目录
- 引言
- 环境
- 步骤
- 1. 安装 docker
- 2. 启动 docker
- 3. 浏览器访问
- 4. One API 配置语言模型、向量模型渠道和令牌
- 5. 创建 FastGPT 知识库
- 6. 创建 FastGPT 应用
- 官方文档
引言
部署之前可以先看一下 RAG 技术原理,也可以后面回过头来看,对一些概念有些了解,对部署的内容会有更好的理解
环境
- Windows 10
- docker 27.0.3
- fastgpt v4.8.9
- oneapi v0.6.7
步骤
1. 安装 docker
docker官网:https://www.docker.com/
版本:Docker version 27.0.3(cmd命令 docker --version)
2. 启动 docker
打开 docker 软件(切记先打开再进行下面的操作)
创建一个 FastGPT 空文件夹,存放以下两个配置文件
config.json
// 已使用 json5 进行解析,会自动去掉注释,无需手动去除
{
"feConfigs": {
"lafEnv": "https://laf.dev" // laf环境。 https://laf.run (杭州阿里云) ,或者私有化的laf环境。如果使用 Laf openapi 功能,需要最新版的 laf 。
},
"systemEnv": {
"vectorMaxProcess": 15,
"qaMaxProcess": 15,
"pgHNSWEfSearch": 100 // 向量搜索参数。越大,搜索越精确,但是速度越慢。设置为100,有99%+精度。
},
"llmModels": [
{
"model": "gpt-4o-mini", // 模型名(对应OneAPI中渠道的模型名)
"name": "gpt-4o-mini", // 模型别名
"avatar": "/imgs/model/openai.svg", // 模型的logo
"maxContext": 125000, // 最大上下文
"maxResponse": 16000, // 最大回复
"quoteMaxToken": 120000, // 最大引用内容
"maxTemperature": 1.2, // 最大温度
"charsPointsPrice": 0, // n积分/1k token(商业版)
"censor": false, // 是否开启敏感校验(商业版)
"vision": true, // 是否支持图片输入
"datasetProcess": true, // 是否设置为知识库处理模型(QA),务必保证至少有一个为true,否则知识库会报错
"usedInClassify": true, // 是否用于问题分类(务必保证至少有一个为true)
"usedInExtractFields": true, // 是否用于内容提取(务必保证至少有一个为true)
"usedInToolCall": true, // 是否用于工具调用(务必保证至少有一个为true)
"usedInQueryExtension": true, // 是否用于问题优化(务必保证至少有一个为true)
"toolChoice": true, // 是否支持工具选择(分类,内容提取,工具调用会用到。目前只有gpt支持)
"functionCall": false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式)
"customCQPrompt": "", // 自定义文本分类提示词(不支持工具和函数调用的模型
"customExtractPrompt": "", // 自定义内容提取提示词
"defaultSystemChatPrompt": "", // 对话默认携带的系统提示词
"defaultConfig": {} // 请求API时,挟带一些默认配置(比如 GLM4 的 top_p)
},
{
"model": "gpt-4o",
"name": "gpt-4o",
"avatar": "/imgs/model/openai.svg",
"maxContext": 125000,
"maxResponse": 4000,
"quoteMaxToken": 120000,
"maxTemperature": 1.2,
"charsPointsPrice": 0,
"censor": false,
"vision": true,
"datasetProcess": false,
"usedInClassify": true,
"usedInExtractFields": true,
"usedInToolCall": true,
"usedInQueryExtension": true,
"toolChoice": true,
"functionCall": false,
"customCQPrompt": "",
"customExtractPrompt": "",
"defaultSystemChatPrompt": "",
"defaultConfig": {}
}
],
"vectorModels": [
{
"model": "text-embedding-ada-002", // 模型名(与OneAPI对应)
"name": "Embedding-2", // 模型展示名
"avatar": "/imgs/model/openai.svg", // logo
"charsPointsPrice": 0, // n积分/1k token
"defaultToken": 700, // 默认文本分割时候的 token
"maxToken": 3000, // 最大 token
"weight": 100, // 优先训练权重
"defaultConfig": {}, // 自定义额外参数。例如,如果希望使用 embedding3-large 的话,可以传入 dimensions:1024,来返回1024维度的向量。(目前必须小于1536维度)
"dbConfig": {}, // 存储时的额外参数(非对称向量模型时候需要用到)
"queryConfig": {} // 参训时的额外参数
},
{
"model": "text-embedding-3-large",
"name": "text-embedding-3-large",
"avatar": "/imgs/model/openai.svg",
"charsPointsPrice": 0,
"defaultToken": 512,
"maxToken": 3000,
"weight": 100,
"defaultConfig": {
"dimensions": 1024
}
},
{
"model": "text-embedding-3-small",
"name": "text-embedding-3-small",
"avatar": "/imgs/model/openai.svg",
"charsPointsPrice": 0,
"defaultToken": 512,
"maxToken": 3000,
"weight": 100
}
],
"reRankModels": [],
"audioSpeechModels": [
{
"model": "tts-1",
"name": "OpenAI TTS1",
"charsPointsPrice": 0,
"voices": [
{ "label": "Alloy", "value": "alloy", "bufferId": "openai-Alloy" },
{ "label": "Echo", "value": "echo", "bufferId": "openai-Echo" },
{ "label": "Fable", "value": "fable", "bufferId": "openai-Fable" },
{ "label": "Onyx", "value": "onyx", "bufferId": "openai-Onyx" },
{ "label": "Nova", "value": "nova", "bufferId": "openai-Nova" },
{ "label": "Shimmer", "value": "shimmer", "bufferId": "openai-Shimmer" }
]
}
],
"whisperModel": {
"model": "whisper-1",
"name": "Whisper1",
"charsPointsPrice": 0
}
}
docker-compose.yml
# 数据库的默认账号和密码仅首次运行时设置有效
# 如果修改了账号密码,记得改数据库和项目连接参数,别只改一处~
# 该配置文件只是给快速启动,测试使用。正式使用,记得务必修改账号密码,以及调整合适的知识库参数,共享内存等。
# 如何无法访问 dockerhub 和 git,可以用阿里云(阿里云没有arm包)
version: '3.3'
services:
# db
pg:
image: pgvector/pgvector:0.7.0-pg15 # docker hub
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.7.0 # 阿里云
container_name: pg
restart: always
ports: # 生产环境建议不要暴露
- 5432:5432
networks:
- fastgpt
environment:
# 这里的配置只有首次运行生效。修改后,重启镜像是不会生效的。需要把持久化数据删除再重启,才有效果
- POSTGRES_USER=username
- POSTGRES_PASSWORD=password
- POSTGRES_DB=postgres
volumes:
- ./pg/data:/var/lib/postgresql/data
mongo:
image: mongo:5.0.18 # dockerhub
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mongo:5.0.18 # 阿里云
# image: mongo:4.4.29 # cpu不支持AVX时候使用
container_name: mongo
restart: always
ports:
- 27017:27017
networks:
- fastgpt
command: mongod --keyFile /data/mongodb.key --replSet rs0
environment:
- MONGO_INITDB_ROOT_USERNAME=myusername
- MONGO_INITDB_ROOT_PASSWORD=mypassword
volumes:
- ./mongo/data:/data/db
entrypoint:
- bash
- -c
- |
openssl rand -base64 128 > /data/mongodb.key
chmod 400 /data/mongodb.key
chown 999:999 /data/mongodb.key
echo 'const isInited = rs.status().ok === 1
if(!isInited){
rs.initiate({
_id: "rs0",
members: [
{ _id: 0, host: "mongo:27017" }
]
})
}' > /data/initReplicaSet.js
# 启动MongoDB服务
exec docker-entrypoint.sh "$$@" &
# 等待MongoDB服务启动
until mongo -u myusername -p mypassword --authenticationDatabase admin --eval "print('waited for connection')" > /dev/null 2>&1; do
echo "Waiting for MongoDB to start..."
sleep 2
done
# 执行初始化副本集的脚本
mongo -u myusername -p mypassword --authenticationDatabase admin /data/initReplicaSet.js
# 等待docker-entrypoint.sh脚本执行的MongoDB服务进程
wait $$!
