【多尺度目标检测】是近年来在深度学习领域中备受关注的一项技术,它通过处理图像中不同尺度的目标,显著提升了模型在复杂场景中的检测精度和鲁棒性。多尺度目标检测技术已经在自动驾驶、安防监控和遥感图像分析等多个领域取得了显著成果,其独特的方法和有效的表现使其成为研究热点之一。
为了帮助大家全面掌握多尺度目标检测的方法并寻找创新点,本文总结了最近两年【多尺度目标检测】相关的20篇顶会顶刊的研究成果,这些论文的文章、来源以及论文的代码都整理好了,希望能为各位的研究工作提供有价值的参考。

三篇论文详述
1、Gold-YOLO: Efficient Object Detector via Gather-and-Distribute Mechanism
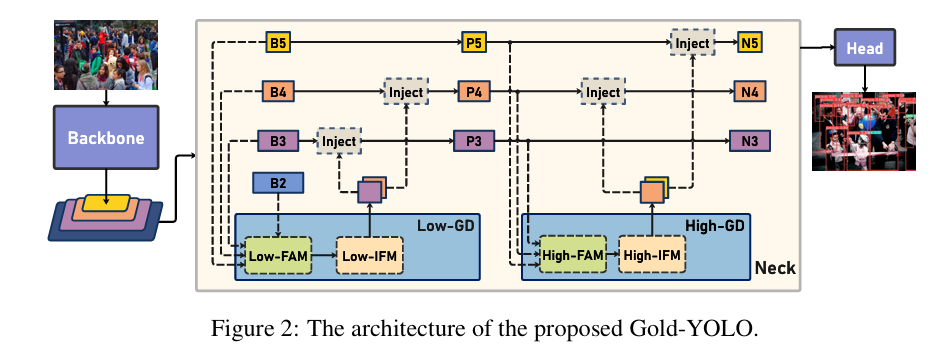
这篇文章主要介绍了一种名为Gold-YOLO的新型高效目标检测模型。Gold-YOLO通过引入一种先进的聚集与分发机制(Gather-and-Distribute,简称GD机制),显著提升了多尺度特征融合的能力,并在不同模型尺寸上实现了延迟与准确性之间的理想平衡。此外,文章还首次在YOLO系列模型中实现了以MAE(Masked Autoencoder)风格进行预训练的方法,进一步提升了模型的收敛速度和准确性。
文章首先概述了目标检测的重要性以及YOLO系列模型在实时目标检测领域的领先地位。作者指出,尽管先前的研究通过修改架构、增强数据和设计新的损失函数等方式提高了基线水平,但现有模型在信息融合方面仍存在问题。为了解决这一问题,文章提出了GD机制,该机制利用卷积和自注意力操作实现高效的信息交换。
Gold-YOLO模型包含两个分支:浅层聚集与分发分支和深层聚集与分发分支,分别通过基于卷积的块和基于注意力的块提取和融合特征信息。此外,为了进一步促进信息流动,文章还引入了一个轻量级的相邻层融合模块,该模块在局部尺度上结合邻近层次的特征。
在实验部分,Gold-YOLO在COCO val2017数据集上达到了39.9%的平均精度(AP),在T4 GPU上达到了1030帧每秒(FPS)的性能,超越了具有相似FPS的先前最先进模型YOLOv6-3.0-N 2.4%。文章还提供了Gold-YOLO的PyTorch和MindSpore代码,方便研究者进一步研究和应用。
文章还对YOLO系列的发展进行了回顾,并讨论了基于Transformer的目标检测方法以及多尺度特征在目标检测中的应用。作者通过消融实验验证了GD结构的有效性,并通过在不同任务和模型上应用GD机制,证明了其通用性和有效性。
最后,文章总结了Gold-YOLO的主要贡献,并指出了其在医疗和智能交通等领域的潜在应用,同时也提到了在军事领域的潜在风险,并承诺将努力防止模型被用于军事目的。文章还讨论了模型的局限性,包括对计算资源的需求和对早期硬件支持的挑战。通过可视化分析,文章展示了Gold-YOLO模型在目标检测中对不同尺寸目标区域的权重分配情况,证明了GD机制在全局特征融合方面的优势。
2、Focal Modulation Networks

这篇文章提出了一种新型的视觉模型——聚焦调制网络(Focal Modulation Networks,简称FocalNets),它是一种创新的注意力机制替代品,用于改善视觉任务中的模型性能。文章的核心贡献是引入了一种新的聚焦调制模块,该模块完全取代了自注意力(Self-Attention, SA)机制,以一种新颖的方式对视觉令牌间的交互进行建模。
聚焦调制包含三个主要组成部分:首先是聚焦上下文化,通过一系列深度卷积层实现,用于编码从短到长范围的视觉上下文;其次是门控聚合,选择性地将上下文信息聚集到每个查询令牌的调制器中;最后是通过元素级仿射变换将调制器注入查询中。这种设计显著提高了模型的解释性,并且与具有相似计算成本的现有最先进自注意力模型相比,在图像分类、目标检测和分割任务上取得了更好的性能。
