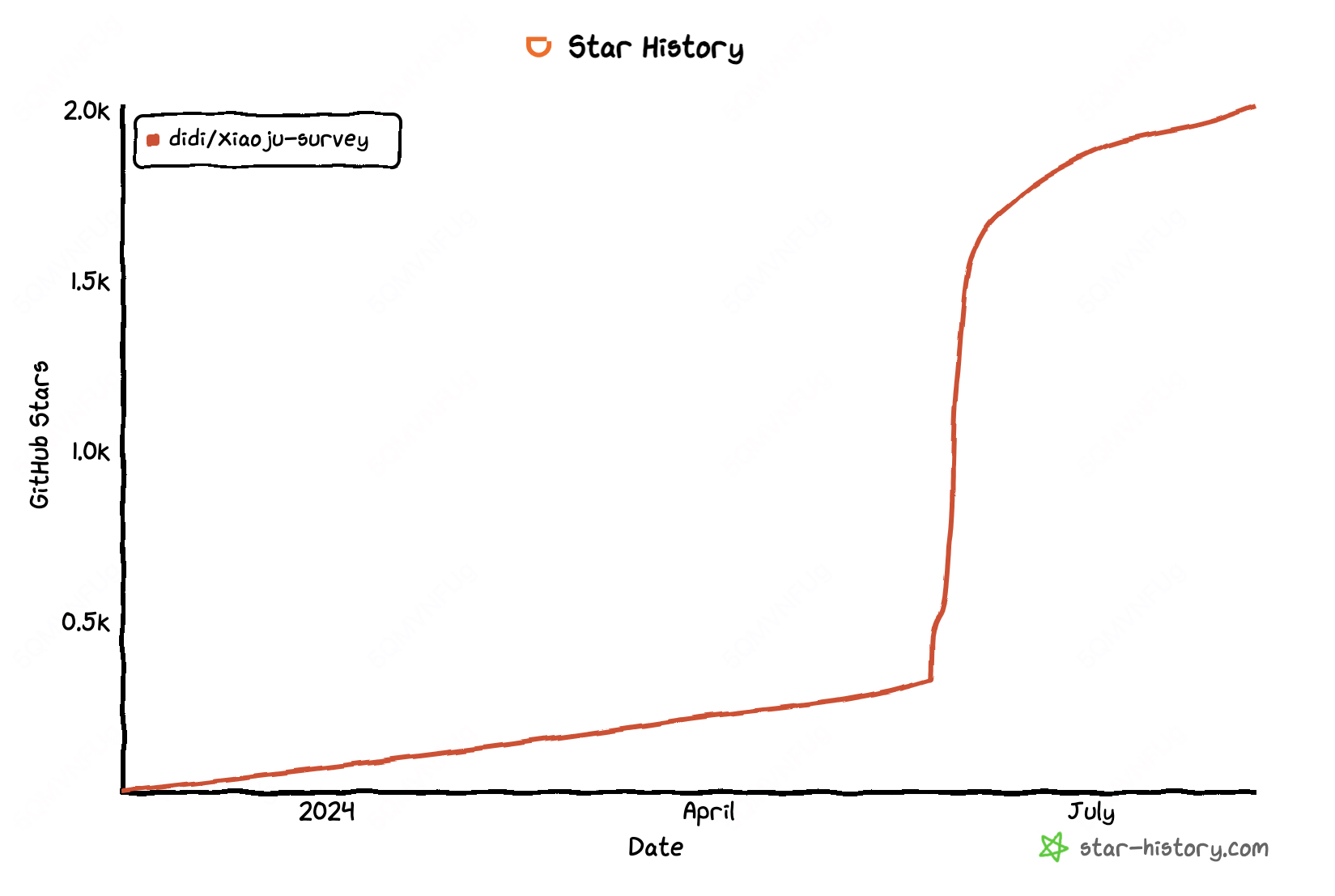
101. 孤岛的总面积

DFS搜索:
-
dfs函数是一个递归函数,用于深度优先搜索(DFS)遍历网格中的陆地区域。它将访问过的陆地标记为0,并统计陆地的数量。 -
我们首先定义了四个方向的移动偏移量
dir。 -
global count语句用于声明count为全局变量,以便在dfs函数中修改它。 -
在
dfs函数开始处,先进行条件判断,如果当前坐标越界或不是陆地(值为1),则直接返回。这是终止条件。 -
如果当前单元格是陆地,将其标记为已访问(设置为0),并增加
count。 -
通过递归调用
dfs函数,继续向四个方向搜索,直到所有连通的陆地都被访问。 -
main函数首先读取输入,初始化网格和全局计数器count。 -
然后,代码分别从网格的四边开始,向中间搜索,对每个找到的陆地区域执行
dfs,并将访问过的陆地标记为海水。 -
搜索完边缘后,重置
count并继续搜索剩余的陆地区域,计算连通的陆地区域数量。
def dfs(grid, x, y):
# 定义四个方向的移动偏移量
dir = [[-1, 0], [0, -1], [1, 0], [0, 1]]
global count # 使用全局变量count来统计陆地空格数量
if not (0 <= x < len(grid) and 0 <= y < len(grid[0]) and grid[x][y] == 1):
return # 先判断终止条件:坐标越界或不是陆地
grid[x][y] = 0 # 标记访问过的陆地为0(海水)
count += 1 # 增加陆地数量计数
for dx, dy in dir: # 向四个方向遍历
nextx, nexty = x + dx, y + dy
dfs(grid, nextx, nexty) # 对新位置递归调用dfs函数
def main():
global count # 声明全局变量count
count = 0
n, m = map(int, input().split())
grid = []
for _ in range(n):
grid.append(list(map(int, input().split())))
# 从左侧边和右侧边向中间遍历
for i in range(n):
if grid[i][0] == 1: dfs(grid, i, 0)
if grid[i][m - 1] == 1: dfs(grid, i, m - 1)
# 从上边和下边向中间遍历
for j in range(m):
if grid[0][j] == 1: dfs(grid, 0, j)
if grid[n - 1][j] == 1: dfs(grid, n - 1, j)
# 重置count,重新计算剩余的陆地区域数量
count = 0
for i in range(n):
for j in range(m):
if grid[i][j] == 1:
dfs(grid, i, j) # 对每个未访问的陆地区域执行dfs
count += 1 # 增加连通区域的计数
print(count) # 打印连通陆地区域的数量
if __name__ == "__main__":
main()BFS搜索:
from collections import deque
def bfs(grid, x, y):
# 定义四个方向的移动偏移量
dir = [[0, 1], [1, 0], [0, -1], [-1, 0]]
global count # 使用全局变量count来统计遍历的陆地数量
queue = deque([(x, y)]) # 使用双端队列deque实现广度优先搜索
grid[x][y] = 0 # 将起始点标记为已访问
count += 1 # 起始点计入陆地数量
while queue:
