(欢迎大家关注我的公众号“机器学习面试基地”,之后将在公众号上持续记录本人从非科班转到算法路上的学习心得、笔经面经、心得体会。未来的重点也会主要放在机器学习面试上!)
最近工作中需要解析一些有模型输入输出信息的csv日志,主要是键值对的形式,大概有两种情形:
情形一:标准的json字符串格式
也就是需要解析的字段为标准的json字符串:

然后需要将每个json字符串中的每一个键解析为新的一列(列名也需要保持相同),即以下的格式:
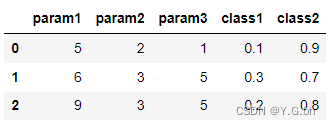
那么用到以下代码即可:
import pandas as pd
import json
#示例数据定义
df1 = pd.DataFrame({'params':['{"param1":5,"param2":2,"param3":1}','{"param1":6,"param2":3,"param3":5}','{"param1":9,"param2":3,"param3":5}'],'results':['{"class1":0.1,"class2":0.9}','{"class1":0.3,"class2":0.7}','{"class1":0.2,"class2":0.8}']})
df1 = df1.join(df1['params'].apply(lambda x:json.loads(x)).apply(pd.Series))#json格式解析
df1 = df1.join(df1['results'].apply(lambda x:json.loads(x)).apply(pd.Series))#json格式解析
df1 = df1.drop(['params','results'],axis=1)#丢弃原字段
- 核心就在于利用apply函数,也就是上面的apply(lambda x:json.loads(x))和apply(pd.Series))。
- 其中第一个apply结合lambda函数对json格式进行解析,会将原始的json字符串解析为python的字典格式,
- 然后通过apply(pd.Series))来将解析后的键值对其拆分为对应的列,即每个键对应一个列。
情形二:不规则的键值对
该情形主要是针对需要解析的字段为非json格式的,比如:

同样需要解析为下面的格式,并将键名作为新的列名:

那么用下面的代码即可做到:
#示例数据
df2 = pd.DataFrame({'params':['param1=5|param2=2|param3=8','param1=4|param2=2|param3=2','param1=2|param2=2|param3=5']})
#解析
parse = (df2.params.str.extractall('([^|]+)=([^|]+)')
.reset_index(level=1,drop=True)
.set_index(0,append=True)[1]
.unstack(level=1))
整体解析麻烦了一些,但是掌握后就会很方便,因为复制好模板代码后只需要简单修改,就能进行解析。对于上面主要需要修改的部分则是extractall里的正则匹配部分。下面简单对上面的代码做一个拆分(如果要深入研究的话,需要去学习正则匹配,这里只做简单介绍)
-
df2.params为指定某一列,也可以用df2[‘params’]
-
.str即将目标列转换为string格式
-
extractall()则是通过正则匹配获取所有满足目标格式的键值对'([^|]+)=([^|]+)'代表了我们想要的匹配格式,主要分为([^|]+)、=、([^|]+)三个部分,也就是匹配’键=值‘的格式([^|]+)又分为()、[]、^、|、+五个部分- 其中()代表了整体打包,也即里面的是一个整体,比如(abc)?表示匹配abc这个字符串0次或者1次,如果不加(),即abc?的话则表示匹配ab或者abc,即?只对c生效而不是abc整体生效。
- []表示单个匹配,即[]匹配一个字符,而非多个。比如
[0-9]表示0-9之间的数都满足匹配要求,可以匹配0到9之间的单个数,但是不能匹配98,99 ^有两种用法,一是限定开头,比如(^cat)则限定开头为cat的字符串。第二种是代表’否’,也就是不匹配的意思,比如上面的[^|]则表示|外的所有字符。那么如何区分两种用法呢,就看^外面是不是紧挨着[],比如/[(^\s+)(\s+$)]/g就是限定开头的用法,而不是’否‘的用法。- +则表示多个的意思,也就是匹配多个
[^|]
- 针对我们的目标格式param1=5|param2=2|param3=8,其实我们需要提取的就是param1=5,那么|是多余的,所以用
[^|]来排除|,由于param是一个字符串,因此需要用+来进行字符串匹配。最后利用()来将其打包为一个整体。
-
reset_index(level=1,drop=True)用于重置索引,如果drop=True,则代表丢弃现有的索引,如果有多级索引,则需要用level参数指定需要丢弃的索引,如果没有指明level,则丢弃所有索引。重置前的结果如下,也就是出现了两级索引,这里删除第二级索引,也就是level=1(或者也可以写成level=‘match’):
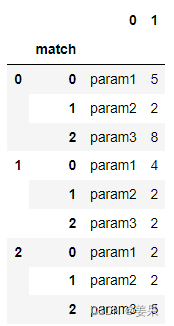
重置后的结果如下:
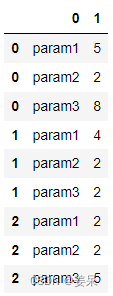
-
set_index(0,append=True)[1]中set_index代表将某一列设置为索引,append=True,则代表保留原索引,并将指定列作为索引附加到原索引上,也就是变成了两级索引。这里将param所在那一列变成了索引。set_index后的结果如下

注意后面还有个[1],这其实就是提取出列名为1的列,注意这里其实只有一列了,因为param那一列已经变成索引了,这一步后的结果如下:

-
最后unstack(level=1))将指定level的索引,转变为列。最后就达到了我们的目的了:

举一反三(进阶版)
假设中间的间隔符不规律:
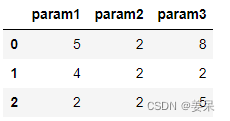
df2 = pd.DataFrame({'params':['*param1=5&$param2=2|param3=8','param1=4|$param2=2|param3=2','param1=2|param2=2|param3=5']})
df2

那就把所有的不规则符号排除掉即可
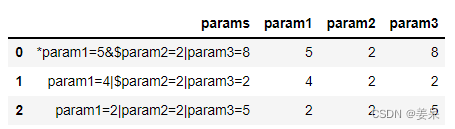
parse = (df2.params.str.extractall('([^|*&$]+)=([^|*&$]+)')
.reset_index(level=1,drop=True)
.set_index(0,append=True)[1]
.unstack(level=1)
)
parse
如果要把解析的字段加在原来的表上,那就用join即可:df2=df2.join(parse)
总结
几行代码包含pandas的诸多技巧,以及正则匹配的知识,对于不规则的键值对,其实只需要掌握正则匹配的原理,然后修改正则匹配处的代码即可,后面的几行代码也无需改动。









![[MQ] SpringBoot使用直连交换机Direct Exchange](https://img-blog.csdnimg.cn/885f975482b644babf9b9b322e0e68f9.png)