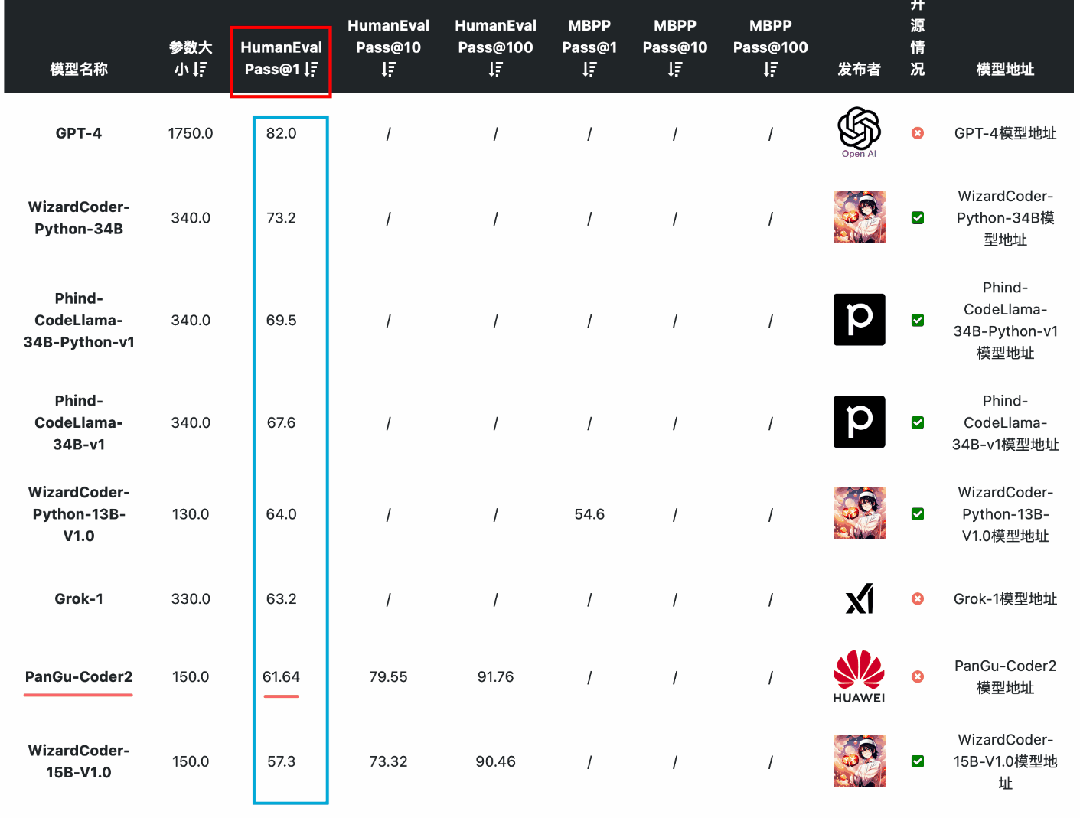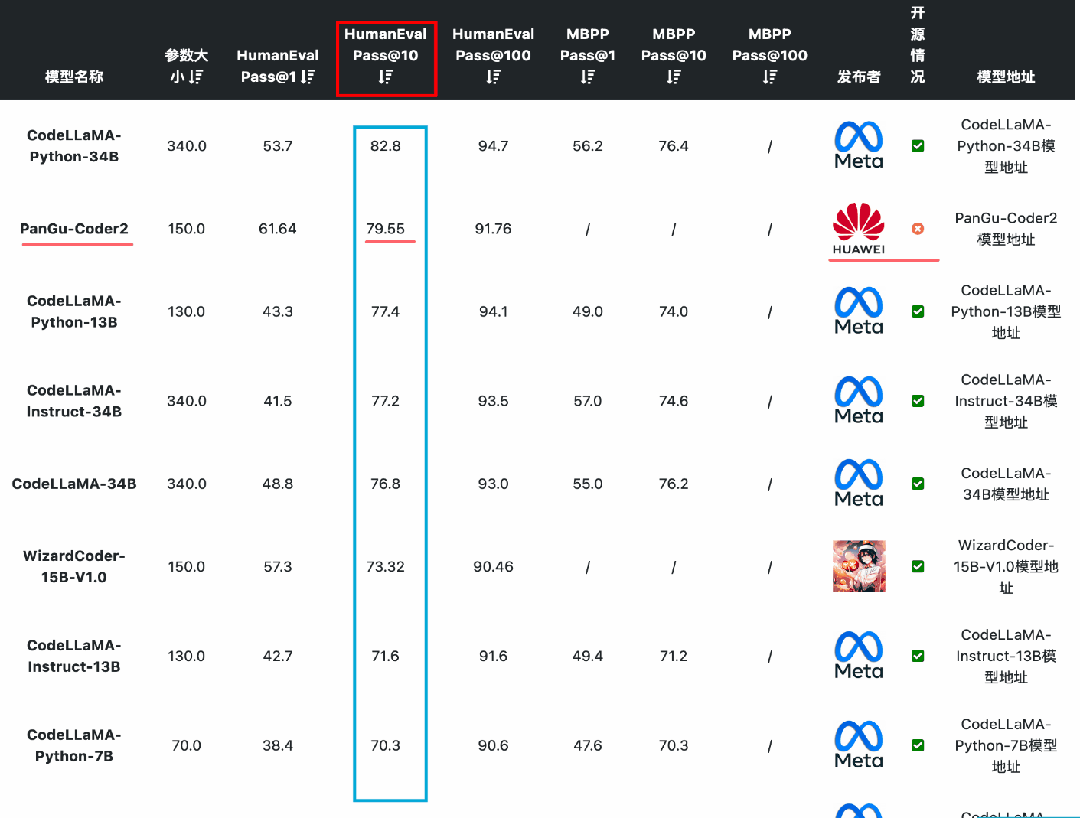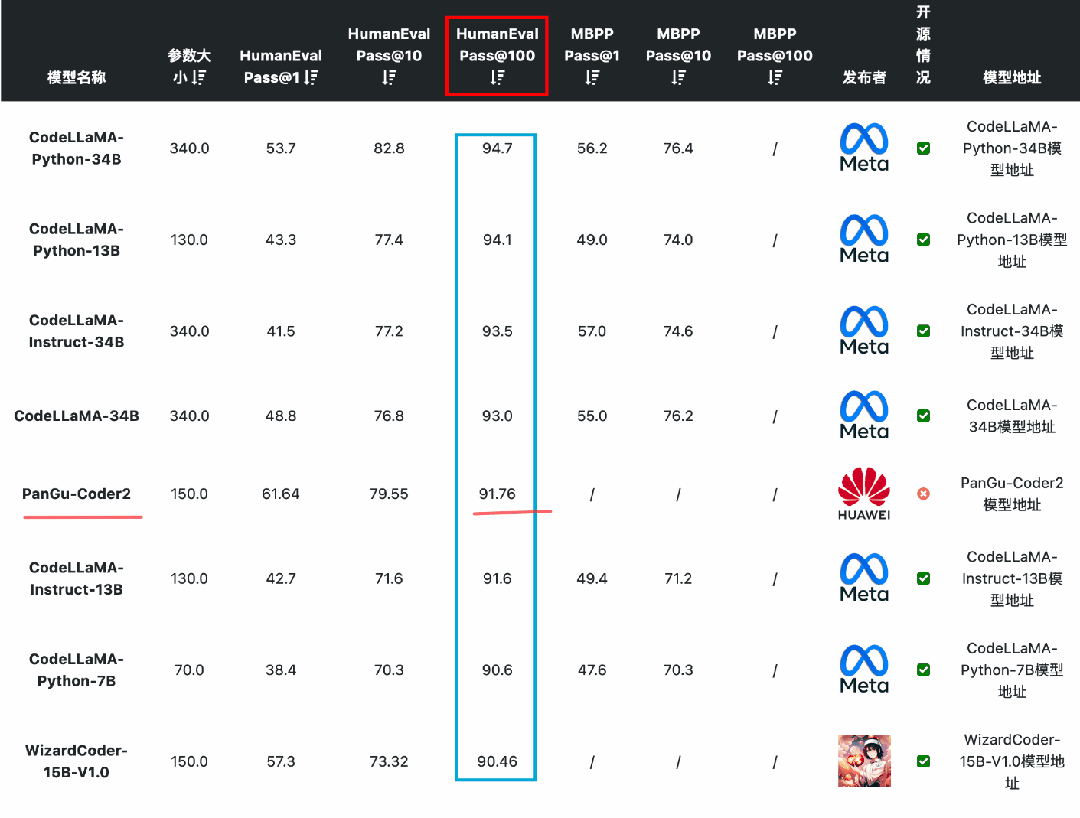
最小斯坦纳树
给定点的“最小生成树”问题。
背景
给定无向连通图 G = ( V , E ) G=(V,E) G=(V,E),给出包含 k k k 个结点的点集 S S S,包含点集 S S S 的连通图被称作 斯坦纳树。但我们关注的是如何求出包含点集 S S S 的最小连通图 G ′ = ( V ′ , E ′ ) G'=(V',E') G′=(V′,E′) 即 最小斯坦纳树。其中 S ⊆ V ′ , E ′ ⊆ E S\subseteq V',E'\subseteq E S⊆V′,E′⊆E。
此处的最小可以指最小的点权和、边权和等。
求解最小斯坦纳树是一个 N P − H a r d \color{red}NP-Hard NP−Hard 问题,所以只会有近似解,并且数据范围不会太大即 k ≤ 10 k\leq10 k≤10。
目前的最好算法的算法时间复杂度为: O ( 3 K N + 2 K M l o g M ) O(3^KN+2^KMlogM) O(3KN+2KMlogM)。其中 N = ∣ V ∣ , M = ∣ E ∣ N=|V|,M=|E| N=∣V∣,M=∣E∣。
动态规划+状态压缩
笔者对着题解思考了这个方法近 1 1 1 天半,并网上查阅了很多资料,再加上自己的一些证明,终于能够彻底搞懂这个算法的精髓。下文将着重论述笔者当时卡住的地方。
我们先假设求的是包含点集 S S S 的边权和最小的连通块。设权重函数 W : E → N W:E\rarr N W:E→N。
【起源】
【性质 1 1 1】 包含点集 S S S 的边权和最小的子图 G ′ = ( V ′ , E ′ ) G'=(V',E') G′=(V′,E′) 一定是一棵树。
【证明】若 G ′ G' G′ 中包含环,那么将环中边权最大的边删去后, G ′ G' G′ 仍连通且边权和变得更小,与前面假设的边权和最小矛盾,故 G ′ G' G′ 不含环,证毕。
