欢迎一起讨论
- 论文地址
- 综述
- 介绍部分核心翻译
- 翻译
- 解释重要的信息
- 元素和实体的关系(包含和被包含,而非相等)
- Graph Index(图索引)
- Community Detection(社区检测)
- Query-Focused Summarization(查询聚焦的摘要)
- Global Answer(全局答案)
- Graph RAG 方法与流程核心翻译以及解释
- Source Documents → Text Chunks
- 翻译
- 召回率与精确度的平衡
- Text Chunks → Element Instances
- 翻译
- 重要信息解释
- 为什么需要“少量示例”(Few-shot Learning)?
- 补充提取(Gleanings)
- 简单的示例(非官方仅为了理解)
- Element Instances → Element Summaries
- 原文大意
- 重要概念解释
- 抽象总结(前一步也有涉及)
- 将多个实例总结为一个整体
- 重复实体的问题以及解决方案、
- Element Summaries → Graph Communities
- 原文大意
- 重要概念解释
- 创建的图索引
- 为什么使用社区检测?
- 层次结构和全局摘要
- Graph Communities → Community Summaries
- 原文概述
- Leiden算法的社区层次
- Community Summaries → Community Answers → Global Answer
- 原文大意
- 其他部分需要代码
论文地址
点我下载
翻译是谷歌翻译+人为纠正了一部分,有的地方感觉还是英文会好点。解释部分为个人理解以及对论文的一定补充,因为不是论文可能并不是针对大众的/
综述
该文章的主要内容和分析:
- 研究背景
传统RAG是一种通过从外部知识库中检索相关信息来增强生成能力的技术,但它在处理针对整个文本语料库的全局问题时表现不佳。本文提出的 Graph RAG 方法旨在结合 RAG 的优点和图索引的结构化特性,以应对这些挑战。 - 方法概述
Graph RAG 方法将文档集转化为一个知识图谱,并通过大语言模型(LLM)生成社区摘要。在用户提出问题时,系统通过摘要生成部分答案,并将这些答案汇总为最终的全局答案。这种方法特别适用于需要理解数据集全局主题的查询任务。 - 主要流程
文档处理与图谱构建:首先,将文档分割成小块,提取其中的实体及其关系,生成图谱。
社区检测与摘要生成:利用社区检测算法(如Leiden算法)对图谱进行分区,并生成每个社区的摘要。
问题解答:通过并行处理生成各个社区的部分答案,并最终整合这些答案生成全局答案。 - 实验与评估
该方法在两个不同的真实世界数据集上进行了评估,包括播客转录文本和新闻文章。实验表明,与传统的 RAG 方法相比,Graph RAG 在回答的全面性和多样性方面表现更好,尤其是在处理复杂的全局性问题时。 - 贡献与局限性
