文章目录
- 滑动窗口
- 窗口
- 滑动
- 滑动窗口丢包
- 流量控制
- 拥塞控制
- 窗口大小变化过程
滑动窗口
有一类算法题,就是通过滑动窗口的思想来解决的,算法中的“滑动窗口”借鉴自 TCP 的滑动窗口
TCP 是要保证可靠传输的==>代价,降低了传输的效率(重传,确认重传等操作)
TCP 希望能在可靠传输的基础上,也有一个不错的效率,就引入了“滑动窗口”
- 这里的提高效率,只是“亡羊补牢”,使传输效率的损失,尽可能降低
- 引入滑动窗口,也不能使传输效率比 UDP 还高
窗口
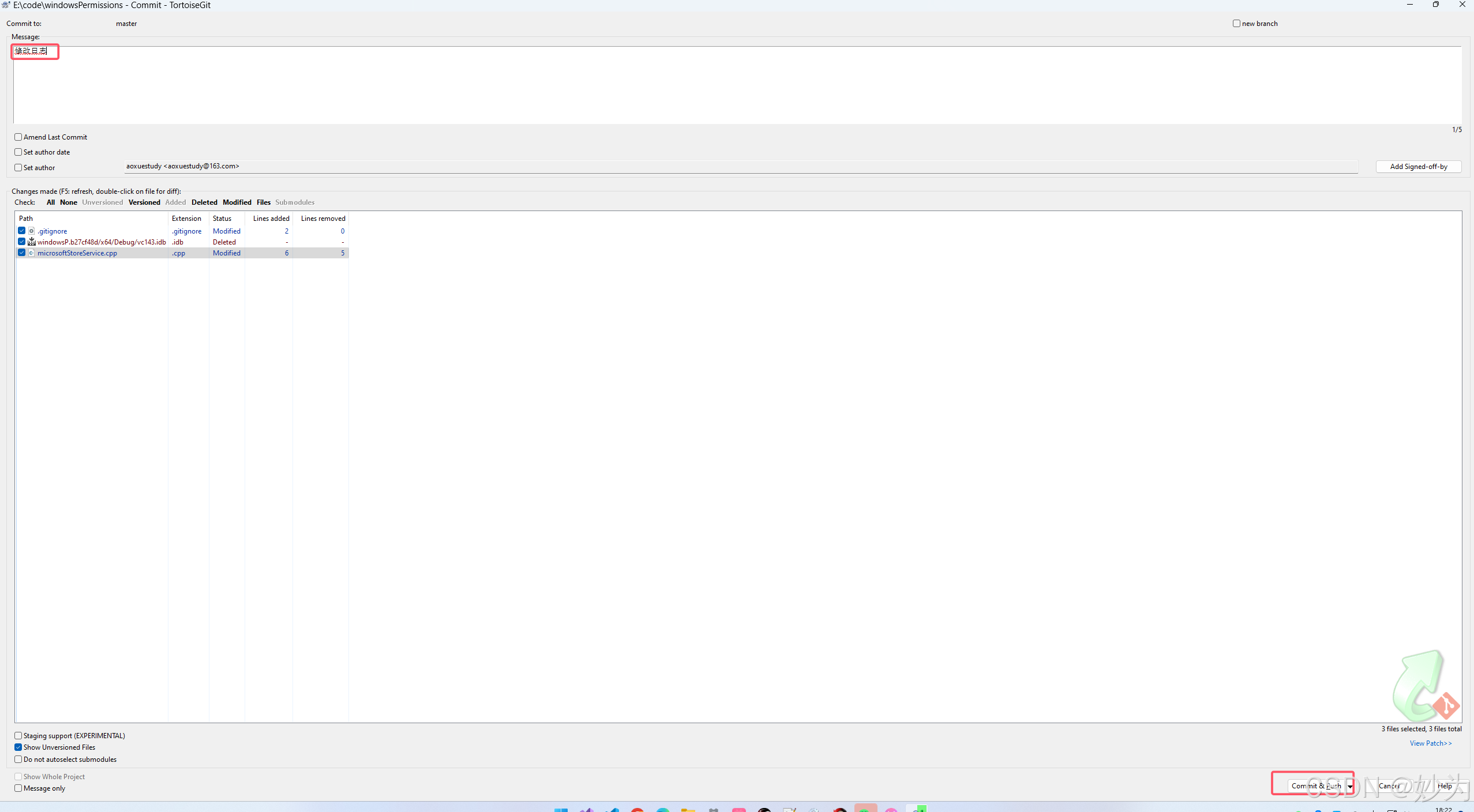
A 每次都需要收到 ACK 之后,再发下一个数据
- 低效,有大量的时间都消耗在等待 ACK 上
改进方案:
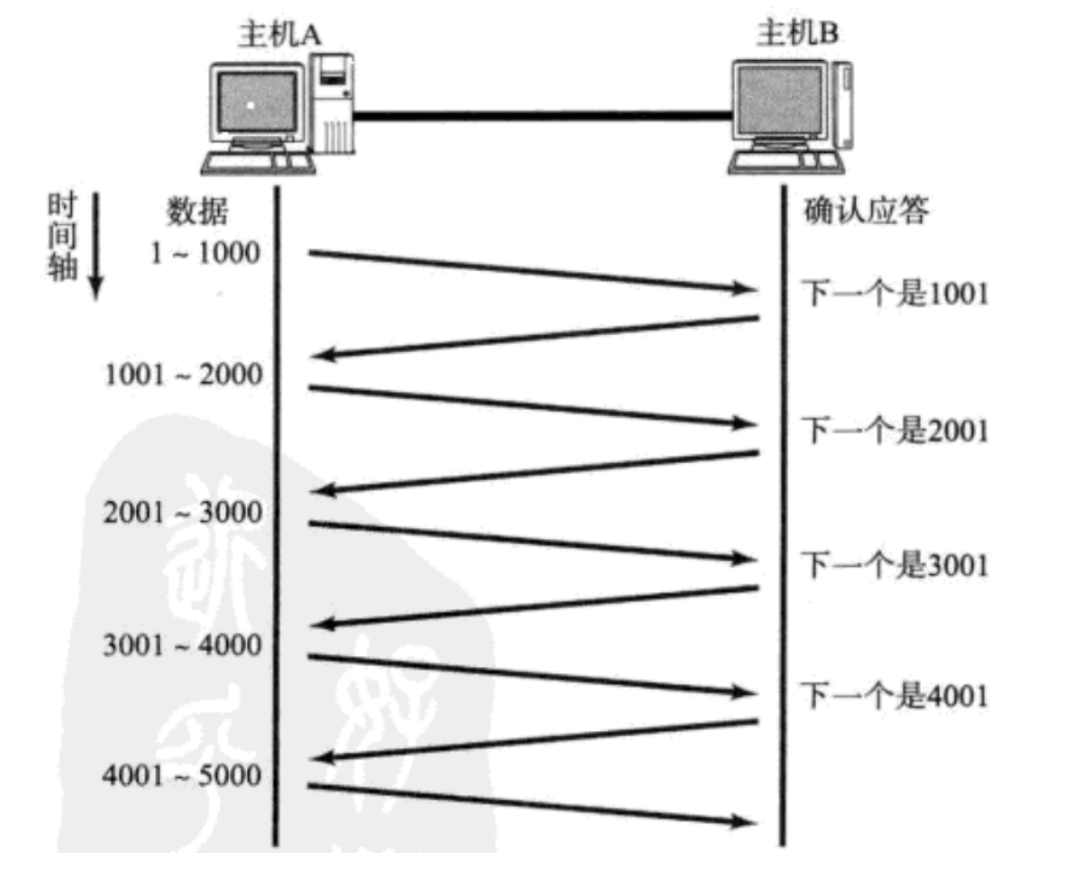
- 把“发送一个等待一个”改为“发送一批等待一批”
- 把多次等待 ACK 的时间合并时一份了
