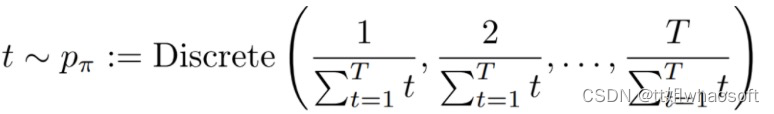在Linux应用层开发中,使用的锁大多都是基于Posix提供的版本。其中,锁的实现,是基于futex调用来完成的,而futex建立在原子访问和内核系统调用上。通过查阅相关资料,发现futex不完全是内核层的实现,如果锁未被占用,则该调用在应用层完成。只有在锁已被其他任务占用,需要将当前任务挂起睡眠时,才通过系统调用进入内核,由内核完成挂起的操作。
在判断锁是否占用时,会涉及原子访问的问题。但是,这个在应用层如何实现?对于内核层,我们知道,原子操作是基于处理器的专用指令来完成的。比如,对于ARMv7,提供了LDREX和STREX分别用于内存数据的加载和存储。在这两个指令之间的数据修改,硬件可以保证是原子的。具体的实现,可以参考博文:
学内核之七:问题三,全局变量加锁与每CPU变量_龙赤子的博客-CSDN博客_全局变量加锁。
回到开头提的问题,在应用层如何实现类似的原子访问?是否也是通过上述指令?我们来具体实践一下,看看结果如何。
通过查找资料(https://gcc.gnu.org/onlinedocs/gcc/_005f_005fsync-Builtins.html#index-_005f_005fsync_005ffetch_005fand_005fadd),发现编译器提供了类似的接口函数,也就是如下一系列函数接口
__sync_fetch_and_##OP##
__sync_##OP##_and_fetch
这里的OP,可以是add、sub、or、and、xor等等。分别对应了不同的运算逻辑。
很多资料都提到了用上述接口实现原子访问。于是,在程序中使用上述接口,实现一个访问共享全局变量的小程序,然后反汇编,检查一下上述接口是否用的是处理器特定的指令。比如,ARMv7的LDREX/STREX类指令。
为了方便汇编分析,例子代码很短很简单。我们随便找了上述一个接口,来测试验证。如下:

基于ARM32平台编译上述代码。
使用objdump反汇编以后,结果如下:

汇编中,如上图133、134行所示,将全局变量的地址放入r0寄存器,将常量1放入r1寄存器,这两个寄存器作为参数,调用sync接口。该接口的反汇编代码如下:
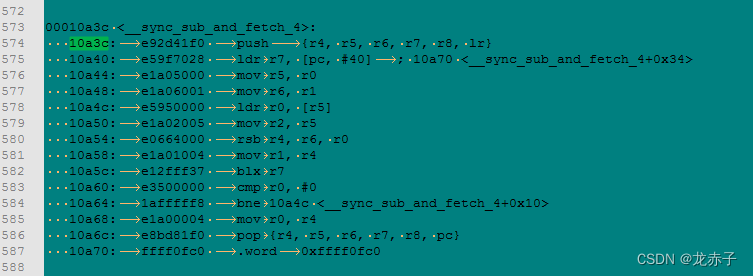
在上述代码里,首先寄存器入栈。然后将10a70位置的内存数据0xffff0fc0存入r7寄存器中。之后通过寄存器操作,将参数传递进来的常量地址处的内容再次存入r0寄存器,跟r6保存的常量进行运算,结果再次存入r1寄存器。并在582行处,执行blx r7(注意,此时,r0和r1寄存器保存了新的参数)。之后,比较r0和0,如果不相等,就继续跳转到10a4c,进行循环处理和判断。否则,将r4的内容放到r0,作为返回值,返回。
可以看到,上面没有明确的LDREX/STREX类指令调用。难道跟上述指令无关?那应用层是如何实现原子操作的?另外,我们也注意到,582行的汇编指令看着有点奇怪。为啥要跳转到r7寄存器位置处?r7寄存器的内容是0xffff0fc0,这个内容有什么特别吗?
暂时放下上面的疑问,我们去看看上述sync函数的实现。下载了一份gcc的源码,搜索了一下,找到了上述函数的定义。
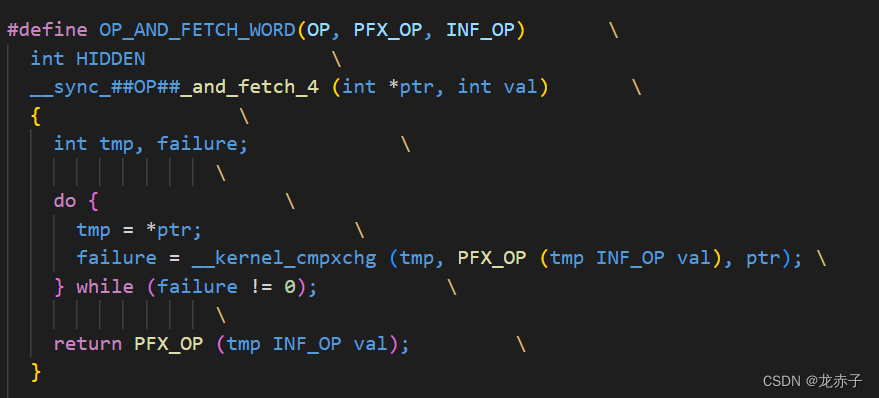
初看,能跟上面的汇编对应上。
这里关键的代码就是
failure = __kernel_cmpxchg (tmp, PFX_OP (tmp INF_OP val), ptr);
这里的__kernel_cmpxchg定义如下:
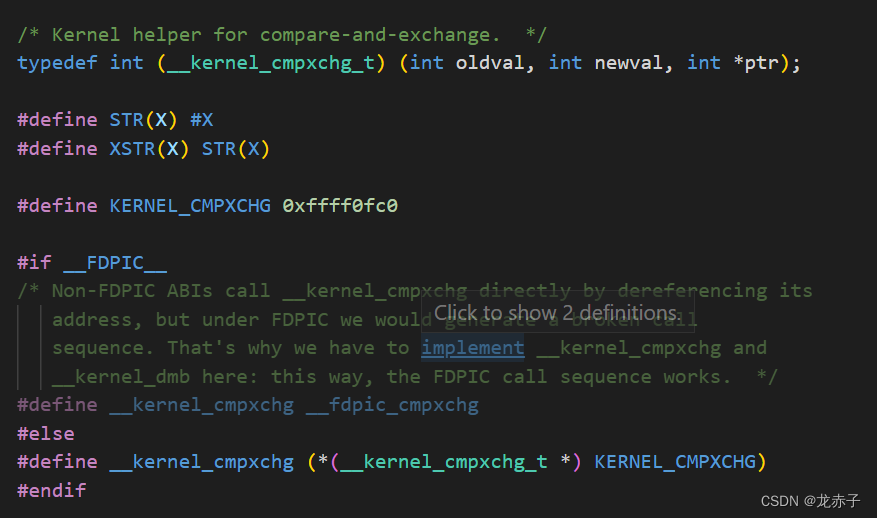
从字面意义来看,是需要借助内核进行比较和交换。另外,关键的,这里出现了上面汇编里的那个魔术数字0xffff0fc0。将其转换为函数指针变量并调用。
到这里,大概就可以猜到,应用层应该是跳转到这样一个特殊地址,由内核辅助完成了原子操作。这个地址这么特殊,内核里一定有对应的处理。内核应该是给应用开了一个口子。我们可以到内核代码里找找看。这里是针对arm平台,只需要搜索arm平台的目录即可。
在内核代码里查找,发现确实有相关定义
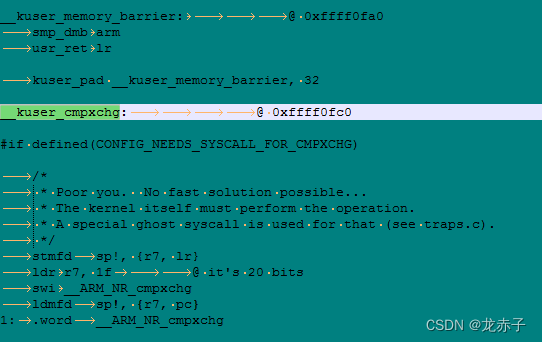
答案越来越近了。为了简便起见,我们直接看内核的汇编代码,跳过上面的各种伪代码。
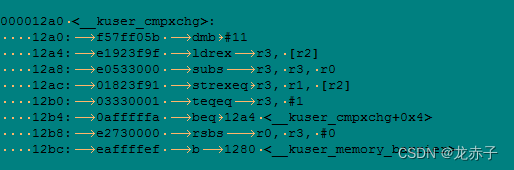
直接在汇编代码中搜索__kuser_cmpxchg,发现,确实有相关函数定义。且其中使用了LDREX/STREX类指令。至此,答案就基本清楚了。应用层的原子操作,还是通过处理器特定的指令实现的。只不过这个路径,走的有点绕。
额外的,我们看到,__kuser_cmpxchg接口中还加了dmb屏障指令。指令的参数为11,是什么含义呢?对此,我们可以从arm手册中找到答案。

从上图可以看到,参数11对应的是ISH,也就是CPU内部核心和内存之间的数据读写,需要保证一致。这里,就是要保证这个“原子变量”的值在大家眼里是一样的,不能不同核心看到的不一样。
至此,问题就说清楚了。只不过这种实现方式,似乎不是系统调用的模式。显然,这种方式,比起锁等其他实现方式,效率要高很多。
上面的说明中,注意到,0xffff0fc0这个地址是内核空间地址,应用层直接调用这个地址,那么就绕过了内核系统调用,这一点是如何做到的?按说,应用层代码访问内核空间地址时,内核会检测到,并作出处理,这里是如何放过的,于是准备使用qemu调试一下内核,看看系统调用是如何被绕过的?难道内核有特殊检查?
但是,当我用虚拟机里的另一个交叉编译环境编译后,发现汇编代码差异比较大,如下图所示:
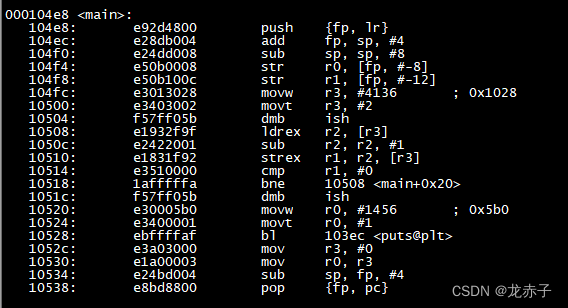
看到直接调用了LDREX和STREX指令。简单直接,直达目的。仔细一想也是,就是一个指令的问题,为啥要绕那么个弯子呢?以后有机会再研究吧。