文章链接:https://arxiv.org/pdf/2408.02657
git链接:https://github.com/Alpha-VLLM/Lumina-mGPT
亮点直击
通过多模态生成预训练的自回归Transformer,而不是从头训练,可以作为逼真的文本到图像生成和视觉与语言任务统一的有效初始化。
基于mGPTs,引入了两种新的微调策略,FP-SFT和Omni-SFT,以在从弱到强的范式中充分释放它们的潜力,仅使用1000万高质量的文本-图像数据。
结果模型Lumina-mGPT不仅在任何分辨率下展示了令人印象深刻的逼真文本到图像生成,弥合了自回归和扩散基础方法之间的差距,还通过语言接口无缝支持各种下游任务。
本文介绍了Lumina-mGPT,一个多模态自回归模型家族,能够执行各种视觉和语言任务,特别是在从文本描述生成灵活的逼真图像方面表现优异。与现有的自回归图像生成方法不同,Lumina-mGPT采用了预训练的decoder-only Transformer作为建模多模态token序列的统一框架。注意见解是,通过使用大规模交织的文本-图像序列进行下一token预测目标的多模态生成预训练(mGPT),简单的decoder-only Transformer能够学习广泛且通用的多模态能力,从而实现逼真的文本到图像生成。基于这些预训练模型,提出了高质量图像-文本对的灵活渐进监督微调(FP-SFT),以充分释放它们在任何分辨率下进行高美学图像合成的潜力,同时保持其通用多模态能力。
此外,引入了全能监督微调(Omni-SFT),将Lumina-mGPT转化为一个基础模型,能够无缝实现全能任务统一。结果显示,该模型具备多种多模态能力,包括视觉生成任务(如灵活的文本到图像生成和可控生成)、视觉识别任务(如分割和深度估计)以及视觉语言任务(如多轮视觉问答)。此外,本文还分析了扩散基础方法和自回归方法之间的差异和相似之处。
方法
Lumina-mGPT 是一个仅包含解码器的Transformer ,采用多模态生成预训练(mGPT)进行初始化,并在来自各种任务的高质量多模态token 上进行微调。基于强大的 mGPT 表示和本文提出的带有明确图像表示的监督微调策略,Lumina-mGPT 在逼真图像生成和全能任务统一方面表现出色,具有高灵活性,能够处理不同的图像分辨率和长宽比。
重新审视带Chameleon的mGPT
mGPT 代表了一类利用仅包含解码器的Transformer 架构的模型,这些模型在广泛的多模态token 序列上进行了预训练。这些模型展现了出色的原生多模态理解、生成和推理能力,提供了在各种模态和任务中进行通用建模的潜力。本文使用最近的开源模型 Chameleon作为例子,来说明 mGPT 的设计选择和实现细节。
多模态分词(Tokenization)
为了将文本和图像统一成多模态token序列,首先需要将文本和图像分别token化为离散空间。特别是对于图像,选择合适的分词器至关重要,因为它决定了生成质量的上限。具体来说,Chameleon 为文本训练了一种新的字节对编码token。对于图像,采用了基于量化的token化方法,参考了之前的工作,将连续的图像补丁转换为来自固定词汇表的离散token ,同时减少空间维度。量化后的图像token被展平成一维序列,并以各种方式与文本token连接,以形成用于统一建模的多模态token序列。
仅解码器Transformer