curx, cury = queue.popleft() # 从队列中取出当前点
for dx, dy in dir: # 遍历四个方向
nextx, nexty = curx + dx, cury + dy
# 检查新坐标是否在网格内
if 0 <= nextx < len(grid) and 0 <= nexty < len(grid[0]):
# 如果新坐标是未访问的陆地,则加入队列并标记
if grid[nextx][nexty] == 1:
queue.append((nextx, nexty))
count += 1
grid[nextx][nexty] = 0 # 标记为已访问
def main():
global count # 声明全局变量count
count = 0
n, m = map(int, input().split())
grid = [list(map(int, input().split())) for _ in range(n)]
# 从网格的边缘向中间遍历
for i in range(n):
if grid[i][0] == 1: bfs(grid, i, 0) # 左侧边
if grid[i][m - 1] == 1: bfs(grid, i, m - 1) # 右侧边
for j in range(m):
if grid[0][j] == 1: bfs(grid, 0, j) # 上边
if grid[n - 1][j] == 1: bfs(grid, n - 1, j) # 下边
# 重置count,重新计算网格内部的陆地数量
count = 0
for i in range(n):
for j in range(m):
if grid[i][j] == 1:
bfs(grid, i, j) # 遍历剩余的陆地
count += 1 # 增加连通区域的计数
print(count) # 打印连通陆地区域的数量
if __name__ == "__main__":
main()102. 沉没孤岛
步骤一:深搜或者广搜将地图周边的 1 (陆地)全部改成 2 (特殊标记)
步骤二:将水域中间 1 (陆地)全部改成 水域(0)
步骤三:将之前标记的 2 改为 1 (陆地)

def dfs(grid, x, y):
# 定义四个方向的移动偏移量
dir = [[-1, 0], [0, -1], [1, 0], [0, 1]]
grid[x][y] = 2 # 将当前访问的陆地标记为2
for dx, dy in dir: # 向四个方向遍历
nextx, nexty = x + dx, y + dy
# 检查新坐标是否越界
if nextx < 0 or nextx >= len(grid) or nexty < 0 or nexty >= len(grid[0]):
continue
# 如果新坐标是未访问的陆地(值为1)且没有被标记过(不是2)
if grid[nextx][nexty] == 1:
dfs(grid, nextx, nexty) # 递归遍历
def main():
n, m = map(int, input().split())
grid = [list(map(int, input().split())) for _ in range(n)]
# 步骤一:从网格边缘向中间遍历
for i in range(n):
if grid[i][0] == 1: dfs(grid, i, 0) # 左侧边
if grid[i][m - 1] == 1: dfs(grid, i, m - 1) # 右侧边
for j in range(m):
if grid[0][j] == 1: dfs(grid, 0, j) # 上边
if grid[n - 1][j] == 1: dfs(grid, n - 1, j) # 下边
# 步骤二、步骤三:将边缘遍历标记过的陆地(2)还原为陆地(1)
# 并将未访问的陆地(1)标记为未访问(0)
for i in range(n):