Graph RAG 方法的一个显著优势是能够有效处理超出 LLM 上下文窗口大小的庞大数据集,同时生成多样且全面的答案。然而,文章也指出,这种方法在某些场景下可能并不总是优于直接的文本摘要方法,并且其效果在不同类型的数据集和查询上可能有所不同。
介绍部分核心翻译
翻译
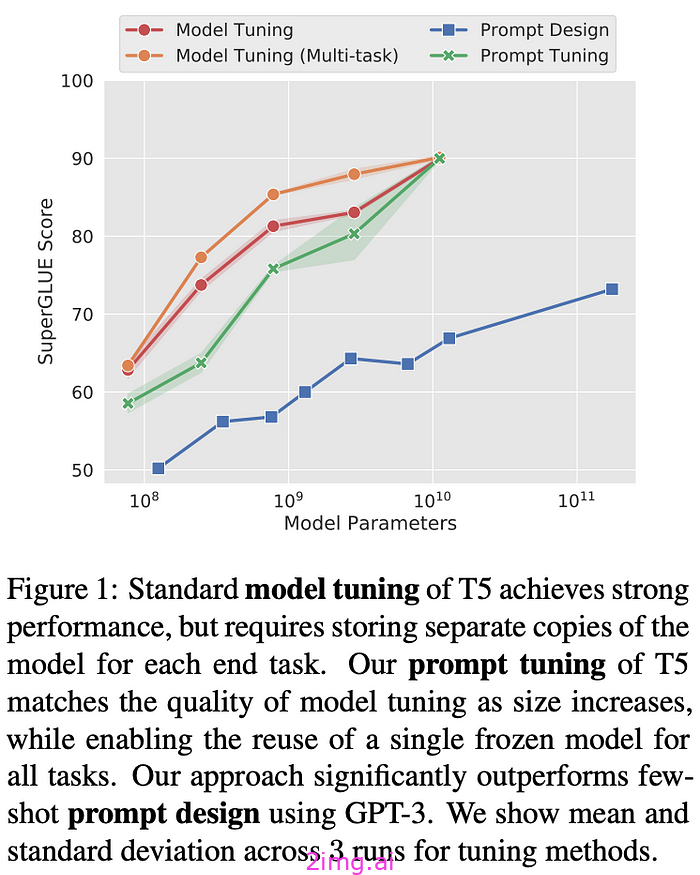
人类在各个领域的成就依赖于我们阅读和推理大量文档的能力,这种能力通常能得出超越文本本身所陈述内容的结论。微软根据上图结论和自身的数据,做了下图的尝试。

Graph RAG 管道使用了由 LLM 生成的源文档文本的图索引。这个索引包含了节点(例如实体)、边(例如关系)和协变量(例如声明),这些元素通过针对数据集领域的 LLM 提示被检测、提取并总结出来。社区检测(例如 Leiden 算法,Traag 等,2019)被用来将图索引划分为若干元素组(节点、边、协变量),LLM 可以在索引时和查询时并行地总结这些元素组。对于给定查询的“全局答案”是通过对所有与该查询相关的社区摘要进行最终一轮的查询聚焦总结后生成的。
解释重要的信息
元素和实体的关系(包含和被包含,而非相等)
“元素”(elements)和“实体”(entities)是相关但不同的概念。具体来说:
- 实体(Entities)
实体是图中的基本构建块,通常表示具体的对象或概念。比如,在文档中,实体可以是“人”、“地点”、“组织”等。实体在图中被表示为节点。 - 元素(Elements)
元素是一个更广泛的概念,它包括了图中的实体(节点)、关系(边)以及协变量(如声明、描述等附加信息)。因此,实体是元素的一种,而元素还包含了与实体相关的其他信息。
关系:
实体 是 元素 的一种,所有的实体都是元素,但并不是所有的元素都是实体。
在图索引中,实体通过它们之间的关系连接在一起,这些关系也是元素的一部分。
协变量则是与这些实体和关系相关的附加信息,它们同样属于元素的范畴。
总结来说,实体是图中具体的对象,而元素则包括了实体以及与实体相关的关系和其他附加信息。在Graph RAG方法中,LLM会提取这些元素,构建起整个图索引,以便后续的查询处理和答案生成。
Graph Index(图索引)
图索引 是通过将文档内容转换为图的形式来表示数据。图中的节点表示实体(如人物、地点等),边表示这些实体之间的关系,协变量(如声明)则是附加的上下文信息。这个图索引为后续的查询处理提供了结构化的数据基础。
Community Detection(社区检测)
社区检测是一种图分析技术,用于识别图中密切相关的节点群体。Graph RAG 使用社区检测算法(如 Leiden 算法)来将图索引划分为多个社区,每个社区包含紧密关联的元素。这种划分有助于在并行处理时更加高效地生成摘要和答案。
Query-Focused Summarization(查询聚焦的摘要)
查询聚焦的摘要 是指根据用户的具体查询,从相关的社区摘要中提取信息,并生成一个针对该查询的总结性回答。这一步骤是将多个社区的部分答案整合为一个全局答案的关键。
Global Answer(全局答案)
