OrangePi AIpro 香橙派 昇腾 Ascend C 算子开发 与 调用 - Tiling实现
flyfish
前置知识
基于Kernel直调工程的算子开发流程图
其中有一个Tiling实现

什么是Tiling、Tiling实现
计算API,包括标量计算API、向量计算API、矩阵计算API,分别实现调用Scalar计算单元、Vector计算单元、Cube计算单元执行计算的功能。
数据搬运API,计算API基于Local Memory数据进行计算,所以数据需要先从Global Memory搬运至Local Memory,再使用计算API完成计算,最后从Local Memory搬出至Global Memory。执行搬运过程的接口称之为数据搬移API,比如DataCopy接口。
大多数情况下,Local Memory的存储,无法完整的容纳算子的输入与输出,需要每次搬运一部分输入进行计算然后搬出,再搬运下一部分输入进行计算,直到得到完整的最终结果,这个数据切分、分块计算的过程称之为Tiling。根据算子的shape等信息来确定数据切分算法相关参数(比如每次搬运的块大小,以及总共循环多少次)的计算程序,称之为Tiling实现。

昇腾AI处理器在进行数据搬运和Vector计算时,对于搬运的数据长度和UB首地址都有必须32B对齐的要求。
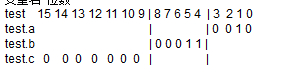
当需要从Global拷贝11个half数值到Local时,使用DataCopy将拷贝16个half(32B)数据到Local上,Local[11]~Local[15]被写成无效数据-1。
非对齐搬入内存

当需要从Local拷贝11个half数值到Global时,使用DataCopy将拷贝16个half(32B)数据到Global上,Global[11]~Global[15]被覆写成-1。
非对齐搬出内存

Tiling实现完成后,获取到的Tiling切分算法相关参数,会传递给kernel侧,用于指导并行数据的切分。由于Tiling实现中完成的均为标量计算,AI Core并不擅长,所以我们将其独立出来放在host CPU上执行。
tiling实现
TilingData参数设计,TilingData参数本质上是和并行数据切分相关的参数,本示例算子使用了2个tiling参数:totalLength、tileNum。totalLength是指需要计算的数据量大小,tileNum是指每个核上总计算数据分块个数。比如,totalLength这个参数传递到kernel侧后,可以通过除以参与计算的核数,得到每个核上的计算量,这样就完成了多核数据的切分。tiling实现代码中通过上下文获取输入输出的shape信息,并对应设置TilingData。
原始的
// 实现核函数
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z)
{
// 初始化算子类,算子类提供算子初始化和核心处理等方法
KernelAdd op;
// 初始化函数,获取该核函数需要处理的输入输出地址,同时完成必要的内存初始化工作
op.Init(x, y, z);
// 核心处理函数,完成算子的数据搬运与计算等核心逻辑
op.Process();
}
// 调用核函数
void add_custom_do(uint32_t blockDim, void* l2ctrl, void* stream, uint8_t* x, uint8_t* y, uint8_t* z)
{
add_custom<<<blockDim, l2ctrl, stream>>>(x, y, z);
}
tiling实现
add_custom_tiling.h
#ifndef ADD_CUSTOM_TILING_H
#define ADD_CUSTOM_TILING_H
#include <cstdint>
struct AddCustomTilingData {
uint32_t totalLength;
uint32_t tileNum;
};
#endif
add_custom.cpp
#include "add_custom_tiling.h"
#include "kernel_operator.h"
constexpr int32_t BUFFER_NUM = 2; // tensor num for each queue
class KernelAdd {
public:
__aicore__ inline KernelAdd() {}
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z, uint32_t totalLength, uint32_t tileNum)
{
this->blockLength = totalLength / AscendC::GetBlockNum();
this->tileNum = tileNum;
this->tileLength = this->blockLength / tileNum / BUFFER_NUM;
xGm.SetGlobalBuffer((__gm__ half *)x + this->blockLength * AscendC::GetBlockIdx(), this->blockLength);
yGm.SetGlobalBuffer((__gm__ half *)y + this->blockLength * AscendC::GetBlockIdx(), this->blockLength);
zGm.SetGlobalBuffer((__gm__ half *)z + this->blockLength * AscendC::GetBlockIdx(), this->blockLength);
pipe.InitBuffer(inQueueX, BUFFER_NUM, this->tileLength * sizeof(half));
pipe.InitBuffer(inQueueY, BUFFER_NUM, this->tileLength * sizeof(half));
pipe.InitBuffer(outQueueZ, BUFFER_NUM, this->tileLength * sizeof(half));
}
__aicore__ inline void Process()
{
int32_t loopCount = this->tileNum * BUFFER_NUM;
for (int32_t i = 0; i < loopCount; i++) {
CopyIn(i);
Compute(i);
CopyOut(i);
}
}
private:
__aicore__ inline void CopyIn(int32_t progress)
{
AscendC::LocalTensor<half> xLocal = inQueueX.AllocTensor<half>();
AscendC::LocalTensor<half> yLocal = inQueueY.AllocTensor<half>();
AscendC::DataCopy(xLocal, xGm[progress * this->tileLength], this->tileLength);
AscendC::DataCopy(yLocal, yGm[progress * this->tileLength], this->tileLength);
inQueueX.EnQue(xLocal);
inQueueY.EnQue(yLocal);
}
__aicore__ inline void Compute(int32_t progress)
{
AscendC::LocalTensor<half> xLocal = inQueueX.DeQue<half>();
AscendC::LocalTensor<half> yLocal = inQueueY.DeQue<half>();
AscendC::LocalTensor<half> zLocal = outQueueZ.AllocTensor<half>();
AscendC::Add(zLocal, xLocal, yLocal, this->tileLength);
outQueueZ.EnQue<half>(zLocal);
inQueueX.FreeTensor(xLocal);
inQueueY.FreeTensor(yLocal);
}
__aicore__ inline void CopyOut(int32_t progress)
{
AscendC::LocalTensor<half> zLocal = outQueueZ.DeQue<half>();
AscendC::DataCopy(zGm[progress * this->tileLength], zLocal, this->tileLength);
outQueueZ.FreeTensor(zLocal);
}
private:
AscendC::TPipe pipe;
AscendC::TQue<AscendC::QuePosition::VECIN, BUFFER_NUM> inQueueX, inQueueY;
AscendC::TQue<AscendC::QuePosition::VECOUT, BUFFER_NUM> outQueueZ;
AscendC::GlobalTensor<half> xGm;
AscendC::GlobalTensor<half> yGm;
AscendC::GlobalTensor<half> zGm;
uint32_t blockLength;
uint32_t tileNum;
uint32_t tileLength;
};
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z, AddCustomTilingData tiling)
{
KernelAdd op;
op.Init(x, y, z, tiling.totalLength, tiling.tileNum);
op.Process();
}
main.cpp

