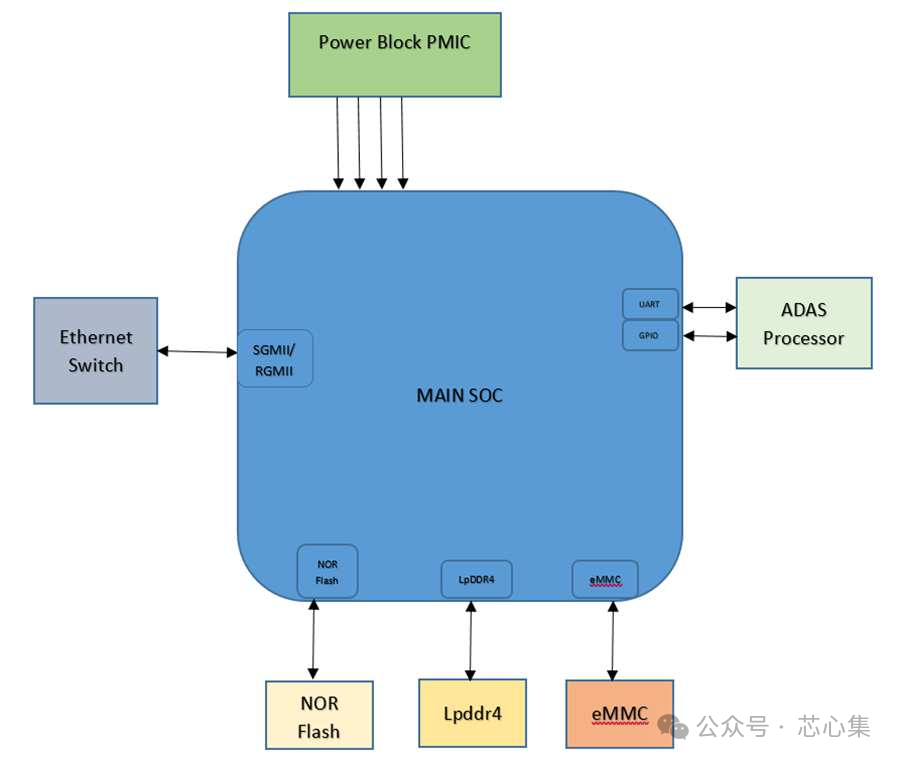
Kubernetes
Kubernetes 是一个可移植、可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化。
主要概念
- Pod:在 Kubernetes 中创建和管理的、最小的可部署的计算单元。
- Service: Service 是 将运行在一个或一组 Pod 上的网络应用程序公开为网络服务的方法。
- Deployment: 管理一组 Pod 的部署和扩展,并向应用程序提供声明性更新。
为什么使用Kubernetes?
- 可扩展性: 根据需求轻松扩展或缩小应用程序。
- 高可用性:使用所需数量的实例运行应用程序,并使其在多个节点上运行。
- 服务发现和负载平衡:Kubernetes 可以使用 DNS 名称或 IP 地址公开容器。如果容器的流量很高,Kubernetes 能够进行负载平衡并分配网络流量。
EFK Stack
EFK Stack结合了 Elasticsearch、Fluentd 和 Kibana,可聚合、存储和可视化 Kubernetes 环境中多个来源的日志。
主要组件
- Elasticsearch :分布式、RESTful 搜索和分析引擎,能够解决越来越多的用例。
- Fluentd :用于统一日志记录的开源数据收集器,它允许您统一数据收集和消费,以便更好地使用和理解数据。
- Kibana :在 Elasticsearch 之上工作的可视化层,提供用户友好的界面来可视化数据。
ELK优势
- 集中日志记录:聚合集群中所有节点和 Pod 的日志,使监控和故障排除更加容易。
- 可扩展性:Elasticsearch 可轻松扩展,使能够高效地存储和查询大量数据。
- 强大的可视化:Kibana 为您的日志数据提供强大且美观的可视化,帮助调试和了解应用程序性能。
在 Kubernetes 上部署 EFK Stack
在 Kubernetes 上部署 EFK Stack涉及设置每个组件用来协作。本文章将遵循使用清单文件的手动部署方法。

部署Elasticsearch
Elasticsearch - EFK Stack的后端 - 基本上是一个基于文档的 NoSQL 数据库,默认在端口 9200 上运行。
Elasticsearch 不仅存储数据,还通过利用复制来确保数据持久性和故障恢复。为了确保数据的快速可用性,除了复制之外,它还使用分片。
在elasticsearch集群中,它是协调操作和管理更改的主节点。
apiVersion: apps/v1
kind: Deployment
metadata:
name: elasticsearch
spec:
replicas: 2
selector:
matchLabels:
component: elasticsearch
template:
metadata:
labels:
component: elasticsearch
spec:
containers:
- name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch:7.9.3
ports:
- containerPort: 9200
部署Fluentd
Fluentd - 日志传送器 - 利用各种插件来过滤和转换日志数据。这些插件在 fluidd 配置文件中定义,该文件使用 .conf 扩展名。
Fluentd 使用内存缓冲机制来确保可靠地将日志传送到 Elasticsearch。
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluent.conf: |
<match **>
@type elasticsearch
host elasticsearch
port 9200
logstash_format true
</match>
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
labels:
app: fluentd
spec:
selector:
matchLabels:
name: fluentd
template:
metadata:
labels:
name: fluentd
spec:
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1.14.6-debian-elasticsearch7-1.0
volumeMounts:
- name: fluentd-config
mountPath: /fluentd/etc/fluent.conf
subPath: fluent.conf
- name: varlog
mountPath: /var/log
volumes:
- name: fluentd-config
configMap:
name: fluentd-config
- name: varlog
hostPath:
path: /var/log
部署Kibana
Kibana - 可视化 - 通过图形和图表提供广泛的数据呈现功能,默认在端口 5601 上运行。
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
spec:
replicas: 1
selector:
matchLabels:
component: kibana
template:
metadata:
labels:
component: kibana
spec:
containers:
- name: kibana
image: docker.elastic.co/kibana/kibana:7.9.3
ports:
- containerPort: 5601
在 Kubernetes 上部署 Elasticsearch
设置StatefulSet
StatefulSet 非常适合 Elasticsearch 等有状态应用程序。它们为每个 Pod 提供稳定、唯一的网络标识符和持久存储。
创建StatefulSet
下面是 Elasticsearch 的 StatefulSet 定义的基本示例。
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: elasticsearch
spec:
serviceName: "elasticsearch"
replicas: 3
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch:7.9.3
ports:
- containerPort: 9200
name: es-http
volumeMounts:
- name: es-data
