前言
本章内容,我们将从注意力的基础概念入手,结合Transformer架构,由宏观理解其运行流程,然后逐步深入了解多头注意力、多头掩码注意力、融合注意力等概念及作用。
注意力机制(Attension)
背景
深度学习中的注意力机制(Attention Mechanism)是一种模仿人类视觉和认知系统的方法。
注意力的产生
如下图所示,人脑在看到一幅图像时是如何分配有限的注意力资源:红色区域表明视觉系统更加关注的区域。
人们会把注意力更多的投入到人的脸部、文本的标题以及文章的首句等位置。

注意力机制核心思想
模仿人的注意力分配方式,将输入数据的重要性动态地分配权重,从而提高模型的表现。
如上图:
- 小孩的脸部:重要,乘以一个较大的权重(如0.99),突出重要性
- 图片的背景:不重要,乘以一个较小的权重(如0.01),削弱重要性
注意力本质:关注的增强,不关注的减弱
公共底层架构Transformer
在了解注意力机制后,我们从人工智能的公共底层架构Transformer入手来逐步了解整体的运行机制。
背景回顾
在【课程总结】Day17(上):NLP自然语言处理及RNN网络中,我们曾介绍过自然语言是具有时序性:
“狗追猫。”
“猫追狗。”
以上例子中,字都是相同的,但是字的顺序不同的,所表达的意思完全相反。
RNN的问题
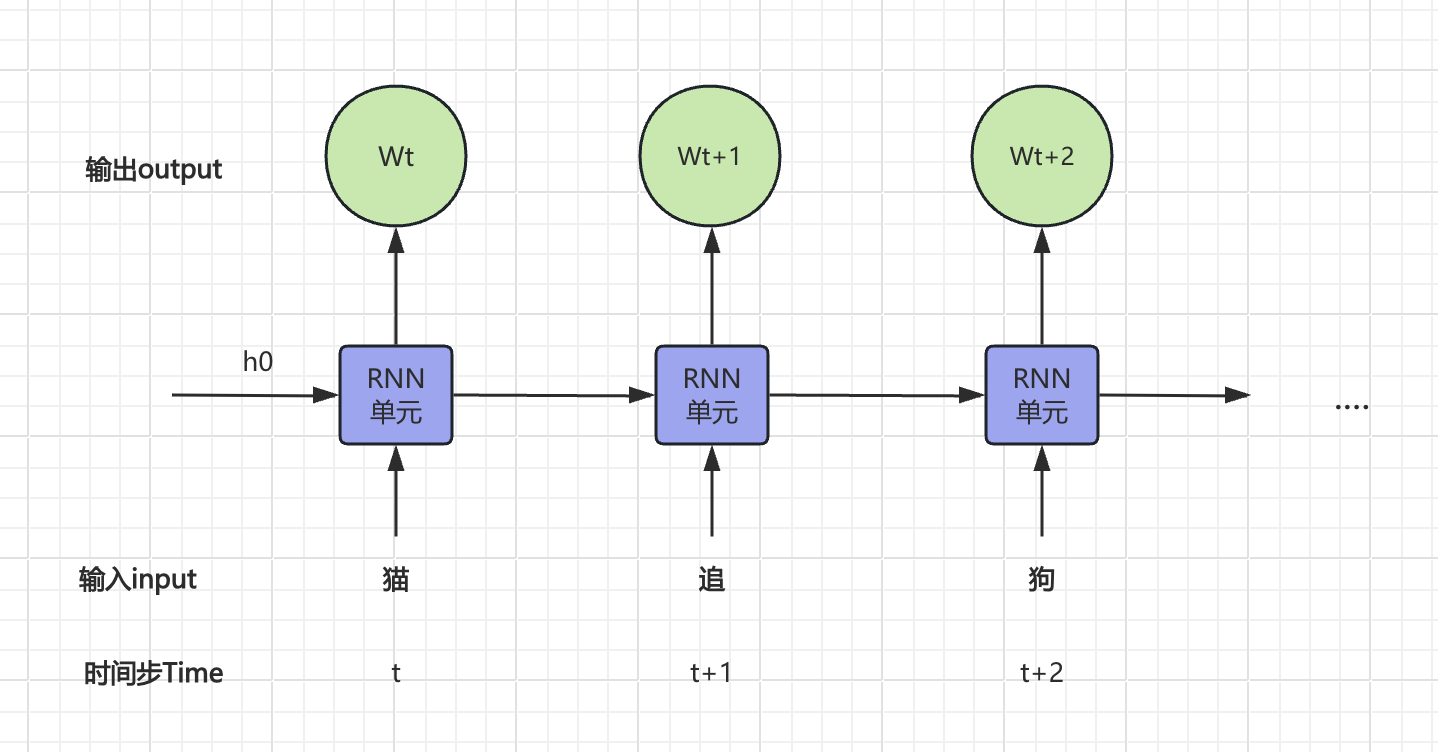
为了处理上述时序数据,RNN通过循环结构,将每个时间步的输出作为下一时间步的输入,最终得到一个完整的输出序列。但这也随之带来了一些问题:
- 梯度消失与爆炸:传统 RNN 在处理长序列时,容易出现梯度消失或梯度爆炸的问题,导致训练困难。
- 训练时间较长:由于序列数据的特性,RNN 的训练时间通常较长,尤其是在长序列上。
- 并行化困难:RNN 的计算依赖于前一个时间步的输出,导致其在训练和推理时难以进行并行化,效率较低,无法有效利用硬件加速。