根据性质 1 1 1,我们不难得到一个暴力算法:枚举 G G G 的所有子图 ,对子图进行最小生成树算法。虽然这样一定能够求出包含 S S S 的斯坦纳树,但时间复杂度是 O ( 2 V E l o g V ) O(2^{V}ElogV) O(2VElogV),这是因为有许多子图是没必要枚举的,且每次枚举后还要进行生成树算法,不如我们干脆就从包含 S S S 的树开始转移。
设 d p [ i ] [ S ] dp[i][S] dp[i][S] 表示以 i i i 为根结点且包含 S S S 的树的最小边权和,因为 S S S 是一个集合,且集合内的元素不超过 10 10 10,所以我们考虑用二进制来表示这个集合。
到这里,几乎所有的题解/博客都是直接给出转移方程,然后再贴个代码。但里面的内容却不细讲,可能是觉得大家都学到斯坦纳树了,没必要再写太过详尽。但是却苦了我这个菜鸟。
为了理解透彻我们先从初始化开始讲。
【初始化】
设 S = { t e r m i n a l [ 1 ] , t e r m i n a l [ 2 ] , ⋯ , t e r m i n a l [ k ] } S=\{terminal[1],terminal[2],\cdots,terminal[k]\} S={terminal[1],terminal[2],⋯,terminal[k]} 。(最初定义斯坦纳树的论文中,管 S S S 中的点叫做终端( t e r m i n a l terminal terminal)点,斯坦纳树中的不属于终端点的其他点叫做斯坦纳点。)那么则有初始化:
for i in (1,2,...,k) :
dp[terminal[i]][1<<(i-1)] = 0;
d p [ t e r m i n a l [ i ] ] [ 1 < < ( i − 1 ) ] dp[terminal[i]][1<<(i-1)] dp[terminal[i]][1<<(i−1)] 中,根是终端点本身,包含的集合也是终端点本身。因为算的是子树的最小边权和,而只有一个点的树显然没有边,所以赋值为 0 0 0。
数组第二维的 ( i − 1 ) (i-1) (i−1) 是为了和集合 S S S 的二进制表示所对齐,因为 S S S 的二进制表示是 1 ⋯ 1 ⏟ k 个 1 \underbrace{1\cdots 1}_{k个1} k个1 1⋯1,即 ( 1 < < k ) − 1 (1<<k)-1 (1<<k)−1,而 1 < < ( i − 1 ) 1<<(i-1) 1<<(i−1) 正好是 S S S 的二进制中第 i i i 个 1 1 1。