mountPath: /usr/share/elasticsearch/data
volumeClaimTemplates:
- metadata:
name: es-data
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 10Gi
此 YAML 文件定义了一个名为 elasticsearch 的 StatefulSet,具有三个副本。它指定使用 Elasticsearch 7.9.3 Image
和数据存储的PVC。
配置PV
- 持久卷 (PV):表示集群中由管理员配置或使用存储类动态配置的一块存储。
- 持久卷声明 (PVC):用户对存储的请求。它指定大小和访问模式,并且可以链接到特定的 PV。
volumeClaimTemplates:
- metadata:
name: es-data
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 10Gi
此配置为每个 Elasticsearch Pod 请求具有 ReadWriteOnce 访问模式的 10Gi 卷。如果设置了动态配置或将 PVC 绑定到手动创建的 PV,则 Kubernetes 集群会自动配置此存储。
设置SVC
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
spec:
selector:
app: elasticsearch
ports:
- port: 9200
targetPort: es-http
type: ClusterIP
此 YAML 文件创建一个名为 elasticsearch 的服务,该服务以标签为 app:elasticsearch 的 Pod 为目标。它使得 Elasticsearch HTTP API 在集群内可以通过服务的集群 IP 进行访问。
在 Kubernetes 上部署 Fluentd
通过DaemonSet部署Fluentd
DaemonSet 确保 pod 的副本在集群中的每个节点上运行。这非常适合日志收集,因为我们希望 Fluentd 从每个节点收集日志。
创建配置
首先,创建一个 Fluentd 配置文件(例如 fluentd-config.conf),指定如何收集和转发日志。
<source>
@type forward
port 24224
bind 0.0.0.0
</source>
<match **>
@type elasticsearch
host elasticsearch.default.svc.cluster.local
port 9200
logstash_format true
</match>
- source: 输入源
- match: 输出地址
- filter: 事件处理pipeline
- system: 系统范围配置
- label: 对输出和过滤器进行分组以进行内部路由
- worker:限制特定的工作节点
- @include: 包含其他文件
定义DaemonSet
fluentd-daemonset.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: kube-system
spec:
selector:
matchLabels:
name: fluentd
template:
metadata:
labels:
name: fluentd
spec:
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1.11-debian-elasticsearch
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch.default.svc.cluster.local"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
volumeMounts:
- name: varlog
mountPath: /var/log
- name: dockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
volumes:
- name: varlog
hostPath:
path: /var/log
- name: dockercontainers
hostPath:
path: /var/lib/docker/containers
配置Fluentd对集群日志进行处理
Fluentd 需要配置为从 Kubernetes 节点和 Pod 收集日志。之前在 fluentd-config.conf 中定义的配置设置 Fluentd 监听日志并将其转发到 Elasticsearch。
Node Logs
DaemonSet 配置将 /var/log 目录从主机挂载到 Fluentd 容器中,允许 Fluentd 从节点访问和收集系统和应用程序日志。
Pod Logs
同样,挂载 /var/lib/docker/containers 使 Fluentd 能够从 Docker 容器收集日志,包括由 Kubernetes Pod 管理的容器。
Forwarding Logs to Elasticsearch
Fluentd 配置指定 Elasticsearch 作为日志的目标。确保 Elasticsearch 正在运行并且可以从 Kubernetes 集群内访问。
<match **>
@type elasticsearch
host elasticsearch.default.svc.cluster.local
port 9200
logstash_format true
</match>
上述配置将所有收集的日志转发到 Elasticsearch,在那里可以对日志进行索引并使其可搜索。
使用了输出插件 Fluent-plugin-elasticsearch,该插件用于将数据转发到 Elasticsearch。匹配部分显示它使用的参数。
在 Kubernetes 上部署 Kibana
部署Kibana
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
spec:
replicas: 1
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: docker.elastic.co/kibana/kibana:7.10.0
env:
- name: ELASTICSEARCH_HOSTS
value: "http://elasticsearch:9200"
ports:
- containerPort: 5601