for j in range(m):
if grid[i][j] == 1:
grid[i][j] = 0
elif grid[i][j] == 2:
grid[i][j] = 1
# 打印最终的网格状态
for row in grid:
print(" ".join(map(str, row)))
if __name__ == "__main__":
main()103. 水流问题
反向思维:从第一组边界上的节点 逆流而上,将遍历过的节点都标记上。
同样从第二组边界的边上节点 逆流而上,将遍历过的节点也标记上。
然后两方都标记过的节点就是既可以流太平洋也可以流大西洋的节点。

def dfs(grid, visited, x, y):
# 定义四个方向的移动偏移量
dir = [[-1, 0], [0, -1], [1, 0], [0, 1]]
if visited[x][y]:
return
visited[x][y] = True
for dx, dy in dir:
nextx, nexty = x + dx, y + dy
# 检查新坐标是否越界
if not (0 <= nextx < len(grid)) or not (0 <= nexty < len(grid[0])):
continue
# 注意:这里是从低向高遍历
if grid[x][y] > grid[nextx][nexty]:
continue
dfs(grid, visited, nextx, nexty)
def main():
global n, m
n, m = map(int, input().split())
grid = [list(map(int, input().split())) for _ in range(n)]
# 初始化两个边界访问矩阵
firstBorder = [[False] * m for _ in range(n)]
secondBorder = [[False] * m for _ in range(n)]
# 从最上和最下行的节点出发,向高处遍历
for i in range(n):
dfs(grid, firstBorder, i, 0) # 遍历最左列
dfs(grid, secondBorder, i, m - 1) # 遍历最右列
# 从最左和最右列的节点出发,向高处遍历
for j in range(m):
dfs(grid, firstBorder, 0, j) # 遍历最上行
dfs(grid, secondBorder, n - 1, j) # 遍历最下行
# 找出两个边界都能访问到的节点
for i in range(n):
for j in range(m):
if firstBorder[i][j] and secondBorder[i][j]:
print(i, j)
if __name__ == "__main__":
main()104. 建造最大岛屿
第一步:一次遍历地图,得出各个岛屿的面积,并做编号记录。可以使用map记录,key为岛屿编号,value为岛屿面积
第二步:再遍历地图,遍历0的方格(因为要将0变成1),并统计该1(由0变成的1)周边岛屿面积,将其相邻面积相加在一起,遍历所有 0 之后,就可以得出 选一个0变成1 之后的最大面积。

def dfs(grid, visited, x, y, mark):
# 定义四个方向的移动偏移量
dir = [[0, 1], [1, 0], [0, -1], [-1, 0]]
if visited[x][y] or grid[x][y] == 0: # 终止条件:访问过的节点 或者 遇到海水
return
visited[x][y] = True # 标记访问过
grid[x][y] = mark # 给陆地标记新标签
for dx, dy in dir: # 向四个方向遍历