初始化了解完了之后,我们需要了解答案是怎么产生的。
【答案产生】
{ d p [ i ] [ S ] ; ∀ i ∈ S } \{dp[i][S];\forall i\in S\} {dp[i][S];∀i∈S} 显然都是正确答案,因为 d p [ i ] [ S ] dp[i][S] dp[i][S] 表示以 i i i 为根结点且包含 S S S 的树的最小边权和,而最小斯坦纳树显然包括 S S S,所以 S S S 中的任意一点为根都可以作为答案。
因为最终答案的 S S S 的二进制表示中有 k k k 个 1 1 1,但初始化时只有一个 1 1 1,所以 d p dp dp 的转移过程中必然需要子集合的合并。
比如说 d p [ i ] [ 00 ⋯ 10 ] dp[i][00\cdots10] dp[i][00⋯10] 和 d p [ i ] [ 00 ⋯ 01 ] dp[i][00\cdots01] dp[i][00⋯01] 可以合并为 d p [ i ] [ 00 ⋯ 11 ] dp[i][00\cdots11] dp[i][00⋯11]( d p dp dp 的第二维是集合的二进制表示)。
看到这里可能会感到好奇,因为初始化时 d p dp dp 数组中根和集合都是终端点本身,即一个点对应一个集合,但上文的 d p [ i ] [ 00 ⋯ 10 ] dp[i][00\cdots10] dp[i][00⋯10] 和 d p [ i ] [ 00 ⋯ 01 ] dp[i][00\cdots01] dp[i][00⋯01] 却是一个点对应两个集合。这是怎么从初始态转移而来的?
我们定义
d
(
i
,
j
)
d(i,j)
d(i,j) 为原图中
i
⇝
j
i\leadsto j
i⇝j 的最短路径长度。我们强行让
j
j
j 结点和 一棵以
t
e
r
m
i
n
a
l
[
i
]
terminal[i]
terminal[i] 为根,包含集合
1
<
<
(
i
−
1
)
1<<(i-1)
1<<(i−1) 的子树连通,那么连通后就有了一棵新树。以
j
j
j 为根,包含集合
1
<
<
(
i
−
1
)
1<<(i-1)
