note
- pandas udf和python udf区别:前者向量化是在不同partition上处理
- @pandas_udf使用panda API来处理分布式数据集,而
toPandas()将分布式数据集转换为本地数据,然后使用pandas进行处理,如果Pyspark的dataframe非常大,直接使用toPandas()很容易导致OOM。
文章目录
- note
- 一、Pyspark中的udf
- 1.1 udf的简单介绍
- 1.2 udf的写法
- 1.3 udf的使用场景
- 二、pandas_udf三大用法
- (1)Scalar向量化标量操作
- (2)Grouped Map
- (3)Grouped Aggregate
- 三、案例介绍
- 3.1 进行基础的数据计算
- 3.2 高级用法:处理复杂类型数据列
- Reference
一、Pyspark中的udf
1.1 udf的简单介绍
- 在java分布式系统中执行python程序是挺耗性能的(如下图Pyspark多进程框架,数据在JVM和Python中进行传输,有额外的序列化和调用开销),apache arrow项目由此发起,以加速大数据分析项目运行速度。
- apache arrow是一种内存中的列式数据格式,用于spark中JVM和python进程之间的数据高效传输。在调用Arrow之前,需要将spark配置选项设置为true:
spark.conf.set("spark.sql.execution.arrow.enabled", "true"),但在spark3.0后的版本中需要改为spark.sql.execution.arrow.pyspark.enabled。

- udf自定义函数,可让我们在使用pyspark进行业务分析时高效自定义功能,一般分为两种:
- event level:是对一条事件or数据进行计算
- aggregation function: 对某个aggregation key的自定义聚合计算。如对pyspark中df使用
collection_list或者collect_set把需要聚合的信息变成一个list后,通过event level的udf实现。- ex:计算用户多次登陆时间的最大值(如下代码)。
- 上面栗子的缺点:如果主键是热点,即聚合出的元素很多,容易OOM,可只对聚合出的list先进行裁剪,如按照时间排序,保留最后topk的事件。
@udf(SomeType())
def find_max(lis):
return max(lis)
SparkDataFrame.groupBy("userId"). \
agg(
find_max(fn.collect_list('log_duration'))
).show()
- 为什么 RDD filter() 方法那么慢呢?原因是 lambda 函数不能直接应用于驻留在 JVM 内存中的 DataFrame。
- 内部实际发生的是 Spark 在集群节点上的 Spark 执行程序旁边启动 Python 工作线程。在执行时,Spark 工作器将 lambda 函数发送给这些 Python 工作器。接下来,Spark worker 开始序列化他们的 RDD 分区,并通过套接字将它们通过管道传输到 Python worker,lambda 函数在每行上进行评估。对于结果行,整个序列化/反序列化过程在再次发生,以便实际的 filter() 可以应用于结果集。
- 因为数据来回复制过多,在分布式 Java 系统中执行 Python 函数在执行时间方面非常昂贵。这个底层的探索:只要避免Python UDF,PySpark 程序将大约与基于 Scala 的 Spark 程序一样快。如果无法避免 UDF,至少应该尝试使它们尽可能高效。
1.2 udf的写法
- 写代码创建函数
- 写一个单元测试
- 保证测试通过,并且计算结果与业务实际需求相符
- 将函数register到pyspark,注意必须声明函数返回值的数据类型(参考下表进行pyspark和python数据类型的对照)

1.3 udf的使用场景
在详细介绍对应的pandas_udf用法前先通过一张图看下在不同场合适合使用哪种udf:

上图源自《Data Analysis with Python and PySpark》。
具体而言:
(1)注册函数到spark:
from fractions import Fraction
from typing import Tuple, Optional
Frac = Tuple[int, int]
def py_reduce_fraction(frac: Frac) -> Optional[Frac]:
"""Reduce a fraction represented as a 2-tuple of integers."""
num, denom = frac
if denom:
answer = Fraction(num, denom)
return answer.numerator, answer.denominator
return None
assert py_reduce_fraction((3, 6)) == (1, 2)
assert py_reduce_fraction((1, 0)) is None
def py_fraction_to_float(frac: Frac) -> Optional[float]:
"""Transforms a fraction represented as a 2-tuple of integers into a float."""
