引言:为什么我们需要更智能的SQL生成?
在数据驱动的业务环境中,SQL 仍然是数据分析的核心工具。然而,编写正确的 SQL 查询需要专业知识,而大型语言模型(LLM)直接生成的 SQL 往往存在**幻觉(hallucination)**或不符合业务逻辑的问题。
Vanna 是一个基于 检索增强生成(RAG) 的框架,专门优化自然语言到 SQL 的转换。它结合了 LLM 的强大推理能力和数据库的上下文信息,显著提高了 SQL 生成的准确性。
本文将深入探讨:
-
Vanna 的核心工作原理
-
它如何比纯 LLM 更可靠
-
如何快速集成到你的数据工作流
1. Vanna 的核心工作原理
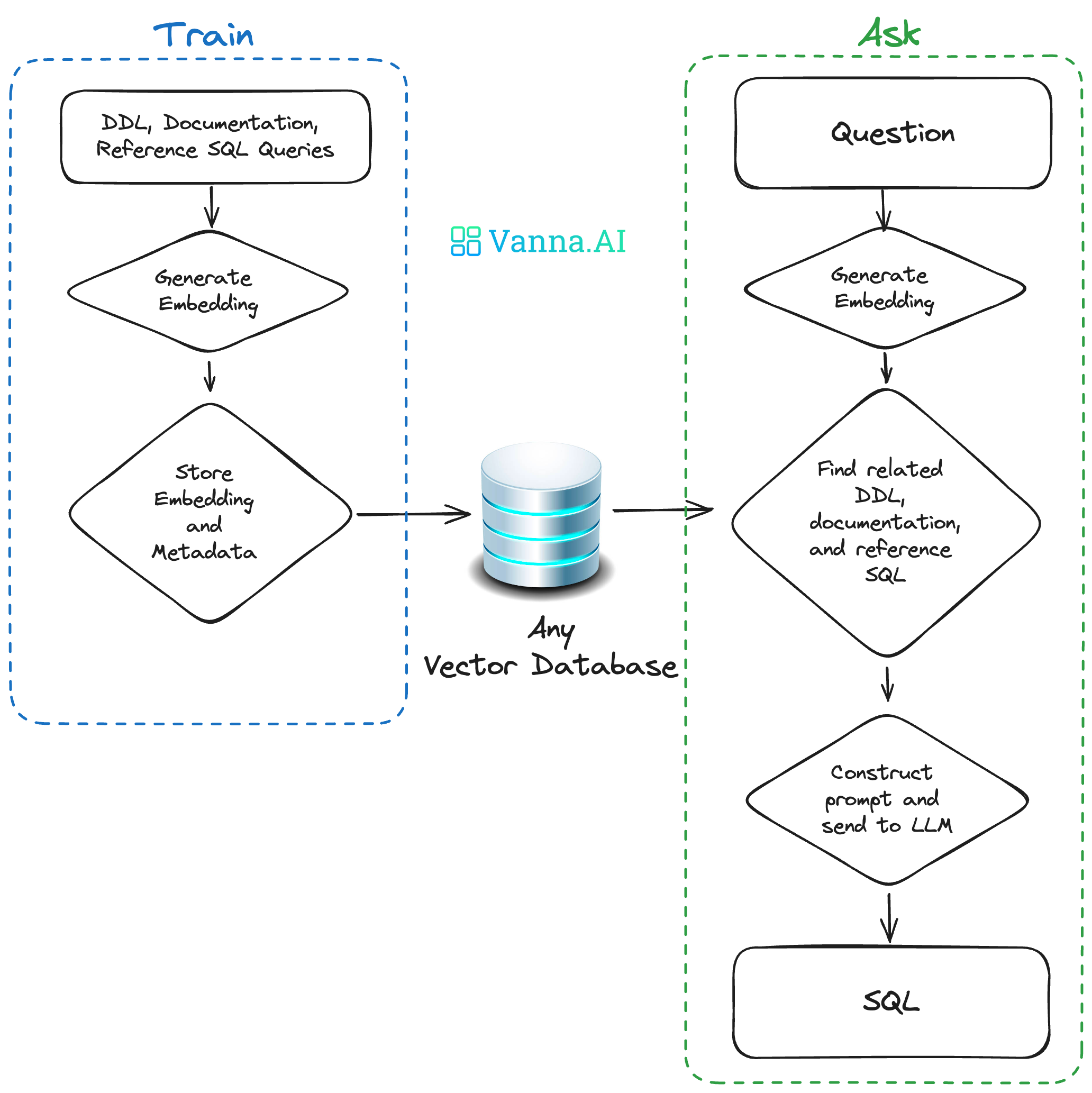
Vanna 的工作流程分为 训练阶段 和 推理阶段,形成一个持续优化的闭环系统。
(1)训练阶段:构建知识库
Vanna 通过以下方式学习你的数据库:
-
数据库模式(DDL):存储表结构、字段类型、外键关系。
vn.train(ddl="CREATE TABLE sales (id INT, product_id INT, amount FLOAT, date TIMESTAMP)") -
业务规则文档:定义关键指标(如“销售额 =
SUM(amount)”)。vn.train(documentation="销售额是指销售表中 amount 列的总和") -
历史查询缓存:存储已验证的 SQL 及其自然语言问题,形成 QA 对。
这些数据会被向量化并存入向量数据库(如 Chroma、FAISS),供后续检索使用。
(2)推理阶段:动态生成SQL
当用户提问时(如 “2023年销售额最高的产品是什么?”),Vanna 执行以下步骤:
-
检索相关上下文
-
使用向量搜索召回:
-
相关表结构(
sales表、products表) -
业务规则(“销售额 =
SUM(amount)”) -
类似的历史查询(
SELECT product, SUM(amount) FROM sales GROUP BY product)
-
-
-
组装Prompt,输入LLM
你是一个SQL专家。根据以下信息生成查询: ### 数据库结构: - sales(id INT, product_id INT, amount FLOAT, date TIMESTAMP) - products(id INT, name VARCHAR) ### 业务规则: - 销售额 = SUM(amount) ### 类似查询: - "各产品销售额" → SELECT name, SUM(amount) FROM sales JOIN products ON sales.product_id = products.id GROUP BY name ### 问题: 2023年销售额最高的产品是什么? -
生成并优化SQL
LLM 返回:SELECT p.name, SUM(s.amount) FROM sales s JOIN products p ON s.product_id = p.id WHERE YEAR(s.date) = 2023 GROUP BY p.name ORDER BY SUM(s.amount) DESC LIMIT 1 -
执行或人工审核
-
可自动执行并返回结果,或由数据团队验证后修正。
-
