RDB和AOF持久化
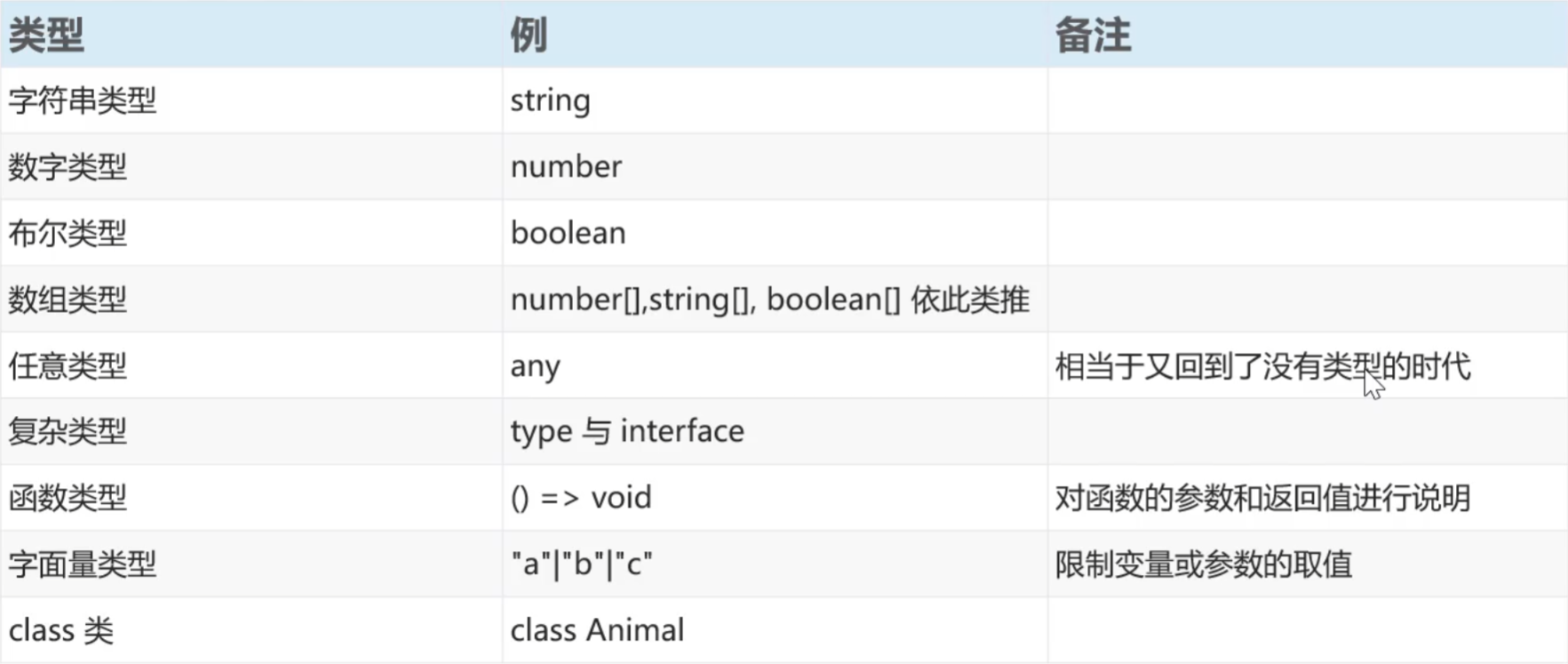
- 一、什么是持久化?
- 二、RDB
- 三、AOF
一、什么是持久化?
数据一般写在内存上,但是当重新启动计算机内存数据是会丢失的,而硬盘中的数据是不会丢失的,所以,当我们把数据从内存放到硬盘中的话就是内存持久化了。Redis ⽀持 RDB 和 AOF 两种持久化机制,持久化功能有效地避免因进程退出造成数据丢失问题,当下次重启时利⽤之前持久化的⽂件即可实现数据恢复。
二、RDB
RDB 持久化是把当前进程数据⽣成快照保存到硬盘的过程,触发 RDB 持久化过程分为手动触发和自动触发。
我们这里只介绍bgsave这个主动的命令,因为一般不用save(这个玩意是会阻塞住前台的,那么就必然会占用资源,让redis阻塞住了,完成不了其他的命令。)
bgsave 命令:Redis 进程执⾏ fork 操作创建⼦进程,RDB 持久化过程由⼦进程负责,完成后⾃动结束。阻塞只发⽣在 fork 阶段,⼀般时间很短。
(这里自动触发在这里一提:1. 使⽤ save 配置。如 “save m n” 表⽰ m 秒内数据集发⽣了 n 次修改,⾃动 RDB 持久化。2. 从节点进⾏全量复制操作时,主节点⾃动进⾏ RDB 持久化,随后将 RDB ⽂件内容发送给从结点。3. 执⾏ shutdown 命令关闭 Redis 时,执⾏ RDB 持久化)
bgsave流程图如下:

- 执⾏ bgsave 命令,Redis ⽗进程判断当前进程是否存在其他正在执⾏的⼦进程,如 RDB/AOF ⼦进程,如果存在 bgsave 命令直接返回。
- ⽗进程执⾏ fork 创建⼦进程,fork 过程中⽗进程会阻塞,通过 info stats 命令查看latest_fork_usec 选项,可以获取最近⼀次 fork 操作的耗时,单位为微秒。
- ⽗进程 fork 完成后,bgsave 命令返回 “Background saving started” 信息并不再阻塞⽗进程,可以继续响应其他命令。
- ⼦进程创建 RDB ⽂件,根据⽗进程内存⽣成临时快照⽂件,完成后对原有⽂件进⾏原⼦替换。执
⾏ lastsave 命令可以获取最后⼀次⽣成 RDB 的时间,对应 info 统计的 rdb_last_save_time 选项。 - 进程发送信号给⽗进程表⽰完成,⽗进程更新统计信息。
- 简单总结一下:父进程负责创建子进程让子进程打工和继续执行其他请求,子进程负责生成RDB文件。
RDB快照存放位置:


RDB优缺点:
• RDB 是⼀个紧凑压缩的⼆进制⽂件,代表 Redis 在某个时间点上的数据快照。⾮常适⽤于备份,全量复制等场景。⽐如每 6 ⼩时执⾏ bgsave 备份,并把 RDB ⽂件复制到远程机器或者⽂件系统中(如 hdfs)⽤于灾备。
• Redis 加载 RDB 恢复数据远远快于 AOF 的⽅式。
• RDB ⽅式数据没办法做到实时持久化 / 秒级持久化。因为 bgsave 每次运⾏都要执⾏ fork 创建⼦进程,属于重量级操作,频繁执⾏成本过⾼。
• RDB ⽂件使⽤特定⼆进制格式保存,Redis 版本演进过程中有多个 RDB 版本,兼容性可能有⻛险。
三、AOF
AOF(Append Only File)持久化:以独⽴⽇志的⽅式记录每次写命令,重启时再重新执⾏ AOF⽂件中的命令达到恢复数据的⽬的。AOF 的主要作⽤是解决了数据持久化的实时性。
AOF对redis性能是否有影响?
我们有这样一个问题,AOF既然是实时的,那么必然一边写内存一边写硬盘,这必然会导致性能变慢呀!但是事实并非如此,我们的AOF并非是直接让工作线程把数据写入硬盘,而是先写入一个内存中的缓冲区,积累了一波之后,再统一写入硬盘中,那么必然不会对redis性能产生影响。
工作流程:

- 所有的写⼊命令会追加到 aof_buf(缓冲区)中。
- AOF 缓冲区根据对应的策略向硬盘做同步操作。
- 随着 AOF ⽂件越来越⼤,需要定期对 AOF ⽂件进⾏重写,达到压缩的⽬的。
- 当 Redis 服务器启动时,可以加载 AOF ⽂件进⾏数据恢复。
AOF 过程中为什么需要 aof_buf 这个缓冲区?Redis 使⽤单线程响应命令,如果每次写 AOF ⽂件都直接同步硬盘,性能从内存的读写变成 IO 读写,必然会下降。先写⼊缓冲区可以有效减少 IO 次数,同时,Redis 还可以提供多种缓冲区同步策略,让⽤⼾根据⾃⼰的需求做出合理的平衡。(就像你嗑瓜子扔瓜子皮的时候,嗑一个丢一个皮跟嗑很多很多积极攒起来丢进垃圾桶的效率是一样!)
文件同步?
文件同步分为三类

大白话就是always就是不停地写入aof_buf后直接进行修改同步到硬盘中,eversec就是每秒进行一次同步,no就是让操作系统内核自己控制同步的频率。一般用的是第二种,第一种可靠性高但效率低,第三种可靠性低但效率高。
系统调⽤ write 和 fsync 说明:
• write 操作会触发延迟写(delayed write)机制。Linux 在内核提供⻚缓冲区⽤来提供硬盘 IO 性能。write 操作在写⼊系统缓冲区后⽴即返回。同步硬盘操作依赖于系统调度机制,例如:缓冲区⻚空间写满或达到特定时间周期。同步⽂件之前,如果此时系统故障宕机,缓冲区内数据将丢失。
• Fsync 针对单个⽂件操作,做强制硬盘同步,fsync 将阻塞直到数据写⼊到硬盘。
• 配置为 always 时,每次写⼊都要同步 AOF ⽂件,性能很差,在⼀般的 SATA 硬盘上,只能⽀持⼤约⼏百 TPS 写⼊。除⾮是⾮常重要的数据,否则不建议配置。
• 配置为 no 时,由于操作系统同步策略不可控,虽然提⾼了性能,但数据丢失⻛险⼤增,除⾮数据重要程度很低,⼀般不建议配置。
• 配置为 everysec,是默认配置,也是推荐配置,兼顾了数据安全性和性能。理论上最多丢失 1 秒的数据
AOF重写?
流程图:
(1)如果当前进程正在执⾏ AOF 重写,请求不执⾏。如果当前进程正在执⾏ bgsave 操作,重写命令延迟到 bgsave 完成之后再执⾏。
(2)⽗进程执⾏ fork 创建⼦进程。
(3)重写
a. 主进程 fork 之后,继续响应其他命令。所有修改操作写⼊ AOF 缓冲区并根据 appendfsync 策略同步到硬盘,保证旧 AOF ⽂件机制正确。
b. ⼦进程只有 fork 之前的所有内存信息,⽗进程中需要将 fork 之后这段时间的修改操作写⼊AOF 重写缓冲区中。
4. ⼦进程根据内存快照,将命令合并到新的 AOF ⽂件中。
5. ⼦进程完成重写
a. 新⽂件写⼊后,⼦进程发送信号给⽗进程。
b. ⽗进程把 AOF重写缓冲区内临时保存的命令追加到新 AOF ⽂件中。
c. ⽤新 AOF ⽂件替换⽼ AOF ⽂件。

问题:为什么要有aof_rewrite_buf?
一、避免数据丢失和不一致
- 保证数据完整性:
- 当进行 AOF(Append Only File)重写时,Redis 会创建一个新的 AOF 文件来替换旧的文件。在这个过程中,如果直接将新的写操作写入新的 AOF 文件,可能会导致部分数据丢失。
- aof_rewrite_buf 作为一个缓冲区,用于暂存新的写操作,确保在 AOF 重写过程中,新的写操作不会丢失,保证了数据的完整性。
- 维持数据一致性:
- 如果没有这个缓冲区,在 AOF 重写期间,新的写操作可能会直接影响正在重写的 AOF 文件,导致重写后的文件与数据库的实际状态不一致。
- aof_rewrite_buf 的存在使得新的写操作可以在重写完成后再被正确地处理,从而保证了数据的一致性。
二、提高重写效率
- 减少磁盘 I/O:
- 避免在重写过程中频繁地写入新的 AOF 文件,可以减少磁盘 I/O 操作,提高重写的效率。
- 新的写操作先写入缓冲区,等重写完成后再一次性地处理,可以减少对磁盘的写入次数。
- 并行处理:
- 在 AOF 重写的同时,Redis 可以继续处理客户端的请求,新的写操作被放入 aof_rewrite_buf 。这样可以实现重写和正常的数据库操作并行进行,提高了 Redis 的整体性能。
三、实现的便利性
- 简化重写逻辑:
- 有了 aof_rewrite_buf ,Redis 可以更方便地管理 AOF 重写过程中的新写操作。
- 重写过程只需要关注旧的 AOF 文件的读取和新文件的生成,而不必直接处理新的写操作,简化了重写的逻辑。
Redis 根据持久化⽂件进⾏数据恢复: