TF-IDF是一种用于信息检索与文本挖掘的常用加权技术。它是一种统计方法,用以评估一个词语对于一个文件集或一个语料库中的其中一份文件的重要程度。它的主要思想是:如果某个词语在一篇文章中出现的频率高(Term Frequency,TF),并且在其他文章中很少出现(Inverse Document Frequency,IDF),则认为这个词语具有很好的类别区分能力,对这篇文章的内容有很好的指示作用。
1. 词频(TF)
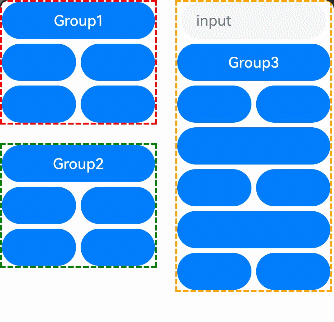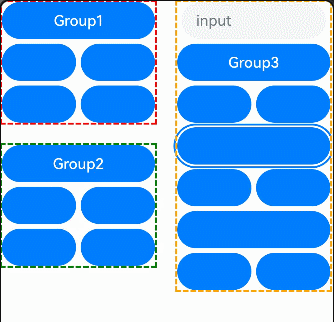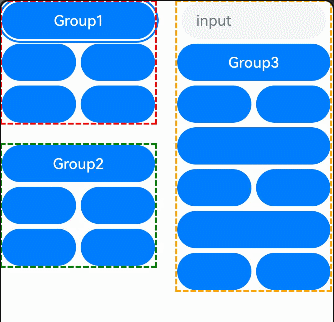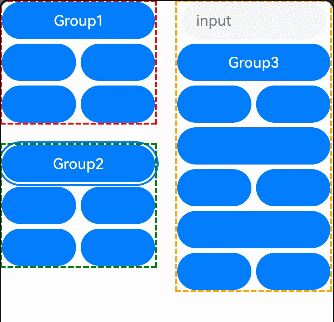
- 定义:表示词条(关键字)在文档中出现的频率。
- 计算公式:

- 目的:评估词条在文档中的重要性。
2. 逆文档频率(IDF)
- 定义:表示词条的普遍重要性。
- 计算公式:

- 目的:评估词条的稀有程度,降低常见词的权重。
3. TF-IDF
- 定义:一个词条在一个文档中的重要性与它在语料库中的稀有程度的乘积。
- 计算公式:

- 应用:通过计算文档中每个词条的TF-IDF值,可以评估词条对文档的区分能力。

4.优点:
-
简单性:TF-IDF算法易于理解和实现,不需要复杂的数学模型或机器学习技术。
-
有效性:在许多情况下,TF-IDF能够有效地捕捉文档中关键词的重要性,对于初步的文本分析和检索任务非常有效。
-
去噪能力:通过降低常见词的权重,TF-IDF减少了停用词和其他常见词对文本分析的影响。
-
无监督:TF-IDF不需要训练数据,可以应用于任何文本集合,无需事先标注。
-
多领域适用性:TF-IDF算法不依赖于特定领域的知识,因此可以应用于不同的领域和语料库。
-
可扩展性:TF-IDF可以应用于大规模文档集合,尽管计算和存储需求可能会随着文档数量的增加而增加。
5.缺点:
-
忽略词序:TF-IDF不考虑词条在文档中的位置或顺序,这可能会丢失一些语义信息。
-
对文档长度敏感:长文档可能会倾向于降低词条的权重,因为TF是基于词条出现次数的,而IDF与文档总数成反比。
-
无法捕捉同义词:TF-IDF无法识别意义相同或相近的不同词条,例如“汽车”和“轿车”可能被视为两个不同的词条。
-
无法处理多义词:TF-IDF不区分词条的不同含义,这可能导致在某些情况下权重分配不准确。
-
停用词处理:虽然TF-IDF降低了常见词的权重,但停用词的筛选需要预先进行,且不同的应用可能需要不同的停用词列表。
-
权重分配:TF-IDF的权重分配可能不是最优的,特别是在某些特定类型的文本分析任务中,可能需要更复杂的权重分配策略。
-
无法捕捉语义关系:TF-IDF不包含语义分析,无法捕捉词条之间的语义关系或上下文信息。
-
更新和维护成本:随着语料库的更新,TF-IDF模型需要重新计算,这可能在大规模数据集上是一个挑战。
6.代码实现
1.数据预处理(task2_1.txt)

#打开文件task2_1.txt并读取所有行到列表cor。
import pandas as pd
infile=open(r"task2_1.txt","r")
cor=infile.readlines() 2.导入TfidfVectorizer并初始化。
from sklearn.feature_extraction.text import TfidfVectorizer
tf=TfidfVectorizer() 3.使用TfidfVectorizer将文本数据转换为TF-IDF矩阵。
tfidf=tf.fit_transform(cor)4.获取TF-IDF模型中的词汇表。
wordlist=tf.get_feature_names_out() 5.创建一个DataFrame,其中词汇表作为索引,TF-IDF矩阵转置后的密集形式作为数据。
df=pd.DataFrame(tfidf.T.todense(),index=wordlist) 6.遍历每篇文档,创建一个字典resdict来存储每篇文档中权重最高的词条。
for k in range(len(cor)):
fea=df.iloc[:,k].to_list()
resdict={}
for i in range(0,len(wordlist)):
if df.iloc[i,k]!= 0: # 只考虑非零权重的词条
resdict[wordlist[i]]=fea[i]
# 按权重降序排序词条
resdict=sorted(resdict.items(),key=lambda x:x[1],reverse=True)
print(resdict)7.完整代码
import pandas as pd
infile=open(r"task2_1.txt","r")
cor=infile.readlines()
# 初始化TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
tf=TfidfVectorizer()
# 转换文本数据为TF-IDF矩阵
tfidf=tf.fit_transform(cor)
# 获取词汇表
wordlist=tf.get_feature_names_out()
# 创建DataFrame,将词汇表作为行索引,原始文本数据作为列
df=pd.DataFrame(tfidf.T.todense(),index=wordlist)
for k in range(len(cor)):
fea=df.iloc[:,k].to_list()
resdict={}
for i in range(0,len(wordlist)):
if df.iloc[i,k]!= 0:
resdict[wordlist[i]]=fea[i]
resdict=sorted(resdict.items(),key=lambda x:x[1],reverse=True)
print(resdict)