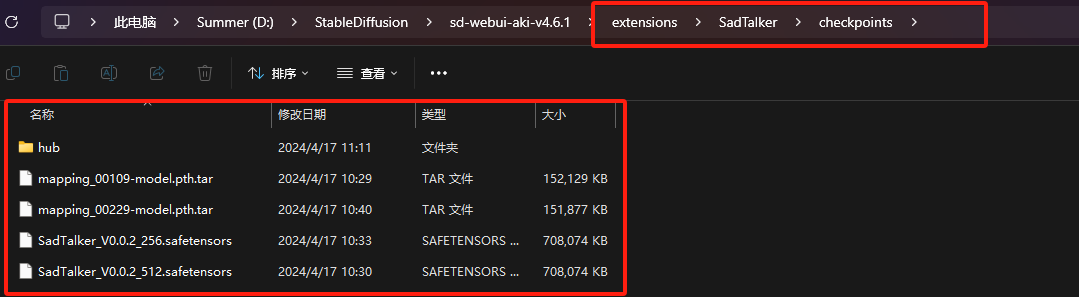
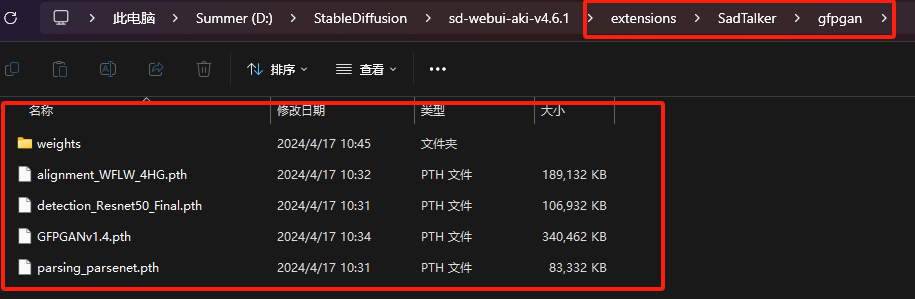
上述两个步骤完成后,需要重启SD,确保模型生效。
步骤说明
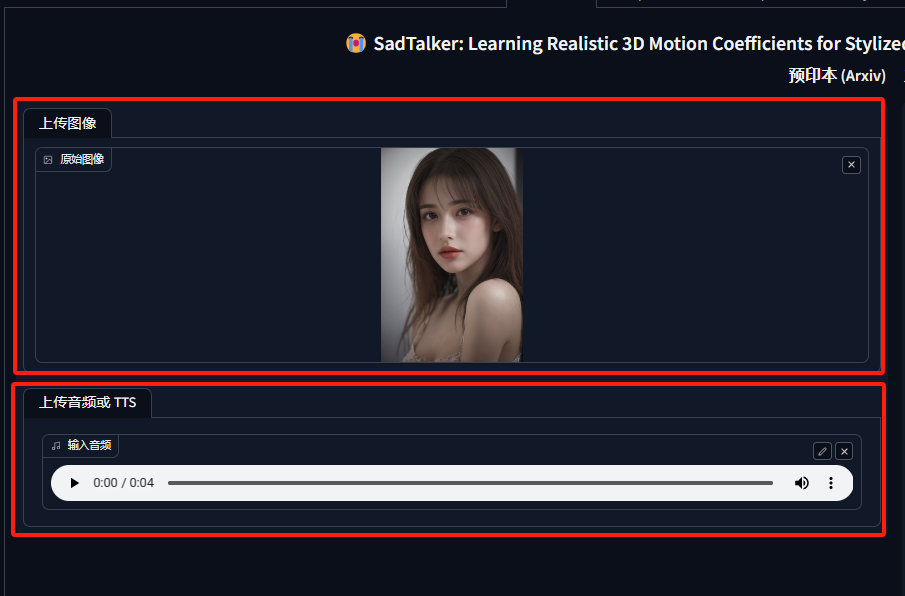
首先,我们打开SadTalker标签页,然后上传一张图片和一段音频:
接着来到参数部分,脸部模型分辨率选择 256 (显卡内存大的可以选择512),预处理选择 完整 ,勾选 使用GFPGAN 增强面部。最后点击生成即可。
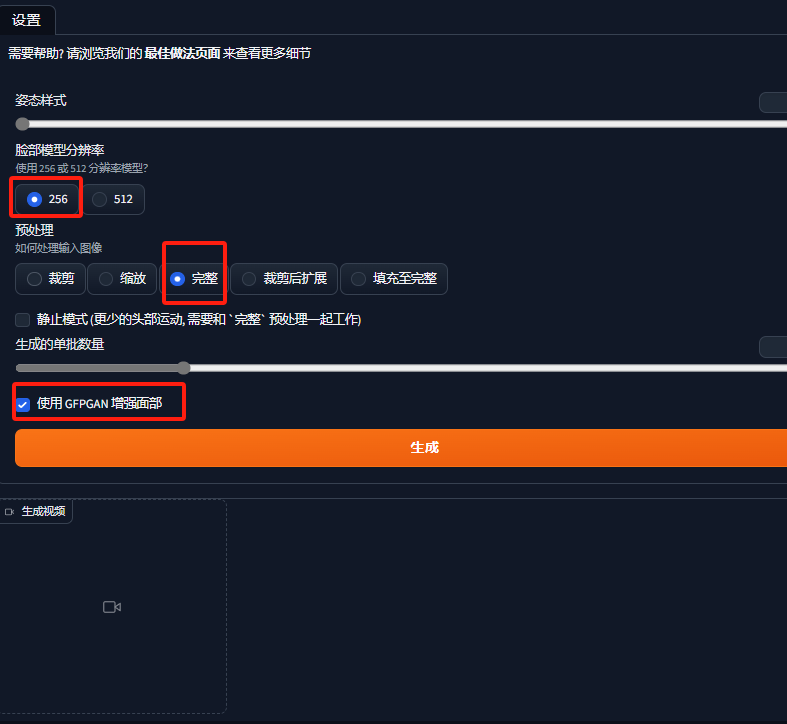
以下是SadTalker中提到的几种预处理选项的区别:
1. 裁剪(Crop):
裁剪预处理选项通常用于对输入图像进行调整,以确保面部区域是图像的主要焦点。这可能涉及到去除图像的多余部分,或者调整面部的位置和大小,使其符合模型的输入要求。
2. 缩放(Resize):
缩放是指改变图像的尺寸大小。这可以是将图像放大或缩小到特定的分辨率,以便与模型的输入尺寸相匹配。缩放可能会影响图像的细节和质量,因此需要谨慎处理以避免过度失真。
3. 完整(Full):
完整预处理选项可能意味着使用整个输入图像作为模型的输入,不做任何裁剪或缩放。这适用于模型能够处理原始图像尺寸的情况,或者当用户希望保留图像的所有内容时。
4. 裁剪后扩展(Crop and Expand):
这个选项可能包含两个步骤:首先裁剪图像以聚焦于面部区域,然后将裁剪后的图像扩展到所需的尺寸。这种预处理方式旨在保留面部的细节,同时确保图像符合模型的输入要求。
5. 填充至完整(Pad to Full):
填充至完整选项通常用于在保持图像原始尺寸的同时,通过添加背景或其他内容来填充图像的空白区域。这可以用于确保图像的尺寸符合模型的要求,同时避免图像内容的失真。
生成效果如下:
(视频由AI生成,请谨慎甄别)
总结
总体来说,有了这款sadTalker插件,只需通过一张图片,一段音频,就能轻松生成一个会说话的视频。
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。

- end -