1<<(i−1) 的子树的最小边权和是:
d
p
[
j
]
[
1
<
<
(
i
−
1
)
]
=
d
p
[
t
e
r
m
i
n
a
l
[
i
]
]
[
1
<
<
(
i
−
1
)
]
+
d
(
t
e
r
m
i
n
a
l
[
i
]
,
j
)
(1)
dp[j][1<<(i-1)] = dp[terminal[i]][1<<(i-1)] + d(terminal[i],j)\tag{1}
dp[j][1<<(i−1)]=dp[terminal[i]][1<<(i−1)]+d(terminal[i],j)(1)
也就是在原来的基础上加上了
t
e
r
m
i
n
a
l
[
i
]
terminal[i]
terminal[i] 到
j
j
j 的最短路。这个式子的正确性是显然的。
接下来我们将演示在一个简单图上的 d p dp dp 过程。
请看下图演示
S = { 1 , 3 } S=\{1,3\} S={1,3}

初始化
d p [ 1 ] [ 01 ] = 0 , d p [ 3 ] [ 10 ] = 0 dp[1][01]=0,dp[3][10]=0 dp[1][01]=0,dp[3][10]=0( d p dp dp 的第二维是集合的二进制表示, 01 01 01 表示 结点 1 1 1 是第一个终端点, 10 10 10 表示结点 3 3 3 是第二个终端点。)。
强行连通
2 , 3 , 4 2,3,4 2,3,4 与 d p [ 1 ] [ 01 ] dp[1][01] dp[1][01] 代表的子树连通:
d p [ 2 ] [ 01 ] = 3 , d p [ 3 ] [ 01 ] = 1 , d p [ 4 ] [ 01 ] = 3 dp[2][01]=3,dp[3][01]=1,dp[4][01]=3 dp[2][01]=3,dp[3][01]=1,dp[4][01]=3。
1 , 2 , 4 1,2,4 1,2,4 与 d p [ 3 ] [ 10 ] dp[3][10] dp[3][10] 代表的子树连通:
d p [ 1 ] [ 10 ] = 1 , d p [ 2 ] [ 10 ] = 2 , d p [ 4 ] [ 10 ] = 4 dp[1][10]=1,dp[2][10]=2,dp[4][10]=4 dp[1][10]=1,dp[2][10]=2,dp[4][10]=4。