nextx, nexty = x + dx, y + dy
if 0 <= nextx < len(grid) and 0 <= nexty < len(grid[0]): # 检查是否越界
dfs(grid, visited, nextx, nexty, mark)
def main():
global n, m, count
n, m = map(int, input().split())
grid = [list(map(int, input().split())) for _ in range(n)]
visited = [[False] * m for _ in range(n)] # 标记访问过的点
gridNum = {} # 记录每个岛屿的面积
mark = 2 # 记录每个岛屿的编号
isAllGrid = True # 标记是否整个地图都是陆地
for i in range(n):
for j in range(m):
if grid[i][j] == 0:
isAllGrid = False
if not visited[i][j] and grid[i][j] == 1:
count = 0
dfs(grid, visited, i, j, mark) # 深度优先搜索,标记岛屿
gridNum[mark] = count # 记录岛屿面积
mark += 1 # 记录下一个岛屿编号
if isAllGrid: # 如果整个地图都是陆地
print(n * m) # 返回全面积
return
result = 0 # 记录最后结果
visitedGrid = set() # 标记访问过的岛屿
for i in range(n):
for j in range(m):
if grid[i][j] == 0:
count = 1
visitedGrid.clear()
for k in range(4): # 检查四个方向
neari, nearj = i + dir[k][0], j + dir[k][1]
if not (0 <= neari < n and 0 <= nearj < m): # 检查是否越界
continue
if grid[neari][nearj] in visitedGrid: # 已访问过的岛屿不重复计算
continue
count += gridNum.get(grid[neari][nearj], 0) # 相邻岛屿的面积累加
visitedGrid.add(grid[neari][nearj]) # 标记岛屿已访问
result = max(result, count) # 更新结果
print(result)
if __name__ == "__main__":
main()-
DFS标记岛屿:首先,代码通过DFS算法遍历整个网格,将所有连通的陆地单元格标记为相同的数字(称为“岛屿编号”或
mark)。每个新发现的陆地区域从2开始编号,并在访问该区域的所有单元格时,将它们标记为当前的mark。 -
记录岛屿面积:在DFS过程中,同时计数每个岛屿的单元格数量,并将这个数量与岛屿编号一起存储在字典
gridNum中。 -
检查海水单元格周围:在DFS完成后,代码再次遍历整个网格。这一次,它专门检查海水单元格(
grid[i][j] == 0)。 -
累加周围岛屿面积:对于每个海水单元格,代码检查其四个相邻单元格(上、下、左、右)。如果一个相邻单元格是陆地,且它的编号(即之前DFS过程中赋予的
mark)不在当前的visitedGrid集合中,则将该岛屿的面积(从gridNum中获取)累加到count变量中,并将该岛屿编号添加到visitedGrid中,以避免重复计算。 -
更新最大结果:对于每个海水单元格,如果通过连接周围的岛屿,累加得到的面积大于当前记录的最大值
result,则更新result。 -
输出结果:最后,代码输出在整个网格中找到的,通过将一个海水单元格变成陆地而能够获得的最大岛屿面积。