# fastgpt
sandbox:
container_name: sandbox
image: ghcr.io/labring/fastgpt-sandbox:latest # git
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:latest # 阿里云
networks:
- fastgpt
restart: always
fastgpt:
container_name: fastgpt
image: ghcr.io/labring/fastgpt:v4.8.9 # git
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.8.9 # 阿里云
ports:
- 3000:3000
networks:
- fastgpt
depends_on:
- mongo
- pg
- sandbox
restart: always
environment:
# root 密码,用户名为: root。如果需要修改 root 密码,直接修改这个环境变量,并重启即可。
- DEFAULT_ROOT_PSW=1234
# AI模型的API地址哦。务必加 /v1。这里默认填写了OneApi的访问地址。
- OPENAI_BASE_URL=http://oneapi:3000/v1
# AI模型的API Key。(这里默认填写了OneAPI的快速默认key,测试通后,务必及时修改)
- CHAT_API_KEY=sk-fastgpt
# 数据库最大连接数
- DB_MAX_LINK=30
# 登录凭证密钥
- TOKEN_KEY=any
# root的密钥,常用于升级时候的初始化请求
- ROOT_KEY=root_key
# 文件阅读加密
- FILE_TOKEN_KEY=filetoken
# MongoDB 连接参数. 用户名myusername,密码mypassword。
- MONGODB_URI=mongodb://myusername:mypassword@mongo:27017/fastgpt?authSource=admin
# pg 连接参数
- PG_URL=postgresql://username:password@pg:5432/postgres
# sandbox 地址
- SANDBOX_URL=http://sandbox:3000
# 日志等级: debug, info, warn, error
- LOG_LEVEL=info
- STORE_LOG_LEVEL=warn
volumes:
- ./config.json:/app/data/config.json
# oneapi
mysql:
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mysql:8.0.36 # 阿里云
image: mysql:8.0.36
container_name: mysql
restart: always
ports:
- 3306:3306
networks:
- fastgpt
command: --default-authentication-plugin=mysql_native_password
environment:
# 默认root密码,仅首次运行有效
MYSQL_ROOT_PASSWORD: oneapimmysql
MYSQL_DATABASE: oneapi
volumes:
- ./mysql:/var/lib/mysql
oneapi:
container_name: oneapi
image: ghcr.io/songquanpeng/one-api:v0.6.7
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/one-api:v0.6.6 # 阿里云
ports:
- 3001:3000
depends_on:
- mysql
networks:
- fastgpt
restart: always
environment:
# mysql 连接参数
- SQL_DSN=root:oneapimmysql@tcp(mysql:3306)/oneapi
# 登录凭证加密密钥
- SESSION_SECRET=oneapikey
# 内存缓存
- MEMORY_CACHE_ENABLED=true
# 启动聚合更新,减少数据交互频率
- BATCH_UPDATE_ENABLED=true
# 聚合更新时长
- BATCH_UPDATE_INTERVAL=10
# 初始化的 root 密钥(建议部署完后更改,否则容易泄露)
- INITIAL_ROOT_TOKEN=fastgpt
volumes:
- ./oneapi:/data
networks:
fastgpt:
在该路径下打开 cmd

依次输入 cmd 命令
docker-compose pull
docker-compose up -d
可以在 docker 软件看到如下界面(绿色表示启动成功、黄色表示启动失败)
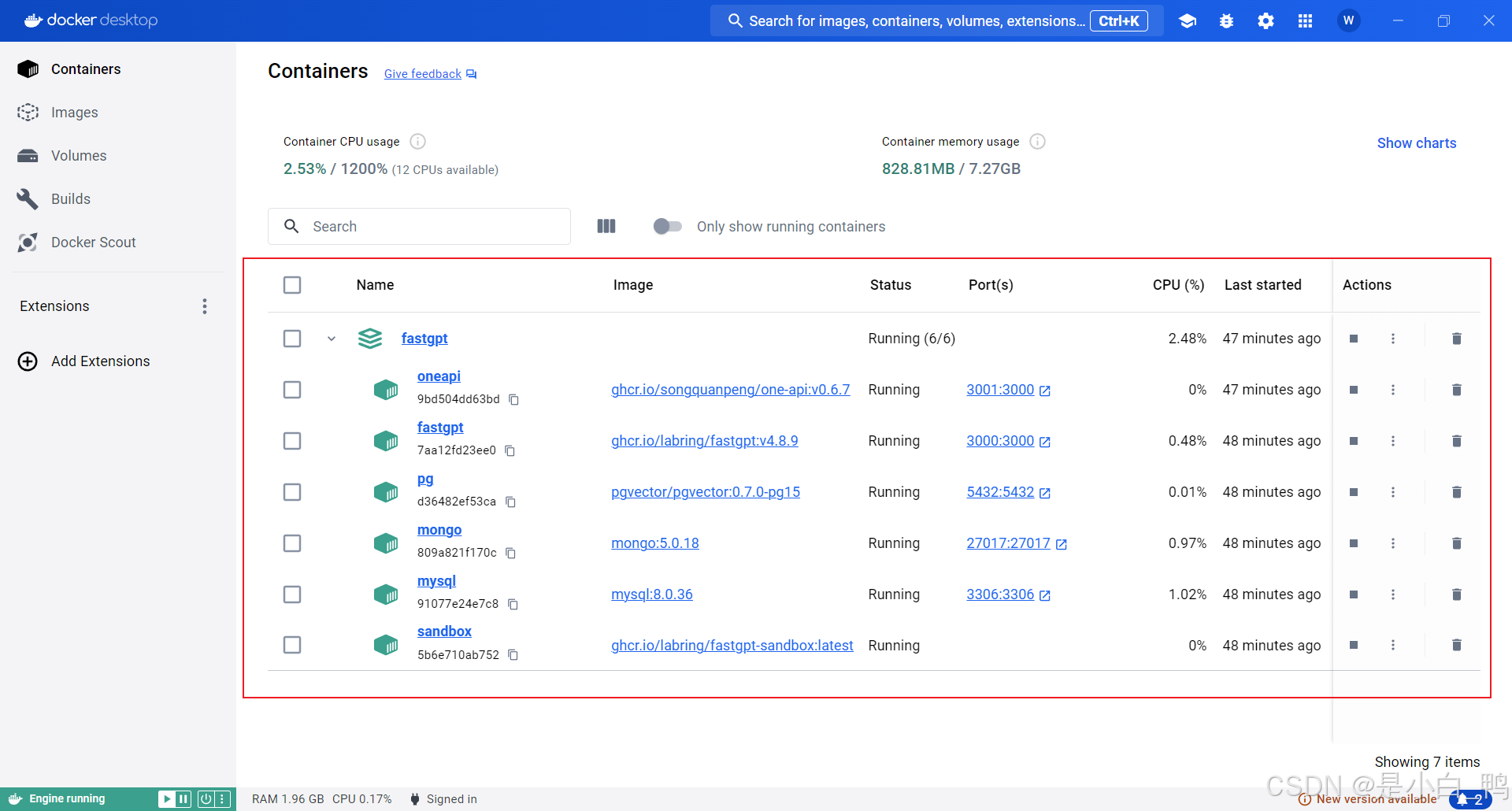
PS :如果遇到 oneapi 启动失败,且报错为 failed to get gpt-3.5-turbo token encoder,解决方法 ——> 链接
3. 浏览器访问
docker 里点击 fastgpt 的 Port 直接跳转或者浏览器输入 http://localhost:3000

登录用户名为 root,密码为 1234(密码是 docker-compose.yml 环境变量里设置的 DEFAULT_ROOT_PSW。如果需要修改 root 密码,直接修改这个环境变量,并重启即可。)
看到如下界面即为 FastGPT 启动成功
4. One API 配置语言模型、向量模型渠道和令牌
通过访问 OneAPI,默认账号为 root 密码为 123456,登录后修改密码
点击渠道栏,如下图填写通义千问模型的相关配置(记得添加所需的向量模型)
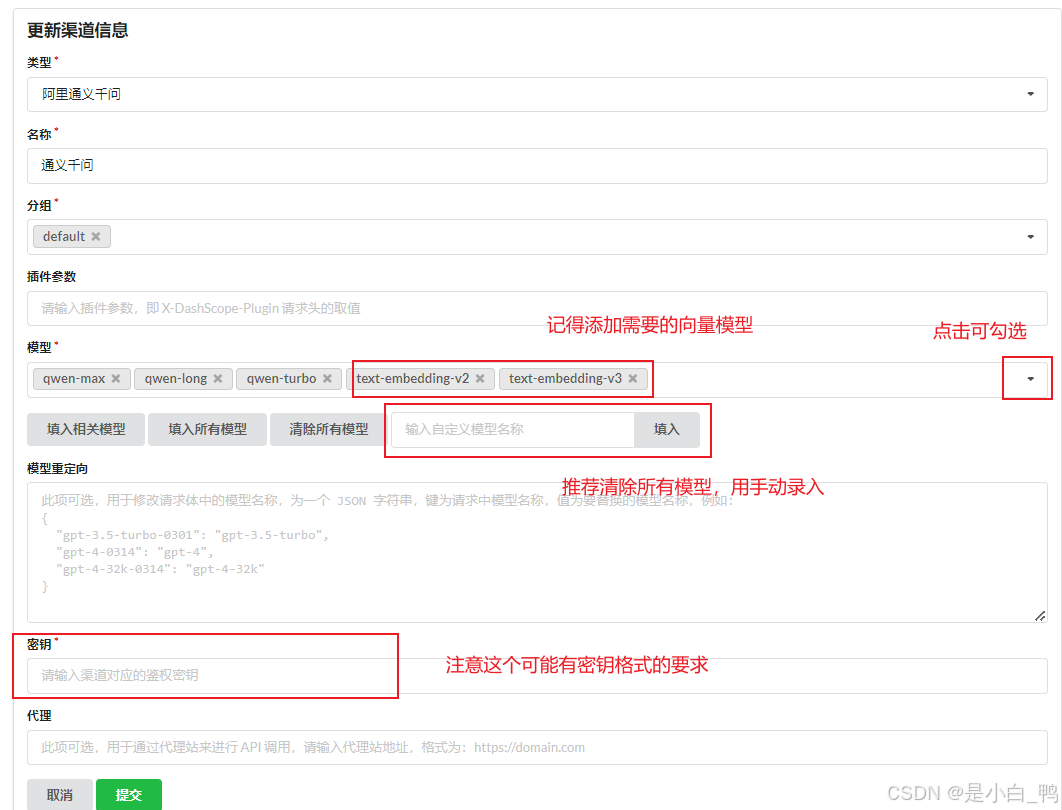
PS:获取通义千问模型密钥
点击测试,能看到状态为已启用即为配置成功
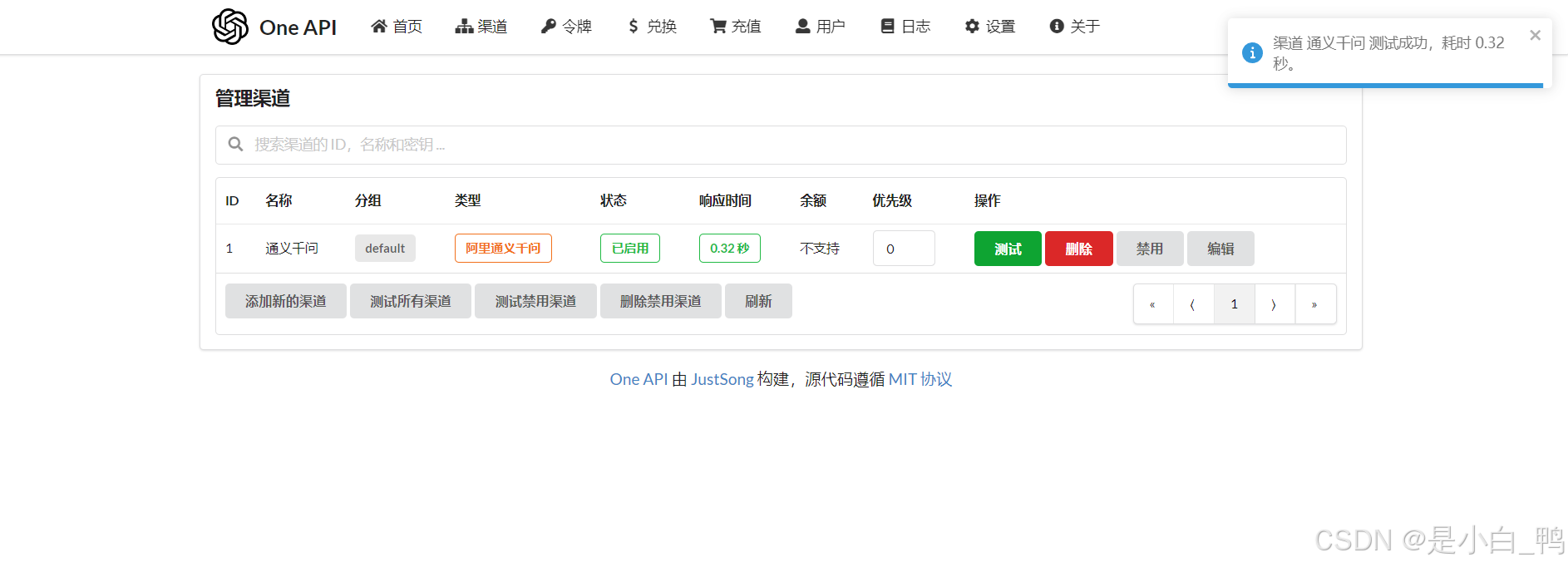
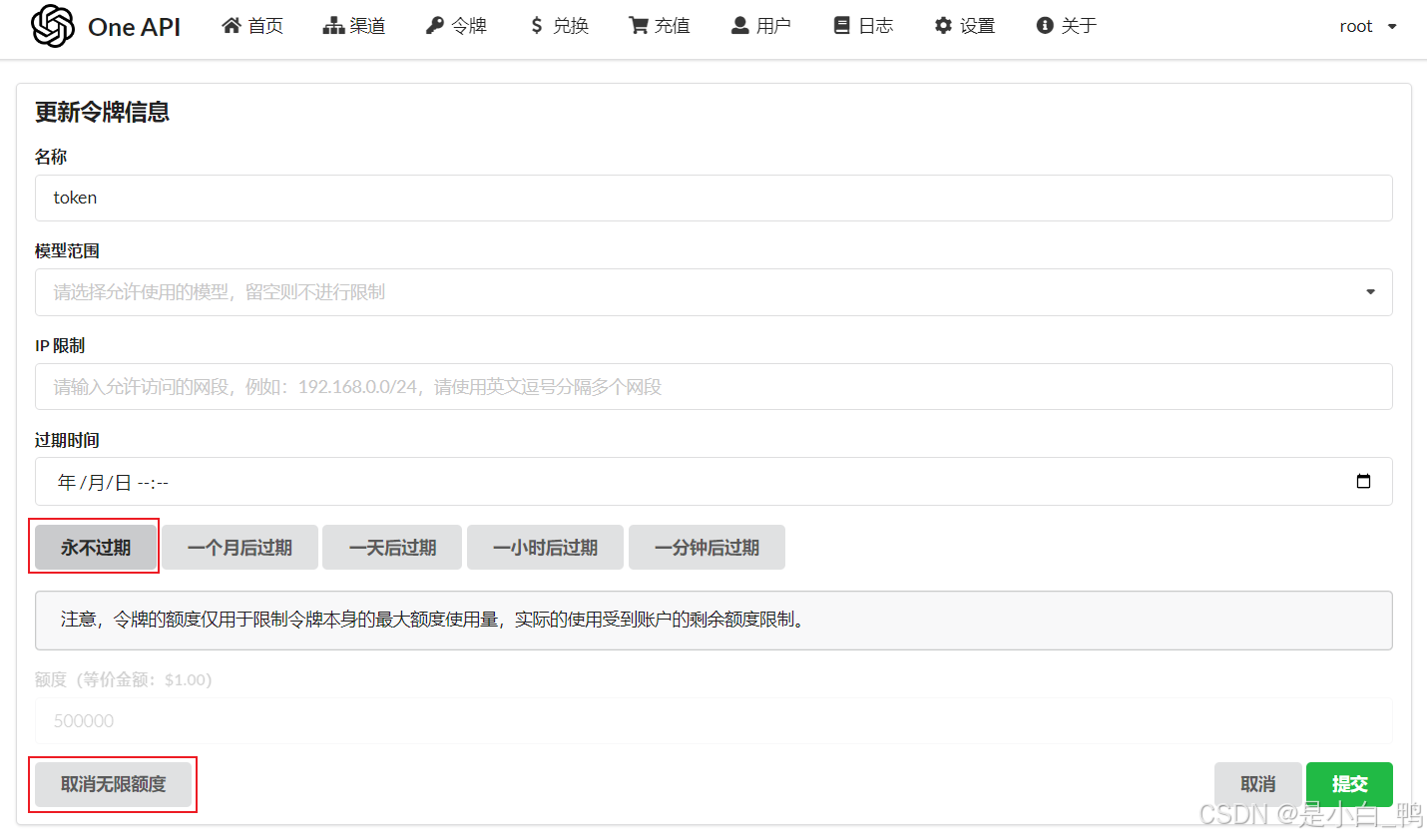
点击令牌栏,删除原有的令牌,重新添加新的,如下图填写令牌配置
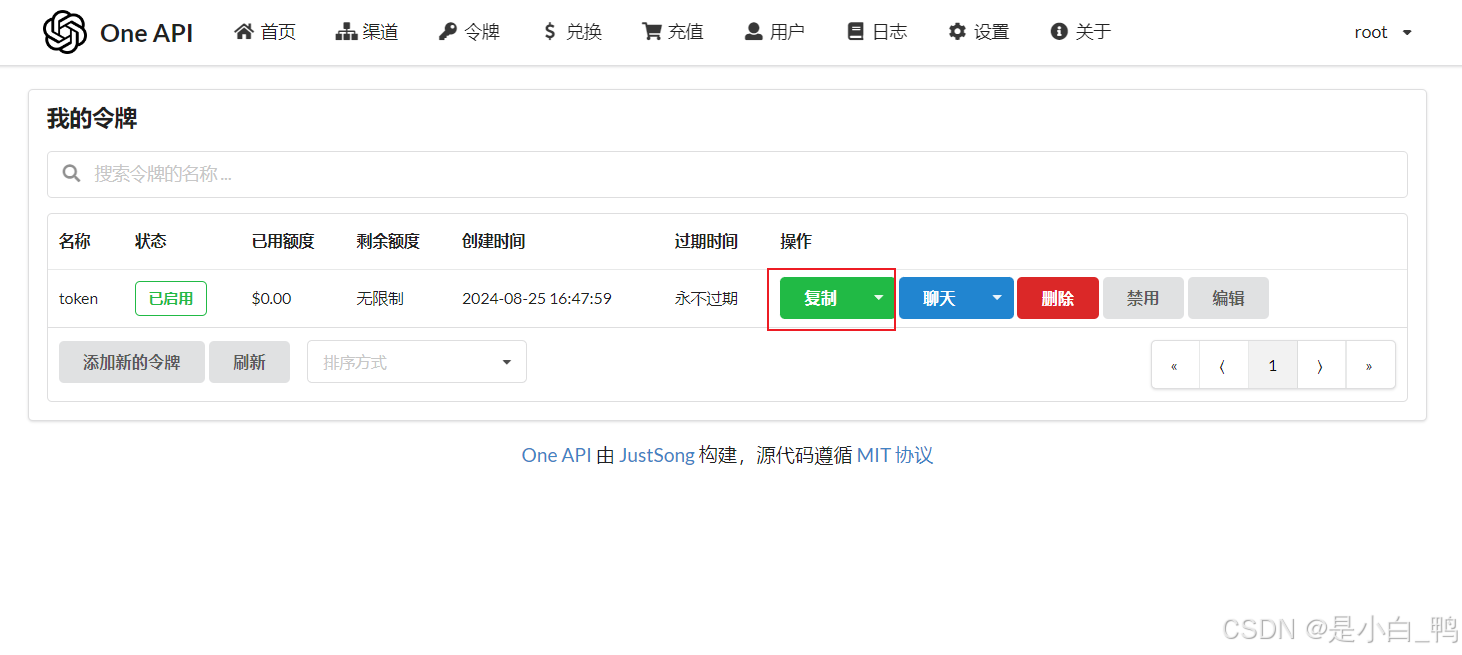
点击复制,粘贴的即为令牌的 api key
修改 docker-compose.yml 文件
替换 OPENAI_BASE_URL(oneapi 的访问地址,需要获取本机 ip)、
替换 CHAT_API_KEY(令牌处复制的 api key)
# AI模型的API地址哦。务必加 /v1。这里默认填写了OneApi的访问地址。
- OPENAI_BASE_URL=http://****:3000/v1
# AI模型的API Key。(这里默认填写了OneAPI的快速默认key,测试通后,务必及时修改)
- CHAT_API_KEY=sk-***
修改 config.json 文件
添加 llmModels(注意模型之间添加英文逗号)
这里要根据模型要求来设置具体参数,有些需要改 maxResponse,务必保证至少有一个为 true 的部分一般都设置 true
"llmModels": [
{
"model": "qwen-max", // 模型名(对应OneAPI中渠道的模型名)
"name": "qwen-max", // 模型别名
"avatar": "/imgs/model/openai.svg", // 模型的logo
"maxContext": 125000, // 最大上下文
"maxResponse": 2000, // 最大回复
"quoteMaxToken": 120000, // 最大引用内容
"maxTemperature": 1.9, // 最大温度
"charsPointsPrice": 0, // n积分/1k token(商业版)
"censor": false, // 是否开启敏感校验(商业版)
"vision": true, // 是否支持图片输入
"datasetProcess": true, // 是否设置为知识库处理模型(QA),务必保证至少有一个为true,否则知识库会报错
"usedInClassify": true, // 是否用于问题分类(务必保证至少有一个为true)
"usedInExtractFields": true, // 是否用于内容提取(务必保证至少有一个为true)
"usedInToolCall": true, // 是否用于工具调用(务必保证至少有一个为true)
"usedInQueryExtension": true, // 是否用于问题优化(务必保证至少有一个为true)
"toolChoice": true, // 是否支持工具选择(分类,内容提取,工具调用会用到。目前只有gpt支持)
"functionCall": false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式)
"customCQPrompt": "", // 自定义文本分类提示词(不支持工具和函数调用的模型
"customExtractPrompt": "", // 自定义内容提取提示词
"defaultSystemChatPrompt": "", // 对话默认携带的系统提示词
"defaultConfig": {} // 请求API时,挟带一些默认配置(比如 GLM4 的 top_p)
