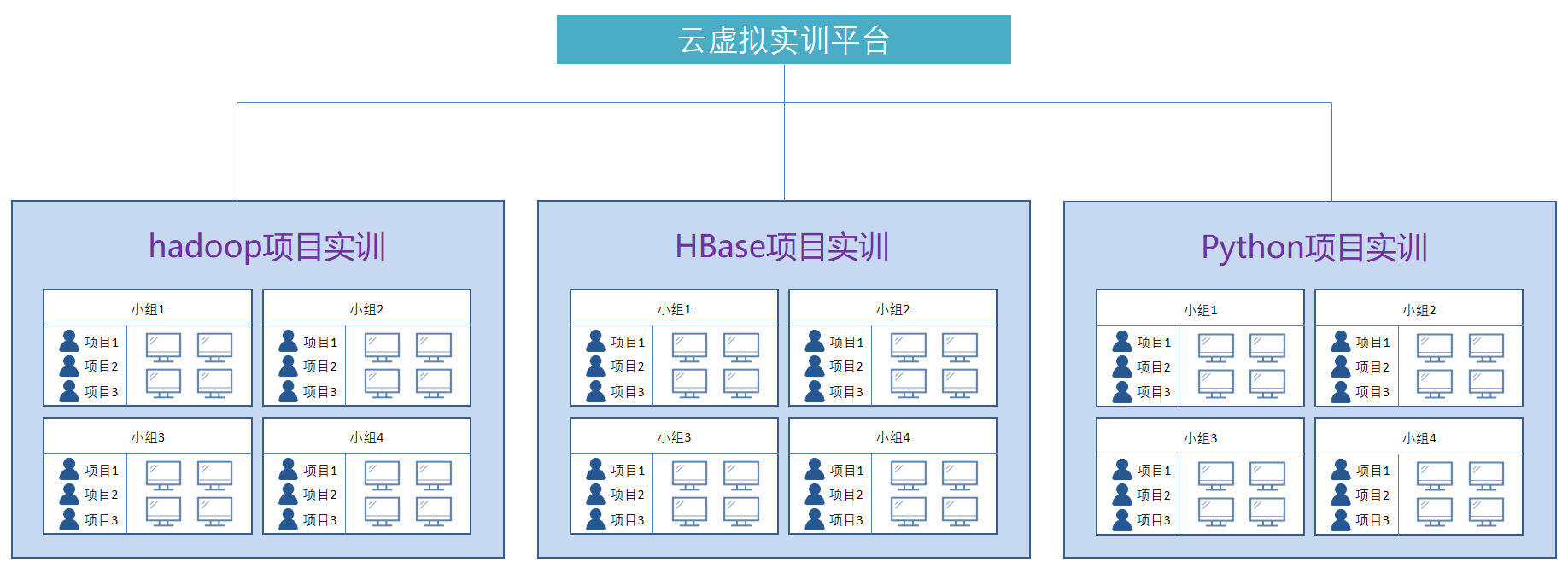
一种新方法可以训练神经网络对损坏的数据进行分类,同时预测下一步操作。 它可以为机器人制定灵活的计划,生成高质量的视频,并帮助人工智能代理导航数字环境。

Diffusion Forcing 方法可以对嘈杂的数据进行分类,并可靠地预测任务的下一步,例如帮助机器人完成操纵任务。 在一项实验中,它帮助机械臂将玩具水果重新排列到圆形垫子上的目标位置,尽管开始时位置随机且存在视觉干扰。 鸣谢:图片:Mike Grimmett/MIT CSAIL Mike Grimmett/MIT CSAIL
在当前的人工智能潮流中,序列模型因其分析数据和预测下一步行动的能力而大受欢迎。 例如,你可能用过 ChatGPT 这样的下一个标记预测模型,它可以预测序列中的每个单词(标记),从而形成用户查询的答案。 还有像 Sora 这样的全序列扩散模型,通过对整个视频序列进行连续 “去噪”,将单词转换成炫目逼真的视觉效果。
麻省理工学院计算机科学与人工智能实验室(CSAIL)的研究人员对扩散训练方案提出了一个简单的改动,使这种序列去噪变得更加灵活。
在应用于计算机视觉和机器人等领域时,下一标记词模型和全序列扩散模型都需要权衡能力。 Next-token 模型可以产生不同长度的序列。 然而,它们在生成这些序列的同时,并不了解远期的理想状态–比如将序列生成导向 10 个标记之外的某个目标–因此需要额外的机制来进行远期(长期)规划。 扩散模型可以执行这种未来条件采样,但缺乏下一个标记模型生成可变长度序列的能力。
CSAIL 的研究人员希望将两种模型的优势结合起来,因此他们创造了一种名为 "Diffusion Forcing"的序列模型训练技术。 这一名称来源于 “教师强化”(Teacher Forcing),它是一种传统的训练方案,将完整的序列生成分解成更小、更容易的下一个标记生成步骤(就像一位好老师简化复杂的概念一样)。
扩散强化发现了扩散模型和教师强化之间的共同点: 它们都使用从未加掩码的标记预测加掩码(噪声)标记的训练方案。 在扩散模型中,它们会逐渐向数据中添加噪声,这可以看作是部分掩蔽。 麻省理工学院研究人员的 "扩散强化法 "可以训练神经网络净化标记集,去除每个标记中不同数量的噪声,同时预测下几个标记。 结果:一个灵活、可靠的序列模型为机器人和人工智能代理带来了更高质量的人工视频和更精确的决策。
通过整理嘈杂的数据并可靠地预测任务的下一步,扩散强化技术可以帮助机器人忽略视觉干扰,完成操作任务。 它还能生成稳定一致的视频序列,甚至引导人工智能代理通过数字迷宫。 这种方法有可能让家用机器人和工厂机器人适应新的任务,并改善人工智能生成的娱乐效果。
