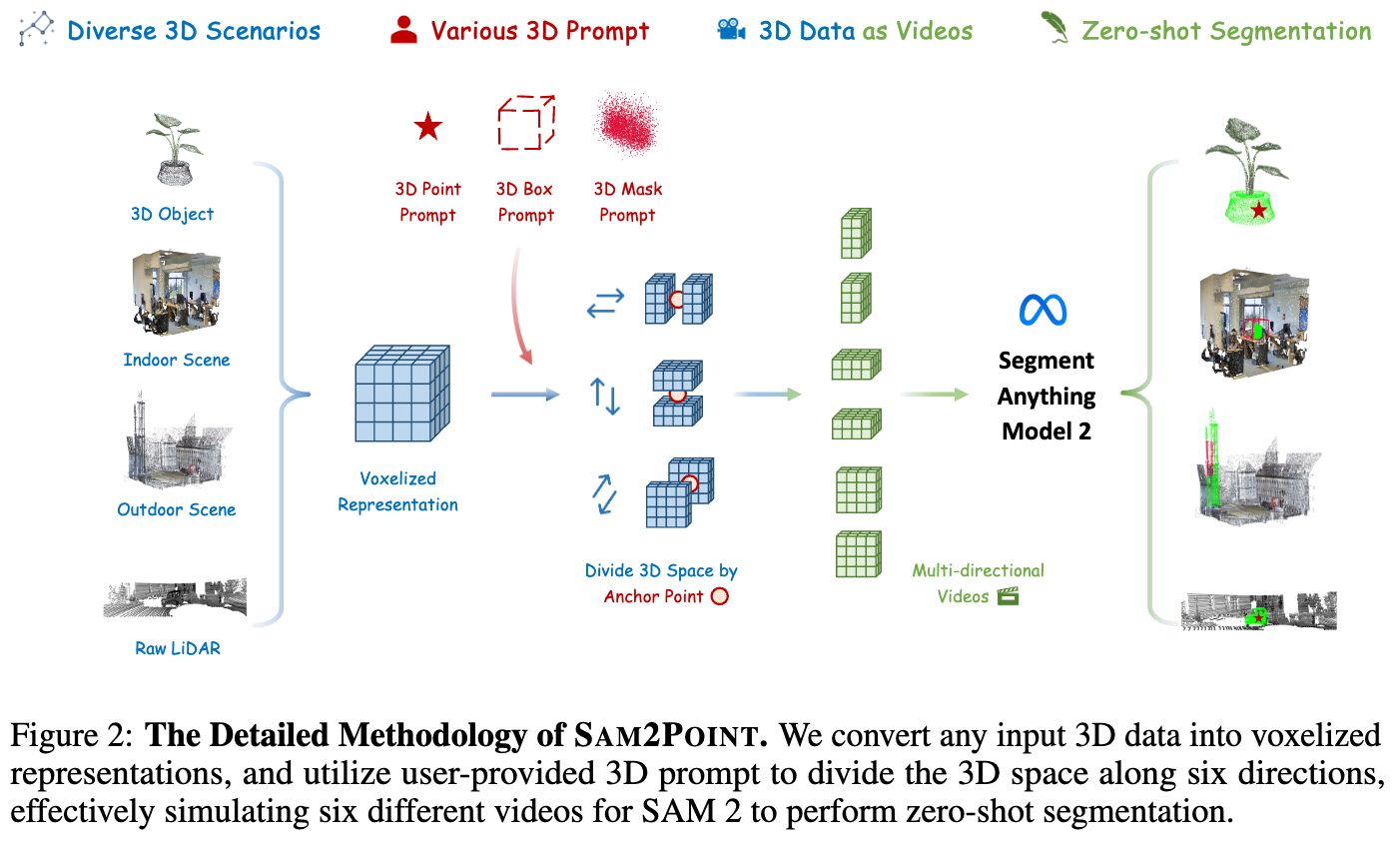
引言
大家好,这里是小琳AI课堂!今天我们要聊的是Meta最新发布的开源大模型LLaMA 3.1。这个版本在AI界掀起了不小的波澜,不仅在参数规模上有显著提升,还在多项性能上实现了突破。让我们一起来看看LLaMA 3.1带来的新变化和意义吧!
新版本亮点
参数规模的飞跃
LLaMA 3.1包含了三个主要参数规模的模型:8B、70B 和惊人的405B(4050亿参数)。这个405B版本,无疑是目前性能最强的开源模型之一,甚至在多项基准测试中超越了闭源模型GPT-4o和Claude 3.5 Sonnet。
功能和性能的全面提升
这个新版本支持多语言对话,并能解决更复杂的数学问题。它的上下文长度扩展至128K Tokens,大大增强了处理长文本的能力。这些进步标志着开源大模型在功能和性能上与闭源模型差距的进一步缩小。
发展历程
初创阶段:理念的萌发🌱
LLaMA模型的构想源于Meta AI对人工智能未来发展的深刻洞察。面对模型规模不断扩大带来的挑战,LLaMA模型的研发应运而生,旨在高效利用大规模数据,提升模型性能和可解释性。
研发阶段:技术的突破🚀
LLaMA模型的研发过程中,Meta AI团队采用了多种创新技术。他们在数据预处理阶段引入了新技术,处理大规模数据集;模型架构方面,采用了基于Transformer的架构,并行处理能力和高效性让它在处理长序列数据方面大放异彩。
技术特点
创新的数据预处理技术
LLaMA模型在数据预处理方面采用了多种创新技术。新的数据清洗和过滤方法,动态掩码技术,都让数据质量更上一层楼,提高了模型的泛化能力。
先进的模型架构
基于Transformer的架构,让LLaMA模型在处理长序列数据方面具有显著优势。团队在Transformer的基础上进行了多种改进,提高了模型的性能和效率。
应用前景
自然语言处理领域的革新
LLaMA模型在自然语言处理领域的应用前景非常广阔。它可以用于文本分类、情感分析、机器翻译等多种任务,为这些任务带来性能的显著提升。
结语
LLaMA 3.1的发布,不仅展示了Meta在开源大模型领域的领导地位,同时也为未来人工智能技术的发展奠定了坚实的基础。随着人工智能技术的不断发展,LLaMA模型有望在未来发挥更加重要的作用,为人工智能领域带来新的突破。
本期的小琳AI课堂就到这里,希望对大家有所启发和帮助!如果对LLaMA模型还有更多的好奇和问题,欢迎继续提问哦!🌈👋