现在所有结点都连通了包含 t e r m i n a l [ i ] terminal[i] terminal[i] 的子树,且包含的集合大小为 1 1 1 。
合并子树
接下来对于每个结点
v
v
v ,我们将两棵以
v
v
v 为根,包含大小为
1
1
1 的集合的子树,合并为一棵 以
v
v
v 为根,包含大小为
2
2
2 的集合的树。
d
p
[
v
]
[
11
]
=
d
p
[
v
]
[
10
]
+
d
p
[
v
]
[
01
]
(2)
dp[v][11]=dp[v][10]+dp[v][01]\tag{2}
dp[v][11]=dp[v][10]+dp[v][01](2)
在这个例子中,
S
S
S 集合大小为
2
2
2,所以此时已经做完了。不妨更普遍一些,
∣
S
∣
>
2
|S|>2
∣S∣>2 显然我们要遍历所有的子集合,设
S
S
S 的子集合为
S
′
S'
S′,则有:
d
p
[
v
]
[
S
]
=
m
i
n
∀
S
′
⊆
S
(
d
p
[
v
]
[
S
]
,
d
p
[
v
]
[
S
′
]
+
d
p
[
v
]
[
S
−
S
′
]
)
(2’)
dp[v][S]=\underset{\forall S'\subseteq S}{min}(dp[v][S],dp[v][S']+dp[v][S-S'])\tag{2'}
dp[v][S]=∀S′⊆Smin(dp[v][S],dp[v][S′]+dp[v][S−S′])(2’)
那么我们可以将
(
1
)
(1)
(1) 式的强行连通也写的更具有普遍性(这样可以求出真正的
d
p
[
v
]
[
S
]
dp[v][S]
dp[v][S]):
d
p
[
v
]
[
S
]
=
m
i
n
∀
u
∈
V
{
d
p
[
u
]
[
S
]
+
d
(
u
,
v
)
}
(1’)
dp[v][S]=\underset{\forall u\in V}{min}\{dp[u][S]+d(u,v)\}\tag{1'}
dp[v][S]=∀u∈Vmin{dp[u][S]+d(u,v)}(1’)
所以,
d
p
dp
dp 过程就是不断的进行三个操作:“强行连通”,“合并子树“,“强行连通”。
稍等…为什么合并子树之后还需要进行强行连通?
举个简单的例子: S = 2 S=2 S=2,对于任意一个结点 v v v 而言,合并子树只是令 d p [ v ] [ 11 ] = d p [ v ] [ 01 ] + d p [ v ] [ 10 ] dp[v][11]=dp[v][01]+dp[v][10] dp[v][11]=dp[v][01]+dp[v][10]。但不代表合并之后 d p [ v ] [ 01 ] + d p [ v ] [ 10 ] dp[v][01]+dp[v][10] dp[v][01]+dp[v][10] 就是真正的一棵以 v v v 为根且包含 S S S 的最小边权和子树。

假设 v = 1 v=1 v=1, S = { 3 , 4 } S=\{3,4\} S={3,4},此时经过一次强行连通之后 d p [ 1 ] [ 01 ] = a + c , d p [ 1 ] [ 10 ] = a + b dp[1][01]=a+c,dp[1][10]=a+b dp[1][01]=a+c,dp[1][10]=a+b,合并后 d p [ 1 ] [ 11 ] = 2 a + b + c dp[1][11]=2a+b+c dp[1][11]=2a+b+c。但实际上 d p [ 1 ] [ 11 ] = d p [ 2 ] [ 11 ] + d ( 1 , 2 ) = a + b + c dp[1][11]=dp[2][11]+d(1,2)=a+b+c dp[1][11]=dp[2][11]+d(1,2)=a+b+c。这也就是我们需要再进行一次强行连通的目的。因为进行完了一次强行连通,我们会对所有的包含集合大小相同的以 v v v 为根的树求出其真正的最小边权和。
这就是为什么我们要在合并子树之后再进行一次强行连通。
但其实,如果我们循环进行两次操作:“合并子树” ,“强行连通” 也是没问题的。因为合并子树的目的是 “扩大集合”,前提是子树所代表的最小边权和准确。因为初始时只有 d p [ t e r m i n a l [ i ] ] [ 1 < < ( i − 1 ) ] dp[terminal[i]][1<<(i-1)] dp[terminal[i]][1<<(i−1)],如果此时我们进行合并子树的话,是不会有任何反应的,因为没有进行连通,所以一个点只对应一个集合。然后再进行强行连通操作。所以每次只要执行两次操作就行了,更省事。
即 d p dp dp 过程就是不断的进行两个操作:“合并子树”,“强行连通”。
到这里,我们可以用一个基础版的代码求出给定点集 S S S 的最小斯坦纳树。基础版的时间复杂度是 O ( 3 k N + N 2 l o g M + 2 k N 2 ) O(3^kN+N^2logM+2^kN^2) O(3kN+N2logM+2kN2)。因为我们需要用到最短路,所以考虑用 n n n 次 d i j k s t r a dijkstra dijkstra 求解出任意两点之间的最短路(当且仅当不含负权边,且 N N N 数量级较小时用)。
合并子树:遍历 S S S 的子集 m a s k mask mask + 遍历每个点 + 枚举 m a s k mask mask 的子集 = O ( 3 k N ) O(3^kN) O(3kN)。
强行连通:遍历 S S S 的子集 m a s k mask mask + 遍历最终根结点 u u u 和中转根结点 v v v = O ( 2 k N 2 ) O(2^kN^2) O(2kN2)。
预处理最短路: n n n 遍 D i j k s t r a Dijkstra Dijkstra = O ( N 2 l o g M ) O(N^2logM) O(N2logM)。
for (int mask = 1; mask < (1 << k); mask ++) {
for (int submask = mask; submask; submask = (submask - 1) & mask)
for (int u = 0; u < N; u ++)
dp[mask][u] = min(dp[mask][u], dp[submask][u] + dp[mask ^ submask][u]);
for (int u = 0; u < N; u ++) {
for (int v = 0; v < N; v ++)
dp[mask][v] = min(dp[mask][v], dp[mask][u] + d[u][v]);
}
【至臻版本】
代码来自 J i a n g l y Jiangly Jiangly(进行了一些个人习惯上的修改)。
for (int s = 0; s < (1 << (K - 1)); s++) {
for (int t = s; t != 0; t = (t - 1) & s)
for (int i = 0; i < N; i++)
dp[s][i] = min(dp[s][i], dp[t][i] + dp[s ^ t][i]);
priority_queue<PII, vector<PII>, greater<PII>> pq;
vector<bool> vis(N, false);
for (int i = 0; i < N; i++)
if (dp[s][i] != inf)
pq.push({dp[s][i], i});
while (!pq.empty()) {
auto [d, x] = pq.top();
pq.pop();
if (vis[x]) continue;
vis[x] = true;
for (auto [y, w] : adj[x]) {
if (dp[s][y] > dp[s][x] + w) {
dp[s][y] = dp[s][x] + w;
pq.push({dp[s][y], y});
}
}
}
}
至臻版本和普通版本的区别就是,至臻版本没有提前预处理出任意两结点之间的最短路。而是在需要用到最短路的时候调用 D i j k s t r a Dijkstra Dijkstra。
我们将有效值统统插入最小优先队列中,然后进行 D i j k s t r a Dijkstra Dijkstra, d p [ S ] [ i ] dp[S][i] dp[S][i] 会在 D i j k s t r a Dijkstra Dijkstra 中松弛为最小值。
【问题】
for (int i = 0; i < N; i++)
if (dp[s][i] != inf)
pq.push({dp[s][i], i});
这段代码为啥和普通的 D i j k s t r a Dijkstra Dijkstra 不一样?正常的 D i j k s t r a Dijkstra Dijkstra 是令起点为 0 0 0,并且只有一个起点。
这段代码的意思是什么?
