一篇文章彻底理解 HDFS 的安全模式
1 什么是 HDFS 的安全模式
Hdfs 的安全模式,即 HDFS safe mode, 是 HDFS 文件系统的一种特殊状态,在该状态下,hdfs 文件系统只接受读数据请求,而不接受删除、修改等变更请求,当然也不能对底层的 block 进行副本复制等操作。
从本质上将,安全模式 是 HDFS 的一种特殊状态,而 HDFS 进入该特殊状态的目的,是为了确保整个文件系统的数据一致性/不丢失数据,从而限制用户只能读取数据而不能改动数据的。
2 什么情况下 HDFS 会进入安全模式
HDFS 进入安全模式的情况分为两种,即主动进入与被动进入。
2.1 HDFS 被动进入安全模式
管理员出于运维管理等各种原因,可以主动执行命令让 hdfs 进入安全模式,相关的命令有:hdfs dfsadmin -safemode enter/get/leave;
2.2 HDFS 主动进入安全模式
HDFS 也可能会主动进入安全模式,这种情况更为常见,是 HDFS 在特殊状况下,为了保证整个文件系统的数据一致性/整个文件系统不丢失数据,而主动进入的一种自我保护状态,底层根本原因又分为两种:
- HDFS 底层启动成功并能够跟 namenode 保持定期心跳的 datanode 的个数没有达到指定的阈值, 阈值通过参数 dfs.namenode.safemode.min.datanodes 指定;
- HDFS 底层达到了最小副本数要求的 block 的百分比没有达到指定的阈值:最小副本数通过参数 dfs.namenode.replication.min/dfs.namenode.safemode.replication.min 指定,阈值通过参数 dfs.namenode.safemode.threshold-pct 指定;
- 当然如果 HDFS 底层启动成功并能够跟 namenode 保持定期心跳的 datanode 的个数没有达到指定的阈值,此时HDFS 底层达到最小副本数要求的 block 的百分比一般也都不会达到指定的阈值;
- 不难理解,正常情况下,HDFS 启动过程中会有一段时间主动进入安全模式并在一段时间后主动退出安全模式,这是由 hdfs 的分本式架构决定的,因为 namenode 启动成功后,需要等待 datanode 启动成功并通过心跳汇报 datanode 上存储的 block 的信息(block report),只有在掌握了足够的 block 的信息(达到最小副本数要求的 block 占所有 block 的百分比达到指定的阈值),并等待特定时间后(通过参数 dfs.namenode.safemode.extension 30000控制),才会主动退出安全模式。
从现实情况来看,常见的HDFS进入安全模式的直接原因有:
- 部分 datanode 启动失败或者因为网络原因与 namenode 心跳失败;
- 部分 datanode 节点存储 hdfs 数据的磁盘卷有损坏,导致存储在该磁盘卷中的数据无法读取;
- 部分 datanode 节点存储 hdfs 数据的磁盘分区空间满,导致存储在该磁盘卷中的数据无法正常读取;
3 HDFS 进入安全模式怎么办?
3.1 分析原因
当 HDFS 主动进入安全模式后,首先需要分析其主动进入安全模式的原因,可以通过以下途径进行分析:
- 查看 namenode webui:可以查看 hdfs namenode webui 的 “overview”/“Startup Progress”/“Datanode Volume Failures” 等页面;
- 查看 namenode 和 datanode 日志,可以直接查看后台主机特定目录下的文件,如 /var/log/hadoop-hdfs目录下的 hadoop-hdfs-hdfs-datanode-node1.out/hadoop-cmf-hdfs-NAMENODE-node1.log.out 等文件,也可以通过 CM 等管控台的 “诊断-日志” 等页面指定服务指定时间指定日志级别进行搜索;
- 比如如下报错日志,即提示了 /dev/mapper/rhel-root 对应的文件系统即根目录磁盘空间不足,hadoop自动进入了安全模式:
- org.apache.hadoop.hdfs.server.namenode.FSNamesystem:NameNode low on available disk space.Already in safemode.
- org.apache.hadoop.hdfs.StateChange: STATE* Safemode is ON. Resources are low on NN. Please add or free up more resources then turn off safemode manually. NOTE:If you turn off safemode before adding resources,the NN will immediately return to safemode. Use"hdfs dfsadmin -safemode leave" to turn safemode off.