#include "add_custom_tiling.h"
#include "data_utils.h"
#ifndef ASCENDC_CPU_DEBUG
#include "acl/acl.h"
#include "aclrtlaunch_add_custom.h"
#else
#include "tikicpulib.h"
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z, AddCustomTilingData tiling);
#endif
int32_t main(int32_t argc, char *argv[])
{
uint32_t blockDim = 8;
size_t tilingSize = 2 * sizeof(uint32_t);
size_t inputByteSize = 8 * 2048 * sizeof(uint16_t);
size_t outputByteSize = 8 * 2048 * sizeof(uint16_t);
#ifdef ASCENDC_CPU_DEBUG
uint8_t *tiling = (uint8_t *)AscendC::GmAlloc(tilingSize);
ReadFile("./input/input_tiling.bin", tilingSize, tiling, tilingSize);
uint8_t *x = (uint8_t *)AscendC::GmAlloc(inputByteSize);
uint8_t *y = (uint8_t *)AscendC::GmAlloc(inputByteSize);
uint8_t *z = (uint8_t *)AscendC::GmAlloc(outputByteSize);
ReadFile("./input/input_x.bin", inputByteSize, x, inputByteSize);
ReadFile("./input/input_y.bin", inputByteSize, y, inputByteSize);
AscendC::SetKernelMode(KernelMode::AIV_MODE);
ICPU_RUN_KF(add_custom, blockDim, x, y, z,
*reinterpret_cast<AddCustomTilingData *>(tiling)); // use this macro for cpu debug
WriteFile("./output/output_z.bin", z, outputByteSize);
AscendC::GmFree((void *)x);
AscendC::GmFree((void *)y);
AscendC::GmFree((void *)z);
AscendC::GmFree((void *)tiling);
#else
CHECK_ACL(aclInit(nullptr));
int32_t deviceId = 0;
CHECK_ACL(aclrtSetDevice(deviceId));
aclrtStream stream = nullptr;
CHECK_ACL(aclrtCreateStream(&stream));
AddCustomTilingData *tiling;
uint8_t *xHost, *yHost, *zHost;
uint8_t *xDevice, *yDevice, *zDevice;
CHECK_ACL(aclrtMallocHost((void **)(&tiling), tilingSize));
ReadFile("./input/input_tiling.bin", tilingSize, tiling, tilingSize);
CHECK_ACL(aclrtMallocHost((void **)(&xHost), inputByteSize));
CHECK_ACL(aclrtMallocHost((void **)(&yHost), inputByteSize));
CHECK_ACL(aclrtMallocHost((void **)(&zHost), outputByteSize));
CHECK_ACL(aclrtMalloc((void **)&xDevice, inputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));
CHECK_ACL(aclrtMalloc((void **)&yDevice, inputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));
CHECK_ACL(aclrtMalloc((void **)&zDevice, outputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));
ReadFile("./input/input_x.bin", inputByteSize, xHost, inputByteSize);
ReadFile("./input/input_y.bin", inputByteSize, yHost, inputByteSize);
CHECK_ACL(aclrtMemcpy(xDevice, inputByteSize, xHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE));
CHECK_ACL(aclrtMemcpy(yDevice, inputByteSize, yHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE));
ACLRT_LAUNCH_KERNEL(add_custom)(blockDim, stream, xDevice, yDevice, zDevice, tiling);
CHECK_ACL(aclrtSynchronizeStream(stream));
CHECK_ACL(aclrtMemcpy(zHost, outputByteSize, zDevice, outputByteSize, ACL_MEMCPY_DEVICE_TO_HOST));
WriteFile("./output/output_z.bin", zHost, outputByteSize);
CHECK_ACL(aclrtFree(xDevice));
CHECK_ACL(aclrtFree(yDevice));
CHECK_ACL(aclrtFree(zDevice));
CHECK_ACL(aclrtFreeHost(xHost));
CHECK_ACL(aclrtFreeHost(yHost));
CHECK_ACL(aclrtFreeHost(zHost));
CHECK_ACL(aclrtFreeHost(tiling));
CHECK_ACL(aclrtDestroyStream(stream));
CHECK_ACL(aclrtResetDevice(deviceId));
CHECK_ACL(aclFinalize());
#endif
return 0;
}


















![[某度信息流]SQL164,2021年11月每天新用户的次日留存率](https://i-blog.csdnimg.cn/direct/292e919182c04f84839e2bbe8bddf2b8.png)