文章通过大量实验展示了FocalNets的卓越性能。例如,在ImageNet-1K数据集上,即使是尺寸较小的FocalNet模型也能达到82.3%和83.9%的top-1准确率。当在ImageNet-22K数据集上进行预训练并在不同分辨率下微调时,FocalNet能够达到86.5%和87.3%的top-1准确率。在目标检测方面,使用Mask R-CNN作为检测方法时,FocalNet在单尺度评估下的性能超过了Swin Transformer,并且在多尺度评估下也显示出优势。此外,当使用大型FocalNet和Mask2former进行ADE20K语义分割时,模型达到了58.5的mIoU分数,在COCO全景分割任务上达到了57.9的PQ分数。使用巨大的FocalNet和DINO作为基础,文章在COCO数据集上达到了64.3和64.4的mAP分数,为该任务树立了新的最先进水平。
文章还深入探讨了Focal Modulation与现有自注意力机制的不同之处,并展示了其优势。例如,自注意力机制首先进行查询-键交互以计算注意力分数,然后进行查询-值聚合以捕获来自其他令牌的上下文。相比之下,Focal Modulation首先在不同粒度级别对空间上下文进行编码,生成调制器,然后以查询依赖的方式将调制器适应性地注入查询令牌中。这种方法减轻了交互和聚合操作的计算负担,使得整个网络更加高效。
此外,文章还提供了模型的代码和预训练模型,以便研究社区可以进一步研究和应用FocalNets。作者通过可视化手段展示了FocalNets在不同层次上学习到的门控值和调制器值,证明了模型能够自适应地聚焦于图像中的目标区域,并且无需使用任何视觉解释工具即可实现这一点。
最后,文章讨论了FocalNets在不同视觉任务上的广泛应用,并展望了未来可能的研究方向,包括将Focal Modulation应用于其他领域任务以及多模态学习中。作者强调了在大规模网络参数化时代,FocalNets展现出的高效性和有效性,以及在不同规模的模型上取得的显著性能提升。
3、Scale-Aware Modulation Meet Transformer
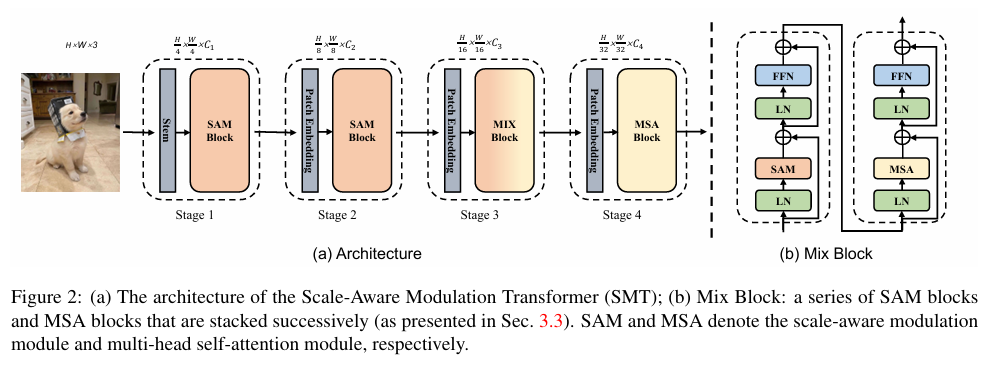
这篇文章介绍了一种新型的视觉Transformer架构——Scale-Aware Modulation Transformer(简称SMT),它通过结合卷积神经网络(CNN)和视觉Transformer的优势,有效处理各种下游任务。SMT的核心是Scale-Aware Modulation(SAM),它包含两个主要的创新设计:Multi-Head Mixed Convolution(MHMC)模块,用于捕获多尺度特征并扩大感受野;以及Scale-Aware Aggregation(SAA)模块,这是一个轻量级但有效的模块,能够跨头融合信息。这两个模块的结合,进一步提升了卷积调制的能力。
文章提出了一种新的混合网络架构——Evolutionary Hybrid Network(EHN),与以往在所有阶段使用调制构建无注意力网络的方法不同,EHN能够模拟网络深度增加时从捕获局部到全局依赖性的转变,从而实现更优越的性能。通过大量实验,作者证明了SMT在多种视觉任务上的显著性能,特别是在ImageNet-1K数据集上的分类任务,以及在COCO数据集上的目标检测和ADE20K数据集上的语义分割任务中,SMT都取得了优于现有最先进模型的结果。
文章还详细讨论了与现有工作的关系,包括对Vision Transformers和CNN的改进,以及混合CNN-Transformer网络的发展。此外,作者还提出了SMT的详细架构,包括其不同阶段的配置和模块设计。在实验部分,作者展示了SMT在不同配置下的性能,包括在ImageNet-1K、ImageNet-22K、COCO和ADE20K数据集上的结果。此外,作者还进行了消融研究,以评估SMT中不同组件的影响,并探讨了不同聚合策略和混合堆叠策略的有效性。
文章的结论强调了SMT作为一种新的通用视觉模型骨架的潜力,它在各种视觉问题上的出色性能可能会鼓励其作为高效视觉建模的新选择。作者还感谢了支持这项研究的资金来源和合作项目。
总体而言,这篇文章提出了一种结合了CNN和Transformer优势的新型视觉模型,通过创新的SAM和EHN设计,实现了在多个视觉任务上的性能提升,展示了其作为一种有前景的通用视觉模型骨架的潜力。




