Transformer的优势
2017年:Google的研究团队在论文《Attention is All You Need》中首次提出了Transformer架构。该架构完全基于自注意力机制(self-attention),摒弃了传统的循环结构,极大地提高了并行处理能力和训练效率。
优势:
- 摆脱循环:Transformer 摆脱了循环,能够在训练和推理时进行并行化,大大提高效率。
- 并行化:Transformer 通过
自注意力并行抽取特征,没有前后顺序的依赖,也就无从谈起信息遗忘。 - 可堆叠:有ResBlock和LayerNorm的加持,模型可以无限堆叠,重复越多,能力越大。
- 能力涌现:真正实现了量变到质变,能力发生了涌现。
所谓能力涌现是指:
- 早期人工智能:只是在既有数据基础上进行学习,然后可以模仿处理类似问题,这种能力只能点对点的解决特定问题,不能称为智能。
- Transformer及大模型: 面临新的场景时,可以把自己老的经验和知识迁移过来,解决新的问题,这才是智能。这种能力也称之为能力涌现。
Transformer架构
整体架构
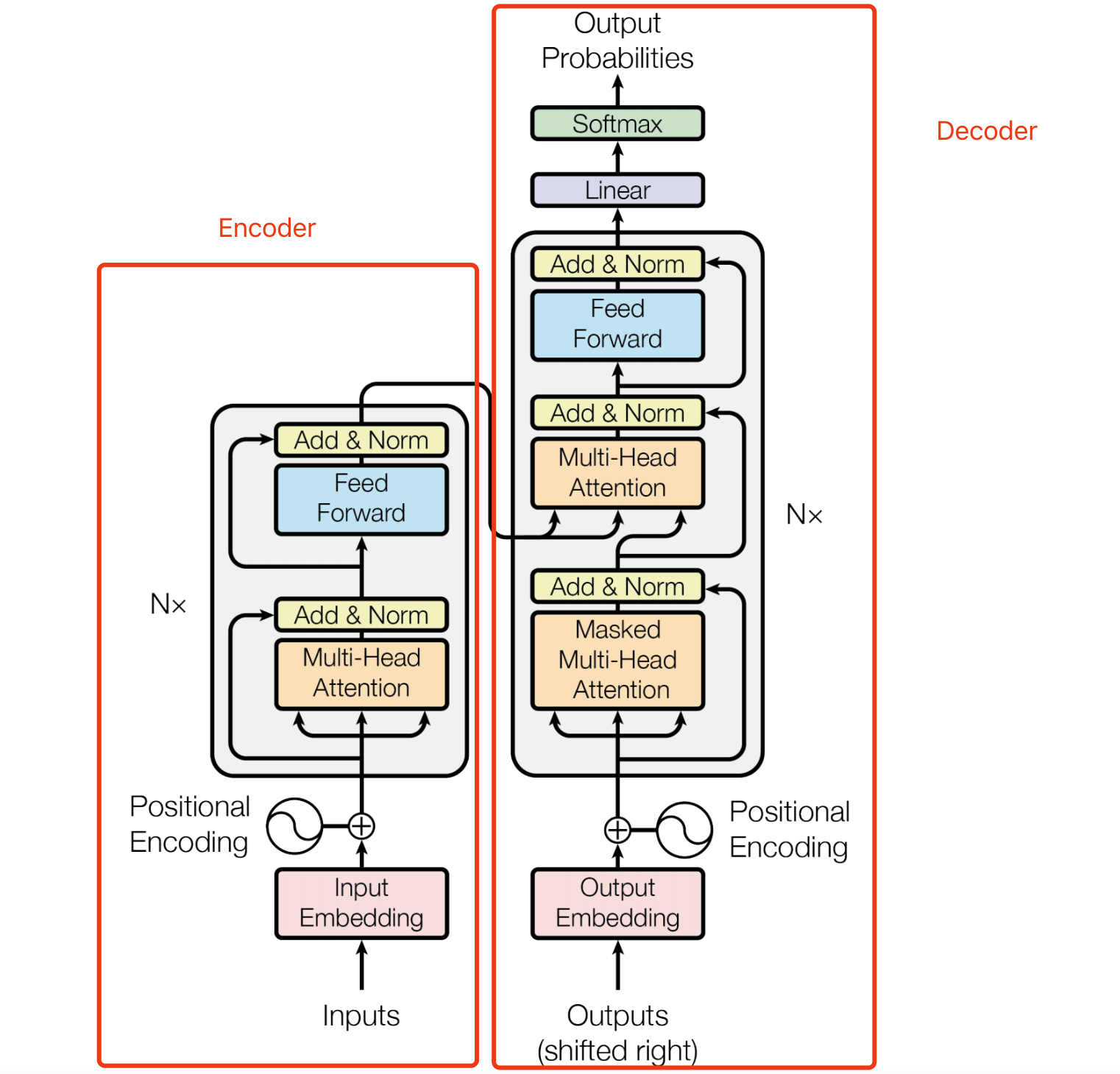
Transformer是一个典型的encoder-decoder结构。
关于Seq2Seq的内容回顾,可以查看【课程总结】Day17(下):初始Seq2Seq模型,本文不再赘述。
宏观处理流程
由于Transformer的架构图有非常多的元素,直接深入细节可能不便于理解整体运行流程,所以我们对模型架构图做一些划分处理,以便从宏观维度理解整体的运行流程。
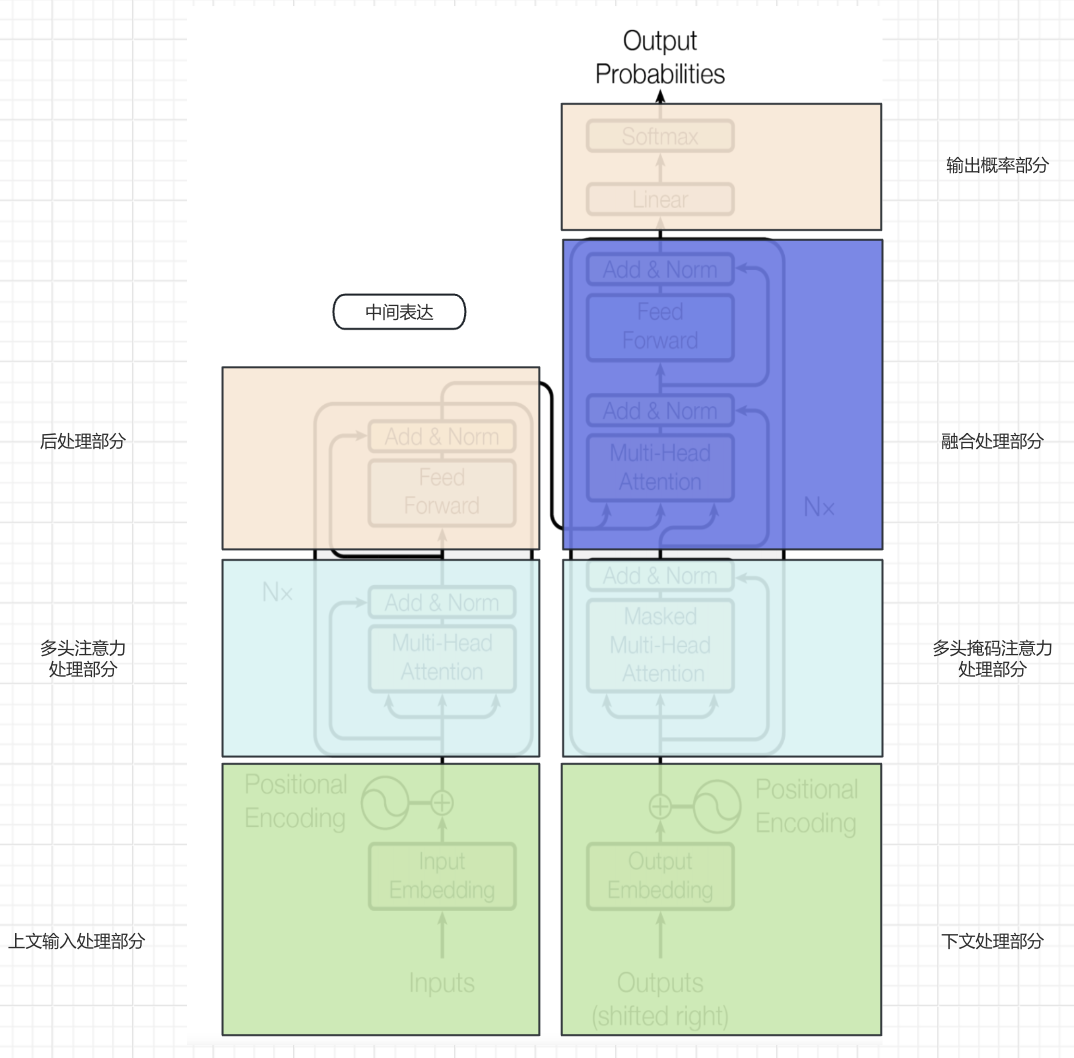
- 第一步:上文输入内容经过
上文输入处理部分进行embedding以及位置编码,生成对应上文的词向量数据。 - 第二步:特征经过
