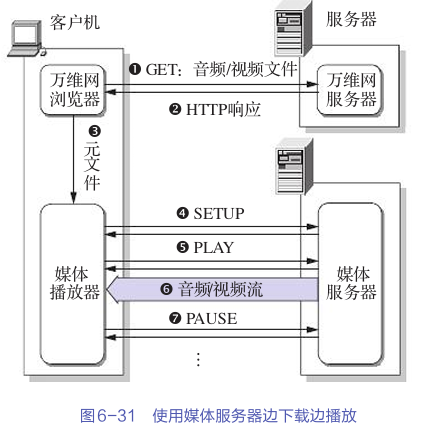
mean()
mean()函数是进行张量均值计算的函数,常用参数可以设置参数dim来进行对应维度的均值计算
以下是使用一个二维张量进行演示的例子
import numpy as np
import torch
device = torch.device('mps' if torch.backends.mps.is_available() else 'cpu')
print(device
)
data1 = torch.randint(0,10,(2,3),dtype=torch.float).to(device)
print(data1)
print(data1.mean())
print(data1.mean(dim = 0))
print(data1.mean(dim = 1))
# mps
# tensor([[2., 8., 2.],
# [7., 3., 7.]], device='mps:0')
# tensor(4.8333, device='mps:0')
# tensor([4.5000, 5.5000, 4.5000], device='mps:0')
# tensor([4.0000, 5.6667], device='mps:0')
可以看到在不指定dim维度的情况下,mean()函数会对所有张量元素进行求和后的均值计算,结果是一个标量张量
在指定了dim为0后,均值计算会沿着行方向去求每一列的均值
在指定了dim为1后,均值计算会沿着列方向去求每一行的均值
sum()
sum()函数为求和函数,同样类似于mean()函数,可以指定参数dim来进行指定维度上的求和计算
以下同样是一个二维张量的演示例子
import numpy as np
import torch
device = torch.device('mps' if torch.backends.mps.is_available() else 'cpu')
print(device
)
data1 = torch.randint(0,10,(2,3),dtype=torch.float).to(device)
print(data1)
print(data1.sum())
print(data1.sum(dim = 0))
print(data1.sum(dim = 1))
# mps
# tensor([[3., 4., 1.],
# [8., 6., 0.]], device='mps:0')
# tensor(22., device='mps:0')
# tensor([11., 10., 1.], device='mps:0')
# tensor([ 8., 14.], device='mps:0')
sum()函数在不指定dim的时候也是对所有张量元素求和计算
在指定了dim为0后,求和计算会沿着行方向去求每一列的和
在指定了dim为1后,求和计算会沿着列方向去求每一行的和
pow()
pow()函数是对张量进行幂次计算的函数,参数为指定指数值exponoent
import numpy as np
import torch
device = torch.device('mps' if torch.backends.mps.is_available() else 'cpu')
print(device
)
data1 = torch.randint(0,10,(2,3),dtype=torch.float).to(device)
print(data1)
print(data1.pow(2))
# mps
# tensor([[2., 5., 9.],
# [4., 2., 7.]], device='mps:0')
# tensor([[ 4., 25., 81.],
# [16., 4., 49.]], device='mps:0')
上面的例子中指定了指数为2,底数为张量中的每个元素值
sqrt()
sqrt()函数是用于对张量进行开二次方根计算的,无需参数设置
import numpy as np
import torch
device = torch.device('mps' if torch.backends.mps.is_available() else 'cpu')
print(device
)
data1 = torch.randint(0,10,(2,3),dtype=torch.float).to(device)
print(data1)
print(data1.sqrt())
# mps
# tensor([[7., 6., 2.],
# [6., 3., 9.]], device='mps:0')
# tensor([[2.6458, 2.4495, 1.4142],
# [2.4495, 1.7321, 3.0000]], device='mps:0')
注意,由于sqrt函数无法进行高次方根的计算,所以若有高次方根的计算需求,可以依旧使用pow()函数进行计算,以下为三次方根的计算演示
import numpy as np
import torch
device = torch.device('mps' if torch.backends.mps.is_available() else 'cpu')
print(device
)
data1 = torch.randint(0,10,(2,3),dtype=torch.float).to(device)
print(data1)
print(data1.pow(1/3))
# mps
# tensor([[2., 7., 8.],
# [1., 0., 1.]], device='mps:0')
# tensor([[1.2599, 1.9129, 2.0000],
# [1.0000, 0.0000, 1.0000]], device='mps:0')
exp()
exp()函数适用于计算底数为e(约等于2.71828)的幂次计算,同样不需要参数指定,指数值就为张量的每个元素值.
import numpy as np
import torch
device = torch.device('mps' if torch.backends.mps.is_available() else 'cpu')
print(device
)
data1 = torch.randint(0,10,(2,3),dtype=torch.float).to(device)
print(data1)
print(data1.exp())
# mps
# tensor([[4., 3., 9.],
# [0., 6., 9.]], device='mps:0')
# tensor([[5.4598e+01, 2.0086e+01, 8.1031e+03],
# [1.0000e+00, 4.0343e+02, 8.1031e+03]], device='mps:0')
log()
log()函数是用于对数计算的函数,底数为e,为了方便更改底数常用的还有log2(底数为2),log10(底数为10)
import numpy as np
import torch
device = torch.device('mps' if torch.backends.mps.is_available() else 'cpu')
print(device
)
data1 = torch.randint(0,10,(2,3),dtype=torch.float).to(device)
print(data1)
print(data1.log())
print(data1.log2())
print(data1.log10())
# mps
# tensor([[0., 7., 8.],
# [7., 0., 1.]], device='mps:0')
# tensor([[ -inf, 1.9459, 2.0794],
# [1.9459, -inf, 0.0000]], device='mps:0')
# tensor([[ -inf, 2.8074, 3.0000],
# [2.8074, -inf, 0.0000]], device='mps:0')
# tensor([[ -inf, 0.8451, 0.9031],
# [0.8451, -inf, 0.0000]], device='mps:0')
上面分别演示了log,log2,log10也就是底数分别为e,2,10的对数计算结果
在实际情况中我们可能对底数的选择更加灵活,如果要计算任意底数的对数,这里我们就可以用到下面的公式进行计算
这里对任意底数b进行对数计算,都可以转换成另一底数但是真数分别为原真数和广播后的原底数的商
import numpy as np
import torch
device = torch.device('mps' if torch.backends.mps.is_available() else 'cpu')
print(device
)
data1 = torch.randint(0,10,(2,3),dtype=torch.float).to(device)
print(data1)
print(data1.log()/torch.full_like(data1,3).log())
# mps
# tensor([[9., 1., 6.],
# [4., 2., 3.]], device='mps:0')
# tensor([[2.0000, 0.0000, 1.6309],
# [1.2619, 0.6309, 1.0000]], device='mps:0')

![[数据集][目标检测]电力场景输电线异物检测数据集VOC+YOLO格式2060张1类别](https://i-blog.csdnimg.cn/direct/087fcbb6be024598bf6ab04a9457483d.png)





![[医疗 AI ] 3D TransUNet:通过 Vision Transformer 推进医学图像分割](https://i-blog.csdnimg.cn/direct/d32a0be7130540f293c4066cc9f1ccf5.png#pic_center)