},
{
"model": "qwen-long",
"name": "qwen-long",
"avatar": "/imgs/model/openai.svg",
"maxContext": 125000,
"maxResponse": 2000,
"quoteMaxToken": 120000,
"maxTemperature": 1.9,
"charsPointsPrice": 0,
"censor": false,
"vision": true,
"datasetProcess": true,
"usedInClassify": true,
"usedInExtractFields": true,
"usedInToolCall": true,
"usedInQueryExtension": true,
"toolChoice": true,
"functionCall": false,
"customCQPrompt": "",
"customExtractPrompt": "",
"defaultSystemChatPrompt": "",
"defaultConfig": {}
},
{
"model": "qwen-turbo",
"name": "qwen-turbo",
"avatar": "/imgs/model/openai.svg",
"maxContext": 125000,
"maxResponse": 2000,
"quoteMaxToken": 120000,
"maxTemperature": 1.9,
"charsPointsPrice": 0,
"censor": false,
"vision": true,
"datasetProcess": true,
"usedInClassify": true,
"usedInExtractFields": true,
"usedInToolCall": true,
"usedInQueryExtension": true,
"toolChoice": true,
"functionCall": false,
"customCQPrompt": "",
"customExtractPrompt": "",
"defaultSystemChatPrompt": "",
"defaultConfig": {}
}
]
添加 vectorModels(注意模型之间添加英文逗号)
"vectorModels": [
{
"model": "text-embedding-v2", // 模型名(与OneAPI对应)
"name": "text-embedding-v2", // 模型展示名
"avatar": "/imgs/model/openai.svg", // logo
"charsPointsPrice": 0, // n积分/1k token
"defaultToken": 700, // 默认文本分割时候的 token
"maxToken": 3000, // 最大 token
"weight": 100, // 优先训练权重
"defaultConfig": {}, // 自定义额外参数。例如,如果希望使用 embedding3-large 的话,可以传入 dimensions:1024,来返回1024维度的向量。(目前必须小于1536维度)
"dbConfig": {}, // 存储时的额外参数(非对称向量模型时候需要用到)
"queryConfig": {} // 参训时的额外参数
},
{
"model": "text-embedding-v3",
"name": "text-embedding-v3",
"avatar": "/imgs/model/openai.svg",
"charsPointsPrice": 0,
"defaultToken": 700,
"maxToken": 3000,
"weight": 100,
"defaultConfig": {},
"dbConfig": {},
"queryConfig": {}
}
]{
"model": "embedding-2", // 模型名(与OneAPI对应)
"name": "Embedding-2", // 模型展示名
"avatar": "/imgs/model/openai.svg", // logo
"charsPointsPrice": 0, // n积分/1k token
"defaultToken": 700, // 默认文本分割时候的 token
"maxToken": 3000, // 最大 token
"weight": 100, // 优先训练权重
"defaultConfig": {}, // 自定义额外参数。例如,如果希望使用 embedding3-large 的话,可以传入 dimensions:1024,来返回1024维度的向量。(目前必须小于1536维度)