往最小堆中插入多个值,其中最小的会在第一次被拿出来。此时最小的值对应的根节点可以看作起点。假设这个点为 u u u,然后用这个起点的值 d p [ s ] [ u ] dp[s][u] dp[s][u],去更新起点周围的点,设为 v v v。此时如果 d p [ s ] [ v ] dp[s][v] dp[s][v] 大于 d p [ s ] [ u ] + w ( u , v ) dp[s][u]+w(u,v) dp[s][u]+w(u,v),那么说明 v v v 从 u u u 转移过来更优(强行连通操作之前, v v v 的合并只会从 v v v 的子树中转移,详细见合并操作)。那么 v v v 就会被松弛成功。更新完 u u u 周围的点,我们重新从最小堆中拿出最小的点作为起点去松弛周围的点。
为什么这样做是对的?
【性质 2 2 2】每次从最小堆中取出来的值,设其对应根结点是 u u u,显然 u u u 一定从最优的点转移过来的。
【证明】因为进行 D i j k s t r a Dijkstra Dijkstra 的元素一定是同集合大小的,假设 d p [ s ] [ u ] dp[s][u] dp[s][u] 是第一个被取出来的最小值,若它不是最优解,假设 u u u 真正的最优解是 ρ ( s , u ) \rho(s,u) ρ(s,u),且设它是由 v v v 转移而来的,显然有 ρ ( s , u ) = d p [ s ] [ v ] + d ( u , v ) ≤ d p [ s ] [ u ] \rho(s,u)=dp[s][v]+d(u,v) \leq dp[s][u] ρ(s,u)=dp[s][v]+d(u,v)≤dp[s][u]。也就是说存在 d p [ s ] [ v ] < d p [ s ] [ u ] dp[s][v]<dp[s][u] dp[s][v]<dp[s][u],所以 d p [ s ] [ u ] dp[s][u] dp[s][u] 不是第一个被取出来的最小值,这与假设矛盾。所以第一个被取出的最小值一定是最优解。
假设 d p [ s ] [ v ] dp[s][v] dp[s][v] 是第 t t t 次被取出来的最小值,如果此时 d p [ s ] [ v ] = ρ ( s , v ) dp[s][v]=\rho(s,v) dp[s][v]=ρ(s,v),说明接下来它不会被后续的点再更新。
设后续的点为 x x x,如果 x x x 能更新 v v v,说明 d p [ s ] [ v ] > d p [ s ] [ x ] + d ( v , x ) dp[s][v]>dp[s][x]+d(v,x) dp[s][v]>dp[s][x]+d(v,x),又因为后续出现的点 d p [ s ] [ x ] > d p [ s ] [ v ] dp[s][x]>dp[s][v] dp[s][x]>dp[s][v],这与假设矛盾,所以 x x x 必然是 v v v 或者 v v v 之前出现过的点即前 t − 1 t-1 t−1 个点。所以每次从最小堆中取出来的值,一定是最优解。
性质 2 2 2 证毕。
根据性质 2 2 2,我们可以知道当 D i j k s t r a Dijkstra Dijkstra 结束之后, ∀ i ∈ V , d p [ s ] [ i ] = ρ ( s , i ) \forall i\in V,dp[s][i]=\rho(s,i) ∀i∈V,dp[s][i]=ρ(s,i)。所以算法正确。
p s ps ps:现在是凌晨四点半,11点的时候喝了一杯咖啡,然后奋战到现在,妈呀真的战斗了个痛快。为什么写这一篇文章,主要是因为我实在看不懂网上的题解,有好多地方不清楚,然后又没有人细讲,所以干脆自己写了一篇,供大家参考。当然斯坦纳树还有许多的应用,我后续再补充,应该不会有第一次学这么难。