目录
一、线性表接口
二、单链表
2.1 单链表的结构定义
2.2 头插法
2.3中间位置的插入
2.4尾插法
2.5遍历链表
2.6查询线性表中是否包含指定元素
2.7返回索引为index的元素值
2.8修改索引为index位置的元素为新值,返回修改前的元素值
2.9删除链表中索引为index的元素,返回删除前的元素值
2.10删除第一个值为val的元素
2.11在表中删除所有值为val的元素
三、带头单链表dummyHead
3.1结构定义
3.2中间位置的插入
3.3头插法和尾插法
3.4遍历带头链表
3.5 在表中删除所有值为val的元素
四、用递归写链表的方法
4.1链表指定位置的插入
4.2链表的正向输出
4.3链表的反向输出
五、ArrayList和LinkedList的区别
数组这种结构适用于频繁查询低频插入和修改的场景,若频繁插入和删除时,由于需要进行元素的搬移以及扩容等操作,浪费空间,性能开销较大,因此引入了链表。
链表是逻辑连续的,不是物理连续的。
物理连续指的是前一个元素一定是位于后一个元素之前,典型的就是数组。
逻辑连续是指每一个结点之间通过一个“钩子”连接,没有这个钩子,每个节点之间是彼此独立的毫无关系。优点就是可以在任意结点之前或者之后插入新的结点,对其他的节点并不造成影响。不需要考虑空间是否够用以及扩容问题,不会造成空间的浪费。
由于链表可以根据是否带头结点、是否循环、是否双向,排列组合有8中结构,只需要考虑三种结构:带向不带头的单链表(单向链表),单项带头链表,双向不带头链表。
一、线性表接口
定义线性表接口Seqlist。定义接口带来的好处:就是可以以非常低的成本来更换具体的子类。
public interface SeqList {
void add(int val);
// 在索引为index的位置插入新元素
void add(int index,int val);
// 查询线性表中是否包含指定元素val
boolean contains(int val);
// 返回索引为index的元素值
int get(int index);
// 修改索引为index位置的元素为新值,返回修改前的元素值
int set(int index,int newVal);
// 删除线性表中索引为index的元素,返回删除前的元素值
int removeByIndex(int index);
// 删除第一个值为val的元素
void removeByValueOnce(int val);
// 在线性表中删除所有值为val的元素
void removeAllValue(int val);
}二、单链表
有两个特殊的结点:头结点:只有头结点没有前驱。尾结点:只有尾结点没有后继。
单链表只能从前向后遍历,无论是插入还是删除方法在链表中都要找到操作位置的前驱结点。
2.1 单链表的结构定义
val表示该结点中存储的数值,next属性保存下一个结点的地址,若没有下一个结点则为null。
size表示该链表中保存的有效元素个数,head 保存了第一个结点的地址。
public class MyLinkedList implements SeqList {
private int size;
private Node head;
private class Node {
private int val;
private Node next;
public Node(int val) {
this.val = val;
}
}
}2.2 头插法
必须先让新结点先挂在原先头结点的前面,然后再让head指向新的结点。
public void addFirst(int val) {
Node node = new Node(val);
node.next = head;
head = node;
size ++ ;
}2.3中间位置的插入
首先要排除不合法的情况,然后根据index的特殊索引选择头插法,然后剩下的情况再继续分析,首先需要遍历该列表停在index位置的前驱节点,然后将该位置的next指向新的node,将node的next修改为原位置的next,最后size++。
public void add(int index, int val) {
if (index < 0 || index > size) {
throw new IllegalArgumentException("add index illegal!");
}
if (index == 0) {
addFirst(val);
return;
}
Node prev = head;
for (int i = 1; i <index; i++) {
prev = prev.next;
}
Node node = new Node(val);
node.next = prev.next;
prev.next = node;
size++;
}2.4尾插法
尾插法不必全部写出,在按照索引插入中,index == size时就是尾插, 并且同样是有前驱节点,尾结点本来指向的就是空,所以新的尾结点也应该指向空。所以尾插法中写入 add(size,val)即可。
public void add(int val) {
add(size,val);
}2.5遍历链表
不能直接使用head进行遍历,遍历一次之后,头结点的地址就找不到了。所以创建一个n使他等于head,用n进行遍历。
public String toString() {
StringBuilder sb = new StringBuilder();
for(Node n = head;n!=null;n = n.next){
sb.append(n.val);
sb.append("->");
if(n.next == null){
sb.append("NULL");
}
}
return sb.toString();
} public static void main(String[] args) {
MyLinkedList myLinkedList = new MyLinkedList();
myLinkedList.addFirst(1);
myLinkedList.add(3);
myLinkedList.add(5);
myLinkedList.addFirst(7);
myLinkedList.add(2,10);
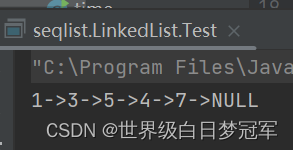
System.out.println();
}调用三种添加方法,尾插3,头插1,尾插5,头插7,在索引为3的位置插入4。最后的结果应为1,3,5,4,7。
2.6查询线性表中是否包含指定元素
创建一个Node类型的n使他等于head,然后遍历整个链表,当第一次遇见n的val等于指定元素,即返回true。如果遍历到最后还是没有,则返回false。遍历到最后意味着n==null。
public boolean contains(int val) {
for(Node n = head;n!= null;n = n.next){
if(n.val == val){
return true;
}
}
return false;
} public static void main(String[] args) {
MyLinkedList myLinkedList = new MyLinkedList();
myLinkedList.add(3);
myLinkedList.addFirst(1);
myLinkedList.add(5);
myLinkedList.add(7);
myLinkedList.add(3,4);
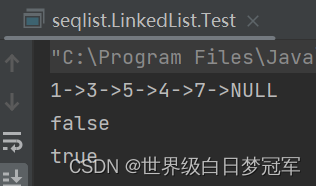
System.out.println(myLinkedList.toString());
System.out.println(myLinkedList.contains(40));
System.out.println(myLinkedList.contains(4));
}
2.7返回索引为index的元素值
首先要创建一个rangeCheck来判断index是否合法。然后遍历链表,找到索引为index的结点,返回该结点的值。
public int get(int index) {
if(!rangCheck(index)){
throw new IllegalArgumentException("get index illegal!");
}
Node node = head;
for(int i = 0;i<index;i++){
node = node.next;
}
return node.val;
}
private boolean rangCheck(int index) {
return index >= 0 && index < size;
} public static void main(String[] args) {
MyLinkedList myLinkedList = new MyLinkedList();
myLinkedList.add(3);
myLinkedList.addFirst(1);
myLinkedList.add(5);
myLinkedList.add(7);
myLinkedList.add(3,4);
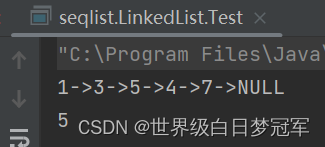
System.out.println(myLinkedList.toString());
System.out.println(myLinkedList.get(2));
}
2.8修改索引为index位置的元素为新值,返回修改前的元素值
public int set(int index, int newVal) {
if(!rangCheck(index)){
throw new IllegalArgumentException("get index illegal!");
}
Node node = head;
for(int i = 0;i<index;i++){
node = node.next;
}
int temp = node.val;
node.val = newVal;
return temp;
} public static void main(String[] args) {
MyLinkedList myLinkedList = new MyLinkedList();
myLinkedList.add(3);
myLinkedList.addFirst(1);
myLinkedList.add(5);
myLinkedList.add(7);
myLinkedList.add(3,4);
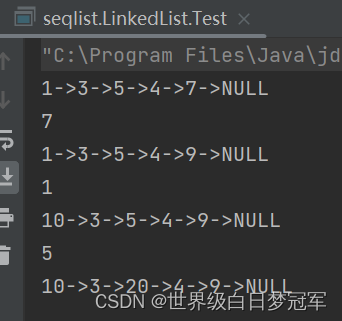
System.out.println(myLinkedList.toString());
System.out.println(myLinkedList.set(4,9));
System.out.println(myLinkedList.toString());
System.out.println(myLinkedList.set(0,10));
System.out.println(myLinkedList.toString());
System.out.println(myLinkedList.set(2,20));
System.out.println(myLinkedList.toString());
}
2.9删除链表中索引为index的元素,返回删除前的元素值
这个方法可以引申出链表的另外两个方法,删除头结点和尾结点。只需要调用该函数并且把index设置为0或者size-1。
想要删除在索引位置上的元素,就需要找到该位置的前驱结点,使前驱节点的与索引位置的next结点连接,这时候就有一个特殊情况,头结点是没有前驱结点的,所以需要把头结点单独分析。