多头注意力处理部分进行特征抽取。 - 第三步:抽取的特征经过
后处理部分进行非线性变换,以增强模型的表达能力和捕捉复杂特征,最终形成中间表达。 - 第四步:
下文处理部分采用与上文处理部分的类似机制进行embedding和增加位置信息。(下文初始会增加<SOS>启动信号。) - 第五步:下文词向量数据经过
多头掩码注意力处理部分进行特征抽取。 - 第六步:
融合处理部分将上文产生的中间表达与下文特征进行融合,即提供上文,让模型补充下文。 - 第七步:
输出概率部分将融合处理部分产生的结果经过softmax进行概率分布,得到输出结果。 - 第八步:进行自回归循环,将产生的输出结果交给
下文处理部分继续第四~第七步,直到输入<EOS>结束。
注意:
Transformer相比较RNN抛弃循环的部分,主要体现在上图浅蓝色的方框中,即通过注意力机制将RNN循环处理的方式一次性并行处理。
动图演示宏观处理过程:

输入处理部分
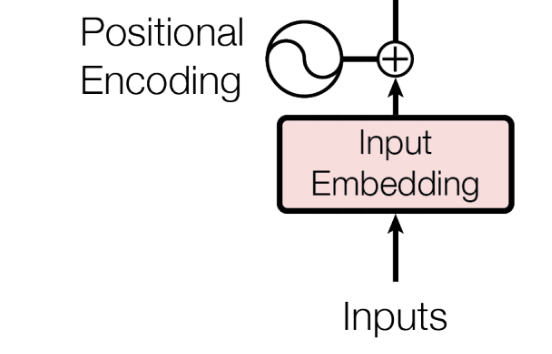
作用:解决序列数据不会丢失顺序的问题。由于Transformer取消了RNN的循环结构,其在处理特征时是并行处理,所以在输入部分需要引入Positional Encoding解决序列数据不会丢失顺序的问题。
以"狗追猫"为例:
- 原始输入:“狗追猫”
- 经过分词:“狗 追 猫”
- 经过word2idx之后:“1 2 3”
- 此时inputs = [1, 2, 3]
- 经过embedding之后:(假设转换后的词向量如下)
- “狗” → [0.1,0.2,0.3,0.4]
- “追” → [0.5,0.6,0.7,0.8]
- “猫” → [0.9,1.0,1.1,1.2]
- 经过Positional Encoding:
- 第一步:计算位置编码:
- 位置0的编码为 [0, 1, 0, 1]
- 位置1的编码为 [0.0001, 1, 0.0001, 1]
- 位置2的编码为 [0.0002, 1, 0.0002, 1]
- 第二步:将位置编码和词向量相加:
- 句子1:“狗追猫。”
- 对于“狗”:[0.1,0.2,0.3,0.4]+[0,1,0,1]=[0.1,1.2,0.3,1.4]
- 对于“追”:[0.5,0.6,0.7,0.8]+[0.0001,1,0.0001,1]≈[0.5001,1.6,0.7001,1.8]
- 对于“猫”:[0.9,1.0,1.1,1.2]+[0.0002,1,0.0002,1]≈[0.9002,2.0,1.1002,2.2]
- 句子2:“猫追狗。”
- 对于“猫”:[0.9,1.0,1.1,1.2]+[0,1,0,1]=[0.9,2.0,1.1,2.2]
- 对于“追”:[0.5,0.6,0.7,0.8]+[0.0001,1,0.0001,1]≈[0.5001,1.6,0.7001,1.8]
- 对于“狗”:[0.1,0.2,0.3,0.4]+[0.0002,1,0.0002,1]≈[0.1002,1.2,0.3002,1.4]
- 句子1:“狗追猫。”
- 第一步:计算位置编码:
- 计算位置编码的方式一般是人工预设的方式计算出来。
- 以上Position的示例是由GPT辅助生成,我并没有深究,关于计算公式详情请见Positional Encoding
通过位置编码,Transformer能够有效地捕获“狗追猫”和“猫追狗”这两个句子中词语的位置信息,从而理解它们之间的关系和语义,进而达到时序数据并行计算。
编码encoder部分
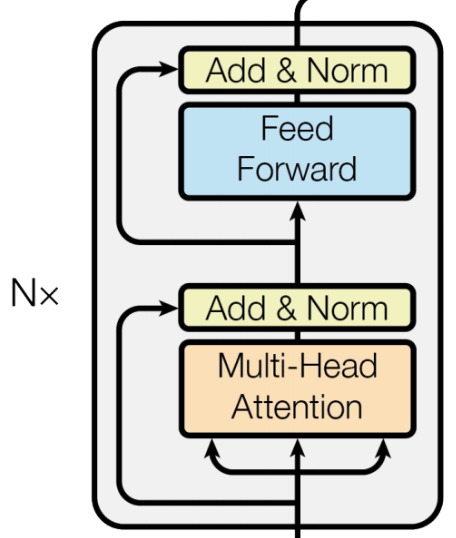
对encoder结构归纳总结,其由两部分组成:前馈网络(Feed Forward)和 自注意力(Self-Attention)。
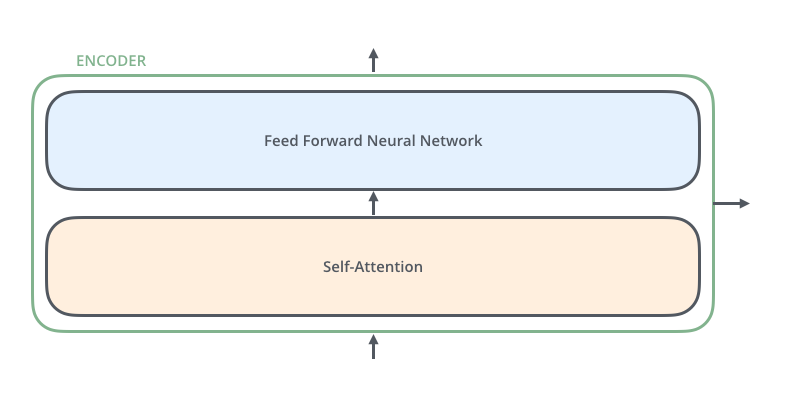
