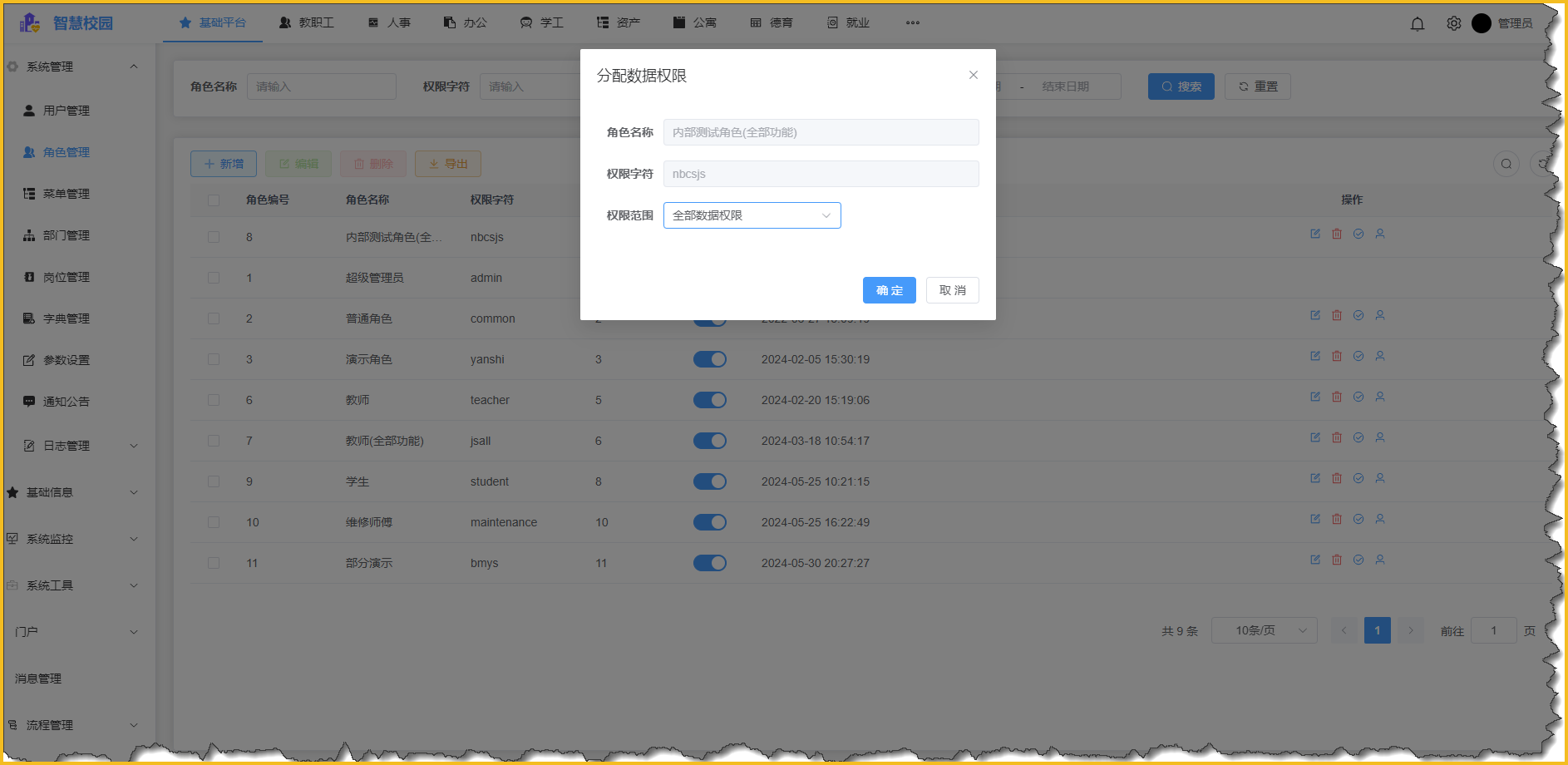
击败GPT4-Turbo,最强开源代码模型DeepSeek-Coder-V2问世|SiliconCloud上新
6月17日,深度求索正式开源了DeepSeek-Coder-V2模型。
根据相关评测榜单,这是全球首个在代码、数学能力上超越GPT-4-Turbo、Claude3-Opus、Gemini-1.5Pro等的开源代码大模型。DeepSeek-Coder-V2包含236B与16B两种参数规模,对编程语言的支持从86种扩展到338种。
一如既往,继DeepSeek V2之后,硅基流动团队第一时间在云服务平台SiliconCloud上线了DeepSeek-Coder-V2

去年11月,最强开源代码模型 DeepSeek-Coder 亮相,大力推动开源代码模型发展。
今年5月,最强开源 MoE 模型 DeepSeek-V2 发布,悄然引领模型结构创新潮流。
今天,全球首个在代码、数学能力上与GPT-4-Turbo争锋的模型,DeepSeek-Coder-V2,正式上线和开源。
全球顶尖的代码、数学能力
DeepSeek-Coder-V2 沿用 DeepSeek-V2 的模型结构,总参数 236B,激活 21B,在代码、数学的多个榜单上位居全球第二,介于最强闭源模型 GPT-4o 和 GPT-4-Turbo 之间。

国内第一梯队的通用能力
在拥有世界前列的代码、数学能力的同时,DeepSeek-Coder-V2 还具有良好的通用性能,在中英通用能力上位列国内第一梯队。

DeepSeek-Coder-V2 和
DeepSeek-V2 的差异
虽然 DeepSeek-Coder-V2 在评测中综合得分更高,但在实际应用中,两个模型各有所长。DeepSeek-V2 是文科生,DeepSeek-Coder-V2 是理科生,精通的技能点不同:

全面开源,两种规模
一如既往,DeepSeek-Coder-V2 模型、代码、论文均开源,免费商用,无需申请。
模型下载:
http://huggingface.co/deepseek-ai
代码仓库:
http://github.com/deepseek-ai/DeepSeek-Coder-V2
技术报告:
http://github.com/deepseek-ai/DeepSeek-Coder-V2/blob/main/paper.pdf
开源模型包含236B和16B两种参数规模
DeepSeek-Coder-V2:总参 236B(即官网和 API 版模型),单机 880G 可部署,单机 880G 可微调(需要技巧)
DeepSeek-Coder-V2-Lite:总参 16B,激活 2.4B,支持 FIM,代码能力接近 DeepSeek-Coder-33B(V1),单卡 40G 可部署,单机 8*80G 可训练。

API服务
DeepSeek-Coder-V2 API 支持 32K 上下文,价格和 DeepSeek-V2 一致,还是大家熟悉的低价:

本地私有化部署
DeepSeek 提供本地私有化部署服务,标准化成品交付,开箱即用,轻松升级。
价格 45 万/套/年,支持灵活的商务方案(登录官网,联系客服)。
价格包含:
一台推理训练一体化的高性能服务器(Nvidia H20、Huawei 910B 或其它同级别显卡,8 显卡互联)。
模型:DeepSeek-V2-236B、Coder-V2-236B、后续其它模型。
一站式软件套件:推理、微调、运维等。
对每个客户,DeepSeek 均会针对应用场景,使用公开数据、脱敏数据进行训练和调优。客户可以使用私有数据进一步微调。
不低于 5 人日/年的技术支持。
预期性能:
输 入: 20000 tokens/s
输出: 500 0~10000 tokens/s
官网已上线 DeepSeek-Coder-V2
访问对话官网: coder.deepseek.com ,与 DeepSeek-Coder-V2 永久免费畅聊。
访问开放平台: platform.deepseek.com ,使用最新 DeepSeek-Coder-V2 API。
DeepSeek 当下与未来
上月 DeepSeek-V2 发布后,深度求索以其卓越的性价比赢得赞誉。但我们的终极目标,始终是打造性能最强大的模型,Coder-V2 的推出,正是向这一愿景迈进的关键一步。我们相信,只有强大的模型能力、普惠的技术应用,才能开启人工智能发展的新篇章。
大模型·DeepSeek(2):DeepSeek-Code-V2
源码地址:https://github.com/deepseek-ai/DeepSeek-Coder-V2
一、总述
开源Mixture-of-Experts (MoE)模型:通过进一步预训练,达到了与闭源模型(如GPT4-Turbo)在代码特定任务上相当的性能。
从DeepSeek-V2的中间检查点开始,额外预训练了6万亿个token,增强了DeepSeek-V2在编码和数学推理方面的能力,同时保持了在通用语言任务上的性能。
支持多种编程语言:对编程语言的支持,从86种增加到338种,这大大扩展了模型的适用范围。
上下文长度从16K扩展到128K,使得模型能够处理更复杂和广泛的编码任务。
标准基准测试中的优越性能:在编码和数学基准测试中,DeepSeek-Coder-V2展示了比闭源模型更优越的性能。
数据集构建:数据集包括60%的源代码、10%的数学语料库和30%的自然语言语料库,这些数据集经过精心筛选和清洗。
模型架构:基于DeepSeek-Coder-V2
训练策略:
训练目标:Next-Token-Prediction和Fill-In-Middle (FIM)
使用Group Relative Policy Optimization (GRPO)算法进行强化学习,以优化模型在编码任务中的正确性和符合人类偏好的行为。
Figure 1:在Code+Math上,DeepSeek-Coder-V2 跟其他模型对比

Table 1:DeepSeek-Coder -> DeepSeek-Coder-v2

二、数据集
数据集 = 60%源代码 + 10%数学语料库 + 30%自然语言语料库

1、源代码:
来自 GitHub(23.11之前创建的repo) 和 CommonCrawl 的 1,170B 代码相关令牌组成,使用与 DeepSeekMath 相同的pipeline
对比 DeepSeek-Coder ,v2的语料库从 86 种编程语言扩展到 338 种编程语言,达到821B 代码和 185B 代码相关文本。
一些清洗策略:
过滤掉平均行长度超过100个字符或最大行长度超过1000个字符的文件。 删除字母字符少于 25% 的文件。 除XSLT编程语言外,我们进一步过滤掉前100个字符中出现字符串“<?xml version=”的文件。 对于 HTML 文件,考虑可见文本与 HTML 代码的比率。我们保留可见文本至少占代码 20% 且不少于 100 个字符的文件。 对于通常包含更多数据的 JSON 和 YAML 文件,仅保留字符数在 50 到 5000 个字符之间的文件。这可以有效地删除大多数数据密集型文件。
2、数学语料库
我们使用相同的pipeline收集来自 CommonCrawl 的 221B 个数学相关token,
是 120B DeepSeekMath 语料库大小的两倍
对于 Common Crawl 源,收集数学,遵循与 DeepSeekMath 相同的流程:
1、初始种子语料库:选择 StackOverflow 等编码论坛、PyTorch 文档等library网站、 StackExchange 等数学网站。 2、基于种子语料库,训练了一个 fastText 模型,来回忆更多与编码相关和数学相关的网页,使用 DeepSeek-V2 的字节对编码(BPE)分词器。 3、对于每个域,我们计算第一次迭代中收集的网页的百分比。收集的网页超过 10% 的域被分类为与代码相关或与数学相关。 4、我们注释与这些已识别域内的代码相关或数学相关内容相关的 URL。链接到这些 URL 的未收集网页将添加到种子语料库中。 经过 3 次数据收集迭代,我们从网页中收集了 700 亿个与代码相关的 token 和 221B 个与数学相关的 token。
上述同样的流程,用于从Github收集高质量的源代码:
我们在 GitHub 上应用相同的pipeline,进行两次数据收集迭代,收集了 94B 源代码。初始种子语料库是通过手动收集高质量源代码(例如包含详细描述的源代码)构建的。
3、自然语言语料库
直接从DeepSeek-V2 中的训练语料库。
DeepSeek-Coder-V2 总共暴露了 10.2T 训练 token,其中 4.2 万亿个 token 来自 DeepSeek V2 数据集,其余 6 万亿个 token 来自 DeepSeek-Coder-V2 数据集。
三、训练
3.1 训练目标:
DeepSeek-Coder-v2 236B,仅利用 Next-Token-Prediction DeepSeek-Coder-v2-16B,使用FIM(Fill-In-Middle),利用 PSM(前缀、后缀、中间)模式。 FIM按照前缀、后缀、中间的顺序构建内容重构,该结构作为预打包过程的一部分应用于文档级别,结构如下图:

3.2 上下文
将上下文长度从 16K 扩展到 128K 令牌,使我们的模型能够处理更复杂和广泛的编码任务。 在这个多源语料库上持续预训练 DeepSeek-V2 后,我们发现 DeepSeek-Coder-V2 显着增强了模型的编码和数学推理能力,同时保持了可比的一般语言性能。
3.3 对齐
1、构建一个指令训练数据集,包括 来自 DeepSeek-Coder (Guo et al., 2024) 和 DeepSeek-Math (Shao et al., 2024) 的代码和数学数据, 来自 DeepSeek-Coder (Guo et al., 2024) 的通用指令数据DeepSeek-V2(DeepSeek-AI,2024)。
2、RL时,采用组相对策略优化 GRPO(Group Relative Policy Optimization)算法来使其行为与人类偏好保持一致。 使用编译器反馈和测试用例在编码领域收集偏好数据,并开发奖励模型来指导策略模型的训练。这种方法确保模型的响应针对编码任务的正确性和人类偏好进行优化。为了使模型能够支持对齐后的代码补全,我们还在使用 16B 参数对基础模型进行微调时采用了 Fill-In-Middle 方法(Guo et al., 2024)。
四、Eval
4.1 对比模型
代码系模型如下:
Meta的LLaMA系:
CodeLlama:基于 Llama2 的代码语言模型组成,并在 500 至 10000 亿个代码token的数据集上继续进行预训练。这些型号有四种尺寸:7B、13B、34B 和 70B。
BigCode出品,BigCode(BigCode社区是由ServiceNow和HuggingFace共同管理)
StarCoder:一个可公开访问的模型,拥有 150 亿个参数。它经过精心策划的 Stack 数据集子集(Kocetkov 等人,2022)的专门训练,涵盖 86 种编程语言。
StarCoder2:由 3B、7B 和 15B 参数模型组成,这些模型在 Stack2 数据集(Lozhkov 等人,2024)的 3.3 至 4.3 万亿个token上进行训练,涵盖 619 种编程语言。
本文所在团队出品:
DeepSeek-Coder:包含一系列代码语言模型,参数范围从 10 亿到 330 亿不等。每个模型都在 2 万亿个 token 上从头开始训练,其中 87% 是代码,13% 是英文和中文的自然语言。这些模型使用 16K 窗口大小和额外的填空任务在项目级代码语料库上进行预训练,从而支持项目级代码补全和填充。
Mistral出品:
Codestral:22B 参数模型。它接受了超过 80 种编程语言的多样化数据集的训练,包括 Python、Java 和 JavaScript 等流行语言,以及 Swift 和 Fortran 等更专业的语言。官博在这里:https://mistral.ai/news/codestral/
另,General NLP的对比模型,主要就是:Llama3 70B 、GPT-4 、Claude 3 Opus、Gemini 1.5 Pro
4.2 评测指标
4.2.1 代码
DeepSeek-Coder-V2 表现出优于所有开源模型的显着优势,且追评SOTA闭源模型(GPT4-Turbo、Claude 3 Opus 和 Gemini 1.5 Pro 等)。 具体分数如下:
在 HumanEval 上取得了 90.2% 的分数(Chen 等人,2021),
在 MBPP 上取得了 76.2% 的分数(Austin 等人,2021a)(通过 EvalPlus 评估流程建立了新的最先进结果) ,
LiveCodeBench 的得分为 43.4%(Jain 等人,2024 年)(2023 年 12 月至 2024 年 6 月的问题)
是第一个在 SWEBench 上得分超过 10% 的开源模型(Jimenez 等人,2023)。
4.2.2 数学
能追平 GPT-4o、Gemini 1.5 Pro 和 Claude 3 Opus 等顶级闭源模型,在:
基准测试:GSM8K
竞赛级基准:MATH (Hendrycks et al., 2021)、AIME (MAA, 2024) 和 Math Odyssey (Netmind.AI, 2024)
4.2.3 自然语言
相比于基座模型 DeepSeek-V2, DeepSeek-Coder-V2的通用语言能力,并未退化。
DeepSeek-Coder-V2 使用 OpenAI simple-eval pipeline 在 MMLU 上实现了 79.2%。 以 GPT-4 作为评判者的主观评价,DeepSeek-Coder-V2 : 在 arena-hard 上获得 65.0 (Li et al., 2024), 在 MT-bench (Zheng et al., 2023) 上获得 8.77, 在alignbench (Liu) 上获得 7.84等人,2023c)
给大家推荐一款AI地址:
https://cloud.siliconflow.cn/models/text/chat/17885302528
注意!!!从现在起,新用户送1亿token,注册即可畅玩:注册地址
https://cloud.siliconflow.cn?referrer=clzgre135000vclt2n58f1lho