"dbConfig": {}, // 存储时的额外参数(非对称向量模型时候需要用到)
"queryConfig": {} // 参训时的额外参数
}
重启 docker
docker-compose down
docker-compose up -d
修改完后的 docker-compose.yml(注意更改 OneApi 的访问地址和 key):
# 数据库的默认账号和密码仅首次运行时设置有效
# 如果修改了账号密码,记得改数据库和项目连接参数,别只改一处~
# 该配置文件只是给快速启动,测试使用。正式使用,记得务必修改账号密码,以及调整合适的知识库参数,共享内存等。
# 如何无法访问 dockerhub 和 git,可以用阿里云(阿里云没有arm包)
version: '3.3'
services:
# db
pg:
image: pgvector/pgvector:0.7.0-pg15 # docker hub
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.7.0 # 阿里云
container_name: pg
restart: always
ports: # 生产环境建议不要暴露
- 5432:5432
networks:
- fastgpt
environment:
# 这里的配置只有首次运行生效。修改后,重启镜像是不会生效的。需要把持久化数据删除再重启,才有效果
- POSTGRES_USER=username
- POSTGRES_PASSWORD=password
- POSTGRES_DB=postgres
volumes:
- ./pg/data:/var/lib/postgresql/data
mongo:
image: mongo:5.0.18 # dockerhub
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mongo:5.0.18 # 阿里云
# image: mongo:4.4.29 # cpu不支持AVX时候使用
container_name: mongo
restart: always
ports:
- 27017:27017
networks:
- fastgpt
command: mongod --keyFile /data/mongodb.key --replSet rs0
environment:
- MONGO_INITDB_ROOT_USERNAME=myusername
- MONGO_INITDB_ROOT_PASSWORD=mypassword
volumes:
- ./mongo/data:/data/db
entrypoint:
- bash
- -c
- |
openssl rand -base64 128 > /data/mongodb.key
chmod 400 /data/mongodb.key
chown 999:999 /data/mongodb.key
echo 'const isInited = rs.status().ok === 1
if(!isInited){
rs.initiate({
_id: "rs0",
members: [
{ _id: 0, host: "mongo:27017" }
]
})
}' > /data/initReplicaSet.js
# 启动MongoDB服务
exec docker-entrypoint.sh "$$@" &
# 等待MongoDB服务启动
until mongo -u myusername -p mypassword --authenticationDatabase admin --eval "print('waited for connection')" > /dev/null 2>&1; do
echo "Waiting for MongoDB to start..."
sleep 2
done
# 执行初始化副本集的脚本
mongo -u myusername -p mypassword --authenticationDatabase admin /data/initReplicaSet.js
# 等待docker-entrypoint.sh脚本执行的MongoDB服务进程
wait $$!
# fastgpt
sandbox:
container_name: sandbox
image: ghcr.io/labring/fastgpt-sandbox:latest # git
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:latest # 阿里云
networks:
- fastgpt
restart: always
fastgpt:
container_name: fastgpt
image: ghcr.io/labring/fastgpt:v4.8.9 # git