自注意力(Self-Attention)
基本思想:在处理序列数据时,每个元素都可以与序列中的其他元素建立关联,而不仅仅是依赖于相邻位置的元素。
计算原则:关注的增强,不关注的减弱
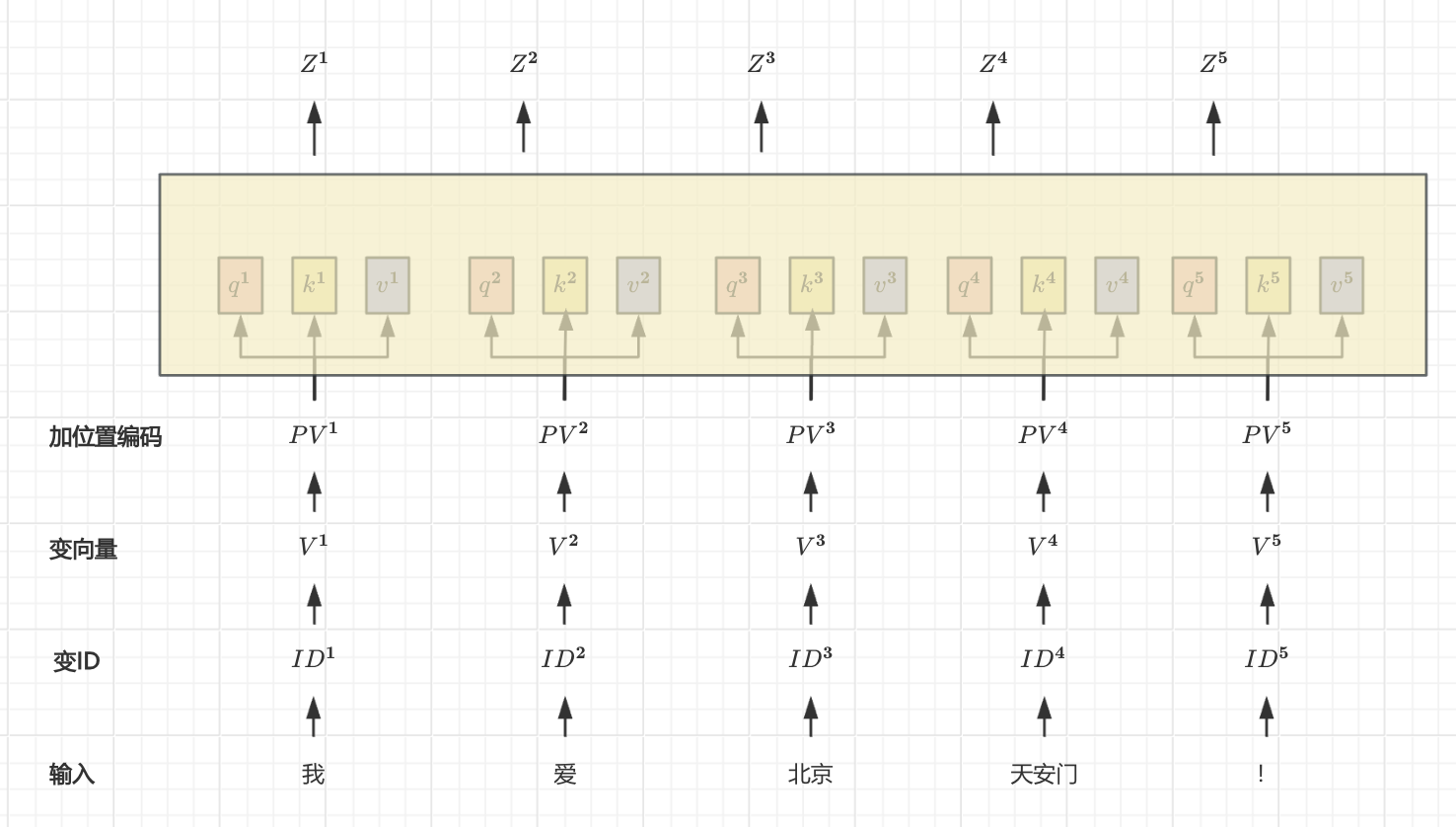
具体方法:
- 输入表示:原始输入的词,经过变ID、embedding、位置编码等处理后,词向量序列(如图中
$$PV^1$$~$$PV^5$$)。 - 一分三:通过三个不同的线性变换,将每个词一分三
$$Q = PVW_Q$$:query 查询向量(作用:查询他人)$$K = PVW_K$$:key 关键词向量(作用:等着别人来查询)$$V = PVW_V$$:value 值向量(作用:代表该词的信息)
- PV :代表具有位置信息的词向量。
$$W_Q$$、$$W_K$$、$$W_V$$:代表三个公共的、可学习的权重矩阵。
- 计算注意力权重:通过计算查询与键的向量内积来获得相似度,然后进行缩放和softmax处理,归一化为注意力权重。
例如:q1与k1,q1与k2,q1与k3计算点积,然后除以
$$\sqrt{d}$$进行缩放和softmax处理为小数。
- ( d ) 是词向量维度。
- 加权求和:通过将每个元素与对应的注意力权重进行加权求和,可以得到自注意力机制的输出
$$Z^1$$~$$Z^5$$。
多头注意力(Multi-Head Attention)
多头注意力机制是在自注意力机制的基础上发展起来的,是自注意力机制的变体,旨在增强模型的表达能力和泛化能力。
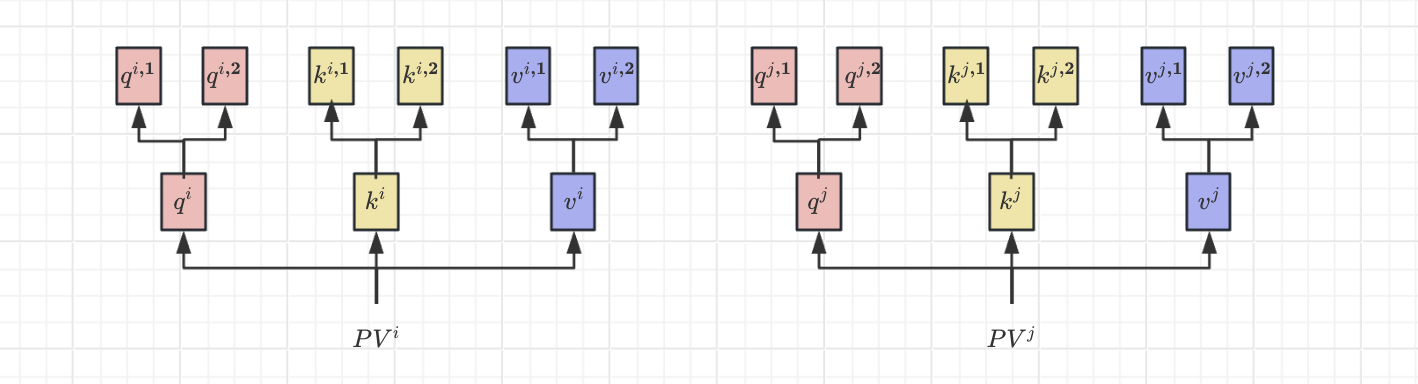
多头注意力在生成q、k、v时,会再分配多个q、k、v,上图为2个头为例。
具体方法:
- 输入表示:与自注意力相同。
- 一分三:对于每个注意力头
$$i$$,使用不同的线性变换矩阵来生成查询、键和值:
- 查询
$$Q_i = X W_Q^i$$ - 键
$$K_i = X W_K^i$$ - 值
$$V_i = X W_V^i$$
$$W_Q^i$$、$$W_K^i$$、$$W_V^i$$是每个头的可学习权重矩阵。
- 计算注意力权重:对于每个头计算注意力权重,方法同自注意力。
- 加权求和:加权求每个头的输出。
- 拼接输出:将每个头的输出拼接起来,得到最终的输出。
- 线性转换:将拼接后的输出通过线性变换矩阵得到最终的输出。
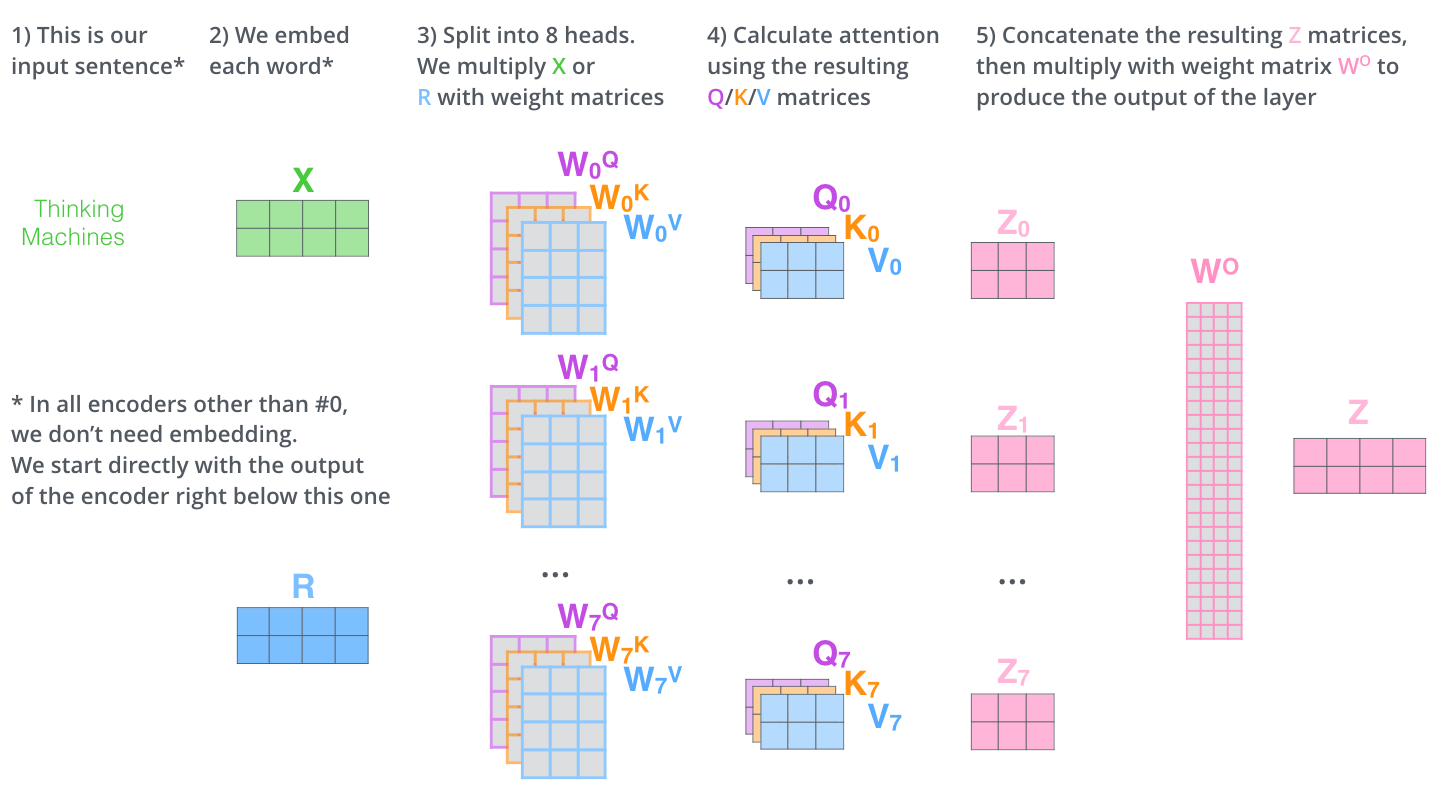
多头注意力的计算仅进行了简单地概念了解,具体的计算过程未做深究,如须了解请参考The Illustrated Transformer
解码decoder部分
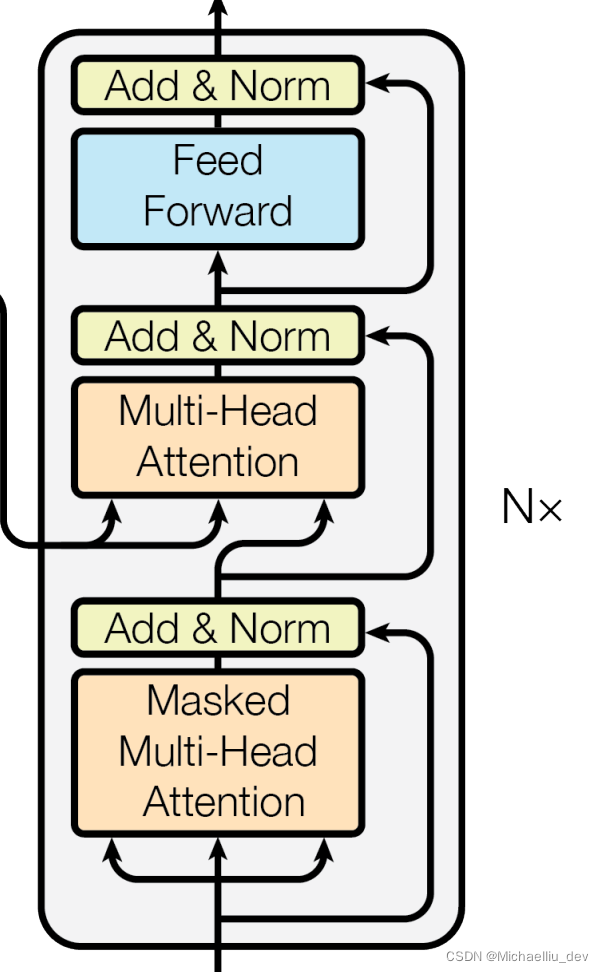
下文处理部分
该部分的逻辑与encoder中的上文处理部分逻辑一致,所以不再赘述。
多头掩码注意力(Masked Multi-Head Attention)处理部分
多头掩码注意力(Masked Multi-Head Attention)比多头注意力(Multi-Head Attention)结构多了一个masked。所以首先搞清楚mask掩码的作用。
Mask掩码的作用:
- 作用1:处理非定长序列,区分 padding 和非 padding 部分
- 作用2:处理定长序列,区分不同时间步之间的依赖关系
pad mask
背景:
在NLP中,文本一般是不定长的,所以在进行 batch训练之前,要先进行长度的统一,其中过短的句子通过 padding 增加到固定的长度;但是 padding 对应的字符只是为了统一长度,padding参与运算等于让无效的部分参与了运算,这会影响模型的性能。
以上内容曾在【课程总结】Day18:Seq2Seq的深入了解也遇到过,Seq2Seq是通过传入实际的数据长度以略过padding部分。