修正后的 SQL 会反馈到训练库,使模型持续改进。
-
Vanna的工作原理
Vanna通过两个简单步骤工作:在你的数据上训练一个RAG“模型”,然后提出问题,返回可自动在数据库上运行的SQL查询。
- 对你的数据训练一个RAG“模型”。
- 提问。
2. Vanna vs. 纯LLM:为什么更可靠?
| 对比维度 | 纯LLM(如ChatGPT) | Vanna + RAG |
|---|---|---|
| 领域知识 | 通用知识,可能不了解你的数据库 | 动态注入表结构、业务规则 |
| 准确性 | 复杂查询错误率高 | 检索增强减少幻觉,实测提升30-50% |
| 可解释性 | 黑箱生成,难以调试 | 可查看检索到的上下文,定位问题 |
| 持续学习 | 静态模型,无法优化 | 用户反馈闭环,越用越准 |
典型案例:
-
纯LLM:提问“计算客户留存率”可能生成错误的 JOIN 逻辑。
-
Vanna:检索业务定义后,生成正确的 SQL(如使用日期差计算留存)。
3. 如何快速集成Vanna?
(1)安装与初始化
pip install vanna
from vanna.llm.openai import OpenAI_Chat
from vanna.vannadb import VannaDB
vn = Vanna(model=OpenAI_Chat(), db_engine=your_db_connection)(2)训练模型
# 注入DDL
vn.train(ddl="CREATE TABLE products (id INT, name VARCHAR, price FLOAT)")
# 添加业务文档
vn.train(documentation="高价值产品指价格超过1000元的商品")
# 录入历史SQL
vn.train(
question="哪些是高价值产品?",
sql="SELECT name FROM products WHERE price > 1000"
)(3)生成SQL
question = "2023年最畅销的高价值产品是什么?"
sql = vn.generate_sql(question)
print(sql)(4)部署为API
Vanna 提供 Flask 快速部署:
from vanna.flask import VannaFlaskApp
app = VannaFlaskApp(vn)
app.run()4. 未来展望
Vanna 的潜力不仅限于 SQL 生成:
-
BI 工具增强:为 Tableau/Power BI 提供自然语言查询接口。
-
自动化数据探查:通过对话式分析发现数据趋势。
-
多模态扩展:结合文本和图表,实现更智能的数据交互。
结论
Vanna 通过 RAG + 反馈学习,将 LLM 变成了一个“懂你业务”的 SQL 助手。它特别适合:
-
数据分析团队:减少重复的 SQL 编写工作。
-
非技术用户:通过自然语言查询数据库。
-
数据平台开发者:快速构建智能查询接口。
项目已开源(Apache 2.0),支持 Snowflake、BigQuery、PostgreSQL 等主流数据库,立即试用:GitHub - vanna-ai/vanna
📌 互动提问
-
你的团队是否尝试过自然语言转 SQL 工具?体验如何?
-
如果采用 Vanna,你希望优先解决哪些场景的问题?
欢迎在评论区分享你的想法! 🚀