num, denom = frac
if denom:
return num / denom
return None
assert py_fraction_to_float((2, 8)) == 0.25
assert py_fraction_to_float((10, 0)) is None
SparkFrac = T.ArrayType(T.LongType())
reduce_fraction = F.udf(py_reduce_fraction, SparkFrac)
frac_df = frac_df.withColumn(
"reduced_fraction", reduce_fraction(F.col("fraction"))
)
print("=====================udf test2:\n")
frac_df.show(5, False)
# +--------+----------------+
# |fraction|reduced_fraction|
# +--------+----------------+
# |[0, 1] |[0, 1] |
# |[0, 2] |[0, 1] |
# |[0, 3] |[0, 1] |
# |[0, 4] |[0, 1] |
# |[0, 5] |[0, 1] |
# +--------+----------------+
# only showing top 5 rows
(2)也可以使用decorator语法糖:
@F.udf(T.DoubleType())
def fraction_to_float(frac: Frac) -> Optional[float]:
"""Transforms a fraction represented as a 2-tuple of integers into a float."""
num, denom = frac
if denom:
return num / denom
return None
frac_df = frac_df.withColumn(
"fraction_float", fraction_to_float(F.col("reduced_fraction"))
)
print("================udf test 3:\n")
frac_df.select("reduced_fraction", "fraction_float").distinct().show(5, False)
# +----------------+-------------------+
# |reduced_fraction|fraction_float |
# +----------------+-------------------+
# |[3, 50] |0.06 |
# |[3, 67] |0.04477611940298507|
# |[7, 76] |0.09210526315789473|
# |[9, 23] |0.391304347826087 |
# |[9, 25] |0.36 |
# +----------------+-------------------+
# only showing top 5 rows
assert fraction_to_float.func((1, 2)) == 0.5
二、pandas_udf三大用法

第一个SCALAR和pandas中的transform类似,第二个GROUPED_MAP是最灵活的。
(1)Scalar向量化标量操作
- 可以与select和
withColumn等函数一起使用。python 函数应该以pandas.series作为输入,并返回一个长度相同的pandas.series。 - 在内部,spark 将通过将列拆分为batch,并将每个batch的函数作为数据的子集调用,然后将结果连接在一起,来执行 padas UDF。
- Pandas_UDF是在PySpark 2.3版本中新增的API,Spark经过Arrow传输数据,使用Pandas处理数据。
Pandas_UDF使用关键字pandas_udf做为装饰器或声明一个函数进行定义,Pandas_UDF包括Scalar(标量映射)和Grouped Map(分组映射)等类型。栗子:
from pyspark.sql.functions import pandas_udf,PandasUDFType
from pyspark.sql.types import IntegerType,StringType
slen=pandas_udf(lambda s:s.str.len(),IntegerType())
@pandas_udf(StringType())
def to_upper(s):
return s.str.upper()
@pandas_udf(IntegerType(),PandasUDFType.SCALAR)
def add_one(x):
return x+1
df = spark.createDataFrame([(1, "John Doe", 21)], ("id", "name", "age"))
df.select(slen("name").alias("slen(name)"), to_upper("name"), add_one("age")).show()
df.withColumn('slen(name)',slen("name")).show()
+----------+--------------+------------+
|slen(name)|to_upper(name)|add_one(age)|
+----------+--------------+------------+
| 8| JOHN DOE| 22|
+----------+--------------+------------+
(2)Grouped Map
Grouped Map和后面的Grouped Aggregate都适合pyspark的split-apply-combine计算模式:
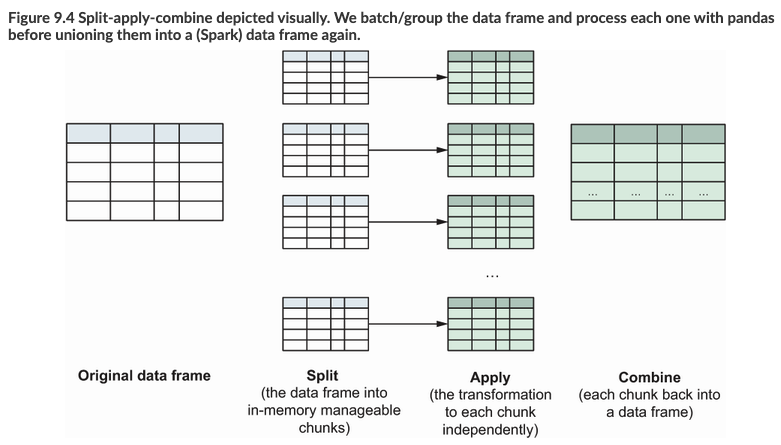
类似在pandas中pandas.groupby().apply,pyspark中使用pandas_udf可以加速大数据的处理逻辑。如下面的例子:
from pyspark.sql.functions import pandas_udf,PandasUDFType
df3 = spark.createDataFrame(
[("a", 1, 0), ("a", -1, 42), ("b", 3, -1), ("b", 10, -2)],
("key", "value1", "value2")
)
from pyspark.sql.types import *
schema = StructType([
StructField("key", StringType()),
StructField("avg_value1", DoubleType()),
StructField("avg_value2", DoubleType()),
StructField("sum_avg", DoubleType()),
StructField("sub_avg", DoubleType())
])
@pandas_udf(schema, functionType=PandasUDFType.GROUPED_MAP)
def g(df):
gr = df['key'].iloc[0]
x = df.value1.mean()
y = df.value2.mean()
w = df.value1.mean() + df.value2.mean()
z = df.value1.mean() - df.value2.mean()
return pd.DataFrame([[gr]+[x]+[y]+[w]+[z]])
df3.groupby("key").apply(g).show()
+---+----------+----------+-------+-------+
|key|avg_value1|avg_value2|sum_avg|sub_avg|
+---+----------+----------+-------+-------+
| a| 0.0| 21.0| 21.0| -21.0|
| b| 6.5| -1.5| 5.0| 8.0|
+---+----------+----------+-------+-------+
当然也不是一定要先对某个字段groupby操作,比如在直接导入torch训练好的模型参数(下面对最简单的linear线性模型举例),对一个很大的pyspark中dataframe进行使用pandas_udf预测:
from __future__ import print_function
from pyspark.sql import SparkSession
from pyspark import SparkConf, SparkContext
from pyspark.sql.functions import pandas_udf, PandasUDFType
import pyspark.sql.functions as F
from pyspark.sql.types import *
import pandas as pd
import torch
from torch import nn
class Linear(nn.Module):
def __init__(self, input_dim, output_dim):
super(Linear, self).__init__()
self.linear = nn.Linear(input_dim, output_dim)
def forward(self, x): # 前向传播
out = self.linear(x) # 输入x,输出out
return out
conf = SparkConf() \
.setAppName("dataframe") \
.set("spark.sql.execution.arrow.pyspark.enabled", "true")
spark = SparkSession.builder.config(conf=conf).getOrCreate()
@pandas_udf("uid long, aid long, score float", PandasUDFType.GROUPED_MAP)
def age_predict(df):
linear = Linear(2, 1)
linear.load_state_dict(torch.load('linear.pth'))
linear.eval()
df['score'] = linear(torch.from_numpy(df.values).type(torch.float32)).detach().numpy()
return df.loc[:, ['uid', 'aid', 'score']]
df = spark.read.format("json").load("hdfs:///tmp/predict.json").repartition(2)
#此处的F.spark_partition_id()即为我的文件分区数量
res = df.groupby(F.spark_partition_id()).apply(age_predict)
(3)Grouped Aggregate
Grouped aggregate Panda UDF类似于Spark聚合函数。Grouped aggregate Panda UDF常常与groupBy().agg()和pyspark.sql.window一起使用。它定义了来自一个或多个的聚合。级数到标量值,其中每个pandas.Series表示组或窗口中的一列。
【栗子】求每个id的平均值分数。
from pyspark.sql.functions import pandas_udf, PandasUDFType
df = spark.createDataFrame(
[(1, 1.0), (1, 2.0), (2, 3.0), (2, 5.0), (2, 10.0)],("id", "v"))
@pandas_udf("double", PandasUDFType.GROUPED_AGG)
def mean_udf(v):
return v.mean()
df.groupby("id").agg(mean_udf(df['v'])).show()
三、案例介绍
3.1 进行基础的数据计算
首先根据用户的活动结束时间和活动持续时间计算活动开始时间。然后
import pandas as pd
from pyspark.sql.types import *
from pyspark.sql import SparkSession
from pyspark.sql.functions import pandas_udf, PandasUDFType
spark = SparkSession.builder.appName("demo3").config("spark.some.config.option", "some-value").getOrCreate()
df3 = spark.createDataFrame(
[(18862669710, '/未知类型', 'IM传文件', 'QQ接收文件', 39.0, '2018-03-08 21:45:45', 178111558222, 1781115582),
(18862669710, '/未知类型', 'IM传文件', 'QQ接收文件', 39.0, '2018-03-08 21:45:45', 178111558222, 1781115582),
(18862228190, '/移动终端', '移动终端应用', '移动腾讯视频', 292.0, '2018-03-08 21:45:45', 178111558212, 1781115582),
(18862669710, '/未知类型', '访问网站', '搜索引擎', 52.0, '2018-03-08 21:45:46', 178111558222, 1781115582)],
('online_account', 'terminal_type', 'action_type', 'app', 'access_seconds', 'datetime', 'outid', 'class'))
def compute(x):
x['end_time'] = pd.to_datetime(x['datetime'], errors='coerce', format='%Y-%m-%d')
x['end_time_convert_seconds'] = pd.to_timedelta(x['end_time']).dt.total_seconds().astype(int)
x['start_time'] = pd.to_datetime(x['end_time_convert_seconds'] - x['access_seconds'], unit='s')
x = x.sort_values(by=['start_time'], ascending=True)
result = x[['online_account', 'terminal_type', 'action_type', 'app', 'access_seconds', 'datetime', 'outid', 'class','start_time', 'end_time']]
return result
schema = StructType([
StructField("online_account", LongType()),
StructField("terminal_type", StringType()),
StructField("action_type", StringType()),
StructField("app", StringType()),
StructField("access_seconds", DoubleType()),
StructField("datetime", StringType()),
StructField("outid", LongType()),
StructField("class", LongType()),
StructField("start_time", TimestampType()),
StructField("end_time", TimestampType()),
])
@pandas_udf(schema, functionType=PandasUDFType.GROUPED_MAP)
def g(df):
print('ok')
mid = df.groupby(['online_account']).apply(lambda x: compute(x))
result = pd.DataFrame(mid)
return result
df3.printSchema()
aa = df3.groupby(['online_account']).apply(g)
aa.show()
3.2 高级用法:处理复杂类型数据列
基于高效对大df进行处理,可以to_json函数将所有复杂数据类型的列转为JSON字符串(Arrow可以便捷处理字符串),然后使用pandas_udf。
import json
from functools import wraps
from pyspark.sql.functions import pandas_udf, PandasUDFType
import pandas as pd
class pandas_udf_ct(object):
"""Decorator for UDAFs with Spark >= 2.3 and complex types
Args:
returnType: the return type of the user-defined function. The value can be either a
pyspark.sql.types.DataType object or a DDL-formatted type string.
functionType: an enum value in pyspark.sql.functions.PandasUDFType. Default: SCALAR.
Returns:
Function with arguments `cols_in` and `cols_out` defining column names having complex
types that need to be transformed during input and output for GROUPED_MAP. In case of
SCALAR, we are dealing with a series and thus transformation is done if `cols_in` or
`cols_out` evaluates to `True`.
Calling this functions with these arguments returns the actual UDF.
"""
def __init__(self, returnType=None, functionType=None):
self.return_type = returnType
self.function_type = functionType
def __call__(self, func):
@wraps(func)
def converter(*, cols_in=None, cols_out=None):
if cols_in is None:
cols_in = list()
if cols_out is None:
cols_out = list()
@pandas_udf(self.return_type, self.function_type)
def udf_wrapper(values):
if isinstance(values, pd.DataFrame):
values = cols_from_json(values, cols_in)
elif isinstance(values, pd.Series) and cols_in:
values = values.apply(json.loads)
res = func(values)
if self.function_type == PandasUDFType.GROUPED_MAP:
if isinstance(res, pd.Series):
res = res.to_frame().T
res = cols_to_json(res, cols_out)
elif cols_out and self.function_type == PandasUDFType.SCALAR:
res = res.apply(ct_val_to_json)
elif (isinstance(res, (dict, list)) and
self.function_type == PandasUDFType.GROUPED_AGG):
res = ct_val_to_json(res)
return res
return udf_wrapper
return converter
from pyspark.sql.types import MapType, StructType, ArrayType, StructField
from pyspark.sql.functions import to_json, from_json
def is_complex_dtype(dtype):
"""Check if dtype is a complex type
Args:
dtype: Spark Datatype
Returns:
Bool: if dtype is complex
"""
return isinstance(dtype, (MapType, StructType, ArrayType))
def complex_dtypes_to_json(df):
"""Converts all columns with complex dtypes to JSON
Args:
df: Spark dataframe
Returns:
tuple: Spark dataframe and dictionary of converted columns and their data types
"""
conv_cols = dict()
selects = list()
for field in df.schema:
if is_complex_dtype(field.dataType):
conv_cols[field.name] = field.dataType
selects.append(to_json(field.name).alias(field.name))
else:
selects.append(field.name)
df = df.select(*selects)
return df, conv_cols
def complex_dtypes_from_json(df, col_dtypes):
"""Converts JSON columns to complex types
Args:
df: Spark dataframe
col_dtypes (dict): dictionary of columns names and their datatype
Returns:
Spark dataframe
"""
selects = list()
for column in df.columns:
if column in col_dtypes.keys():
schema = StructType([StructField('root', col_dtypes[column])])
selects.append(from_json(column, schema).getItem('root').alias(column))
else:
selects.append(column)
return df.select(*selects)
import json
def cols_from_json(df, columns):
"""Converts Pandas dataframe colums from json
Args:
df (dataframe): Pandas DataFrame
columns (iter): list of or iterator over column names
Returns:
dataframe: new dataframe with converted columns
"""
for column in columns:
df[column] = df[column].apply(json.loads)
return df
def ct_val_to_json(value):
"""Convert a scalar complex type value to JSON
Args:
value: map or list complex value
Returns:
str: JSON string
"""
return json.dumps({'root': value})
def cols_to_json(df, columns):
"""Converts Pandas dataframe columns to json and adds root handle
Args:
df (dataframe): Pandas DataFrame
columns ([str]): list of column names
Returns:
dataframe: new dataframe with converted columns
"""
for column in columns:
df[column] = df[column].apply(ct_val_to_json)
return df
# 1. 构造数据集
from pyspark.sql.types import Row
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
spark.conf.set("spark.sql.execution.arrow.enabled", "true")
df = spark.createDataFrame([(1., {'a': 1}, ["a", "a"], Row(a=1)),
(2., {'b': 1}, ["a", "b"], Row(a=42)),
(3., {'a': 1, 'b': 3}, ["d","e"], Row(a=1))],
schema=['vals', 'maps', 'lists', 'structs'])
df.show(), df.printSchema()
# 2. 定义处理过程 并且用装饰器
df_json, ct_cols = complex_dtypes_to_json(df)
def change_vals(dct):
dct['x'] = 42
return dct
@pandas_udf_ct(df_json.schema, PandasUDFType.GROUPED_MAP)
def normalize(pdf):
pdf['maps'].apply(change_vals)
return pdf
# 3. 使用定义的装饰器
df_json = df_json.groupby("vals").apply(normalize(cols_in=ct_cols, cols_out=ct_cols))
df_final = complex_dtypes_from_json(df_json, ct_cols)
print("================ test 8:\n")
df_final.show(truncate=False), df_final.printSchema()
- 上面栗子中的需求:将值为42的键
x添加到maps列中的字典中。步骤:- 使用
complex_dtypes_to_json来获取转换后的 Spark 数据帧df_json和转换后的列ct_cols。 - 然后定义 UDF 规范化并使用的
pandas_udf_ct装饰它,使用dfj_json.schema(因为只需要简单的数据类型)和函数类型GROUPED_MAP指定返回类型。 - 其中初始的数据df和处理后的结果df如下所示。
- 使用
只是为了演示,现在按 df_json 的 vals 列分组,并在每个组上应用的规范化 UDF。如前所述,必须首先使用参数 cols_in 和 cols_out 调用它,而不是仅仅传递 normalize。作为输入列,传递了来自 complex_dtypes_to_json 函数的输出 ct_cols,并且由于没有更改 UDF 中数据帧的形状,因此将其用于输出 cols_out。如果的 UDF 删除列或添加具有复杂数据类型的其他列,则必须相应地更改 cols_out。作为最后一步,使用 complex_dtypes_from_json 将转换后的 Spark 数据帧的 JSON 字符串转换回复杂数据类型。
# 初始df
+----+----------------+------+-------+
|vals| maps| lists|structs|
+----+----------------+------+-------+
| 1.0| {a -> 1}|[a, a]| {1}|
| 2.0| {b -> 1}|[a, b]| {42}|
| 3.0|{a -> 1, b -> 3}|[d, e]| {1}|
+----+----------------+------+-------+
root
|-- vals: double (nullable = true)
|-- maps: map (nullable = true)
| |-- key: string
| |-- value: long (valueContainsNull = true)
|-- lists: array (nullable = true)
| |-- element: string (containsNull = true)
|-- structs: struct (nullable = true)
| |-- a: long (nullable = true)
# 结果df
+----+-------------------------+------+-------+
|vals|maps |lists |structs|
+----+-------------------------+------+-------+
|1.0 |{a -> 1, x -> 42} |[a, a]|{1} |
|2.0 |{b -> 1, x -> 42} |[a, b]|{42} |
|3.0 |{a -> 1, b -> 3, x -> 42}|[d, e]|{1} |
+----+-------------------------+------+-------+
root
|-- vals: double (nullable = true)
|-- maps: map (nullable = true)
| |-- key: string
| |-- value: long (valueContainsNull = true)
|-- lists: array (nullable = true)
| |-- element: string (containsNull = true)
|-- structs: struct (nullable = true)
| |-- a: long (nullable = true)
Reference
[1] 利用pyspark pandas_udf 加速机器学习任务
[2] Apache Spark+PyTorch 案例实战
[3] 官方文档pandas_udf介绍(带栗子)
[4] pandas_udf使用说明
[5] pyspark-03 UDF和Pandas_UDF
[6] 使用Pyspark的pandasUDF调用sklearn模型进行大规模预测
[7] spark部署TF、 Torch深度学习模型
[8] https://www.manning.com/books/data-analysis-with-python-and-pyspark
[9] PySpark中的自定义函数(UDF)
[10] pytoch+spark进行鲜花预测案例. databricks
[11] 在PySpark中对GroupedData应用UDF(带功能python示例)
[12] PySpark UD(A)F 的高效使用
[13] More Efficient UD(A)Fs with PySpark
[14] Efficient UD(A)Fs with PySpark
[15] pyspark pandas_udf. CSDN笔记
[16] PySpark Usage Guide for Pandas with Apache Arrow
[17] 使用Pandas_UDF快速改造Pandas代码
[18] PySpark Pandas UDF (pandas_udf) Example。 SparkByExample
[19] APACHE SPARK+PYTORCH 案例实战
[20] PySpark源码解析,用Python调用高效Scala接口,搞定大规模数据分析
[21] PySpark Or Pandas? Why Not Both:https://towardsdatascience.com/pyspark-or-pandas-why-not-both-95523946ec7c
[22] https://www.manning.com/books/data-analysis-with-python-and-pyspark
[23] pandas_udf使用说明.博客园