全局答案 是对给定查询的最终回答。它是在对所有相关社区的摘要进行查询聚焦的总结后生成的,目的是提供一个全面且有针对性的答案,涵盖与查询相关的所有重要信息。
Graph RAG 方法与流程核心翻译以及解释
Source Documents → Text Chunks
翻译
一个基本的设计决策是确定从源文档中提取的输入文本应被分割为多大粒度的文本块进行处理。在接下来的步骤中,这些文本块将被传递给一组用于提取图索引各种元素的大型语言模型(LLM)提示。较大的文本块需要较少的LLM调用来进行这种提取,但较长的LLM上下文窗口会导致召回率的下降(Kuratov等,2024;Liu等,2023)。这种现象可以在图2中观察到,图中展示了一个单轮提取(即无补充提取)的情况:在一个样本数据集(HotPotQA,Yang等,2018)上,使用600个token的文本块几乎提取了两倍于使用2400个token文本块的实体引用。尽管更多的引用通常更好,但任何提取过程都需要在召回率和精确度之间为目标活动找到平衡。
召回率与精确度的平衡
召回率(Recall) 指的是系统能够识别并提取到所有相关信息的能力。较高的召回率意味着系统提取到了更多的实体或信息。
精确度(Precision) 指的是系统提取到的内容中有多少是真正相关的,较高的精确度意味着提取结果中噪音较少。
在文本块的选择中,设计者需要在召回率和精确度之间找到一个平衡点:
大文本块可能导致高精度但低召回率,因为系统可能漏掉一些重要的信息。
小文本块可能提高召回率,但也有可能带来一些无关的信息,影响精确度。
Text Chunks → Element Instances
翻译
这一步的基本要求是识别并提取源文本块中的图节点和边的实例。我们使用一个多部分的LLM提示来完成此操作,首先识别文本中的所有实体,包括它们的名称、类型和描述,然后再识别所有显然相关的实体之间的关系,包括源实体和目标实体以及它们关系的描述。两种类型的元素实例都以分隔的元组列表形式输出。
根据文档语料库的领域特点调整这个提示的主要机会在于为LLM提供用于上下文学习的少量示例的选择(Brown等,2020)。例如,虽然我们默认的提示可以适用于广泛的“命名实体”类别(如人物、地点、组织),但具有专业知识的领域(例如科学、医学、法律)将受益于专门针对这些领域的少量示例。我们还支持一个次要的提取提示,用于提取我们希望与提取的节点实例关联的任何额外协变量。我们默认的协变量提示旨在提取与检测到的实体相关的声明,包括主语、宾语、类型、描述、源文本范围以及开始和结束日期。
为了平衡效率和质量的需求,我们使用了多轮“补充提取”(gleanings),最多达到指定的最大轮次,以鼓励LLM检测到在先前提取轮次中可能遗漏的额外实体。这是一个多阶段过程,首先我们要求LLM评估是否提取了所有实体,使用100的logit偏差强制其做出是/否决定。如果LLM响应说有实体被遗漏,那么继续提示“在上一次提取中遗漏了许多实体”,以鼓励LLM补充提取这些遗漏的实体。这种方法使我们能够在使用较大文本块的情况下不降低质量(如图2所示),也不会引入不必要的噪音。
重要信息解释
为什么需要“少量示例”(Few-shot Learning)?
少量示例学习:LLM的能力可以通过提供几个示例来提升。这些示例告诉模型我们具体想提取哪些信息。比如,如果我们处理的是法律文本,我们可以给LLM几个示例,告诉它如何识别法律条款和相关的法律关系。
领域适应:不同领域的文本往往有自己特定的术语和结构,因此在不同领域,提供一些有针对性的示例可以显著提高模型的提取准确性。
补充提取(Gleanings)
多轮提取:有时候,模型在第一次提取时可能会遗漏一些信息。为了尽量减少这种遗漏,我们会让模型多次扫描同一个文本块,每次尝试提取更多的信息。
补充提取的过程:每次提取后,模型会判断是否有遗漏,如果有,它会在下一轮中尝试“补充”那些遗漏的实体和关系。这种方法可以确保即使我们使用较大的文本块,也能保持较高的提取质量。
简单的示例(非官方仅为了理解)
测试环境:python3.10.14 windows 某大模型API 提示词为官方提供
假设文本:
“苹果公司的CEO是蒂姆·库克。他在2020年领导公司推出了多款新产品。”
那么经过这一步提取出来的就是:

Element Instances → Element Summaries
原文大意
使用大型语言模型(LLM)来“提取”源文本中表示的实体、关系和声明的描述,本身已经是一种抽象总结的形式,它依赖于LLM创建出独立且有意义的概念摘要,这些概念可能是隐含的而不是文本中明确表述的(例如隐含关系的存在)。要将所有这些实例级别的摘要转换为每个图元素(即实体节点、关系边和声明协变量)的单一描述性文本块,需要进一步对匹配的实例组进行LLM摘要。
在这一阶段,可能的担忧是,LLM可能不会始终以相同的文本格式提取对同一实体的引用,导致出现重复的实体元素,从而在实体图中生成重复的节点。然而,由于在接下来的步骤中,所有密切相关的实体“社区”将被检测和总结,并且鉴于LLM能够理解多种名称变体背后的共同实体,我们的方法能够应对这种变体,只要所有变体都足够密切地连接到一组相关实体。
总体来说,我们在潜在噪声较大的图结构中使用丰富的描述性文本来表示同质节点,这与LLM的能力以及全局、查询聚焦摘要的需求相一致。这些特性也使得我们的图索引区别于典型的知识图谱,后者依赖于简明一致的知识三元组(主语、谓语、宾语)来进行下游推理任务。
重要概念解释
抽象总结(前一步也有涉及)
在这个过程中,LLM实际上是在对这些信息进行抽象总结。这意味着它不仅仅是从文本中逐字逐句地复制信息,而是根据文本的整体含义生成一个简洁且有意义的描述。比如,文本中可能没有明确说出两个实体之间的关系,但LLM可以根据上下文推断出这种关系并生成相应的描述。
将多个实例总结为一个整体
在提取出这些信息后,我们希望将相同或类似的实例合并为一个整体的描述。比如,如果多次提到“苹果公司”和“库克”的关系,我们希望最终生成一个统一的描述来代表这个关系,而不是有很多重复的信息。
重复实体的问题以及解决方案、
在这个大标题的执行过程中,可能会遇到一个问题:同一个实体(比如“苹果公司”)可能会在不同的地方以不同的格式或名称出现(比如“Apple Inc.”、“苹果公司”、“Apple”),LLM可能会认为它们是不同的实体,导致生成了多个重复的实体节点。
解决方案:后续步骤中会使用一种称为社区检测的技术。这种技术可以识别并合并那些密切相关的实体和关系,即使它们的名称或描述略有不同。因为LLM有能力识别这些变体背后的共同点,所以我们的整体方法可以处理这些差异,并将它们合并为一个统一的实体。
Element Summaries → Graph Communities
原文大意
在前一步中创建的索引可以建模为一个同质的无向加权图,其中实体节点通过关系边相连,边的权重表示检测到的关系实例的标准化计数。给定这样一个图,可以使用各种社区检测算法将图划分为社区,这些社区中的节点彼此之间的连接比与图中其他节点的连接更强(例如,参见Fortunato, 2010 和 Jin et al., 2021 的综述)。在我们的流程中,我们使用Leiden算法(Traag等,2019),因为它能够高效地恢复大规模图的层次社区结构(见图3)。这个层次结构的每个级别都提供了一个社区划分,这些划分覆盖了图中的所有节点,且相互排斥并集体穷尽,使得能够通过分而治之的方法进行全局摘要。
重要概念解释
创建的图索引
在前一步中,我们通过提取文本中的实体(如人、地点、公司等)和它们之间的关系,构建了一个图。这张图的结构可以表示为一个同质的无向加权图。
同质(Homogeneous):这意味着图中的所有节点(实体)和边(关系)都是相同类型的。换句话说,所有节点都是“实体”,所有边都是“关系”。
无向(Undirected):无向图意味着节点之间的连接(边)没有方向性,表示关系是双向的。例如,A和B之间的关系在无向图中表示为A-B,而不是A→B或B→A。
加权(Weighted):加权图中的边具有一个数值权重。在这里,边的权重表示检测到的关系实例的标准化计数(normalized counts)。也就是说,某个关系出现的次数越多,权重就越高。
为什么使用社区检测?