- 批量发送的数据越多,效率就越高
- 批量发送的数据中,不需要等待的数据的量,称为“窗口大小”
- 批量发送的是数据的字节数,而不是条
- 窗口就是一次能发多少数据,具体的数据量就是窗口大小
滑动
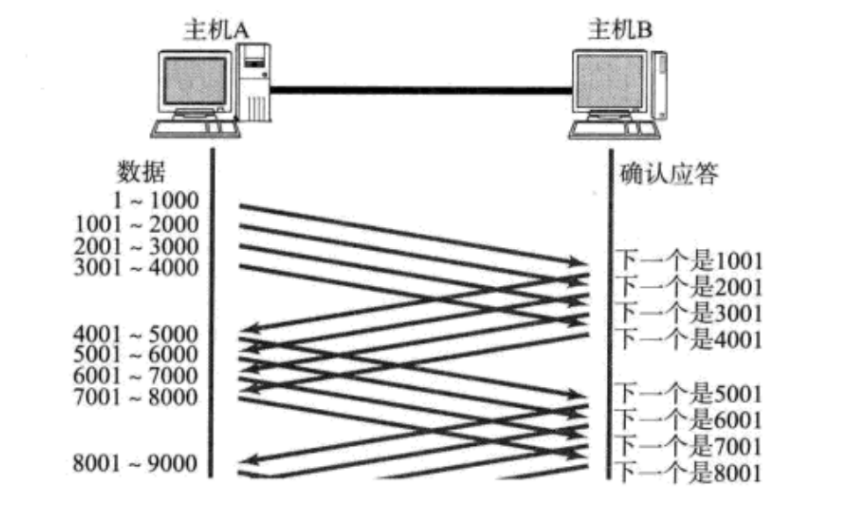
当收到了第一个 ACK 之后,不会继续等待剩下的 3 个 ACK 到了之后再发下一组,而是收到这个 ACK 之后,就立即发送下一条数据
- 收到
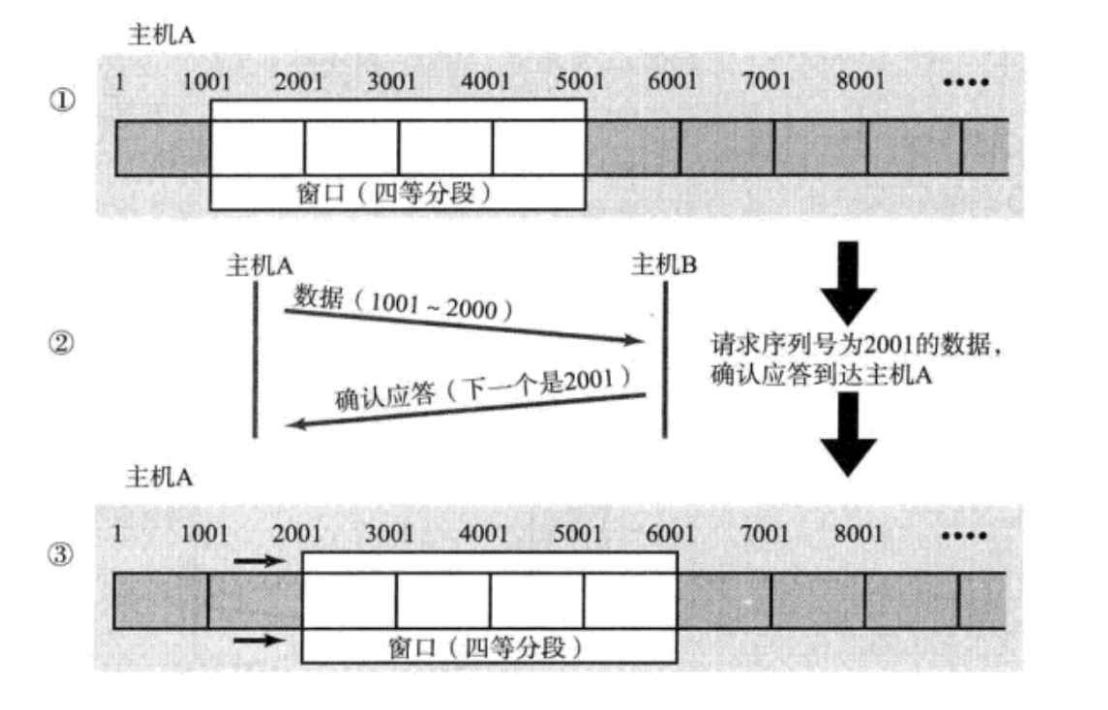
2001 ACK,说明1001-2000数据得到应答了 - 然后立即发送
5001-6000这个数据,此时等待的ACK范围就是2001-6000(四份数据),窗口大小还是 4000 - 窗口大小不变,只是窗口所处的位置改变了
每收到一个 ACK,窗口就往后挪,因为 ACK 是接连不断的发送的,所以窗口就往后挪动了,就滑起来了
滑动窗口就是批量传输数据的一种实现方式
滑动窗口丢包
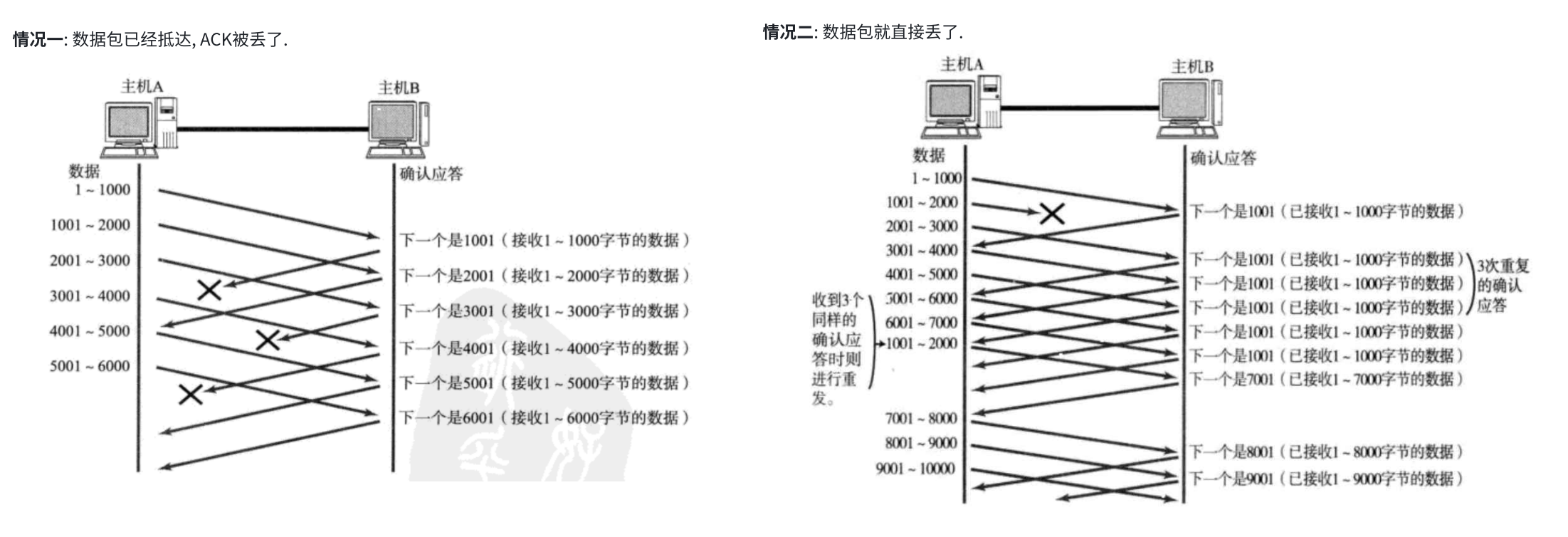
情况一:
不需要任何处理;批量发数据,批量 ACK,多个 ACK 只是丢其中的一部分,不可能全丢
确认序号的含义:表示的是收到的数据最后一个字节的下一个序号。进一步理解成,确认序号之前的数据,都已经收到了,接下来你要发的数据就从确认序号这里往后发
- 虽然 1001 ACK 丢了,但是 2001 ACK 到达了。发送方收到 2001 ACK 之后,意味着 2001 之前的数据都已经收到了
- 后一个
ACK能涵盖前一个ACK的意义
情况二:
1001-2000 丢包之后:
- 在
A发过去2001-3000之后,此时,B收到的数据为:1-1000,2001-3000 - 此时
B收到2001-3000的时候,返回的ACK确认序号不是3001,而是1001 B就是在向A索要1001的数据- 接下来,
B和搜到的3001-4000,4001-5000,5001-6000.… 对应的ACK确认序号都是1001 - 主机
A连续收到1001这样的ACK之后,主机A意识到1001数据包丢了,于是主机重传1001-2000 - 当
1001-2000重传过来之后,由于执勤啊2001-7000数据都是已经发过了,此时的1001-2000相当于是补全了之前的空缺,此时就意味着1-7000的数据都齐了,于是接下来索要7001开头的数据即可
上述过程,没有任何拖泥带水的操作,快速的识别出了是哪个数据丢包,并且针对性的进行了重传,其他顺利到达的数据都无需重传,这个过程称为“快速重传”
快速重传可以视为是“滑动窗口”下搭配的“超时重传”
滑动窗口/快速重传、确认应答/超时重传
他们彼此之间并不冲突。如果通信双方单位时间发送的数据量比较少,就是按照之前的确认应答/超时重传;如果单位时间内发送的数据比较多,就会按照滑动窗口/快速重传
流量控制
滑动窗口,窗口大小对于传输数据的性能是直接相关的,但窗口能无限大吗?
通信是双方的事,发送方发的快乐,你也得确保接收方能处理得过来
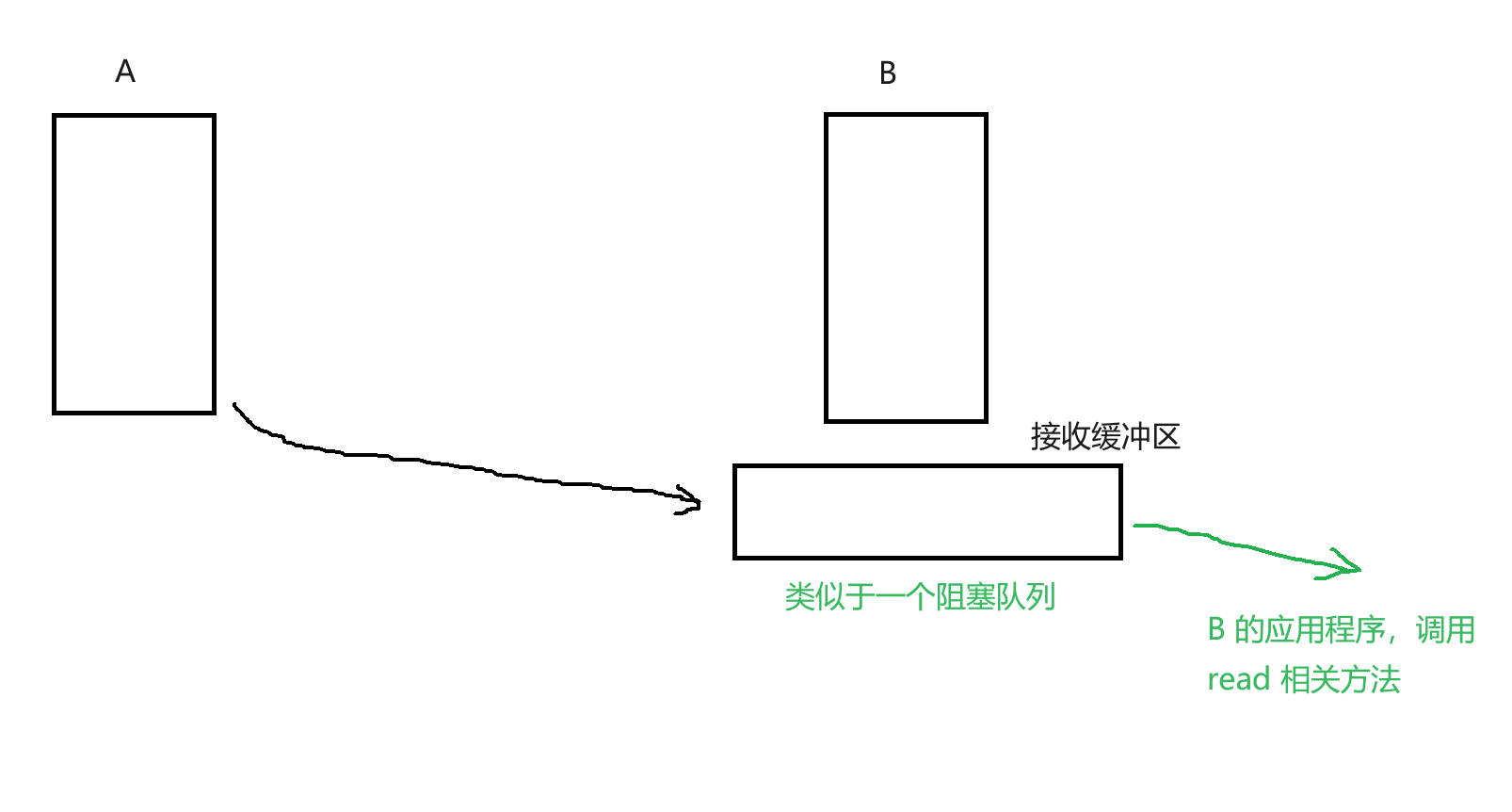
- 接收缓冲区:内核中的内存空间,每个
Socket对象都有一个这样的缓冲区,其类似于一个阻塞队列(BlockingQueue) - 这个传输过程就是一个“生产者消费者模型”
- 如果发送速度特别快,消费数据比较慢,就会使接收缓冲区满,此时如果继续强行发送数据,就会“丢包”(被接收方丢弃)
- 这里就需要根据接收方的处理能力,反向制约发送方的发送速度,这就是流量控制
此处可以通过“定量”的方式来实现制约,看接收缓冲区剩余空间大小
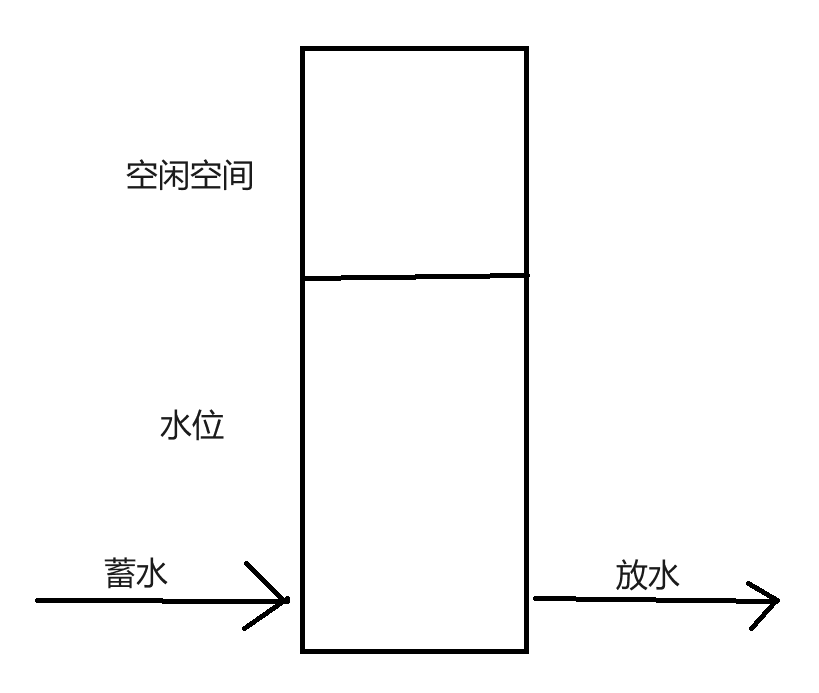
- 如果空闲空间比较大,就可以认为应用程序处理速度比较快
- 就可以让发送方发的快一点,设置一个更大的窗口大小
- 如果空闲空间比较小,就可以认为应用程序处理速度比较慢
- 就可以让发送方发的慢一点,设置一个更小的窗口大小
TCP 中,接收方收到数据的时候,就是把接收缓冲区剩余空间大小通过 ACK 数据报,反馈给发送方。之后发送方就可以依据这个数据来设置发送的窗口大小了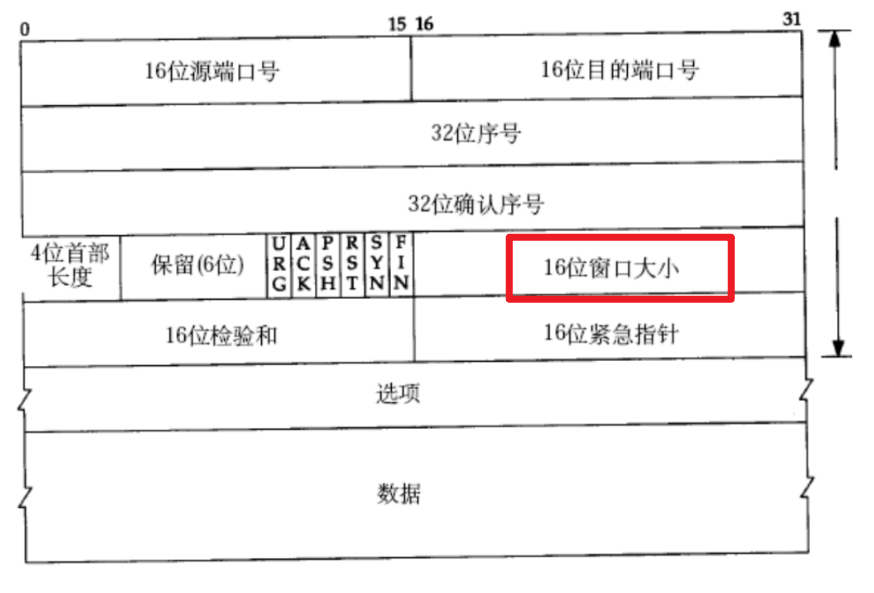
- 这里面的“
16位窗口大小”体现了刚才谈到的接收方接收缓冲区的剩余空间,这个属性只有在ACK报文中才有效(ACK这一位为1)
此处的 16 位表示范围 64KB,是否意味着发送方窗口大小最大就是 64KB 呢?
- 不是的
- 选项中,可以设置一个特殊的选项“窗口扩展因子”
- 发送方的窗口大小 = 窗口大小 << 窗口扩展因子(左移运算符)
- 左移一位就相当于
*2
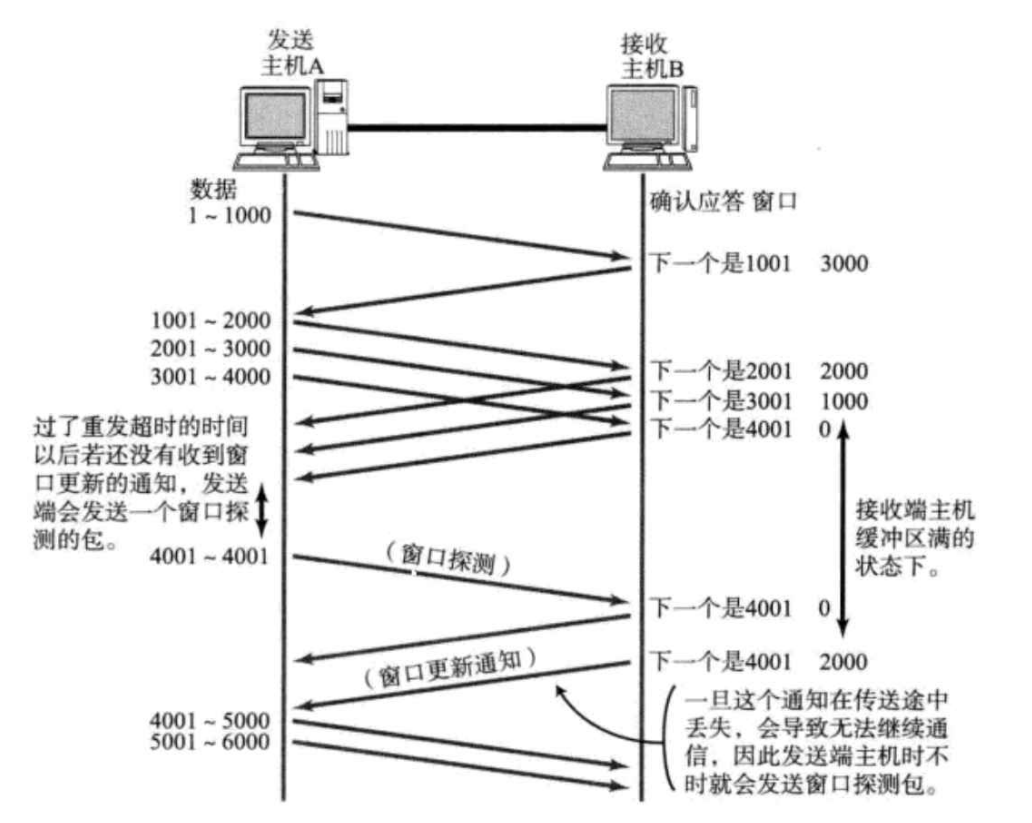
此时假设接收方应用程序没有读取任何数据,就是一直在生产,却没有消费,最后发送方的窗口大小就变成 0 了,接收缓冲区就满了,发送方就不能再发送了。那发送方不发送数据,要等待多久呢?
