Kafka 消费者交付语义指的是 Kafka 消费者在处理消息时如何保证消息的可靠性和一致性。这涉及到消息是否被丢失、重复处理或者按顺序消费。
Kafka消费者交付语义有三种,即:
- 最多一次
- 至少一次
- 精确一次
当消费者组/消费者从 Kafka 消费数据时,仅支持最多一次和至少一次这两种语义。但是您可以通过选择适当的数据存储来实现类似于精确一次的交付语义,例如,任何键值存储、RDBMS(主键)、Elasticsearch或任何其他支持幂等写入的存储。
最多一次
在最多一次传递语义中,消息最多只能传递一次。在这种语义中,宁可丢失消息也不应重复传递消息。采用最多一次语义的应用程序可以轻松实现更高的吞吐量和较低的延迟。默认情况下,由于“enable.auto.commit”为 true,因此Kafka消费者设置为使用“最多一次”传递语义。
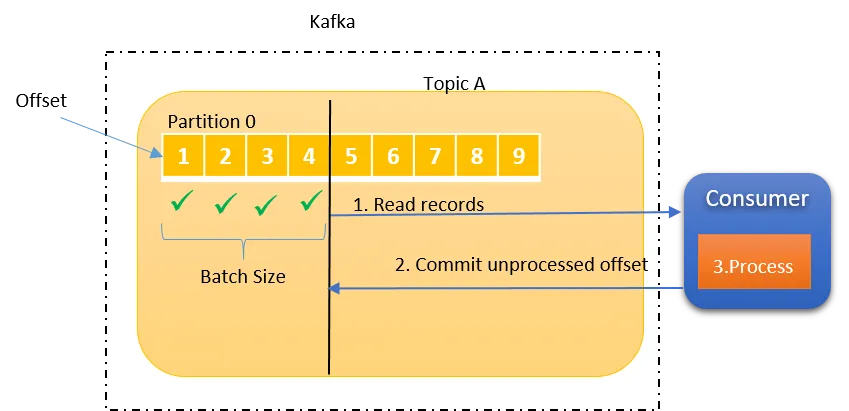
这种语义下,如果消费者在将消息提交为已读,但是在处理消息之前宕机了或者消息处理失败,则未处理的消息将丢失,并且不会再次读取,分区重新平衡将导致另一个消费者从上次提交的偏移量读取消息。
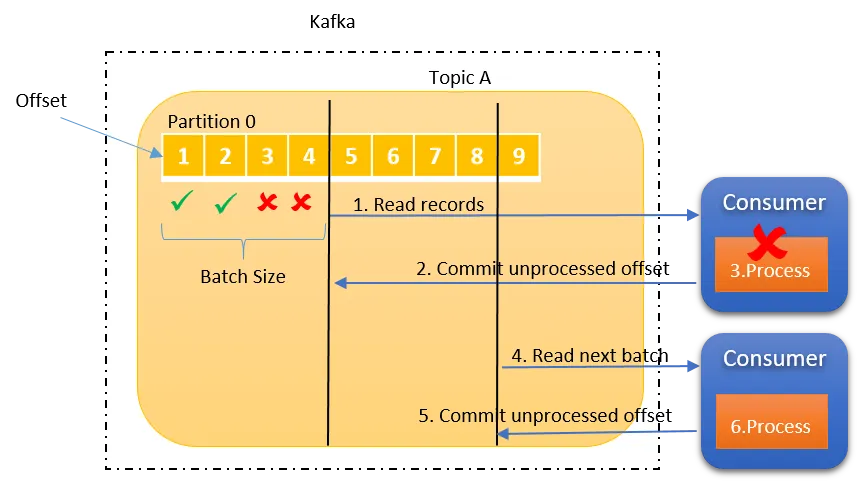
如下图所示,消息是分批读取的,批次中的部分或全部消息可能未处理,但仍已提交为已处理,这就造成了消息的丢失。
至少一次
在至少一次传递语义中,可以多次传递消息,但不应丢失任何消息。消费者确保所有消息都被读取和处理,即使这可能导致消息重复。为了在消费数据时做到至少一次语义,需要将“enable.auto.commit”值设置为“false”`,您可以选择在处理完消息后手动提交,这样你就掌握了消费偏移量提交的主动权,只有消费成功的消息偏移量才会提交。
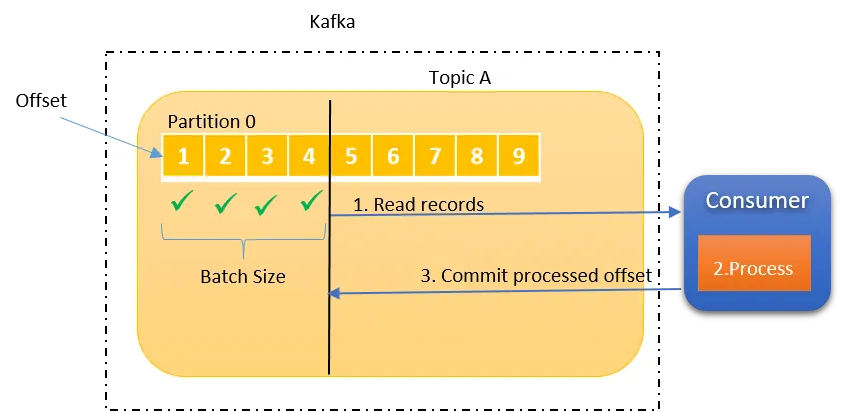
如果消费者在处理消息之前发生故障,未处理的消息不会丢失,因为偏移量未提交,分区重新平衡将导致另一个消费者从上次提交的偏移量再次读取相同的消息进进行处理。
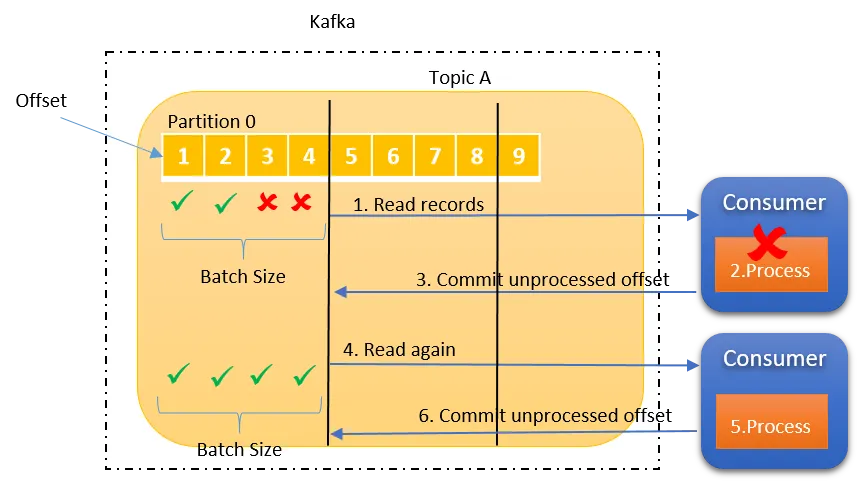
但是如果消费者在处理消息之后、提交消费偏移量之前发生故障,因为偏移量未提交,分区重新平衡将导致另一个消费者从上次提交的偏移量再次读取相同的消息进进行处理,这就导致这批消息会被重复消费。
精确一次
在精确一次传递语义中,一条消息只能传递一次,并且不能丢失任何消息。这是所有传递语义中最困难的。与其他两种语义相比,采用精确一次语义的应用程序可能具有较低的吞吐量和较高的延迟。
就像前面介绍的一样,可以通过选择适当的数据存储来实现类似于精确一次的语义。
我们可以通过选择支持幂等写入数据存储来实现。幂等写入意味着即使重复执行相同的写入操作,结果也不会改变。这可以确保在至少一次语义中,即使消息被多次处理,最终数据存储中的数据不会重复。
假设我们使用MySQL作为数据存储,并且每条消息都有一个唯一的ID(例如,消息偏移量)。我们将消息写入MySQL数据库的表中,并使用消息的唯一ID作为主键。