在Transformer中,通过给无效区域加一个很大的负数偏置,使无效区域经过softmax计算之后得到的结果几乎为0,从而避免了无效区域参与计算。
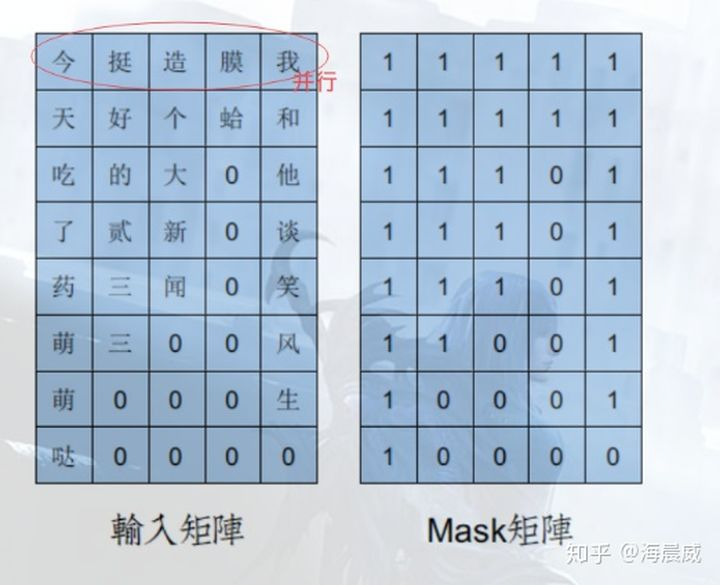
subsequence mask
在语言模型中,常常需要从上一个词预测下一个词,但如果要在LM中应用 self attention 或者是同时使用上下文的信息,要想不泄露要预测的标签信息,就需要 mask 来“遮盖”它。

- 一个包括四个词的句子[A,B,C,D],在计算了相似度scores之后,得到上面第一幅图
- 将scores的上三角区域mask掉,即替换为负无穷,再做softmax得到第三幅图。
- 这样,比如输入 B 在self-attention之后,也只和A,B有关,而与后序信息无关。
以上内容搬运自动图图解Transformer及其工程领域应用。
除此之外,其他功能与多头注意力一致,不再赘述。
融合注意力处理部分
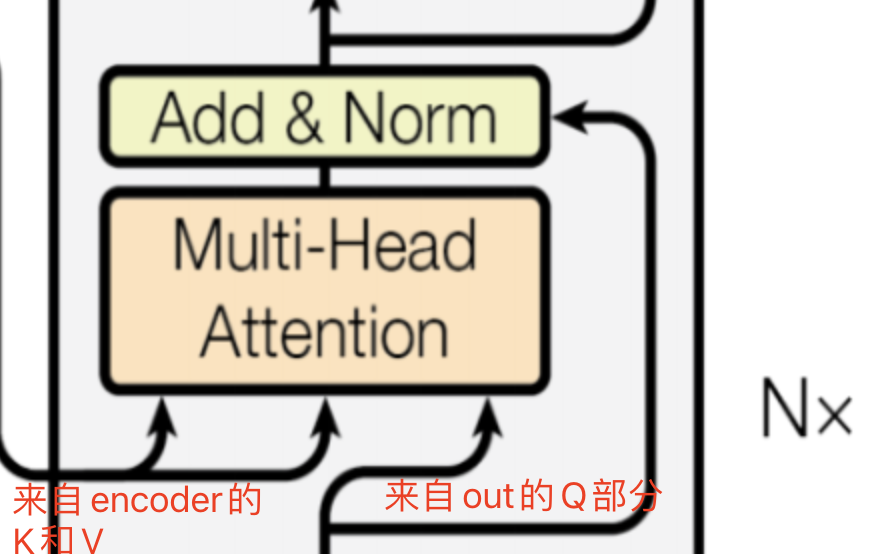
融合处理部分的输入箭头中:
- 左侧两个是来自encoder的中间表达K和V
- 右侧一个箭头来自 decoder的输出
- 这部分功能是将encoder的输出与decoder的输出进行融合,从而得到一个完整的输出。
回顾Transformer的整体结构
详细的结构图(带有内部组件)
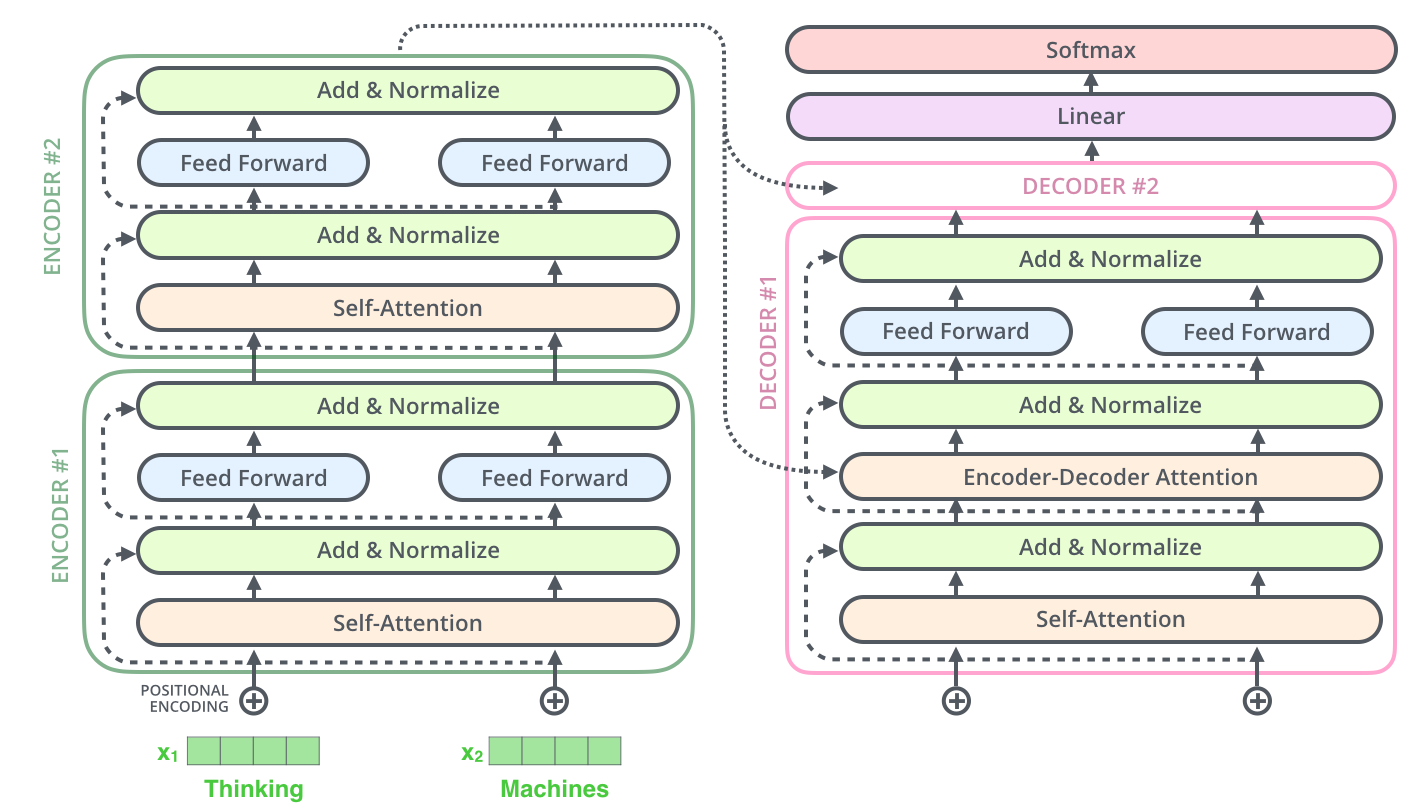
简化的结构图(带有动画效果)

内容小结
- 注意力机制是一种模仿人类视觉和认知系统的方法,其本质是:关注的增强,不关注的减弱
Transformer架构基于自注意力机制(self-attention),摒弃了传统的RNN循环结构,极大地提高了并行处理能力和训练效率。Transformer是一个典型的seq2seq结构(encoder-decoder结构),- 在endoder部分,主要由
上文输入处理外挂和多头注意力处理组成; - 在decoder部分,主要由
下文输入处理外挂、多头掩码注意力、融合处理组成。
- 在endoder部分,主要由
- 关于注意力
自注意力机制在处理序列数据时,每个元素都可以与序列中的其他元素建立关联,而不仅仅是依赖于相邻位置的元素。多头注意力机制是在自注意力机制的基础上发展起来的,是自注意力机制的变体,旨在增强模型的表达能力和泛化能力。多头掩码注意力(Masked Multi-Head Attention)比多头注意力(Multi-Head Attention)结构多了一个masked。融合注意力是将encoder的输出与decoder的输出进行融合,从而得到一个完整的输出。
mask掩码有两种作用:- 作用1:处理非定长序列,区分 padding 和非 padding 部分。
- 实现原理是:通过给无效区域加一个很大的负数偏置,使无效区域经过softmax计算之后得到的结果几乎为0,从而避免了无效区域参与计算。
- 作用2:处理定长序列,区分不同时间步之间的依赖关系,即从上一个词预测下一个词,避免"未来词"信息干扰。
- 实现原理是:在计算词的相似度scores之后,通过三角矩阵mask掉(即替换为负无穷)再做softmax,从而遮挡住"未来词"。
- Transformer的decoder时通过自回归循环,将产生的输出结果交给
下文处理部分重复进行多头注意力处理和融合注意力处理,直到输入<EOS>结束。
参考资料
论文:Attention Is All You Need
博客:The Illustrated Transformer
CSDN:论文解读:Attention Is All You Need
CSDN:《Attention Is All You Need》算法详解
CSDN:动图图解Transformer及其工程领域应用