- 原本是要通过 ACK 来知道对方接收缓冲区中的剩余空间的,但是不发送数据就没有 ACK 呀
- 所以当窗口大小为 0 的时候,等待一个“超时时间”后,会发送一个“窗口探测包”,不携带任何业务数据(载荷部分是空的),只是为了触发 ACK,通过这个操作来查询一下,接收方接收缓冲区剩余多少。如果还是 0,就过一会之后再查
- 接收方也会在接收缓冲区不为 0 的时候(消费了一定数据之后),主动触发一个“窗口更新通知”这样的数据,告诉接收方缓冲区内的余量情况
流量控制,也不是 TCP 独有的机制,其他的协议也可能会涉及到流量控制(比如,数据链路层中有的协议也支持流量控制)
拥塞控制
这个操作,也是和刚才的流量控制有关联的
- 滑动窗口==>踩油门
- 流量控制==>踩刹车
- 拥塞控制==>踩刹车
流量控制,是站在接收方的视角来限制发送方的速度
拥塞控制,是站在传输链路的视角来限制发送方的速度
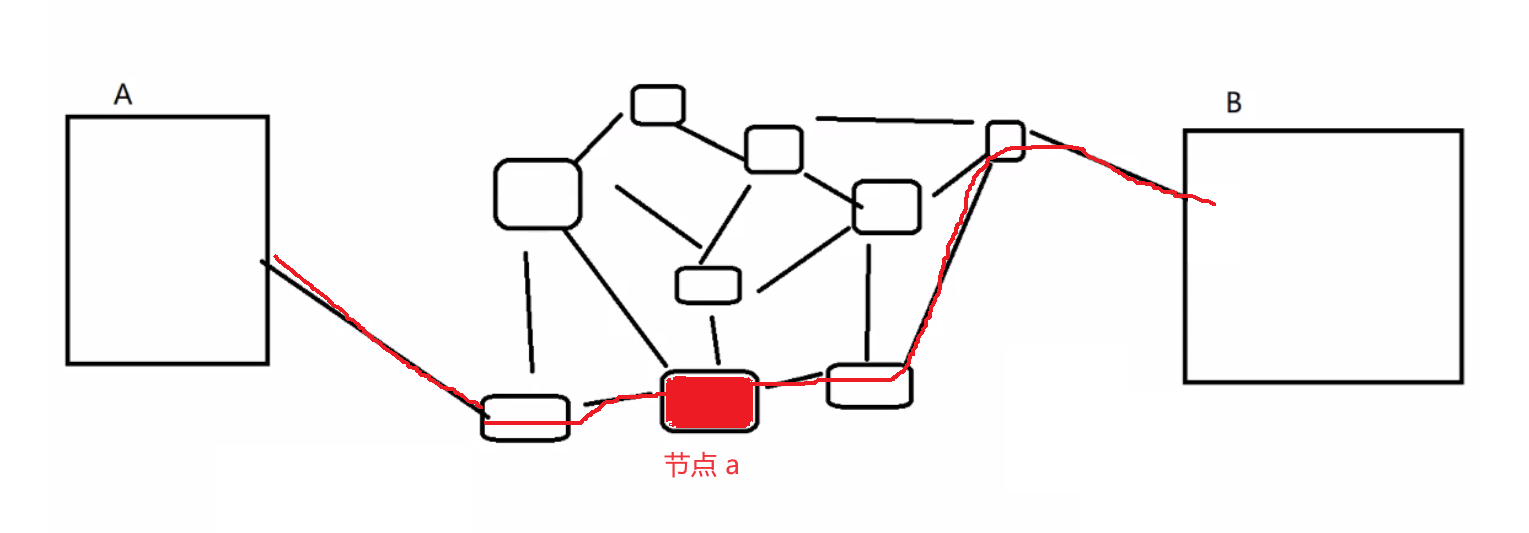
假设 B 处理速度非常快,此时 A 可以无限速度的发送数据吗?