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.8.9 # 阿里云
ports:
- 3000:3000
networks:
- fastgpt
depends_on:
- mongo
- pg
- sandbox
restart: always
environment:
# root 密码,用户名为: root。如果需要修改 root 密码,直接修改这个环境变量,并重启即可。
- DEFAULT_ROOT_PSW=1234
# AI模型的API地址哦。务必加 /v1。这里默认填写了OneApi的访问地址。
- OPENAI_BASE_URL=http://***:3001/v1
# AI模型的API Key。(这里默认填写了OneAPI的快速默认key,测试通后,务必及时修改)
- CHAT_API_KEY=sk-***
# 数据库最大连接数
- DB_MAX_LINK=30
# 登录凭证密钥
- TOKEN_KEY=any
# root的密钥,常用于升级时候的初始化请求
- ROOT_KEY=root_key
# 文件阅读加密
- FILE_TOKEN_KEY=filetoken
# MongoDB 连接参数. 用户名myusername,密码mypassword。
- MONGODB_URI=mongodb://myusername:mypassword@mongo:27017/fastgpt?authSource=admin
# pg 连接参数
- PG_URL=postgresql://username:password@pg:5432/postgres
# sandbox 地址
- SANDBOX_URL=http://sandbox:3000
# 日志等级: debug, info, warn, error
- LOG_LEVEL=info
- STORE_LOG_LEVEL=warn
volumes:
- ./config.json:/app/data/config.json
# oneapi
mysql:
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mysql:8.0.36 # 阿里云
image: mysql:8.0.36
container_name: mysql
restart: always
ports:
- 3306:3306
networks:
- fastgpt
command: --default-authentication-plugin=mysql_native_password
environment:
# 默认root密码,仅首次运行有效
MYSQL_ROOT_PASSWORD: oneapimmysql
MYSQL_DATABASE: oneapi
volumes:
- ./mysql:/var/lib/mysql
oneapi:
container_name: oneapi
image: ghcr.io/songquanpeng/one-api:v0.6.7
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/one-api:v0.6.6 # 阿里云
ports:
- 3001:3000
depends_on:
- mysql
networks:
- fastgpt
restart: always
environment:
# mysql 连接参数
- SQL_DSN=root:oneapimmysql@tcp(mysql:3306)/oneapi
# 登录凭证加密密钥
- SESSION_SECRET=oneapikey
# 内存缓存
- MEMORY_CACHE_ENABLED=true
# 启动聚合更新,减少数据交互频率
- BATCH_UPDATE_ENABLED=true
# 聚合更新时长
- BATCH_UPDATE_INTERVAL=10
# 初始化的 root 密钥(建议部署完后更改,否则容易泄露)
- INITIAL_ROOT_TOKEN=fastgpt
volumes:
- ./oneapi:/data
networks:
fastgpt:
修改完后的config.json:
// 已使用 json5 进行解析,会自动去掉注释,无需手动去除
{
"feConfigs": {
"lafEnv": "https://laf.dev" // laf环境。 https://laf.run (杭州阿里云) ,或者私有化的laf环境。如果使用 Laf openapi 功能,需要最新版的 laf 。
},
"systemEnv": {
"vectorMaxProcess": 15,
"qaMaxProcess": 15,
"pgHNSWEfSearch": 100 // 向量搜索参数。越大,搜索越精确,但是速度越慢。设置为100,有99%+精度。
},
"llmModels": [
{
"model": "qwen-max", // 模型名(对应OneAPI中渠道的模型名)
"name": "qwen-max", // 模型别名
"avatar": "/imgs/model/openai.svg", // 模型的logo
"maxContext": 125000, // 最大上下文
"maxResponse": 2000, // 最大回复
"quoteMaxToken": 120000, // 最大引用内容
"maxTemperature": 1.9, // 最大温度
"charsPointsPrice": 0, // n积分/1k token(商业版)
"censor": false, // 是否开启敏感校验(商业版)
"vision": true, // 是否支持图片输入
"datasetProcess": true, // 是否设置为知识库处理模型(QA),务必保证至少有一个为true,否则知识库会报错
"usedInClassify": true, // 是否用于问题分类(务必保证至少有一个为true)
"usedInExtractFields": true, // 是否用于内容提取(务必保证至少有一个为true)
"usedInToolCall": true, // 是否用于工具调用(务必保证至少有一个为true)
"usedInQueryExtension": true, // 是否用于问题优化(务必保证至少有一个为true)
"toolChoice": true, // 是否支持工具选择(分类,内容提取,工具调用会用到。目前只有gpt支持)
"functionCall": false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式)
"customCQPrompt": "", // 自定义文本分类提示词(不支持工具和函数调用的模型
"customExtractPrompt": "", // 自定义内容提取提示词
"defaultSystemChatPrompt": "", // 对话默认携带的系统提示词
"defaultConfig": {} // 请求API时,挟带一些默认配置(比如 GLM4 的 top_p)
},
{
"model": "qwen-long",
"name": "qwen-long",
"avatar": "/imgs/model/openai.svg",
"maxContext": 125000,
"maxResponse": 2000,
"quoteMaxToken": 120000,
"maxTemperature": 1.9,
"charsPointsPrice": 0,
"censor": false,
"vision": true,
"datasetProcess": true,
"usedInClassify": true,
"usedInExtractFields": true,
"usedInToolCall": true,
"usedInQueryExtension": true,
"toolChoice": true,
"functionCall": false,
"customCQPrompt": "",
"customExtractPrompt": "",
"defaultSystemChatPrompt": "",
"defaultConfig": {}
},
{
"model": "qwen-turbo",
"name": "qwen-turbo",
"avatar": "/imgs/model/openai.svg",
"maxContext": 125000,
"maxResponse": 2000,
"quoteMaxToken": 120000,
"maxTemperature": 1.9,
"charsPointsPrice": 0,
"censor": false,
"vision": true,
"datasetProcess": true,
"usedInClassify": true,
"usedInExtractFields": true,
"usedInToolCall": true,
"usedInQueryExtension": true,
"toolChoice": true,
"functionCall": false,
"customCQPrompt": "",
"customExtractPrompt": "",
"defaultSystemChatPrompt": "",
"defaultConfig": {}
}
],
"vectorModels": [
{
"model": "text-embedding-v2", // 模型名(与OneAPI对应)
"name": "text-embedding-v2", // 模型展示名