- org.apache.hadoop.hdfs.server.namenode.NameNodeResourceChecker:Space available on volume '/dev/mapper/rhel-root' is 103092224, which is below the configured reserved amount 104857600
3.2 修复问题
通过以上排查确认进入安全模式的原因后,就可以进行针对性的修复了:
- 比如如果有 datanode 未启动成功,则尝试修复并启动对应的 datanode;
- 比如如果有 datanode 存储 hdfs 数据的磁盘分区空间满,则尝试扩展磁盘分区空间;
- 比如如果有 datanode 存在存储卷故障,则尝试修复存储卷,如果无法修复则需要替换存储卷(会丢失存储卷上的数据);
- 需要注意的是,如果出现了某些 datanode 节点彻底损坏无法启动,或某些 datanode 节点磁盘卷故障彻底无法修复的情况,则这些数据对应的 block 及 block 上层的 hdfs 文件,就被丢失了,后续可能需要联系业务人员补数据(从上游重新拉取数据,或重新运行作业生成数据),如果业务人员也无法补数据,这些数据就被彻底损坏无法恢复了;
- 可以通过如下命令查看丢失的 block 及这些 block 对应的上层 hdfs 文件,并记录下来后续交给业务人员去判断是否需要补数据:hdfs fsck / -list-corruptfileblocks,hdfs fsck / -files -blocks -locations;
- 对于不存在数据丢失的情况,按照上述方式修复并重启集群后,HDFS 就会退出安全模式并正常对外提供读写服务;
- 对于存在数据丢失的情况,需要通过如下命令手动退出安全模式并删除损坏的/丢失的 block 对应的上层 hdfs 文件:
- 退出安全模式(只有退出安全模式才能删除数据):sudo -u hdfs hdfs dfsadmin -safemode leave;
- 删除丢失的 blockd 对应的上层 hdfs 文件(自动检查文件系统并把丢失的block的上层hdfs文件删除):sudo -u hdfs hdfs fsck / -delete;
- 在删除了丢失的 block 对应的上层 hdfs 文件后,HDFS 底层达到最小副本数要求的 block 的百分比就达到了指定的阈值(总文件数降低了总 block数也相应降低了,所以成功汇报的block的百分比就相应上升达到阈值了),所以重启后也就能够正常退出安全模式并正常对外提供读写服务了;
3.3 修复问题的错误方法
不对 hdfs 主动进入安全模式的具体原因进行分析,而是直接通过如下方法强制退出安全模式,是无脑的错误示范:
- 直接通过命令强制退出安全模式:sudo -u hdfs hdfs dfsadmin -safemode leave
- 不经分析直接删除损坏的文件:sudo -u hdfs hdfs fsck / -delete
- 直接更改相关参数降低安全模式阈值:比如 dfs.namenode.safemode.threshold-pct/dfs.namenode.safemode.min.datanodes;
4 HDFS 安全模式相关参数
HDFS 安全模式相关参数有:
- dfs.namenode.safemode.threshold-pct: 副本数达到最小要求的 block 占系统总block数的百分比, default 0.999f,Specifies the percentage of blocks that should satisfy the minimal replication requirement defined by dfs.namenode.replication.min. Values less than or equal to 0 mean not to wait for any particular percentage of blocks before exiting safemode. Values greater than 1 will make safe mode permanent;
- dfs.namenode.safemode.min.datanodes:离开安全模式的最小可用datanode数量要求,default 0,Specifies the number of datanodes that must be considered alive before the name node exits safemode. Values less than or equal to 0 mean not to take the number of live datanodes into account when deciding whether to remain in safe mode during startup. Values greater than the number of datanodes in the cluster will make safe mode permanent;
- dfs.namenode.safemode.extension:集群可用 block 比例、可用 datanode 都达到要求之后,自动退出安全模式的时延,default 30000,Determines extension of safe mode in milliseconds after the threshold level is reached. Support multiple time unit suffix (case insensitive), as described in dfs.heartbeat.interval;
- dfs.namenode.safemode.replication.min: 判断能否退出安全模式时对 block 的最小副本数的要求,默认为1,a separate minimum replication factor for calculating safe block count. This is an expert level setting. Setting this lower than the dfs.namenode.replication.min is not recommend and/or dangerous for production setups. When it's not set it takes value from dfs.namenode.replication.min;
- dfs.namenode.replication.min: block 的最小副本数,default 1, Minimal block replication;
其他磁盘预留空间大小类参数:dfs.datanode.du.reserved/dfs.datanode.du.reserved.pct/dfs.datanode.du.reserved.calculator/dfs.namenode.resource.du.reserved/dfs.namenode.resource.checked.volumes/dfs.namenode.resource.checked.volumes.minimum;
5 一个某客户生产环境HDFS 进入安全模式的修复案例
某客户线上业务系统中的大数据 HIVE 作业无法运行,查看 hdfs 发现进入了安全模式,如下所示:

进一步查看发现,所有 datanode 都成功启动了,但部分 datanode 存在存储卷故障,且这些存储卷背后是 nfs 网络文件系统,如下所示:


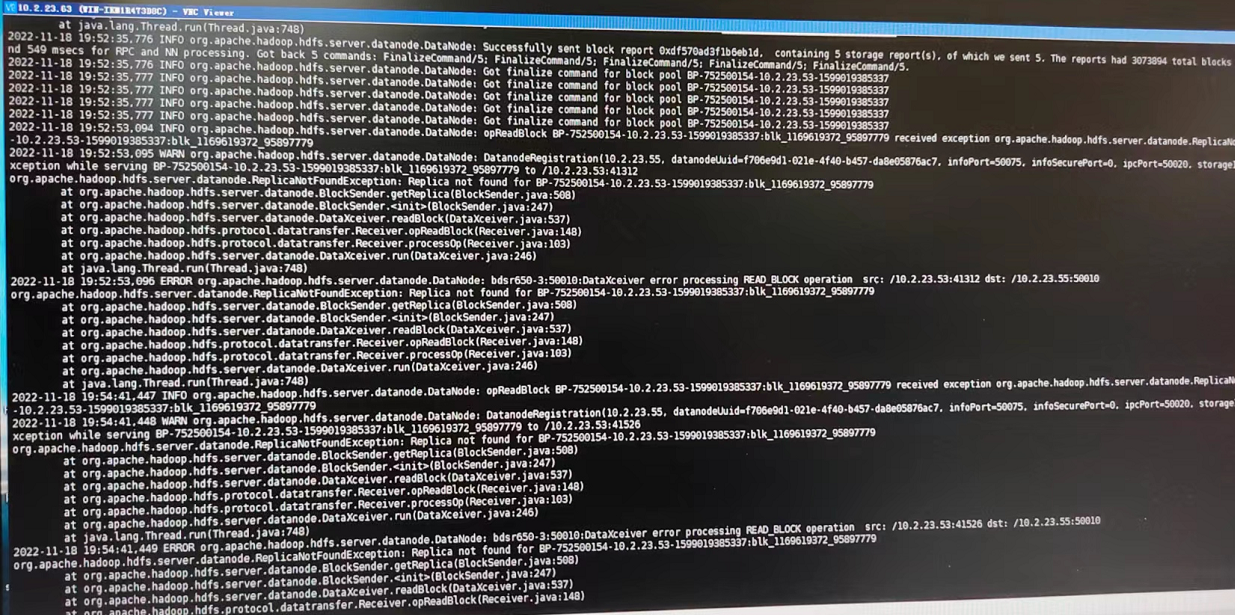
查看 datanode日志发现,datanode 底层的 DataXceiver 线程无法读取部分 block,导致 ReplicaNotFoundException:
通过 CM 管控台的 “诊断-日志” 页面,指定服务为HDFS,指定时间为近期1个小时,指定日志级别为 WARN,搜索发现,调用方法
user=pwd.getpwuid(s.st_uid) 时报错了:keyError:‘getpwuid(): uid not found: 4294967294’,且报错对应的正是 nfs 网盘目录:
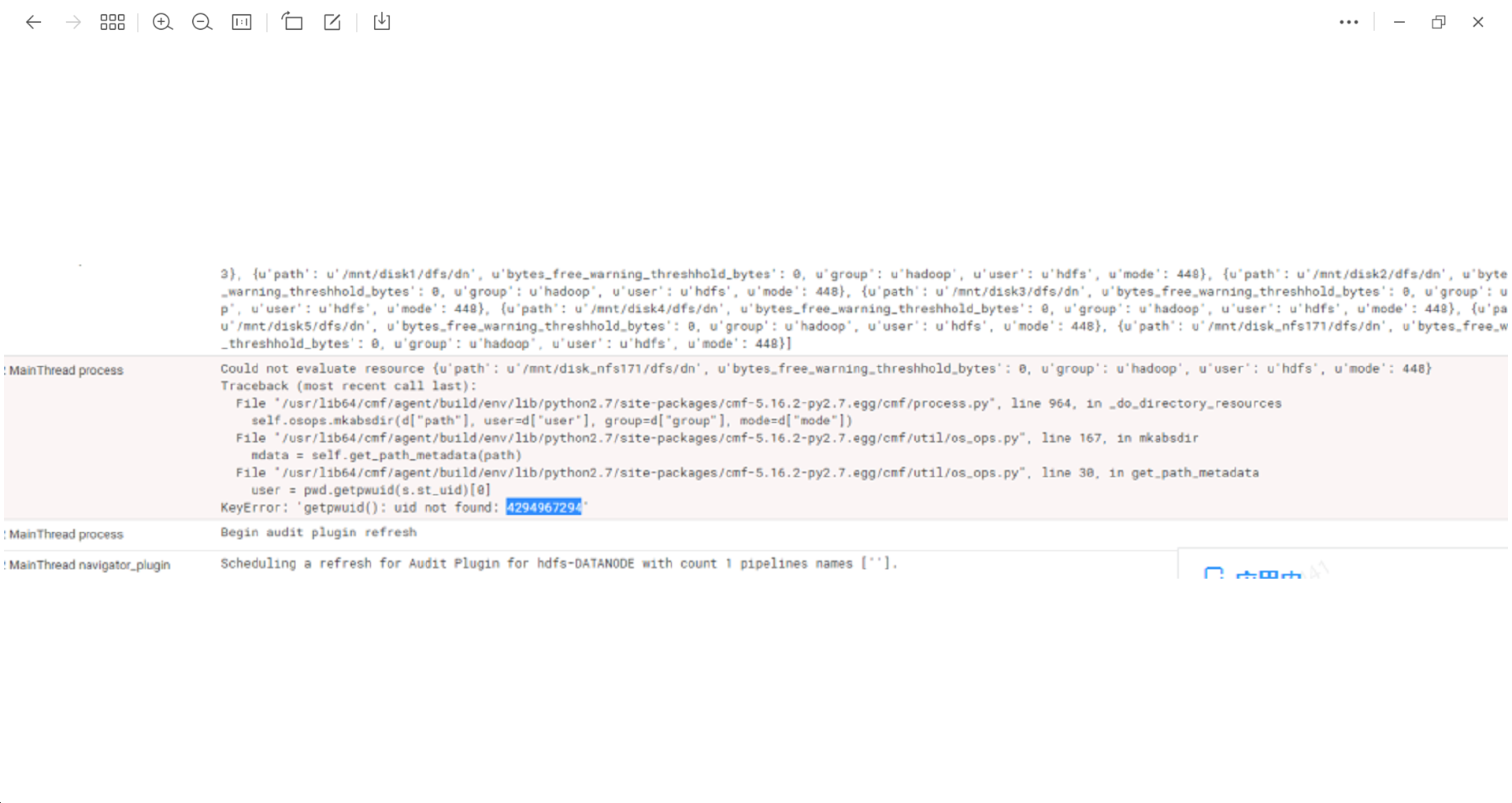
通过 ls 命令查看发现,上述报错对应的 nfs 网盘目录的 owner显示的正是错误信息中的 4294967294,而不是用户名比如 hdfs等,且通过命令 ”uid hdfs“ 查看发现 hdfs 对应的uid并不是4294967294:
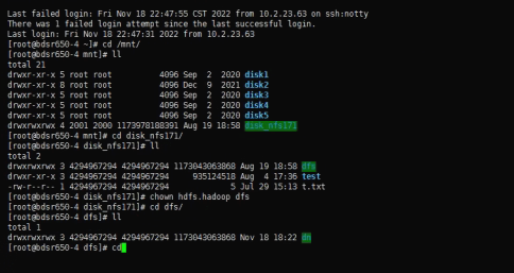
至此问题确认,概括如下:
-
nfs 挂载的目录被认为是 “Datanode Volume Failures” ,所以 nfs 目录下的 block 数据对 hdfs 不可读写,所以副本数达到最小要求的 block 占系统总 block 数的百分比达不到默认的阈值,hdfs 出于数据一致性的要求,自动进入了安全模式;
-
而导致 hdfs 无法读写 nfs 对应目录下的 block数据的原因是,不知出于何种原因,nfs 对应目录的 owner/group 显示的是 4294967294/4294967294,而不是期望的 hdfs/hdfs,所以底层调用方法 user=pwd.getpwuid(s.st_uid)获取 nfs 对应目录的woner/group 时,报错了:keyError:‘getpwuid(): uid not found: 4294967294’,最后 hdfs 因为无法获取 nfs 对应目录的 owner/group 而无法读取该目录下的文件;
-
为修复问题,手动通过命令 chown 更改了nfs 对应目录的 owner/group 为 hdfs/hdfs,然后重启 hdfs,在重启后 hdfs 自动进入并自动退出了安全模式,正常对外提供读写服务。
-
为避免节点重启再出现上述问题,后续安排了了解 nfs 的运维同学帮忙排查下 nfs 挂载的目录为什么显示的 owner/group 是 4294967294/4294967294 而不是 hdfs/hdfs。
-
最后需要强调说明下,由于 NFS 在性能和稳定性上相比本地磁盘差距不小,不建议在 hdfs 底层使用 nfs 网盘。(如果在测试等环境使用 nfs 网盘,一定要记得需要通过修改文件 /etc/fstab 确保开机自动挂载 nfs).