- 当然不行,中间的链路可能顶不住
- 此时节点 a 已经负载很高了,如果 A 发送很快,那么这个节点可能就直接丢包了
流量控制,就可以精准的使用接收方接收缓冲区来进行衡量
考量中间节点的情况就麻烦了
- 中间的节点非常多
- 每次传输数据,走的路线还都不一样
- 中间哪个节点遇到瓶颈了不清除
- 中间节点传输数据不止有 A 的,还有很多其他设备的数据
别害怕,可以通过做实验的方式,来找到一个合适的发送速度
- 在拥塞控制中,将中间所有的节点视为一个整体,不关心内部的细节
然后进行“实验”(面多加水,水多加面)
- 先按照一个比较小的速度,发送数据
- 数据非常畅通,没有丢包,说明网络上传输数据整体是比较畅通的,就可以加快传输数据的速度
- 增大到一定的速度之后,发现出现丢包了,说明网络上可能存在拥堵了,就减慢传输数据的速度
- 减速之后,发现又不丢包了,继续再加速
- 加速之后又丢包了,再减速
- …
一直持续地动态变化,这是很科学的,因为网络环境也是一直变化的,所以以变化应对变化
流量控制会限制发送窗口,拥塞控制也会限制发送窗口。这两个机制会同时起作用,最终实际的发送窗口大小,取决于上述两个机制得到的发送窗口较小值
窗口大小变化过程
-
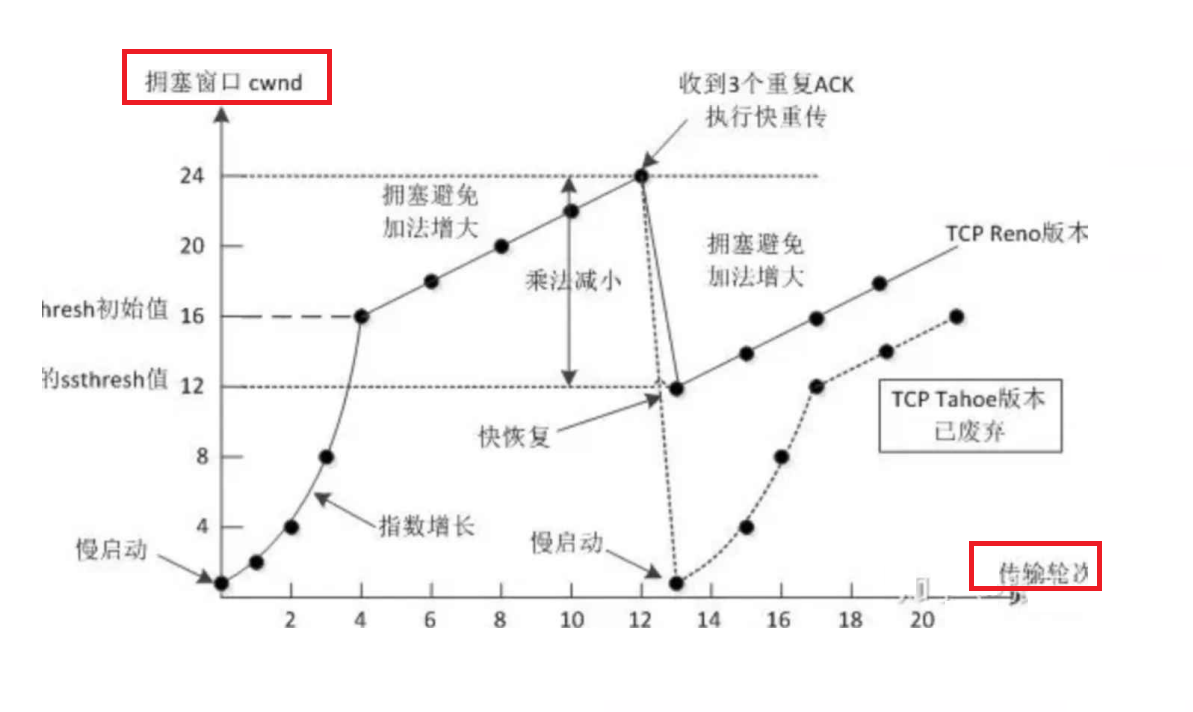
刚开始传输数据,拥塞窗口会非常小,用一个很小的速度来发送数据(慢启动)
- 因为当前网络是否拥堵是未知的
-
不丢包,增大窗口大小(指数增长)
- 每过一轮,窗口大小就翻倍,增长速度特别快,会在短时间内达到很大的窗口大小
-
增长到一定程度,达到某个指定的阈值,此时即使没有丢包,也会停止指数增长,变成线性增长
- 这样就不会太快的进入丢包的节奏
-
线性增长也会持续使发送速度越来越快,达到某个情况下,就会出现丢包
- 一旦出现丢包,接下来就需要减慢发送速度,也就是减少窗口大小
此时有两种处理方式:
- 经典的方案,回归慢启动开始非常小的初始值,先指数增长,再线性增长
- 现在的方案,回归到新的阈值上,直接进行线性增长(以后都不会指数增长了)