使用KeepAlived配置实现虚IP在多服务器节点漂移
1 )环境准备
- 2台 linux , 一主一备
- 节点1:192.168.184.30 CentOS 7 Master
- 节点2:192.168.184.40 CentOS 7 Backup
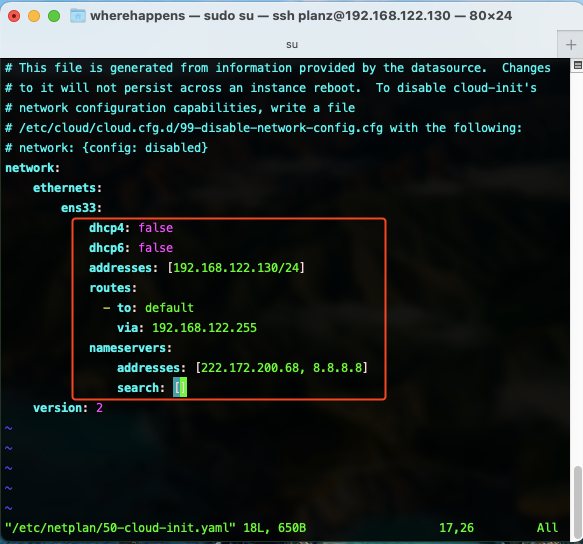
- VIP 192.168.184.50
- 安装 KeepAlived, $
yum install keepalived- 注意,安装好yum源,base 源就有这个软件
- 两台都执行安装
- 关闭selinux 和 防火墙
- $
setenforce 0临时关闭- 或
vim /etc/sysconfig/selinux编辑SELINUX=disabled永久关闭
- 或
- $
systemctl stop firewalld关闭systemctl disable firewalld关闭自启动
- 这里非常重要,否则可能两台机器无法通信
- $
2 ) 相关配置说明
- 查看软件生成了哪些文件, $
rpm -ql keepalived- 可以选择其中一台去执行
- 输出有一些比较重要的文件和目录,可以去看看,这里着重说明
- /etc/keepalived/keepalived.conf 主配置文件
- /etc/sysconfig/keepalived 更改默认属性配置文件
- /usr/bin/genhash 二进制程序
- /usr/lib/systemd/system/keepalived.service 使用systemctl 启动停止查看
- /usr/libexec/keepalived 这是lib包
- /usr/sbin/keepalived 这是主程序文件
- 查看相关配置文件 $
vim /etc/keepalived/keepalived.conf- 可以先在一台上操作,比如 184.30 这台机器
- ! Configuration File for keepalived 这一段是注释
global_defs块中,决定了全局属性,全局配置, 对整个 keepalived 生效global_defs { notification_email { # 这里可以写多个邮箱, 确保服务器在内网并且邮箱可收到当前服务器发送的邮件 admin@baidu.com master@baidu.com } notification_email_from ka@baidu.com # 填写自己的邮箱 smtp_server 192.168.184.200 smtp_connect timeout 30 # 连接邮件服务器时的超时时长 router_id Nginx # 这里 router_id 自己起个名字 # vrrp_skip_check_adv_addr # 以下都注释掉 # vrrp_strict # 严格的vrrp限制,可以注释掉,可能会有绑定好了,但ping不通的问题,所以注释了 # vrrp_garp_interval 0 # vrrp_gna_interval 0 }vrrp_instance Nginx_1块,是vrrp的实例,名称叫做 Nginx_1 这个自己修改vrrp instance Nginx_1 { state MASTER # 标记是 master 还是 backup interface ens33 # 当前服务器需要绑定的网卡,指定一块网卡, 根据实际情况指定内网网卡(184.30这块) virtual_router_id 51 # 标识虚拟路由id,可以自己写,要确保相同名称的实例,这里的id是一样的 priority 100 # 指定优先级,值越大,转移优先级越高 advert_int 1 authentication { auth_type PASS # 认证方式,通过密码 auth_pass 1111 } virtual_ipaddress { # 虚拟的ip地址,下面可以填入多个,VIP 也可以就填一个,按照之前设计 192.168.200.50 } }- 其他配置都可以先删除
- 接着,在 184.40 的 /etc/keepalived/keepalived.conf 配置文件做类似必要修改
global_defs { notification_email { admin@baidu.com master@baidu.com } notification_email_from ka@baidu.com smtp_server 192.168.184.200 smtp_connect timeout 30 # 连接邮件服务器时的超时时长 router_id Nginx # vrrp_skip_check_adv_addr # vrrp_strict # vrrp_garp_interval 0 # vrrp_gna_interval 0 } vrrp instance Nginx_1 { # 这里要和 master 配置成同一个实例名称,否则不会成功 state BACKUP # 注意这里 interface ens33 # 根据实际情况指定内网网卡(184.40这块) virtual_router_id 51 # 同 master 一致,才能保证转移 priority 98 # 这个优先级较小 advert_int 1 authentication { auth_type PASS # 认证方式,通过密码 auth_pass 1111 } virtual_ipaddress { # 虚拟的ip地址,下面可以填入多个,VIP 也可以就填一个,按照之前设计 192.168.200.50 } } - 配置好两台之后,我们在 184.30 机器上监控下日志,新开一个控制台, $