与使用预训练编码器的 Unified-IO 和 Parti 的编码器-解码器架构不同,mGPT 从头开始训练一个仅包含解码器的自回归Transformer,在将文本和图像输入转换为离散token的统一序列 后,这种方法提供了更简单、更统一的多模态生成建模方法。mGPT 采用了标准的密集Transformer 架构,以便于扩展和泛化,进行了如 RoPE(和 SwiGLU激活函数等小的调整,参考了 LLaMA 系列)。
然而,当模型规模和多模态token序列的上下文长度增加时,这种标准的Transformer 架构会表现出训练不稳定性,这在 Chameleon和 Lumina-Next中都有观察到。研究发现,这种不稳定性是由于Transformer块中的网络激活无法控制地增长所造成的。因此,为了保持中间激活的幅度并进一步稳定训练过程,添加了 Pre-Norm、Post-Norm 和 QK-Norm 到每个Transformer 块中。
训练目标
在训练过程中,mGPT 通过标准的下一个token 预测目标建模多模态序列的条件概率。此外,Chameleon 应用了 z-loss来稳定 7B 和 30B 模型的训练。最初,低估了 z-loss 的重要性,因为在与(多模态)LLM 训练相关的大多数工作中,它是缺失的。然而,发现没有这项时,logits 的幅度会激增,导致损失发散。另一方面,使用 z-loss 时,观察到对于 7B 和 30B 模型,推理时图像生成的最佳温度远低于 1B 模型,因为在更大的模型中 logits 的幅度显著降低。
Chameleon 的局限性
尽管像 Chameleon 这样的 mGPT 模型在单个仅解码器的Transformer 中展示了图像和文本的联合理解潜力,但其图像生成能力在质量和分辨率灵活性方面仍不及最先进的扩散基础框架。此外,值得注意的是,Chameleon 的开源版本中甚至缺乏图像生成能力。此外,Chameleon 的能力仅限于视觉-语言和仅文本任务,未涵盖更广泛的视觉中心任务。这些任务包括经典的视觉识别任务(如分割和深度预测)以及创意视觉生成任务(如可控生成和图像编辑)。Lumina-mGPT 基于 Chameleon 构建,旨在释放其在灵活逼真图像生成方面的全部潜力,成为一个多功能的视觉通用模型。
Lumina-mGPT
基于预训练的多模态生成预训练(mGPT)表示,Lumina-mGPT 实现了灵活的逼真图像生成以及视觉和语言任务的统一。为了充分释放 mGPT 的潜力,提出了明确图像表示(Uni-Rep)、灵活渐进监督微调(FP-SFT)和全能监督微调(Omni-SFT)。Uni-Rep 消除了原始 2D 形状的扁平化 1D 图像token 中的模糊性,为灵活分辨率和长宽比下的图像理解和生成奠定了基础。FP-SFT 以从简单到困难的方式逐步微调 mGPT 以生成更高分辨率的离散图像token ,同时融入多任务微调,以防止文本知识的灾难性遗忘。在 FP-SFT 过程之后,Lumina-mGPT 能够以灵活的分辨率生成逼真的图像。在 FP-SFT 阶段的图像生成能力的基础上,继续在全能任务数据集上微调 Lumina-mGPT,通过将图像和注释从密集标注、空间条件图像生成和多轮编辑数据集中token 化为离散token 。所有微调阶段均采用下一个token 预测目标来共同建模多模态token ,并集成 z-loss,与预训练阶段类似。
有效初始化
大规模预训练和可扩展模型架构已被广泛验证为通向先进智能的黄金路径。由于 mGPT(如 Chameleon)在大规模图像-文本交织数据集上进行预训练,并为图像和文本开发了有效且可泛化的表示,它们可以更好地作为灵活逼真图像生成及其他任务的起始点,而不是随机初始化或仅语言模型。此外,LLaMA架构,结合了查询-键归一化和旋转位置编码等特性,通过广泛的验证展示了其强大和可扩展性。通过从遵循 LLaMA 架构的 Chameleon mGPT 初始化,可以利用这些架构优势。因此,从 mGPTs 开始初始化能够高效地训练出性能优异的 Lumina-mGPT 模型,其参数范围从 7B 到 30B,仅使用 1000 万高质量图像-文本数据点。
