通过案例学PyTorch。
扫码关注《Python学研大本营》,加入读者群,分享更多精彩
Autograd
Autograd 是 PyTorch 的自动微分包。多亏了它,我们不需要担心偏导数、链式法则或类似的东西。
那么,我们如何告诉 PyTorch 做它的事情并计算所有梯度呢?这就是backward()的好处。
你还记得计算梯度的起点吗?这是损失,因为我们根据我们的参数计算了它的偏导数。因此,我们需要从相应的 Python 变量调用backward()方法,例如,loss.backward().
梯度的实际值如何?我们可以通过查看张量的grad属性来检查它们。
如果您查看该方法的文档,它会清楚地说明梯度是累积的。因此,每次我们使用梯度来更新参数时,我们都需要在之后将梯度归零。这就是zero_()的好处。
方法名称末尾的下划线( _ )是什么意思?你还记得吗?如果没有,请滚动回上一节并找出答案。
因此,让我们放弃梯度的手动 计算,并同时使用backward()和zero_()方法。
但是,总有一个问题,这次它与参数的更新有关……
lr = 1e-1
n_epochs = 1000
torch.manual_seed(42)
a = torch.randn(1, requires_grad=True, dtype=torch.float, device=device)
b = torch.randn(1, requires_grad=True, dtype=torch.float, device=device)
for epoch in range(n_epochs):
yhat = a + b * x_train_tensor
error = y_train_tensor - yhat
loss = (error ** 2).mean()
# No more manual computation of gradients!
# a_grad = -2 * error.mean()
# b_grad = -2 * (x_tensor * error).mean()
# We just tell PyTorch to work its way BACKWARDS from the specified loss!
loss.backward()
# Let's check the computed gradients...
print(a.grad)
print(b.grad)
# What about UPDATING the parameters? Not so fast...
# FIRST ATTEMPT
# AttributeError: 'NoneType' object has no attribute 'zero_'
# a = a - lr * a.grad
# b = b - lr * b.grad
# print(a)
# SECOND ATTEMPT
# RuntimeError: a leaf Variable that requires grad has been used in an in-place operation.
# a -= lr * a.grad
# b -= lr * b.grad
# THIRD ATTEMPT
# We need to use NO_GRAD to keep the update out of the gradient computation
# Why is that? It boils down to the DYNAMIC GRAPH that PyTorch uses...
with torch.no_grad():
a -= lr * a.grad
b -= lr * b.grad
# PyTorch is "clingy" to its computed gradients, we need to tell it to let it go...
a.grad.zero_()
b.grad.zero_()
print(a, b)
在第一次尝试中,如果我们使用与Numpy代码中相同的更新结构,我们将得到下面的奇怪错误……但我们可以通过查看张量本身来了解发生了什么——我们又一次“迷路”了梯度,同时将更新结果重新分配给我们的参数。因此,grad属性结果是,它引发了None错误……
# FIRST ATTEMPT
tensor([0.7518], device='cuda:0', grad_fn=<SubBackward0>)
AttributeError: 'NoneType' object has no attribute 'zero_'
然后,我们在第二次尝试中使用熟悉的就地 Python 赋值对其进行轻微更改。而且,PyTorch 再次抱怨并引发错误。
# SECOND ATTEMPT
RuntimeError: a leaf Variable that requires grad has been used in an in-place operation.
为什么?事实证明这是一个“好事太多”的案例。罪魁祸首是 PyTorch 能够从涉及任何梯度计算张量或其依赖项的每个Python 操作构建动态计算图。
我们将在下一节中深入探讨动态计算图的内部工作原理。
那么,我们如何告诉 PyTorch “后退”并让我们更新参数而不弄乱其花哨的动态计算图?这torch.no_grad()就是好处。它允许我们独立于 PyTorch 的计算图对张量执行常规 Python 操作。
最后,我们成功地运行了我们的模型并获得了结果参数。果然,它们与我们在Numpy- only 实现中得到的匹配。
# THIRD ATTEMPT
tensor([1.0235], device='cuda:0', requires_grad=True) tensor([1.9690], device='cuda:0', requires_grad=True)
动态计算图
“不幸的是,没有人能知道动态计算图是什么。你必须亲自去看看。”
PyTorchViz包及其
make_dot(variable)方法使我们能够轻松地可视化与给定 Python 变量关联的图形。
所以,让我们坚持最低限度:两个(梯度计算)张量用于我们的参数、预测、误差和损失。
torch.manual_seed(42)
a = torch.randn(1, requires_grad=True, dtype=torch.float, device=device)
b = torch.randn(1, requires_grad=True, dtype=torch.float, device=device)
yhat = a + b * x_train_tensor
error = y_train_tensor - yhat
loss = (error ** 2).mean()
如果我们调用make_dot(yhat),我们将得到下面图 3 中最左边的图表:

让我们仔细看看它的组件:
-
蓝色框:这些对应于我们用作参数的张量,我们要求 PyTorch 为其计算梯度的张量;
-
灰色框:涉及梯度计算张量或其依赖项的Python 操作;
-
绿色框:与灰框相同,除了它是计算梯度的起点(假设该backward()方法是从用于可视化图形的变量调用的)——它们是从图形中自下而上计算的。
如果我们为error(中心)和loss(右)变量绘制图表,它们与第一个变量之间的唯一区别是中间步骤的数量(灰色框)。
现在,仔细看看最左边图表的绿色框:有两个箭头指向它,因为它是将两个变量a和b*x的和相加。看起来很明显,对吧?
然后,看同一个图的灰色框:它在进行乘法运算,即b*x。但是只有一个箭头指向它!箭头来自与我们的参数b对应的蓝色 框。
为什么我们的数据x没有一个盒子?答案是:我们不为它计算梯度!因此,即使计算图执行的操作涉及更多张量,它也仅显示梯度计算张量及其依赖项。
如果我们为参数a的requires_grad设置为False,计算图会发生什么情况?

不出所料,参数a对应的蓝色框没有了!足够简单:没有梯度,没有图形。
动态计算图的最大优点是您可以根据需要将其复杂化。您甚至可以使用控制流语句(例如,if 语句)来控制梯度流。
下面的图 5 显示了一个示例。

优化器
到目前为止,我们一直在使用计算出的梯度手动更新参数。这对于两个参数来说可能没问题……但是如果我们有很多参数怎么办?!我们使用 PyTorch 的优化器之一,例如SGD或Adam。
优化器获取我们想要更新的参数、我们想要使用的学习率(可能还有许多其他超参数!)并通过其step()方法执行 更新。
此外,我们也不再需要将梯度一一归零了。我们只需调用优化器的zero_grad()方法就可以了!
在下面的代码中,我们创建了一个随机梯度下降(SGD) 优化器来更新我们的参数a和b。
不要被优化器的名字所迷惑:如果我们一次使用所有训练数据进行更新——就像我们在代码中实际做的那样——优化器正在执行批量梯度下降,不管它的名字是什么。
PyTorch 的优化器在行动——不再需要手动更新参数!
torch.manual_seed(42)
a = torch.randn(1, requires_grad=True, dtype=torch.float, device=device)
b = torch.randn(1, requires_grad=True, dtype=torch.float, device=device)
print(a, b)
lr = 1e-1
n_epochs = 1000
# Defines a SGD optimizer to update the parameters
optimizer = optim.SGD([a, b], lr=lr)
for epoch in range(n_epochs):
yhat = a + b * x_train_tensor
error = y_train_tensor - yhat
loss = (error ** 2).mean()
loss.backward()
# No more manual update!
# with torch.no_grad():
# a -= lr * a.grad
# b -= lr * b.grad
optimizer.step()
# No more telling PyTorch to let gradients go!
# a.grad.zero_()
# b.grad.zero_()
optimizer.zero_grad()
print(a, b)
让我们检查一下之前和之后的两个参数,以确保一切正常:
# BEFORE: a, b
tensor([0.6226], device='cuda:0', requires_grad=True) tensor([1.4505], device='cuda:0', requires_grad=True)
# AFTER: a, b
tensor([1.0235], device='cuda:0', requires_grad=True) tensor([1.9690], device='cuda:0', requires_grad=True)
我们优化了优化过程。还剩下什么?
Lose
我们现在处理损失计算。正如预期的那样,PyTorch 再次让我们受益匪浅。根据手头的任务,有许多损失函数可供选择。由于我们的是回归,因此我们使用均方误差 (MSE) 损失。
请注意,这
nn.MSELoss实际上为我们创建了一个损失函数——它不是损失函数本身。此外,您可以指定要应用的缩减方法,也就是说,您希望如何聚合各个点的结果——您可以对它们进行平均 (reduction='mean') 或简单地将它们相加 (reduction='sum') .
然后,我们稍后在第 20 行使用创建的损失函数来计算给定预测和标签的损失。
我们的代码现在看起来像这样:
torch.manual_seed(42)
a = torch.randn(1, requires_grad=True, dtype=torch.float, device=device)
b = torch.randn(1, requires_grad=True, dtype=torch.float, device=device)
print(a, b)
lr = 1e-1
n_epochs = 1000
# Defines a MSE loss function
loss_fn = nn.MSELoss(reduction='mean')
optimizer = optim.SGD([a, b], lr=lr)
for epoch in range(n_epochs):
yhat = a + b * x_train_tensor
# No more manual loss!
# error = y_tensor - yhat
# loss = (error ** 2).mean()
loss = loss_fn(y_train_tensor, yhat)
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(a, b)
此时,只剩下一段代码需要更改:predictions。然后是时候介绍 PyTorch 的实现方式了。

推荐书单
《PyTorch深度学习简明实战 》

本书针对深度学习及开源框架——PyTorch,采用简明的语言进行知识的讲解,注重实战。全书分为4篇,共19章。深度学习基础篇(第1章~第6章)包括PyTorch简介与安装、机器学习基础与线性回归、张量与数据类型、分类问题与多层感知器、多层感知器模型与模型训练、梯度下降法、反向传播算法与内置优化器。计算机视觉篇(第7章~第14章)包括计算机视觉与卷积神经网络、卷积入门实例、图像读取与模型保存、多分类问题与卷积模型的优化、迁移学习与数据增强、经典网络模型与特征提取、图像定位基础、图像语义分割。自然语言处理和序列篇(第15章~第17章)包括文本分类与词嵌入、循环神经网络与一维卷积神经网络、序列预测实例。生成对抗网络和目标检测篇(第18章~第19章)包括生成对抗网络、目标检测。
本书适合人工智能行业的软件工程师、对人工智能感兴趣的学生学习,同时也可作为深度学习的培训教程。
作者简介:
日月光华:网易云课堂资深讲师,经验丰富的数据科学家和深度学习算法工程师。擅长使用Python编程,编写爬虫并利用Python进行数据分析和可视化。对机器学习和深度学习有深入理解,熟悉常见的深度学习框架( PyTorch、TensorFlow)和模型,有丰富的深度学习、数据分析和爬虫等开发经验,著有畅销书《Python网络爬虫实例教程(视频讲解版)》。
链接(新书限时5.5折):https://item.jd.com/13528847.html
精彩回顾
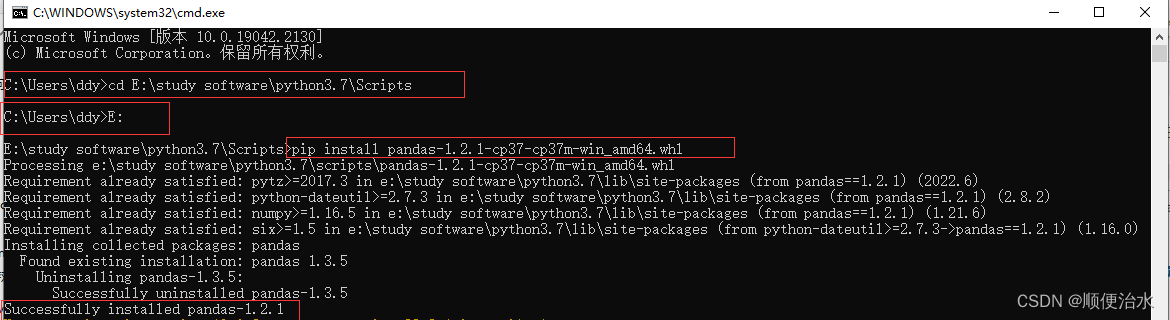
《Pandas1.x实例精解》新书抢先看!
【第1篇】利用Pandas操作DataFrame的列与行
【第2篇】Pandas如何对DataFrame排序和统计
【第3篇】Pandas如何使用DataFrame方法链
【第4篇】Pandas如何比较缺失值以及转置方向?
【第5篇】DataFrame如何玩转多样性数据
【第6篇】如何进行探索性数据分析?
【第7篇】使用Pandas处理分类数据
【第8篇】使用Pandas处理连续数据
【第9篇】使用Pandas比较连续值和连续列
【第10篇】如何比较分类值以及使用Pandas分析库
扫码关注《Python学研大本营》,加入读者群,分享更多精彩