tail -f /var/log/messages - 之后再 184.30 上开启一个终端,启动 $
systemctl start keepalived - 通过 var/log/messages 日志的监控,我们可以看到如下关键信息
Starting Keepalived v1.3.5 (03/19,2017),git commit v1.3.5-6 g6fa32f2 这里可以看到软件版本 Opening file '/etc/keepalived/keepalived.conf' 这里正在打开配置文件 Starting Healthcheck child process, pid=3968 这里进行健康检查 Starting VRRP child process, pid=3969 这里启动 VRRP 协议 Keepalived healthcheckers[3968]: Opening file '/etc/keepalived/keepalived.conf Registering Kernel netlink reflector Registering Kernel netlink command channel Registering gratuitous ARP shared channel Opening file '/etc/keepalived/keepalived.conf' Started LVS and VRRP High Availability Monitor VRRP Instance(Nginx 1) removing protocol VIPs. Using LinkWatch kernel netlink reflector... VRRP sockpool: [ifindex(2), proto(112), unicast(0), fd(10,11)] VRRP_Instance(Nginx_1) Transition to MASTER STATE # 注意这里,进入 master 状态 VRRP_Instance(Nginx_1) Entering MASTER STATE VRRP_Instance(Nginx_1) setting protocol IPs. # 注意这里,设置 ip Sending gratuitous ARP on ens33 for 192.168.184.50 # 配置184.50到当前节点 VRRP_Instance(Nginx_1) Sending/queueing gratuitous ARPs on ens33 for 192.168.184.50 # 不停发送信息 Sending gratuitous ARP on ens33 for 192.168.184.50 Sending gratuitous ARP on ens33 for 192.168.184.50- 184.30 后面在局域网内不停发送 ARP 广播信息:我已经有了184.50地址了,并且我是健康的
- 184.40 机器收到后发现自己的优先级较低,会自动进入备用和待命状态
- 在184.30 这台机器上检查 $
ip a1: lo: <LOOPBACK,UP, LOWER UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid lft forever preferred lft forever inet6 :: 1/128 scope host valid lft forever preferred lft forever 2: ens33: <BROADCAST,MULTICAST, UP, LOWER UP> mtu 1500 qdisc pfifo fast state UP qlen 1 000 link/ether 00:0c:29:e1:51:9c brd ff:ff:ff:ff:ff:ff inet 192.168.184.30/24 brd 192.168.184.255 scope global ens33 valid lft forever preferred lft forever inet 192.168.184.50/32 scope global ens33 valid lft forever preferred lft forever inet6 fe80::e2f8:ff8a:c97a:2368/64 scope link valid lft forever preferred lft forever- 这里可以看到 ens33上存在:
inet 192.168.184.50/32 scope global ens33 - 也就是 184.50 被绑定到了 ens33 网卡上了
- 使用其他机器,比如 184.40 ping 这个 184.50 显示正常
- 这样,184.50 这个 VIP 就可以正常对外提供服务了
- 这里可以看到 ens33上存在:
- 按照同样的方法,监测并启动 184.40 这台 backup 机器
- 它会进入 BACKUP STATE 并不断进行监测
- 有一条重要信息:
VRRP_Instance(Nginx_1) Received advert with higher priority 100, ours 98 - 可见,基于优先级,这里仍旧是 BACKUP STATE
- 执行 $
ip a时,184.40 是不会有 184.50 的VIP信息的
3 )模拟主节点宕机
- 在 184.30 机器上,$
systemctl stop keepalived或 $reboot - 在 184.40 机器上监测的日志信息中会发现,立即进入 MASTER STATE
- 并且 setting protocol VIPs.
- 同时,继续广播自己已经拥有了 184.50,其他机器去主动更新本地ARP缓存表
- 通过 $
ip a可以看到 184.50 已经有了
- 当184.30机器恢复并重新上线
- 184.30 会立即变成 MASTER STATE
- 184.40 会立即降级 BACKUP STATE
- 这个是默认的配置,有时候我们并不想有这个效果,会对业务存在一定风险
- 如果不想重新上线后又变成了 MASTER STATE,即非抢占式的
- 在两台机器的 /etc/keepalived/keepalived.conf 的
vrrp_instance Nginx_1段中 - 添加一项配置
nopreempt并且 都配置成 state BACKUP,没有 MASTER 了 - 这样就都配置成了非抢占式,注意这里,非抢占式都配置成 BACKUP
- 只要有一台配置了 MASTER 并且优先级较大,非抢占式就不会成功,就会去抢占
- 在两台机器的 /etc/keepalived/keepalived.conf 的
- 以上就实现了2台机器的 VIP 转移, 需要多个机器的话,就多配置几台即可
4 )日志管理
- 默认情况下,配置到了 /var/log/messages 中,如果不想配置在这里
- 可以在 /etc/sysconfig/keepalived 中
# Options for keepalived. See `keepalived --help' output and keepalived(8) and # keepalived.conf(5) man pages for a list of all options. Here are the most # common ones : # # --vrrp -P Only run with VRRP subsystem. # --check -C Only run with Health-checker subsystem. # --dont-release-vrrp -V Dont remove VRRP VIPs & VROUTEs on daemon stop. # --dont-release-ipvs -I Dont remove IPVS topology on daemon stop. # --dump-conf -d Dump the configuration data. # --log-detail -D Detailed log messages. # --log-facility -S 0-7 Set local syslog facility (default=LOG DAEMON) # KEEPALIVED OPTIONS="-D -d -S 0" # 修改这里,默认是 -DKEEPALIVED OPTIONS="-D -d -S 0"将 日志文件 放入 -S 中
- 之后,$
vim /etc/rsyslog.conf更改日志的存放位置local7.* /var/log/boot.log local0.* /var/log/keepalived/keepalived.log - 之后,$
systemctl restart rsyslog重启日志服务 - 之后,$
systemctl restart keepalived重启 keepalived - 检查,$
cd /var/log/keepalived/ && ll下发现存在 keepalived.log 文件- 以后,所有的 keepalived 日志都会写在这里
Nginx 高可用原理
1 ) 原理

- 同一时刻,两台Nginx只能有一台拥有 VIP
- 当 Nginx 挂掉,KeepAlived 不会因为Nginx挂掉而转移 VIP
- 而是宕机(或KeepAlived服务退出)之后才能转移
- 我们需要写一个脚本,把 keepalived 和 Nginx 结合起来,实现服务的故障转移
- 我们需要监测nginx程序,如果nginx 宕掉,那么就触发故障转移
- 比如说,有两台Nginx服务器,准备好相同的数据,一台服务器节点宕掉之后
- 另外一台服务器节点把对应的Nginx服务给我启动起来
- 只要ip漂过来之后,对于用户来说,仍然能访问到相关服务
2 ) 脚本
- $
vim nginx_health.sh用于监测 nginx#!/bin/bash # ps -ef | grep nginx | grep -v grep &> /dev/null if [ $? -ne 0 ];then killall keepalived fi$?表示 上一行命令的执行结果
- 这里,当 Nginx 存在,执行 $
ps -ef | grep nginx | grep -v grep &> /dev/null再执行 $$?这里是 0 - 如果,Nginx 不存在,执行 $
ps -ef | grep nginx | grep -v grep &> /dev/null再执行 $$?这里是 1 (非零) - 充分说明,我们可以通过这条命令的返回值来确定 Nginx 进程是否存在
- 对脚本赋予执行权限 $
chmod +x nginx_health.sh - 两台机器都做以上处理,后续需要在 KeepAlived 配置文件中利用这样的脚本去追踪Nginx的状态
- 并且配置实现对 Nginx 的高可用,此处留下思考,不再提供细节

![[Algorithm][综合训练][体育课测验(二)][合唱队形][宵暗的妖怪]详细讲解](https://i-blog.csdnimg.cn/direct/e81daa5bca604435aca824c5dc3ee813.png)