预训练仅解码器的多模态生成预训练(mGPT)模型在各种应用中已被广泛探索和应用。与这些现有方法不同,Lumina-mGPT 的主要贡献在于展示了从合适的 mGPT 表示开始的好处,而不是使用大型语言模型(LLMs)或随机初始化,特别是在文本到图像生成方面。相信这一发现可以启发未来在图像生成和视觉通用模型方面的进展。
Lumina-mGPT 的监督微调
明确图像表示(Unambiguous Image Representation)
现有方法,如 Chameleon和 LlamaGen,将图像表示为 2D 离散图像编码的 1D 扁平序列。虽然这种方法适用于固定图像分辨率,但在图像分辨率可变的情况下(如 Lumina-mGPT 支持的情况),它变得模糊。例如,分辨率为 512×512、256×1024 和 1024×256 的图像都可以编码成相同数量的token ,这使得在不检查token 内容的情况下很难推断原始形状。这种模糊性对图像感知和生成提出了重大挑战。
为了解决这个问题,本文提出了明确图像表示(Uni-Rep),它通过在 <start-of-image> token 之后添加额外的高度/宽度指示token ,并在属于同一行的图像token 之后插入 <end-of-line> token ,来增强图像表示。如下图 2 所示,这种修改确保可以准确解析出图像的原始形状,而无需额外的上下文或深入研究图像token 的内容。这一改进为 Lumina-mGPT 在任何分辨率和长宽比下执行图像相关任务奠定了基础。

需要注意的是,虽然高度/宽度指示器或 <end-of-line> token 中的任意一个都可以单独实现消歧义,但仍然同时使用这两者,因为它们各有不同的优点。在生成图像时,高度/宽度指示器在任何图像token之前生成,可以预先确定图像的形状,帮助 Lumina-mGPT 组成图像内容。另一方面,<end-of-line> token 可以作为anchors,为 1D token 序列提供额外的显式空间信息。
灵活渐进监督微调(FP-SFT)
FP-SFT 过程使预训练的 mGPT 能够以渐进的方式生成具有灵活长宽比的高分辨率图像。该过程分为三个阶段,每个阶段的宽度和高度的乘积分别为 512²、768² 和 1024²。在每个阶段,准备了一组具有相似面积但不同高宽比的候选分辨率,每张图像都匹配到最合适的分辨率。在低分辨率阶段,较短的序列长度和较高的训练吞吐量使得模型能够快速遍历大量数据,学习图像的整体构图和广泛的视觉概念。相反,在高分辨率阶段,模型预计将专注于学习高分辨率图像特有的高频细节。受益于在高吞吐量预训练和低分辨率微调阶段建立的强大基础,低吞吐量高分辨率微调阶段的数据效率高,从而提高了 FP-SFT 过程的整体效率。
FP-SFT 使用精心策划的高分辨率逼真图像-文本对数据集。此外,还在训练过程中融合了来自 OpenHermess(Teknium,2023)的纯文本数据和来自 Mini-Gemini(Li 等,2024a)的图像到文本数据,以防止灾难性遗忘。为了提供用户自然指定生成图像所需分辨率的方式,开发了分辨率感知提示(如上面图 2 所示)。对于每张图像及其相应的描述,提示的结构如下:
根据以下提示生成一张 {width}x{height} 的图像:
{description}
全能监督微调(Omni-SFT)
虽然灵活的逼真图像生成是 Lumina-mGPT 的主要目标,但发现经过 FP-SFT 后的模型可以有效地转移到广泛的图像理解和生成任务中。因此,提出了 Omni-SFT,这是一个初步探索,旨在提升 Lumina-mGPT 成为视觉通用模型。Omni-SFT 的训练数据包括以下内容:
-
单回合和多回合语言引导的图像编辑:来自 MagicBrush和 SEED的数据(仅涉及现实世界和多回合子集)。
-
密集预测任务:包括来自 NYUv2和 ScanNet的表面法线估计,来自 Kitti v2和 Sintel的深度估计,来自 MSCOCO的姿态估计,使用 OneFormer标注的语义分割数据),以及来自 RefCOCO的基础数据。
-
内部空间条件图像生成数据:条件包括表面法线、深度、姿态和分割。
-
从 FP-SFT 过程中使用的数据的小部分样本。
经过 Omni-SFT 后,Lumina-mGPT 展现了完成广泛任务的通用能力,除了文本到图像生成,表明在这一方向上构建多模态通用模型的潜力。
训练设置
尽管 SFT 过程涉及多个任务,但对所有任务使用统一的下一个token 预测损失。由于 Lumina-mGPT 被设计为聊天模型,所有数据都被组织为单回合或多回合对话,损失仅应用于响应部分。所有实验中,使用 AdamW优化器,权重衰减为 0.1,beta 参数为 (0.9, 0.95),学习率设置为。为了稳定训练,对 7B 和 30B 模型都应用了权重为 的 z-loss,并且对 7B 模型额外应用了 0.05 的 dropout。为了适应大型模型体积,使用了 PyTorch FSDP和梯度检查点。为了提高训练吞吐量,所有数据在训练前都经过了预token 化,并根据token 数量进行了聚类,确保每个全局批次由具有相似长度的数据组成。
Lumina-mGPT 的推理
无分类器引导
无分类器引导(Classifier-Free Guidance, CFG)最初是为了增强文本到图像扩散模型生成样本的质量和文本对齐度。在推理过程中将这一技术引入了自回归模型。当生成图像token 时,CFG 处理后的 logits 被公式化为 ,其中 代表基于完整上下文的原始 logits; 代表仅基于当前生成图像的 <start-of-image> token 之后的token 的上下文独立 logits,不依赖于任何先前的上下文;表示无分类器引导的指导尺度。为了使 CFG 起作用,在训练期间,<start-of-image> 之前的上下文会以 10% 的概率被随机丢弃。在实践中,可以使用 KV 缓存加速 和 的计算。CFG 对 Lumina-mGPT 的生成性能有显著影响。
图像和文本的不同解码超参数
在推理过程中,自回归模型的采样策略涉及众多超参数,这些参数会显著影响采样结果。发现,文本解码和离散图像码解码的最佳解码超参数差异很大。例如,top-k=5 设置在生成文本时表现良好。然而,在生成图像时,top-k 的值应更大(例如 2000),以避免重复和无意义的模式。因此,实施了一种状态感知控制机制用于推理。具体来说,文本解码使用一组默认超参数;一旦生成了 <start-of-image> token ,超参数会切换到那些针对图像生成优化的设置。生成<end-of-image> token 后,参数会恢复到初始设置。
实验
基础的逼真文本到图像生成
首先展示了 Lumina-mGPT 在 FP-SFT 处理下的基础文本到图像生成能力。如下图 1 所示,Lumina-mGPT 能够在各种分辨率下生成逼真的图像,首次实现了无需模型级联的原生 1K 自回归生成,这是文本到图像生成中的常见技术。这些生成的图像展现出强大的语义一致性和复杂的视觉细节,尽管只在有限的计算资源和文本-图像对上进行了微调。

与最先进的自回归方法的比较 将 Lumina-mGPT 的文本到图像合成能力与 LlamaGen和 Parti进行了比较。LlamaGen 在 ImageNet FID 分数上超越了最先进的扩散模型。与 LlamaGen 相比,Lumina-mGPT 在文本到图像生成中能够实现更好的视觉质量,如下图 3 所示。需要注意的是,Lumina-mGPT 仅需要 1000 万张图像-文本对,而 LlamaGen 训练了 5000 万张低质量的图像-文本对,并附带了 1000 万张内部美学图像-文本对。与拥有 200 亿参数的 AR 文本到图像模型 Parti 相比,Lumina-mGPT 也展示了更好的视觉质量和美学。然而,由于计算成本和训练数据集的显著差异,Lumina-mGPT 在文本指令跟随能力上逊色于 Parti。此外,LlamaGen 和 Parti 都不支持像 Lumina-mGPT 那样支持任意长宽比的 1K 分辨率图像的端到端生成。LlamaGen 仅支持固定分辨率的 512 × 512,而 Parti 则使用额外的超分辨率上采样器生成 1024 × 1024 的图像。

FP-SFT 的有效性
为了进一步验证 FP-SFT 的有效性,在下图 4 中可视化了不同微调阶段生成的图像。随着图像分辨率的增加,观察到 VQ-VAE 引入的视觉伪影逐渐减少,并且出现了多样的细粒度视觉细节。从这些插图中,可以得出结论,FP-SFT 能够逐步释放 mGPT 生成高质量图像的潜力。

全能任务统一与 Lumina-mGPT
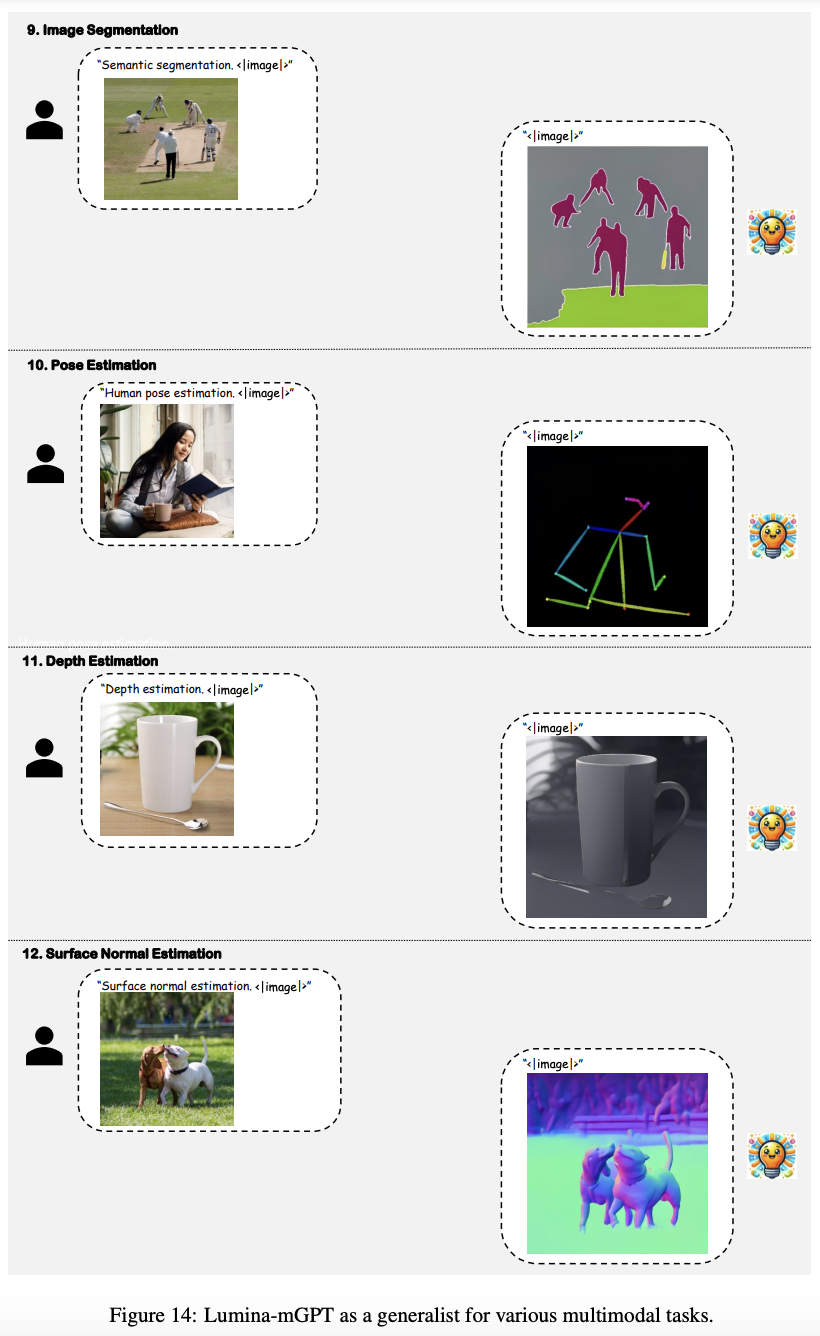
通过在 FP-SFT 之后执行 Omni-SFT,Lumina-mGPT 能够执行多种任务,这些任务可以分为文本-only 的多轮对话、视觉多轮对话、多轮图像编辑、密集标注和空间条件图像合成。为了直观地展示这些能力,在下图 12 至 16 中可视化了如何将各种下游任务无缝地集成到 Lumina-mGPT 中。




首先,得益于 Chameleon 的广泛预训练和本文的多任务微调以减轻灾难性遗忘,Lumina-mGPT 支持 LLMs 中的常见text-only 任务,如解决数学问题、编程和常识推理。例如,如图 12 所示,Lumina-mGPT 能够正确回答“哪个更大?9.9 还是 9.11”,这是几乎所有现有 LLM,包括 GPT-4和 Gemini,都感到困惑的问题。
如上面图 13 所示,Lumina-mGPT 还能够处理各种视觉-语言任务,包括图像描述、视觉问答和一般的多轮多图像对话。作为一个视觉通才,纳入经典视觉识别任务也很重要。使用自然语言作为统一接口,Lumina-mGPT 可以执行多种计算机视觉任务,包括图像分割、姿势估计、深度估计、表面法线估计和引用对象检测。有关示例,请见上面图 14 和 15。
除了逼真的图像生成之外,增加对文本到图像生成模型的额外控制也是至关重要的。如上图 15 和 16 所示,Lumina-mGPT 支持多种空间控制,包括深度图、分割图、法线图和人体姿势,以指导目标图像的生成。尽管上述示例仍处于初步阶段,但它们展示了 Lumina-mGPT 可以有效地遵循各种指令,显示了其作为一个框架统一多个具有挑战性的任务的良好潜力。
与扩散方法的比较
长期以来,与自回归模型相比,扩散模型在文本到图像生成领域一直占据主导地位。尽管 LlamaGen 宣称超越了扩散模型,但其结果仅限于 ImageNet 基准测试,目前尚无这两种架构之间的直接比较。本节旨在提供一个关于自回归方法和扩散方法的详细比较,这些方法是在相同的文本-图像数据集上训练的,重点关注图像质量、多样性、文本呈现和多语言能力。具体而言,将 Lumina-mGPT 和 Lumina-Next-SFT作为自回归和扩散方法的代表。对 Lumina-Next-SFT 和 Lumina-mGPT 的直接视觉比较揭示了自回归和扩散生成建模方法之间的相似性和差异。
关于扩散模型与自回归模型生成的相似性
在相同的文本提示下,扩散模型和自回归(AR)模型都能生成具有相似审美风格和精细细节的逼真图像,如下图 5 所示。这表明,在相同的训练数据、训练预算和可比模型规模的情况下,这两种架构都可以实现令人满意的文本到图像生成性能。自回归模型在视觉美学方面表现出色,与其扩散模型对手相媲美,挑战了扩散模型在生成建模中更有效和更有前景的架构的观点。这一发现也与“理想表现假设”相一致,即神经网络虽然训练架构和目标不同,但逐渐学会了共享的表示空间。因此,这一假设强调了收集更多高质量数据和优化训练基础设施作为数据和模型扩展方向的重要性,以提升总体模型性能,而不依赖于特定的架构。

扩散模型与自回归模型生成的差异
尽管存在视觉上的相似性,但扩散模型和自回归模型之间也存在显著差异。如上面图 5 所示,Lumina-mGPT 使用不同的随机种子展现了更多的多样性,而 Lumina-Next-SFT 则生成了具有相似布局和纹理的图像。这在一定程度上可以归因于 Lumina-mGPT 使用了较高的温度和 top-k 值。然而,过度的多样性也使得本文的模型在稳定性方面较差,更容易产生视觉伪影。
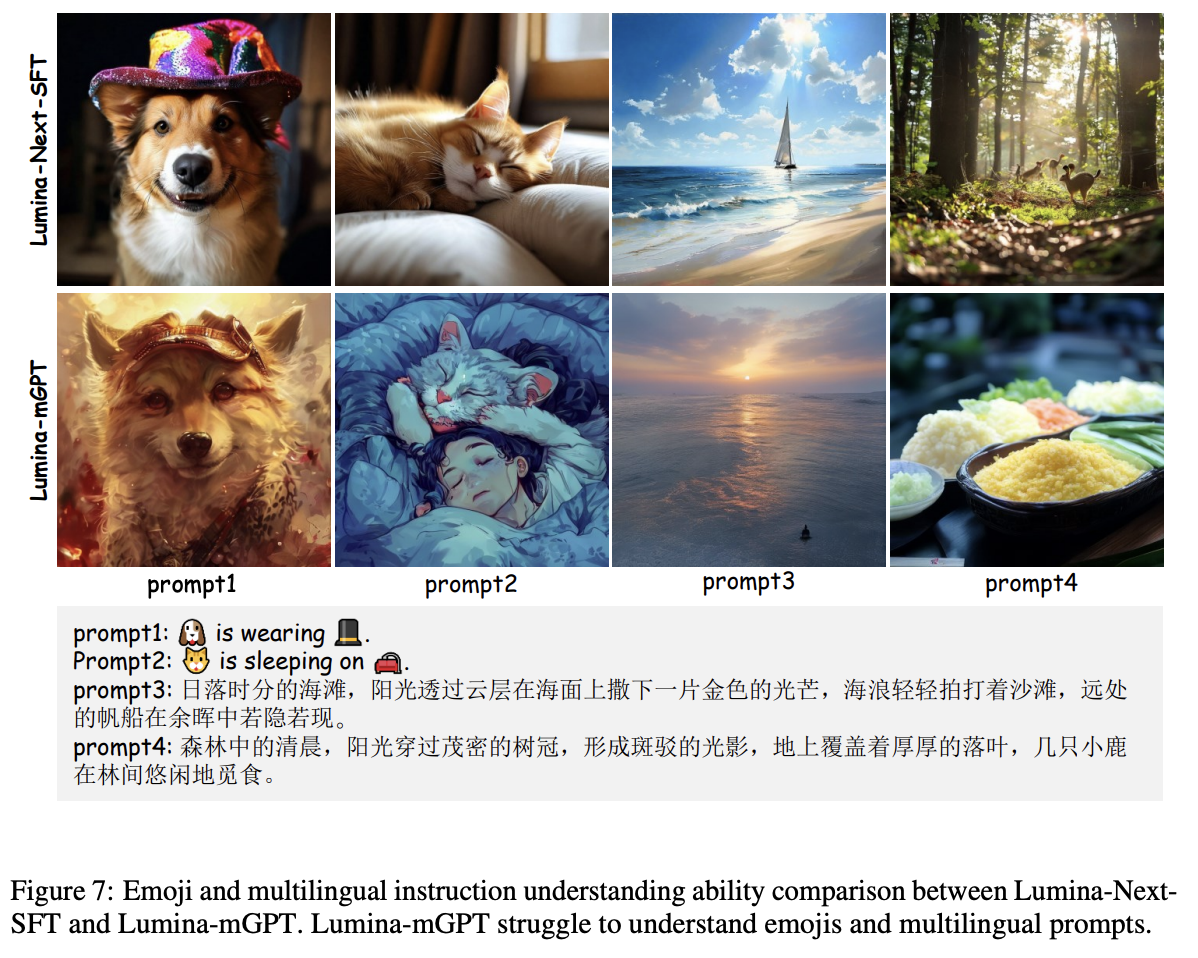
还比较了 Lumina-mGPT 和 Lumina-Next-SFT 在文本渲染和多语言理解方面的能力。如下图 6 所示,Lumina-mGPT 在文本合成结果方面表现显著优于 Lumina-Next-SFT,而后者在生成完整字符时表现不佳。

这突显了 mGPT 的重要性,因为该模型在预训练阶段通过大量交织的数据学习了文本和图像之间的无缝多模态表示。然而,在多语言理解方面,Lumina-mGPT 在表情符号和中文提示方面的表现不如 Lumina-Next-SFT,如下图 7 所示。原因在于,尽管 Lumina-mGPT 学习了更好的文本-图像对齐,但由于预训练时缺乏多语言文本语料,这限制了其表现。相比之下,Lumina-Next-SFT 使用的文本编码器在多语言能力上显著强于 Chameleon。因此,希望通过全面提升基础 mGPT 模型的能力,例如增加更多的多语言数据,Lumina-mGPT 能在所有下游任务中受益。
除了文本到图像生成外,Lumina-mGPT 还支持统一框架内的各种视觉和语言任务。然而,扩散模型的设计限制了它们在多个模态和任务中的兼容性和性能。扩散模型通常需要特定的架构设计和额外的训练来处理每个未见过的任务。相比之下,Lumina-mGPT 将所有模态的输入视为多模态token序列,并利用自然语言作为接口,通过下一个token预测来统一各种任务。
解码配置的影响
在自回归模型中,Lumina-mGPT 解码阶段的各种配置参数显著影响样本质量。在视觉领域,这些超参数(如温度 T、top-k 和分类器自由指导(CFG))尚未得到广泛研究。本节探讨了这些超参数如何影响生成图像的质量、纹理和风格。
温度的影响
为了评估这些解码参数的效果,我先设置一个标准解码配置:T=1.0,Top-k=2000,CFG=4.0,这是一种良好的使用设置。从这一baseline开始,逐渐将温度 T 从 0.7 调整到 1.0,以生成不同温度下的图像。结果如下图 8 所示。当温度设置较低时,视觉细节减少,物体趋向过度平滑。相反,当温度设置较高时,生成的图像包含丰富的视觉内容,但更容易出现更多的伪影。
Top-k 的影响
基于标准解码设置,将 top-k 值从 50 变化到 8192,其中 8192 等于 Lumina-mGPT 使用的 VQ-VAE 代码本的大小。结果如下图 8 所示,随着温度的增加,趋势相似。当 top-k 较低时,图像内容和纹理相对简单,也表现出过度平滑的问题。当 top-k 设置较高时,图像的细节和纹理更加多样,使其更具审美吸引力,但同时也增加了伪影的可能性。

分类器自由指导(CFG)的影响 在文本到图像的扩散模型中,CFG 具有极其重要的作用。为了验证其在自回归生成中的有效性,将 CFG 值从 1.0 更改为 8.0。如上图 8 所示,随着 CFG 值的增加,生成图像的质量得到改善,证明了分类器自由指导在此背景下的有效性。
Lumina-mGPT 作为 VQ 码的细化器
众所周知,VQ-VAE(和 VAE通过将图像压缩成潜在表示来实现图像压缩,但这会带来信息损失,特别是对于高频细节如边缘、头发和文字。这种不可避免的损失限制了所有潜在空间生成模型的图像生成质量。
然而,惊讶地发现,通过简单的“无编辑”指令,Lumina-mGPT 可以改进由 VQ-VAE 编码的离散图像token。Lumina-mGPT 可以生成一系列经过细化的图像token,这些token可以解码成更好的图像。
比较了 Chameleon 中使用的 VQ-VAE、使用 Lumina-mGPT 细化的 Chameleon 的 VQ-VAE 以及 SDXL VAE的重建质量,如下图 9 所示。SDXL VAE 在重建性能方面显著优于 Chameleon 的 VQ-VAE。这也解释了为什么基于扩散的方法在文本到图像生成中能够超越自回归模型。然而,在使用 Lumina-mGPT 细化 VQ 码之后,重建图像的质量在细节和文本渲染方面都有了显著提高,与 SDXL VAE 不相上下。

假设,Lumina-mGPT 在大规模训练和高质量的 FP-SFT 过程中学习了真实图像token的潜在分布。Omni-SFT 进一步触发了这种ze ro-shot 能力,在多种任务和指令的训练后出现。这种zero-shot能力可以弥补 VQ-VAE 中编码器和解码器之间的表示差距,提示了改进当前两阶段潜在生成建模范式的有前景方向。例如,可以利用 Lumina-mGPT 作为教师来细化 VQ 码,用于学生训练,或在推理时通过类似于分类器自由指导的方式操作token logits 来设计推理时间技术。
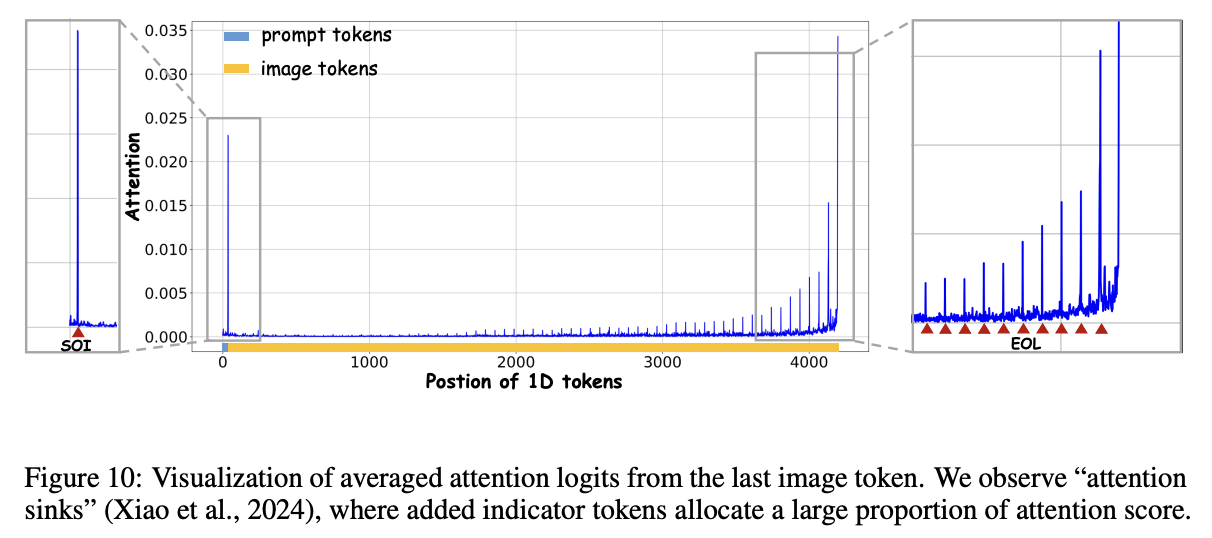
注意力可视化
为了更好地理解 Lumina-mGPT 的采样行为,可视化了文本到图像生成过程中最后一个图像token的平均注意力 logits,如下图 10 所示。结果显示,注意力分数对于远处的token下降,表明模型相对于远离的token,更加关注局部token。这种行为与 RoPE 中设计的长期衰减特性相一致。此外,观察到类似于 LLM中所称的“注意力下沉”模式,即大量的注意力分数分配给少数几个token。详细分析后,这些下沉token被识别为指示符,包括 <start-of-image> 和 <end-of-line> token。值得注意的是,文本token的注意力分数显著小于 <start-of-image> token的分数。这表明,文本token中的大部分语义信息可能已经被封装到 <start-of-image> token中。这些有趣的发现表明,Lumina-mGPT 从这些下沉token中聚合了更多信息,展示了 Uni-Rep 中这些指示符的有效性,并开辟了利用这些下沉token加速采样过程的潜力。