此 YAML 文件定义了一个名为 kibana 的具有单个副本的部署。它使用官方 Kibana 映像并通过 ELASTICSEARCH_HOSTS 环境变量连接到 Elasticsearch。
Kibana 默认使用端口 5601,并使用 HTTP REST API 与 ELasticsearch 进行通信。为了保护 Kibana,应启用 Elasticsearch 的安全功能。
apiVersion: v1
kind: Service
metadata:
name: kibana
spec:
type: NodePort
ports:
- port: 5601
targetPort: 5601
nodePort: 30001
selector:
app: kibana
Service在 NodePort 上公开 Kibana,以便从集群外部进行访问。
Monitoring && Alerting
监控 EFK Stack有助于确保日志系统以最佳性能运行。以便尽早检测问题,例如 Elasticsearch 存储空间不足或 Fluentd 遇到高延迟。

Prometheus with EFK
Prometheus 是一个用于收集和存储指标的开源监控解决方案。将 Prometheus 与 EFK Stack集成能够收集有关每个组件的性能和运行状况的指标。
Prometheus 允许每个作业的抓取间隔配置,这在抓取哪些目标以及抓取频率方面提供了极大的灵活性。
设置Prometheus
首先,在 Kubernetes 集群中安装 Prometheus。可以使用 Prometheus Operator 来更轻松地管理。
kubectl create -f https://raw.githubusercontent.com/prometheus-operator/prometheus-operator/master/bundle.yaml
配置Prometheus监控EFK
- 使用 elasticsearch-exporter 将 Elasticsearch Metrics公开给 Prometheus
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: elasticsearch-exporter
labels:
team: backend
spec:
selector:
matchLabels:
app: elasticsearch-exporter
endpoints:
- port: http
- Fluentd Metrics可以使用内置的 Prometheus 插件公开。
<source>
@type prometheus
port 24231
</source>
- Kibana 本身并不导出 Prometheus Metrcis,但可以使用 kibana-prometheus-exporter 插件。
Grafana可视化
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: grafana
name: grafana
spec:
selector:
matchLabels:
app: grafana
template:
metadata:
labels:
app: grafana
spec:
securityContext:
fsGroup: 472
supplementalGroups:
- 0
containers:
- name: grafana
image: grafana/grafana:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3000
name: http-grafana
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /robots.txt
port: 3000
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 30
successThreshold: 1
timeoutSeconds: 2
livenessProbe:
failureThreshold: 3
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
tcpSocket:
port: 3000
timeoutSeconds: 1
resources:
requests:
cpu: 250m
memory: 750Mi
volumeMounts:
- mountPath: /var/lib/grafana
name: grafana-pv
volumes:
- name: grafana-pv
persistentVolumeClaim:
claimName: grafana-pvc
---
apiVersion: v1
kind: Service
metadata:
name: grafana
spec:
ports:
- port: 3000
protocol: TCP
targetPort: http-grafana
selector:
app: grafana
sessionAffinity: None
type: LoadBalancer
Note: 这是一个示例片段。要尝试执行任务,请使用相应任务语句中提供的 URL。
配置Alerting
Prometheus Alertmanager 可以管理 Prometheus 发送的警报。根据 EFK Metrics定义警报规则。
例如,如果 Elasticsearch 的堆使用率过高,则创建警报。
groups:
- name: elasticsearch-alerts
rules:
- alert: ElasticsearchHighHeapUsage
expr: elasticsearch_jvm_memory_used_bytes / elasticsearch_jvm_memory_max_bytes > 0.9
for: 5m
labels:
severity: critical
annotations:
summary: "High Heap Usage (instance {{ $labels.instance }})"
description: "Elasticsearch node {{ $labels.node }} heap usage is above 90%."
设置 Alertmanager 以在触发警报时通过电子邮件、Slack 或其他渠道发送通知。
global:
resolve_timeout: 5m
route:
receiver: 'slack-notifications'
receivers:
- name: 'slack-notifications'
slack_configs:
- channel: '#alerts'