排除不合法的情况后,现针对index == 0来分析,直接将head = head.next即可,同时要让长度减一。剩下的情况只需要找到index位置的前驱结点,使它的next = index位置的next。
public int removeFirst(){
return removeByIndex(0);
}
public int removeLast(){
return removeByIndex(size-1);
}
public int removeByIndex(int index) {
if(!rangCheck(index)){
throw new IllegalArgumentException("get index illegal!");
}
if(index ==0){
int tmp = head.val;
head = head.next;
size--;
return tmp;
}
Node node = head;
for(int i = 1;i<index;i++){
node = node.next;
}
int tmp = node.next.val;
node.next = node.next.next;
size--;
return tmp;
} public static void main(String[] args) {
MyLinkedList myLinkedList = new MyLinkedList();
myLinkedList.add(1);
myLinkedList.add(3);
myLinkedList.add(5);
myLinkedList.add(7);
myLinkedList.add(3,4);
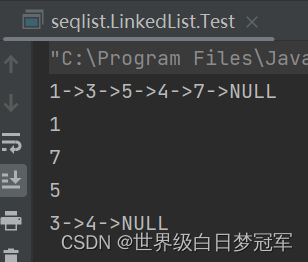
System.out.println(myLinkedList.toString());
System.out.println(myLinkedList.removeFirst());
System.out.println(myLinkedList.removeLast());
System.out.println(myLinkedList.removeByIndex(1));
System.out.println(myLinkedList.toString());
}先删除头结点,然后删除尾结点,再删除下标为1的数。
2.10删除第一个值为val的元素
想要删除值为的元素,就需要找到它的前驱结点,使前驱节点的与查找元素的后继结点连接,这种时候也需要将头结点单独来看,因为头结点没有前驱结点。
并且如果链表为null这种情况也要分开处理,因为链表为空代表链表中没有值处理不了。
逻辑上的终止条件(假设要删除位置的前驱结点为prev):此处删除的是prev的后继节点,因此保证prev的后继节点必须存在,所以终止条件是prev.next != null。
public void removeByValueOnce(int val) {
if(head == null){
return ;
}
if(head.val==val){
int tmp = head.val;
head = head.next;
size--;
return ;
}
for(Node prev = head;prev.next!= null;prev = prev.next){
if(prev.next.val== val){
prev.next = prev.next.next;
size--;
return;
}
}
} public static void main(String[] args) {
MyLinkedList myLinkedList = new MyLinkedList();
myLinkedList.add(7);
myLinkedList.add(1);
myLinkedList.add(3);
myLinkedList.add(7);
myLinkedList.add(5);
myLinkedList.add(3,4);
myLinkedList.add(7);
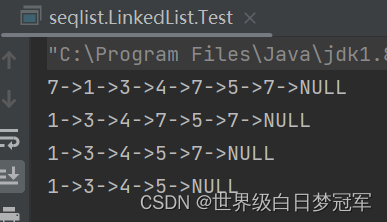
System.out.println(myLinkedList.toString());
myLinkedList.removeByValueOnce(7);
System.out.println(myLinkedList.toString());
myLinkedList.removeByValueOnce(7);
System.out.println(myLinkedList.toString());
myLinkedList.removeByValueOnce(7);
System.out.println(myLinkedList.toString());
}
2.11在表中删除所有值为val的元素
若链表为空则直接返回,若链表的头结点就是待删除的结点,需要考虑删除后补上的结点的值也是val,所以需要进行while循环,直到head的值不是val,在这种情况中需要让head!=null ,否则无法取得head的val值。
进行完这一步,head可能为空,也可能head的值不是val。同样创建prev进行遍历使 prev= head。所以需要先保证prev不为空,才能取得prev.next的val值。
删除一个结点之后不能直接使prev引用向后走,prev引用直到prev.next.val != val时prev才能向后走,否则如果补上的结点值也为val则会被忽略。
public void removeAllValue(int val) {
if(head == null){
return ;
}
while (head!=null&&head.val==val){
int tmp = head.val;
head = head.next;
size--;
}
if(head == null){
return ;
}
Node prev = head;
while(prev.next!=null){
if(prev.next.val== val){
prev.next = prev.next.next;
size--;
}else {
prev = prev.next;
}
}
} public static void main(String[] args) {
MyLinkedList myLinkedList = new MyLinkedList();
myLinkedList.add(7);
myLinkedList.add(7);
myLinkedList.add(3);
myLinkedList.add(7);
myLinkedList.add(7);
myLinkedList.add(5);
myLinkedList.add(3,4);
myLinkedList.add(7);
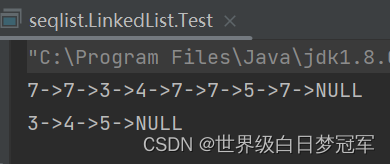
System.out.println(myLinkedList.toString());
myLinkedList.removeAllValue(7);
System.out.println(myLinkedList.toString());
}
三、带头单链表dummyHead
在单链表的操作过程中,每次插入和删除都需要考虑头结点的情况,因为只有头结点特殊,没有前驱,所以需要想一个办法,让链表中所有的有效结点都一视同仁,就不需要区额外关注头结点的情况。
因此引入一种新的结构,虚拟头结点dummyHead,不存储具体的元素,只是作为链表的头来使用,所有存储元素的结点都是该头结点的后继结点。
3.1结构定义
与单链表不同的地方就是要在构造方法中先定义虚拟头结点。后来每一个结点都在虚拟头结点的后面。
public class LinkedListWithHead {
private int size;
private Node dummyHead;
private static class Node {
private int val;
private Node next;
public Node(int val) {
this.val = val;
}
}
public LinkedListWithHead(){
this.dummyHead = new Node(-1);
}
}3.2中间位置的插入
首先排除不合法情况后不需要将第一个有效结点单独拿出来调用头插法,因为它也有前驱结点,所以可以一视同仁。
public void add(int index, int val){
if (index < 0 || index > size) {
throw new IllegalArgumentException("add index illegal!");
}
Node prev = dummyHead;
for (int i = 0; i < index; i++) {
prev = prev.next;
}
Node node = new Node(val);
node.next = prev.next;
prev.next = node;
size++;
}3.3头插法和尾插法
与单链表没有什么差别,就是将单链表的头结点换成了带头链表的虚拟头结点的后继节点。
public void addFirst(int val){
Node node = new Node(val);
node.next = dummyHead.next;
dummyHead.next = node;
size++;
}但是在带头链表中,第一个有效结点也有前驱节点,所以也可以像尾插法一样运用add方法。
public void addFirst(int val){
add(0,val);
}
public void addLast(int val) {
add(size,val);
}3.4遍历带头链表
经过链表之后,带头链表的遍历就很好写了,摘除头结点之后遍历即可。
public String toString() {
StringBuilder sb = new StringBuilder();
Node cur = dummyHead.next;
while (cur != null) {
sb.append(cur.val);
sb.append("->");
if (cur.next == null) {
sb.append("NULL");
}
cur = cur.next;
}
return sb.toString();
} public static void main(String[] args) {
LinkedListWithHead linkedListWithHead = new LinkedListWithHead();
linkedListWithHead.addLast(3);
linkedListWithHead.addLast(5);
linkedListWithHead.addLast(9);
linkedListWithHead.addFirst(1);
linkedListWithHead.add(3,7);
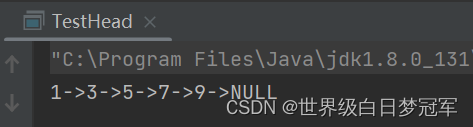
System.out.println(linkedListWithHead.toString());
}先尾插3,5,9。然后头插1,在指定位置3插入7。
3.5 在表中删除所有值为val的元素
具体逻辑也是和单链表一样的,只是不需要特别考虑头结点。用cur指向虚拟头结点,来判断cur.next的val是否和需要判断的值相同,如果相同就将cur.next指向 cur.next.next,直到不相同的时候,就让cur向右移。
public void removeAllValue(int val){
Node cur = dummyHead;
while (cur.next!=null){
Node sec = cur.next.next;
if(cur.next.val == val){
cur.next = sec;
size--;
}else{
cur = cur.next;
}
}
} public static void main(String[] args) {
LinkedListWithHead linkedListWithHead = new LinkedListWithHead();
linkedListWithHead.addLast(1);
linkedListWithHead.addLast(1);
linkedListWithHead.addLast(3);
linkedListWithHead.addLast(1);
linkedListWithHead.addLast(5);
linkedListWithHead.addLast(1);
linkedListWithHead.addFirst(1);
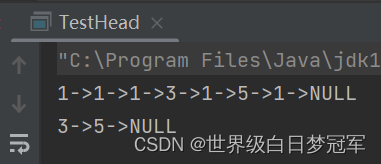
System.out.println(linkedListWithHead.toString());
linkedListWithHead.removeAllValue(1);
System.out.println(linkedListWithHead.toString());
}
四、用递归写链表的方法
具体构造还是和之前一样。
public class LinkedListR implements SeqList {
private int size;
private Node head;
private class Node {
private int val;
private Node next;
public Node(int val) {
this.val = val;
}
}
}4.1链表指定位置的插入
首先就是不合法情况的排除,然后先判断如果index==0就是头插法,如果index!=0,那么直接让head.next = add(head.next,index - 1,val),调用递归一直到找到index位置然后插入即可。
然后头插和尾插都调用这个方法输入对应的位置即可。
public void addFirst(int val) {
add(0,val);
}
@Override
public void add(int val) {
add(size,val);
}
@Override
public void add(int index, int val) {
if (index < 0 || index > size) {
throw new IllegalArgumentException("add index illegal!");
}
head = add(head,index,val);
}
private Node add(Node head, int index, int val) {
if (index == 0) {
Node node = new Node(val);
node.next = head;
head = node;
size ++;
return head;
}
head.next = add(head.next,index - 1,val);
return head;
}4.2链表的正向输出
链表的正向输出用递归写也很简单,首先head==null时,输出NULL然后返回即可,然后先输出当前的值在调用递归,一个接一个输出。
private void print(Node head) {
if (head == null) {
System.out.print("NULL\n");
return;
}
System.out.print(head.val + "->");
print(head.next);
}
public void print() {
print(head);
}4.3链表的反向输出
用递归的方法反向输出会更加的容易,能倒叙从尾结点开始输出内容,一直到头结点。
首先当head==null时,直接返回就好,然后需要把先把子链表全部输出完,站在head位置,只要一直输出就好。但是这个时候最后输出没有办法加上null,正常正向输出最后会有null,所以创建一个变量count计数,在每次调用递归前count++。然后每次调用完递归返回后再count--,当count==0时,已经走到了链表的头结点,在最后要继续输出null。
public void printReverse() {
printReverse(head);
}
int count = 0;
private void printReverse(Node head) {
if (head == null) {
return;
}
count ++;
printReverse(head.next);
count --;
System.out.print(head.val + "->");
if (count == 0) {
System.out.print("NULL\n");
}
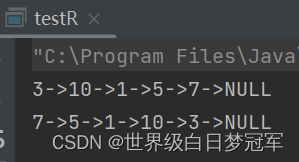
} public static void main(String[] args) {
LinkedListR list = new LinkedListR();
list.addFirst(1);
list.addFirst(3);
list.add(5);
list.add(7);
list.add(1,10);
list.print();
list.printReverse();
}
五、ArrayList和LinkedList的区别
| 不同点 | ArrayList | LinkedList |
| 存储空间上 | 物理上一定连续 | 逻辑上连续,但物理上不一定连续 |
| 随机访问 | 支持O(1) | 不支持:O(N) |
| 头插 | 需要搬移元素,效率低O(N) | 只需修改引用的指向,O(1) |
| 插入 | 空间不够时需要扩容 | 没有扩容的概念 |
| 应用场景 | 元素高效存储+频繁访问 | 任意位置插入和删除频繁 |