限制
失败案例
尽管 Lumina-mGPT 能生成逼真的图像,但有时它会产生明显的视觉伪影。例如,Lumina-mGPT 可能会生成四肢不合理的人物和动物,如下图 11 的第一行所示。此外,与包括 SD3、Kolors和 HunyuanDiT在内的现有最先进的文本到图像生成方法相比,Lumina-mGPT 的提示跟随能力较差,因为它的训练资源和数据规模远小于这些最先进的方法(这些方法的训练数据超过 10 亿对图像-文本对)。在密集token和可控生成方面,Lumina-mGPT 目前的结果较为初步,受限于有限的训练预算。因此,图 11 的第二行提供了 Lumina-mGPT 产生不准确预测或语义不一致图像的例子,无法理解给定的图像条件。因此,期望通过扩大数据规模和计算资源,Lumina-mGPT 能有效解决这些失败案例,如不足的指令跟随能力和视觉伪影问题。

生成速度
自回归模型在推理过程中需要大量的网络评估,这与扩散模型中的迭代去噪过程类似。当生成高分辨率图像时,这种情况更加严重,通常需要几分钟才能生成完整的图像token序列,显著慢于当前使用先进采样器的扩散模型。然而,已经有许多优化自回归模型推理速度的技术,如 vLLM(Kwon et al., 2023)和 FlashAttention。相信通过在未来整合这些方法,Lumina-mGPT 可以在推理过程中实现显著的加速。
VQ-VAE 重建质量
VQ-VAE 被用作图像tokenizer,将连续图像转换为离散的token表示。同时,它也通过压缩图像的空间维度引入了信息瓶颈。因此,VQ-VAE 的重建质量在很大程度上决定了生成质量的上限。发现Chameleon 中提出的 VQ-VAE 有时在重建高频细节时存在困难,尤其是在图像中包含文本和人脸时。引入 VQ-VAE 的进一步改进,如 FSQ,可能也会提升 Lumina-mGPT 的生成质量。
结论
Lumina-mGPT,这是一种仅有解码器的Transformer ,可以从文本提示中生成多样化、逼真的图像,支持任意分辨率的生成。不同于随机初始化,Lumina-mGPT 从一个多模态生成预训练(mGPT)的自回归Transformer 开始初始化。利用从大规模交错数据中学习到的通用多模态表示,设计了两种微调策略——FP-SFT 和 Omni-SFT,分别释放了 mGPT 在文本到图像生成和全能任务统一方面的潜力。展示了 Lumina-mGPT 在各种任务中的广泛多模态能力,并在与扩散模型的对比中强调了其高质量的文本到图像生成能力。
参考文献
[1] Lumina-mGPT: Illuminate Flexible Photorealistic Text-to-Image Generation with Multimodal Generative Pretraining
更多精彩内容,请关注公众号:AI生成未来

欢迎加群交流AIGC技术


















![[译] How things get done on the Go Team](https://img-blog.csdnimg.cn/img_convert/0d7023e7d624fee39f5751eb6512c0fb.png)