"avatar": "/imgs/model/openai.svg", // logo
"charsPointsPrice": 0, // n积分/1k token
"defaultToken": 700, // 默认文本分割时候的 token
"maxToken": 3000, // 最大 token
"weight": 100, // 优先训练权重
"defaultConfig": {}, // 自定义额外参数。例如,如果希望使用 embedding3-large 的话,可以传入 dimensions:1024,来返回1024维度的向量。(目前必须小于1536维度)
"dbConfig": {}, // 存储时的额外参数(非对称向量模型时候需要用到)
"queryConfig": {} // 参训时的额外参数
},
{
"model": "text-embedding-v3",
"name": "text-embedding-v3",
"avatar": "/imgs/model/openai.svg",
"charsPointsPrice": 0,
"defaultToken": 700,
"maxToken": 3000,
"weight": 100,
"defaultConfig": {},
"dbConfig": {},
"queryConfig": {}
}
],
"reRankModels": [],
"audioSpeechModels": [
{
"model": "tts-1",
"name": "OpenAI TTS1",
"charsPointsPrice": 0,
"voices": [
{ "label": "Alloy", "value": "alloy", "bufferId": "openai-Alloy" },
{ "label": "Echo", "value": "echo", "bufferId": "openai-Echo" },
{ "label": "Fable", "value": "fable", "bufferId": "openai-Fable" },
{ "label": "Onyx", "value": "onyx", "bufferId": "openai-Onyx" },
{ "label": "Nova", "value": "nova", "bufferId": "openai-Nova" },
{ "label": "Shimmer", "value": "shimmer", "bufferId": "openai-Shimmer" }
]
}
],
"whisperModel": {
"model": "whisper-1",
"name": "Whisper1",
"charsPointsPrice": 0
}
}
5. 创建 FastGPT 知识库
选择新建知识库
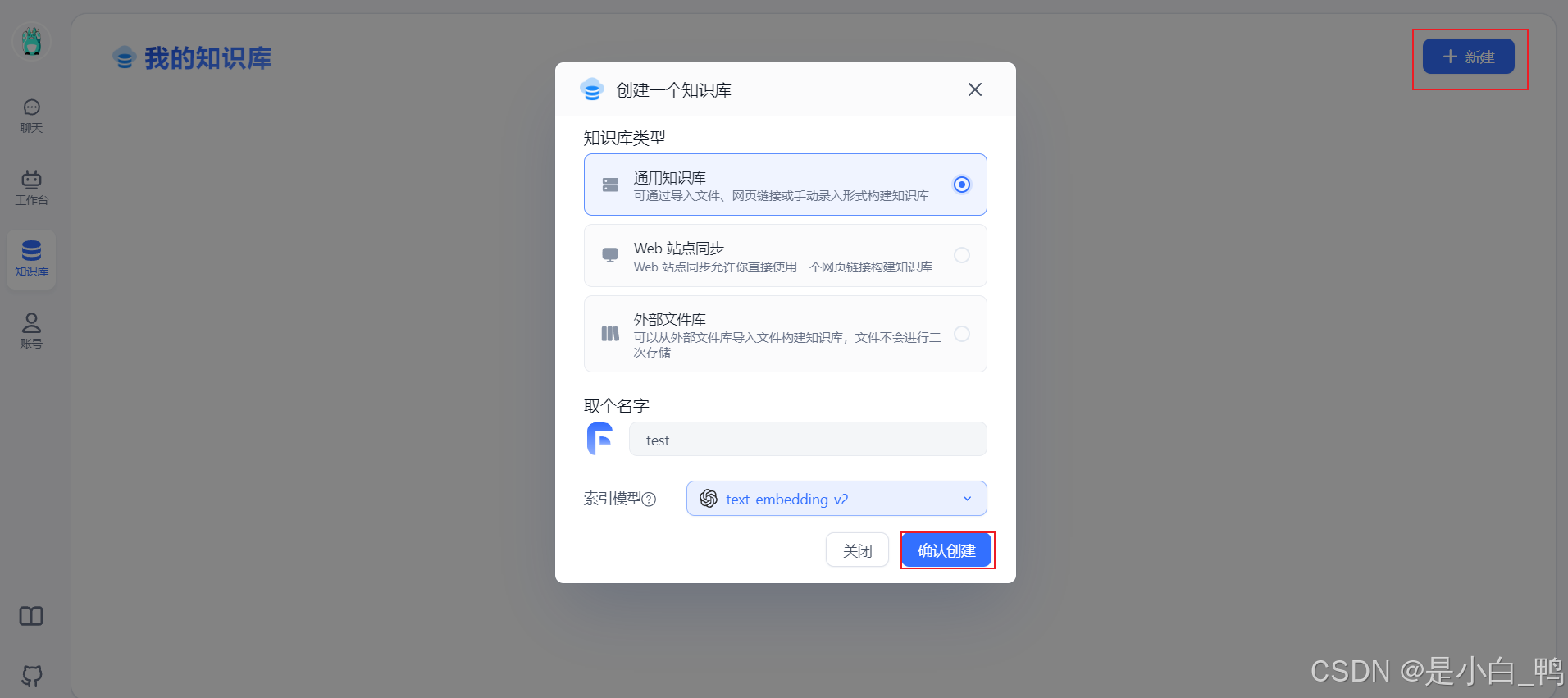
选择导入文本数据集
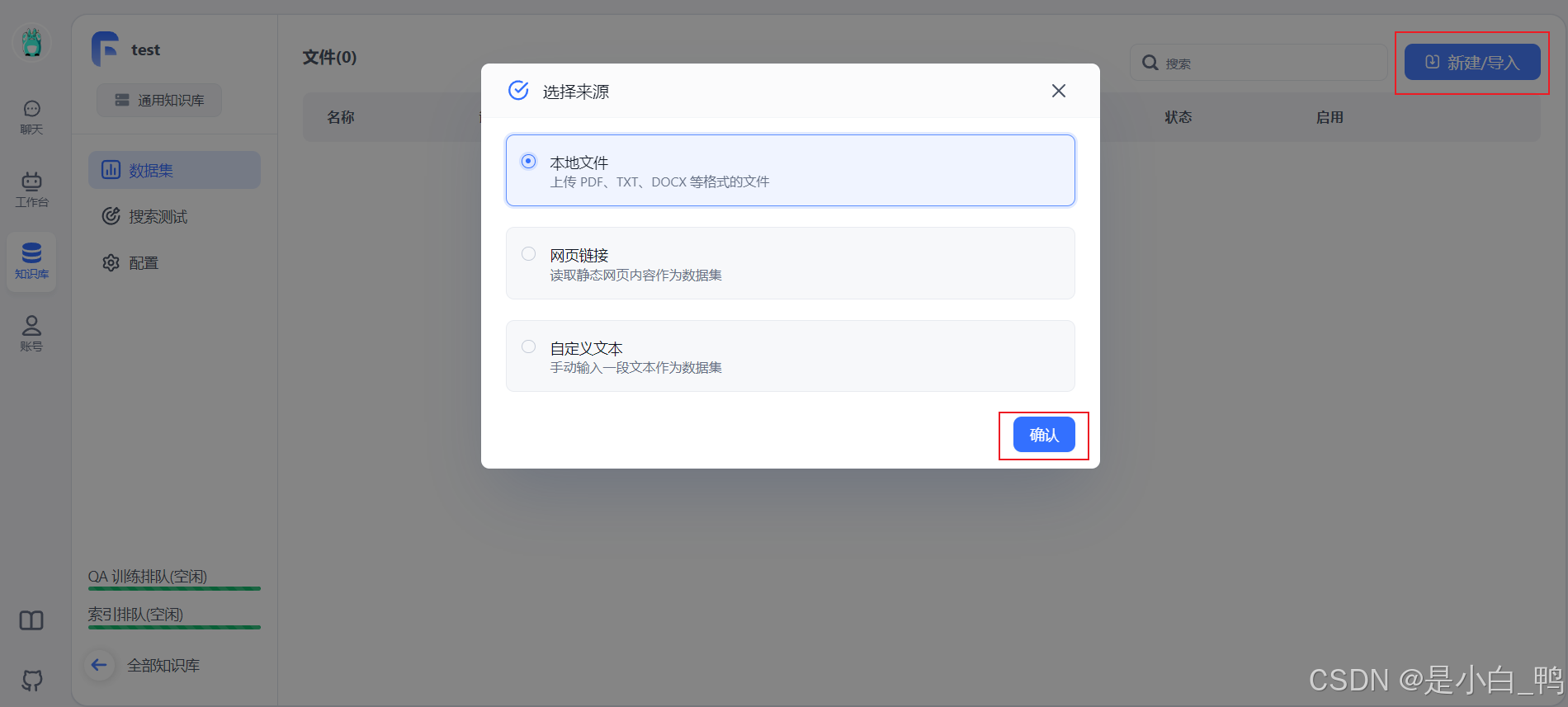
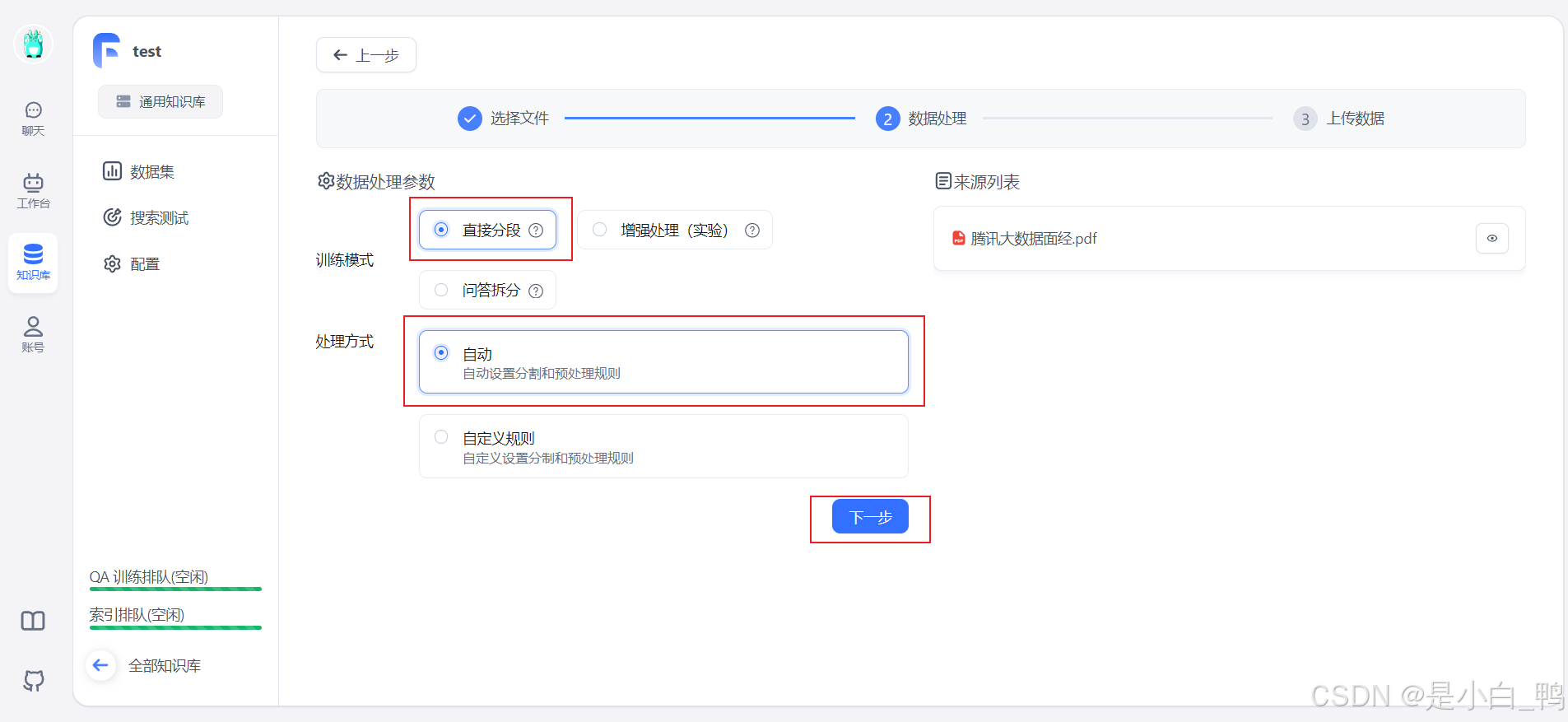
上传本地文件,设置数据处理参数,选择直接分段或问答拆分,点击上传
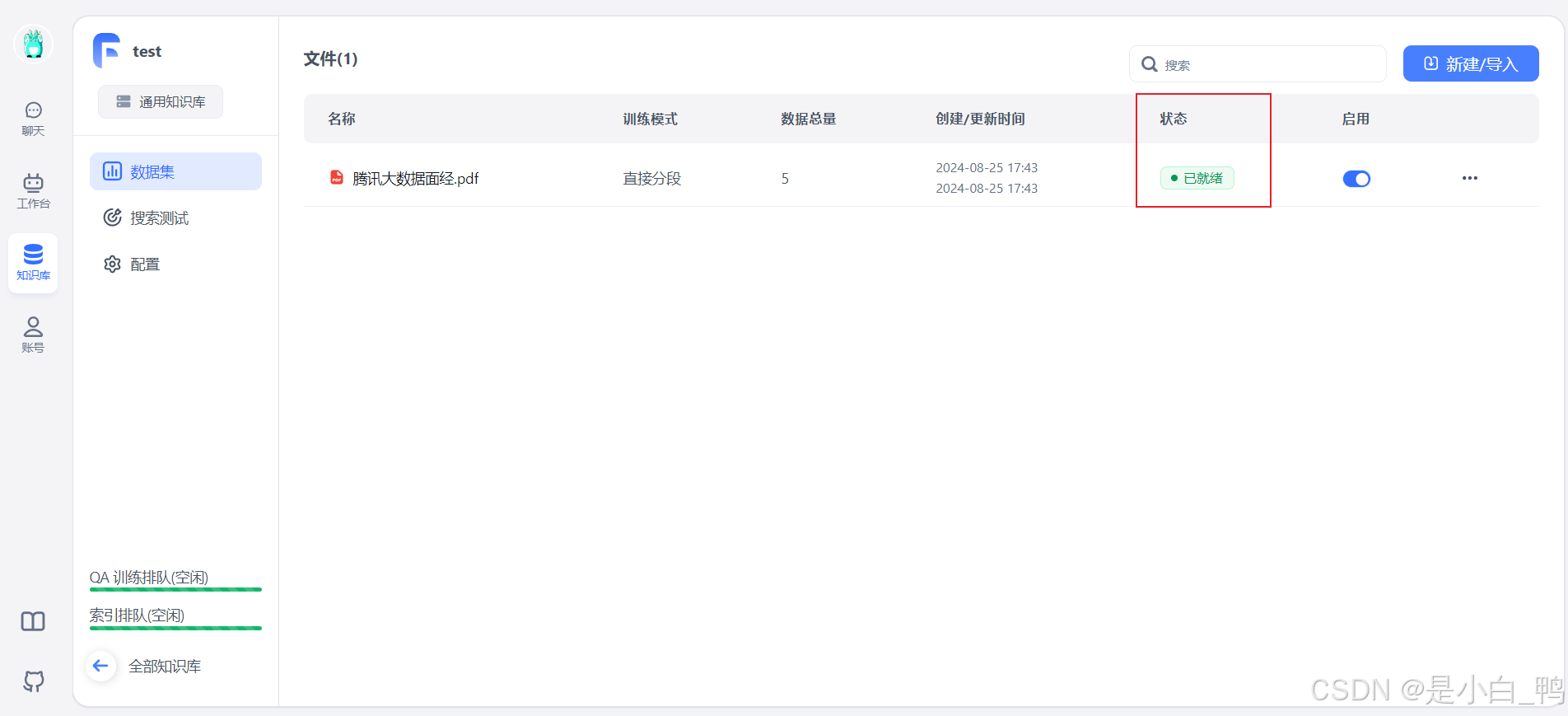
等待索引创建,当状态为“已就绪”即为成功
点击文件名,可以查看具体分块情况
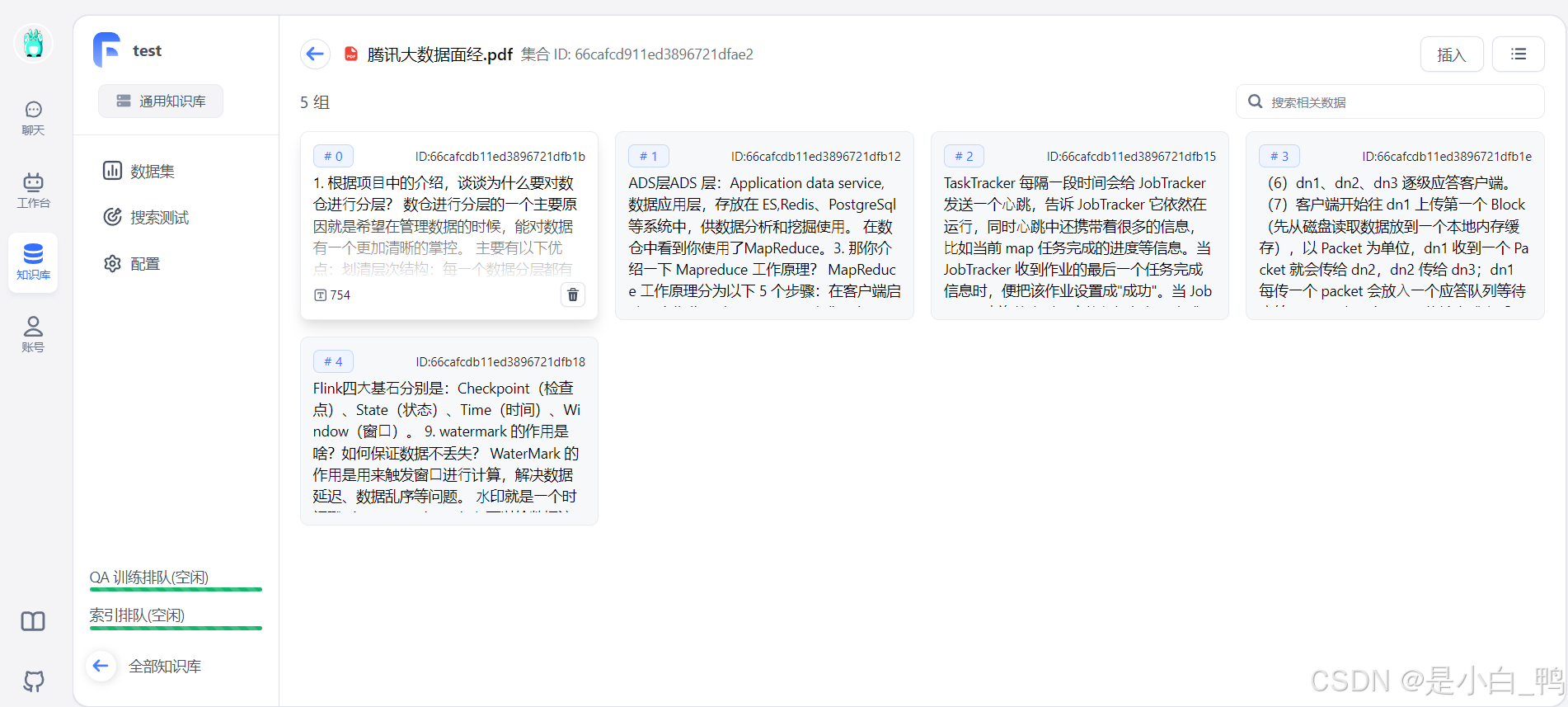
6. 创建 FastGPT 应用
到工作台(应用)新建应用
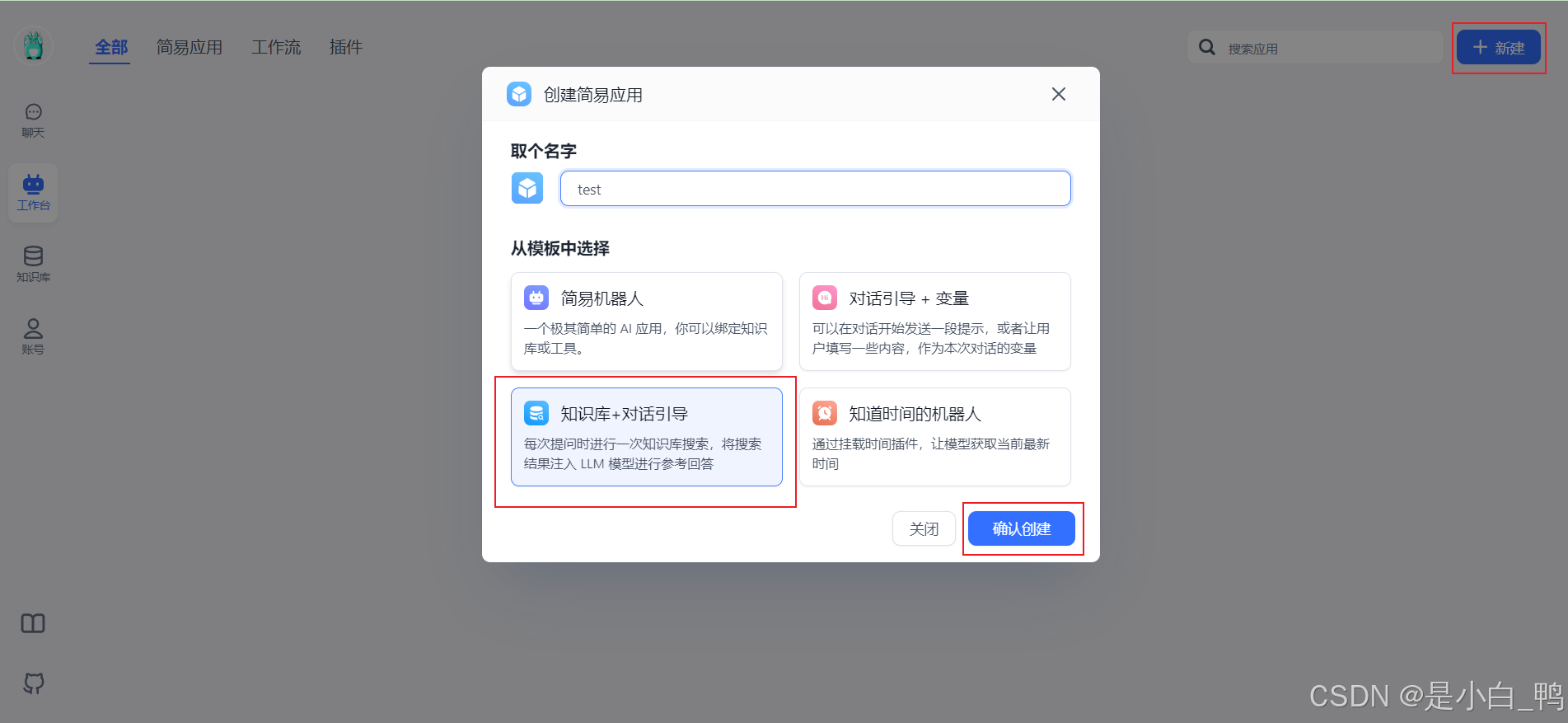
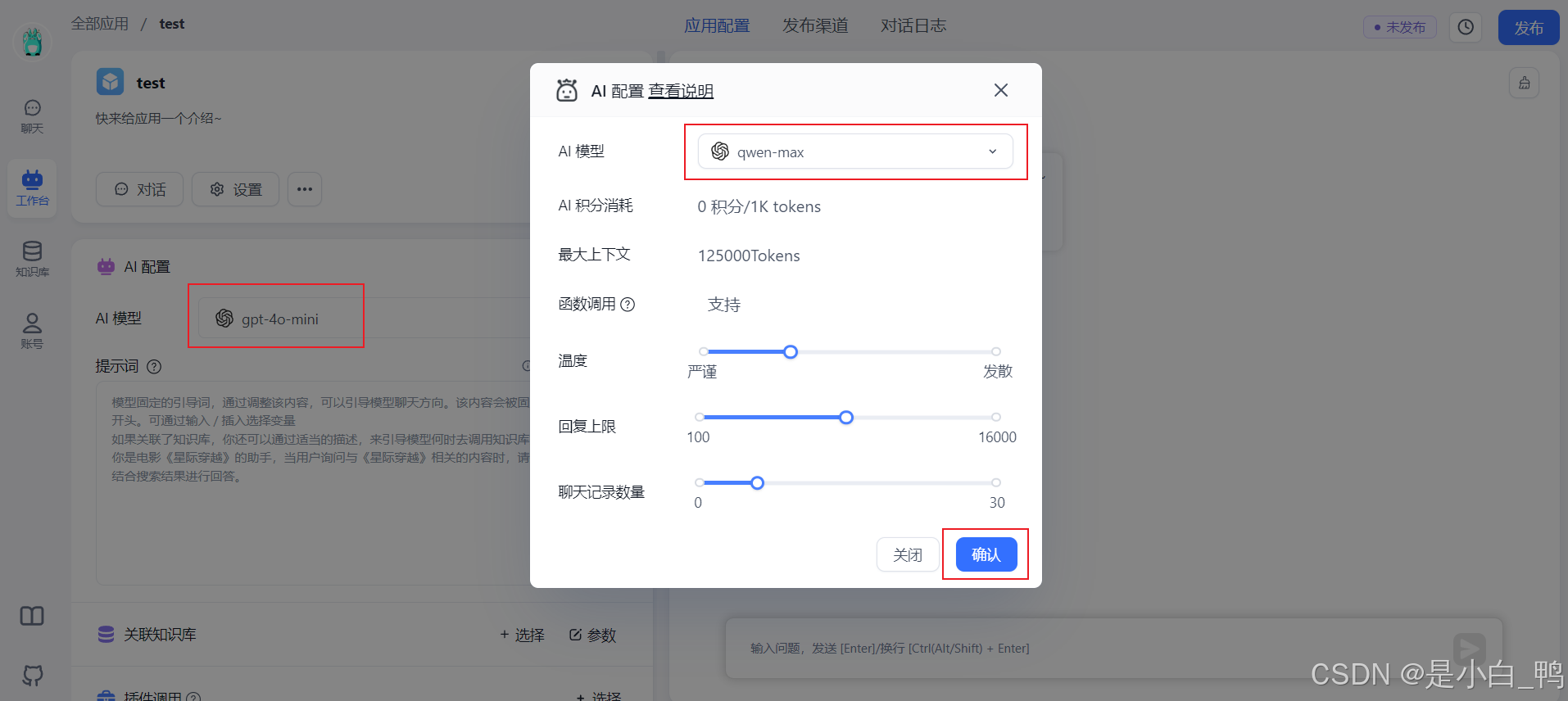
选择语言模型
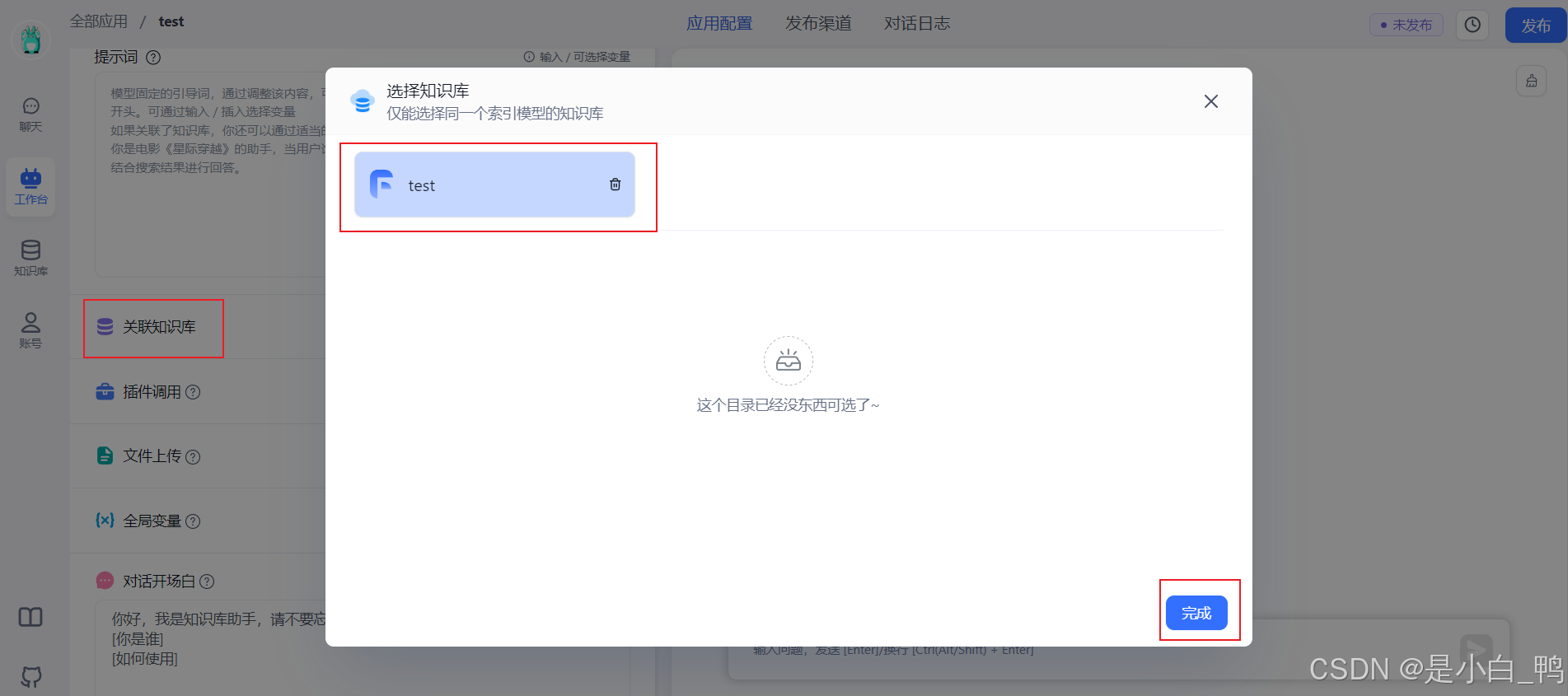
关联知识库,点击相应的知识库添加或删除
点击关联知识库的参数选择是否开启问题优化,若开启则需要选择相应模型
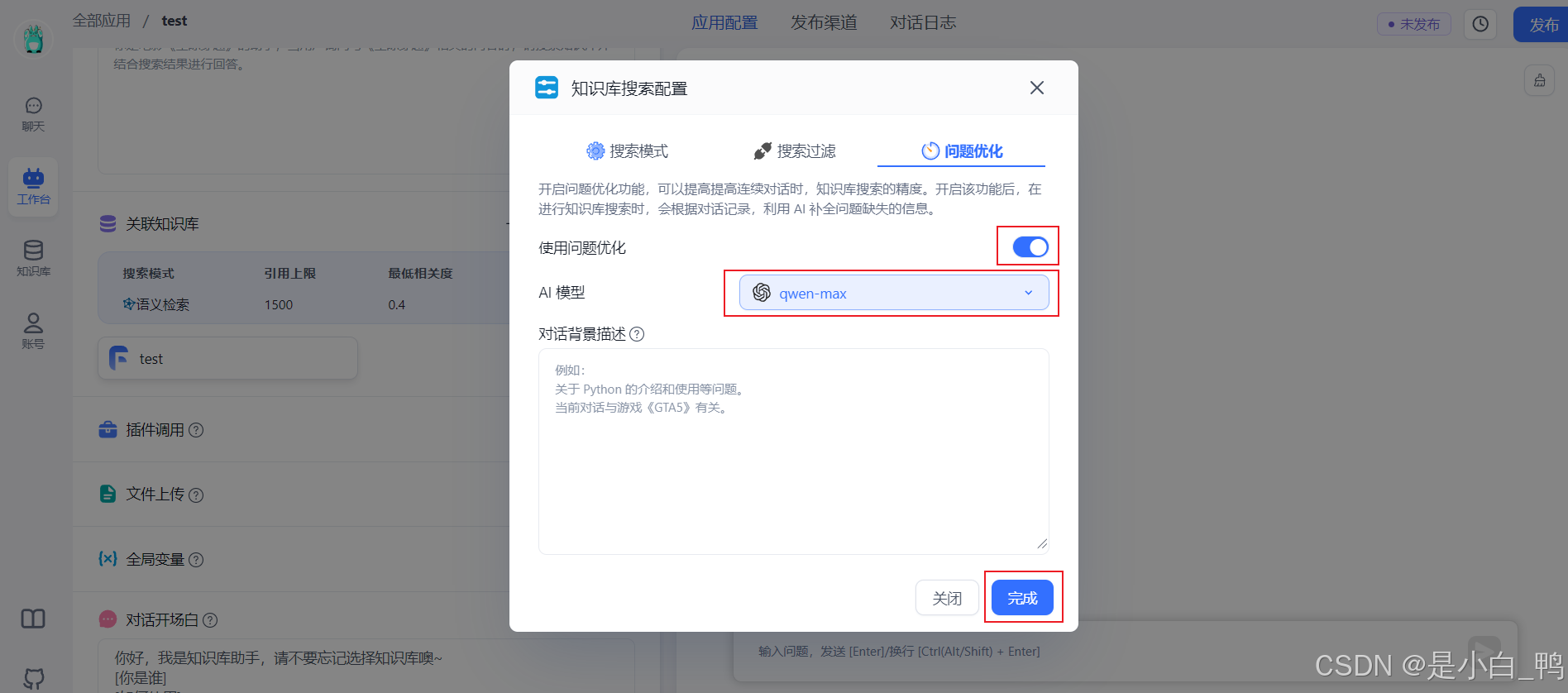
输入对话测试,能得到回答,点击发布
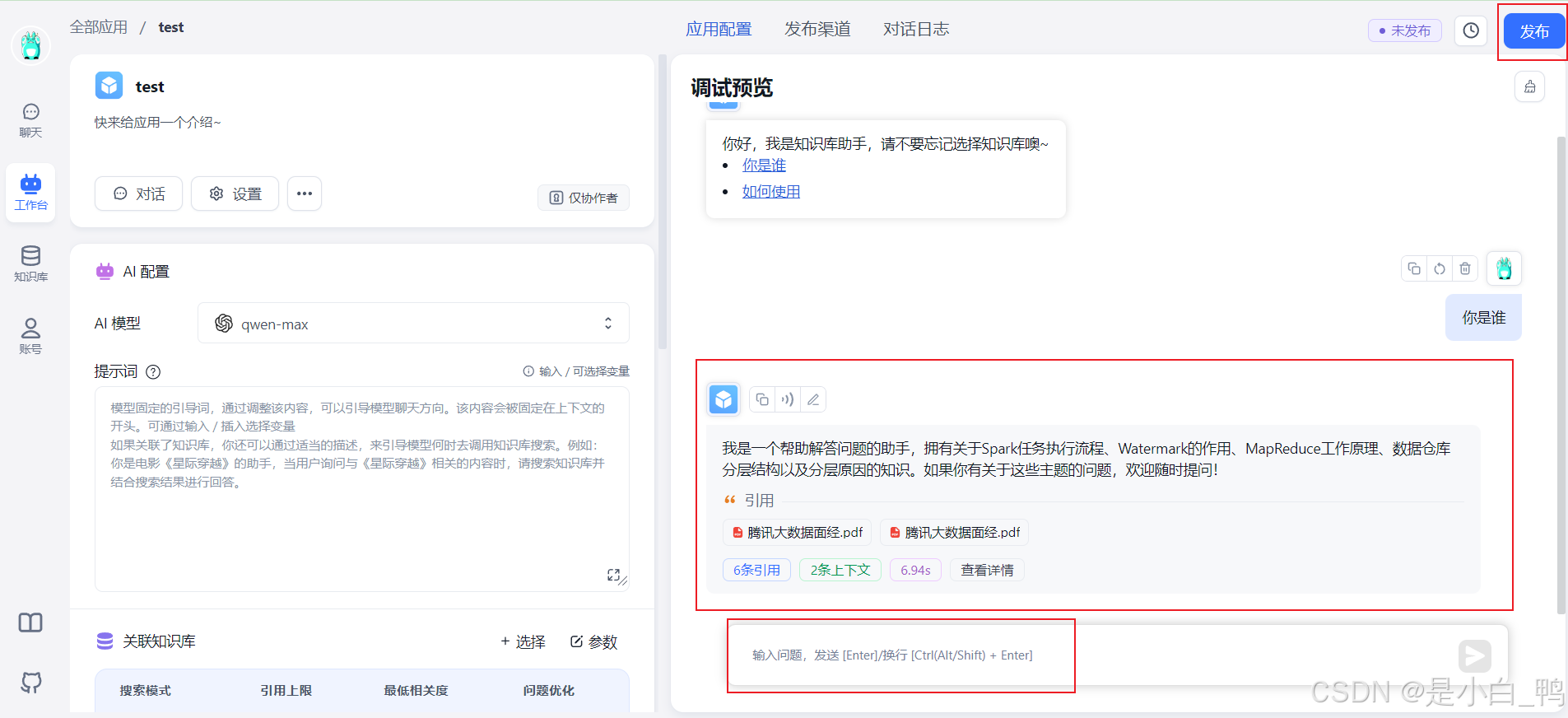
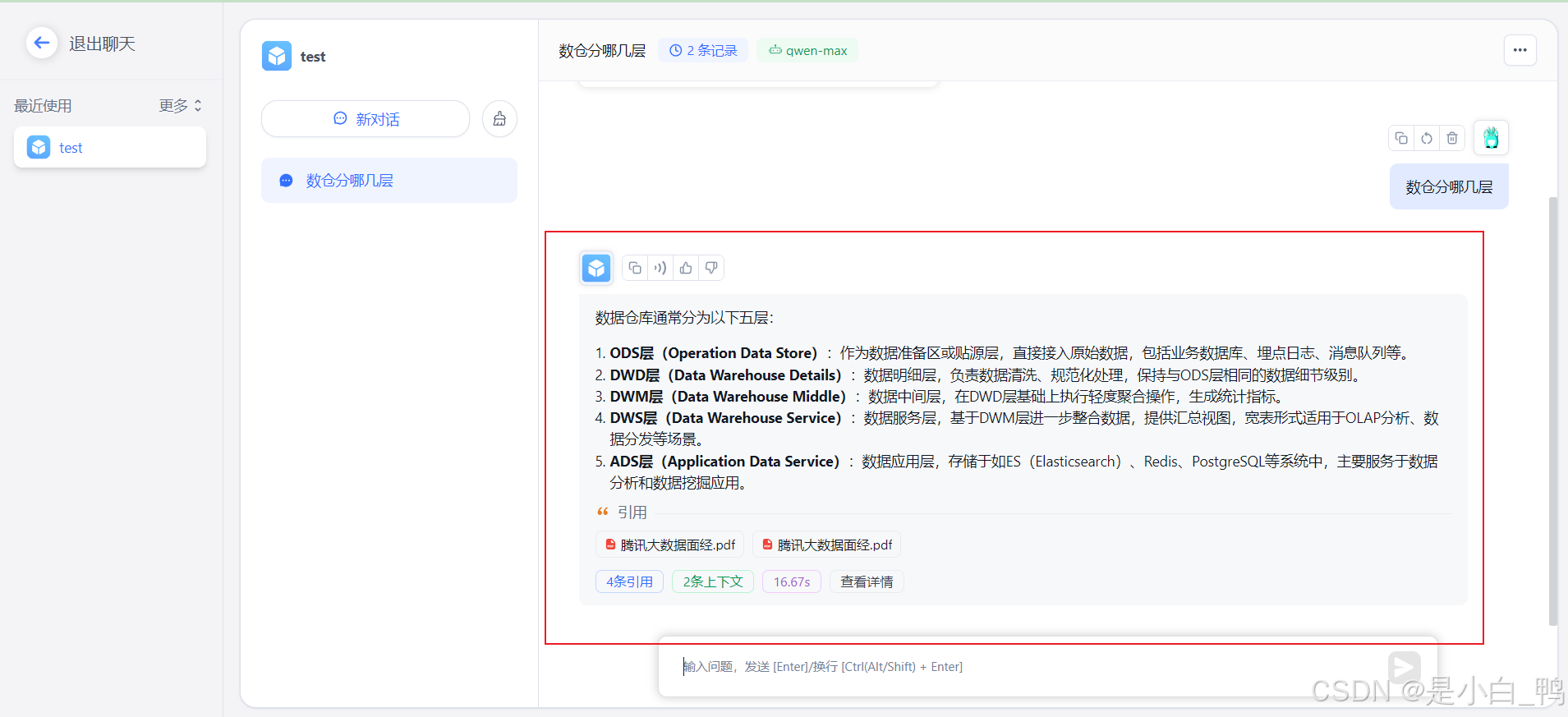
打开聊天,能正常对话即为成功
至此,整个 FastGPT 的部署和基本使用已经介绍完成,后续需要的工作:
1、丰富语言模型、向量模型、重排序模型等
2、优化知识库的文本索引创建
3、探究应用的配置,比如提示词、知识库关联、对话开场白等
4、根据对话进行优化,比如将一些常见的问答提取到知识库等
官方文档
https://doc.fastgpt.in/docs/development/docker/


