Properties props = new Properties();
props.put("bootstrap.servers", "broker1:9092,broker2:9092");
props.put("group.id", "my-group");
props.put("enable.auto.commit", "false"); // 禁用自动提交
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList("myTopic"));
try (Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/mydb", "user", "password")) {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
String insertSQL = "INSERT INTO my_table (id, value) VALUES (?, ?) ON DUPLICATE KEY UPDATE value=?";
try (PreparedStatement ps = connection.prepareStatement(insertSQL)) {
ps.setLong(1, record.offset());
ps.setString(2, record.value());
ps.setString(3, record.value());
ps.executeUpdate();
}
}
consumer.commitSync();
}
} catch (SQLException e) {
e.printStackTrace();
}
下面图表展示了如何使用消息偏移量作为唯一标识符进行幂等写入:
Kafka Topic: myTopic
+-----------+-----------+-----------+
| Offset 0 | Offset 1 | Offset 2 |
| Message A | Message B | Message C |
+-----------+-----------+-----------+
消费者读取消息并将其写入MySQL数据库:
+-------------------------------+
| MySQL数据库: my_table |
+-----------+-------------------+
| ID (Offset) | Value |
+-----------+-------------------+
| 0 | Message A |
| 1 | Message B |
| 2 | Message C |
+-----------+-------------------+
如果消息重复处理(例如,Offset 1的Message B),由于使用了ON DUPLICATE KEY UPDATE,写入操作将更新现有记录,而不会插入重复记录。



