1.社区检测可以帮助我们将复杂的图划分为多个较小的部分,这样做有几个好处:
简化处理:通过将图划分为社区,我们可以分而治之,分别处理每个社区的信息,从而简化处理流程。
提高准确性:社区中的节点关系密切,因此在生成摘要或处理信息时,可以集中关注每个社区内部的关系,提高信息处理的准确性。
2.解决之前说的重复实体的问题
层次结构和全局摘要
Leiden算法生成的层次结构提供了图的多层次划分。每个层次都对图中的所有节点进行划分,这些划分是相互排斥且集体穷尽的,即每个节点只属于一个社区,且所有节点都被划分在某个社区中。
这种层次化的社区结构使得我们可以使用分而治之的策略来进行全局摘要。也就是说,我们可以先在较小的社区中生成摘要,然后逐步汇总这些社区的摘要,最终生成整个图的全局摘要
Graph Communities → Community Summaries
原文概述
社区摘要的目的:生成的社区摘要帮助用户理解数据集的全局结构和语义,即使在没有具体查询的情况下,这些摘要也有助于理解数据集。用户可以通过浏览不同层次的社区摘要,了解整体主题,并深入到更详细的子主题。
摘要生成方法:摘要生成分为不同层次,包括根社区(最高层次)和叶社区(最低层次)。在叶社区中,系统优先考虑重要的节点和边,逐步将它们加入到模型的上下文窗口中,直到达到上下文窗口的限制。在更高层次的社区中,如果所有元素摘要都能适应上下文窗口,则直接生成总结;如果不能,则通过替换较长的摘要来确保摘要适应上下文窗口。
总结的应用:这些社区摘要在图形索引中作为回答全局查询的关键部分,通过分层次的摘要帮助系统有效地处理和回答复杂的查询。
Leiden算法的社区层次
Leiden算法生成的社区是分层次的,通常有多个层次:
根社区(Root communities):这些是图中最顶层的社区,包含了较大的主题或群体。我们称之为层次0。
叶社区(Leaf-level communities):这些是最低层次的社区,包含了最具体的子群体或主题。我们称之为层次1及以下。
Community Summaries → Community Answers → Global Answer
原文大意
首先,我们把之前生成的社区摘要随机打乱,并将它们分成预先规定大小的“小块”。这样做是为了确保信息均匀分布在这些块中,避免所有重要信息集中在一个地方,导致在处理时可能会被忽略。
生成中间答案:
然后,我们会让LLM(大型语言模型)根据每个小块生成一个中间答案。这是一个并行处理的过程,也就是说,每个小块会同时被处理。
每个生成的答案都会得到一个0到100分的分数,这个分数表示这个答案对回答用户问题的帮助程度。分数为0的答案会被过滤掉,因为它们对回答问题没有帮助。
合成最终答案:
最后,我们会根据这些中间答案的帮助程度(分数)来排序,从最有帮助的答案开始,把它们逐个放入一个新的上下文窗口,直到达到token(即字数或词数)的限制。
这个新窗口中的内容就是我们为用户生成的最终答案,并会把它返回给用户
其他部分需要代码
后续对大家有帮助的话,会手撕代码。