"序列模型的目的是以已知的过去为条件,预测未知的未来,这是一种二进制掩蔽。 然而,掩蔽并不需要是二进制的,"第一作者、麻省理工学院电子工程与计算机科学(EECS)博士生、CSAIL 成员陈博源说。 利用 "扩散强化 "技术,我们为每个标记添加了不同程度的噪声,从而有效地起到了分数掩码的作用。 在测试时,我们的系统可以 "解除 “标记集合的屏蔽,并在不久的将来以较低的噪音水平扩散一个序列。 它知道在其数据中应该相信什么,以克服分布外输入”。
在多项实验中,"扩散强化 "技术在忽略误导数据的情况下执行任务,同时预测未来的行动。
例如,当将其应用到机械臂中时,它可以帮助在三个圆形垫子上交换两个玩具水果,这是一系列需要记忆的长视距任务中的一个最简单的例子。 研究人员通过在虚拟现实中对机器人进行远距离控制(或远程操作)来训练机器人。 机器人通过摄像头模仿用户的动作进行训练。
为了生成视频,他们在谷歌 DeepMind 实验室模拟器创建的 "Minecraft "游戏玩法和丰富多彩的数字环境中进行了扩散强化训练。 与类似 Sora 的全序列扩散模型和类似 ChatGPT 的下一个标记模型等同类基线相比,该方法在给定单帧视频时,能生成更稳定、分辨率更高的视频。 这些方法生成的视频似乎并不一致,后者有时甚至无法生成超过 72 帧的工作视频。
Diffusion Forcing 不仅能生成花哨的视频,还能充当运动规划器,引导人们朝着期望的结果或奖励前进。 得益于其灵活性,Diffusion Forcing 可以独特地生成不同视距的计划,执行树状搜索,并将 "远期未来比近期未来更不确定 "这一直觉融入其中。 在求解二维迷宫的任务中,Diffusion Forcing 的表现优于六种基线方法,它能更快地生成通往目标位置的计划,这表明它可以成为未来机器人的有效规划器。
在每次演示中,Diffusion Forcing 都充当全序列模型、下一个标记预测模型或两者兼而有之。 陈博士认为,这种多用途方法有可能成为 "世界模型 "的强大支柱。"世界模型 "是一种人工智能系统,可以通过在数十亿互联网视频上进行训练来模拟世界的动态。 这样,机器人就能根据周围环境想象自己需要做什么,从而执行新颖的任务。 例如,如果你要求机器人在没有经过训练的情况下打开一扇门,模型可以制作一段视频,向机器展示如何打开门。
该团队目前正寻求将他们的方法扩展到更大的数据集和最新的变压器模型,以提高性能。 他们打算扩大工作范围,建立一个类似于 ChatGPT 的机器人大脑,帮助机器人在没有人类示范的情况下在新环境中执行任务。"通过扩散强化,我们正在迈出一步,将视频生成和机器人技术更紧密地结合在一起,"资深作者、麻省理工学院助理教授兼 CSAIL 成员 Vincent Sitzmann 说,他在 CSAIL 中领导着场景表示小组。 “最后,我们希望能利用互联网上视频中存储的所有知识,让机器人为日常生活提供帮助。 还有许多令人兴奋的研究挑战,比如机器人如何通过观察人类来学习模仿人类,即使他们自己的身体与我们的身体如此不同!”
Paper: “Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion”