备注:测试数据库版本为MySQL 8.0
这个blog我们来聊聊MySQL的字符集
前言:
字符集和排序规则
说实话我对这两个概念比较模糊,其实可以简单的理解:
字符集(character set):定义了字符以及字符的编码。
排序规则(collation):定义了字符的比较规则。
一个字符集对应至少一种排序规则(一般是1对多)
两个不同的字符集不能有相同的排序规则
每个字符集都有默认的排序规则
MySQL字符集相关参数
character_set_client 客户端来源数据使用的字符集,默认值:utf8mb4
character_set_connection 连接层字符集,默认值:utf8mb4
character_set_database 当前选中数据库的默认字符集,默认值:utf8mb4
character_set_results 查询结果字符集,默认值:utf8mb4
character_set_server 默认的内部操作字符集,默认值:utf8mb4
character_set_system 系统元数据(字段名等)字符集,默认值:utf8
这些参数真的多,不过还好MySQL 8.0开始,这些都是默认utf8mb4了(character_set_system除外)。
MySQL支持的字符集、排序规则:
-- MySQl支持的字符集
SHOW CHARACTER SET;
-- MySQL utf8mb4支持的排序规则:
SHOW COLLATION WHERE Charset = 'utf8mb4';常用的字符集
utf8和utf8mb4
MySQL8.0开始,默认字符集修改为了utf8mb4。
MySQL在5.5.3之后增加了utf8mb4的编码,mb4即4-Byte UTF-8 Unicode Encoding,专门用来兼容四字节的unicode。utf8mb4为utf8的超集并兼容utf8,比utf8能表示更多的字符。
如果需要存储4 字节的字符,utf8字符集就会出现问题,例如emoji表情,所以建议选择utf8mb4而非utf8。
当然utf8替换为utf8mb4占的空间更多,如果utf8绝对够用,也可以依旧使用utf8
gbk/gb2312/gb18030
GB2312 :中国国家标准简体中文字符集,共收录 6763 个汉字,其中一级汉字 3755 个,二级汉字 3008 个;同时收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的 682 个字符。
GBK :共收入21886个汉字和图形符号,GBK 向下与 GB 2312 完全兼容,向上支持 ISO 10646 国际标准,在前者向后者过渡过程中起到的承上启下的作用。
GB18030 :共收录汉字70244个,GB18030 与 GB 312 和 GBK 兼容
大多数情况下,GBK就够用了,如果生僻字比较多,可以改为GB18030
关于utf8和gbk字符集如何选择:
UTF-8:一个汉字 = 3个字节,英文是1个字节
GBK: 一个汉字 = 2个字节,英文是1个字节
测试记录:
-- 测试语句
create table t_utf8(en varchar(100),cn varchar(100)) DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci;
insert into t_utf8 values ('a','张');
insert into t_utf8 values ('ab','张三');
create table t_gbk(en varchar(100),cn varchar(100)) DEFAULT CHARACTER SET gbk COLLATE gbk_chinese_ci;
insert into t_gbk values ('a','张');
insert into t_gbk values ('ab','张三');
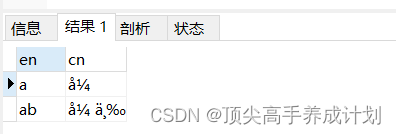
select en,cn,char_length(en),char_length(cn),length(en),length(cn) from t_utf8;
select en,cn,char_length(en),char_length(cn),length(en),length(cn) from t_gbk;
上面的sql语句对应下面的结果


latin
光latin字符集就有latin1、latin2、latin5、latin7四种,当然这4种字符集在中国应用很少,我在这里也就不一一讲解了。
MySQL一直到8.0版本才将字符集由latin1改为utf8mb4。
之前版本如果创建数据库和表的时候,不指定字符集,默认都是latin1字符集。
latin1存中文很容易出现乱码问题,给系统带来灾难性的问题,如果是MySQL 8.0之前版本,创建数据库和表,一定要指定字符集。
测试记录:
-- 创建一个latin字符集的表
create table t_latin(en varchar(100),cn varchar(100)) DEFAULT CHARACTER SET latin1 COLLATE latin1_general_ci;
-- insert的时候直接报错
insert into t_latin values ('a','程');
insert into t_latin values ('ab','张三');
-- set names latin1 此时可以将中文数据录入表
set names latin1;
insert into t_latin values ('a','张');
insert into t_latin values ('ab','张三');
-- 查询也没有问题,正常显示
select * from t_latin;
-- 退出重登陆后,发现中文乱码了
exit;
mysql -uroot -p
use test;
select * from t_latin;

解决latin1字符集显示显示乱码的两种方法
#方法一
select en,cn from t_latin;
select en,convert(unhex(hex(convert(cn using latin1))) using utf8) as cn from t_latin;
#方法二
set names latin;
set names latin1;
select en,cn from t_latin;常用MySQL的排序规则介绍
utf8_general_ci 不区分大小写,这个你在注册用户名和邮箱的时候就要使用。
utf8_general_cs 区分大小写,如果用户名和邮箱用这个 就会造成不良后果
utf8_bin:字符串每个字符串用二进制数据编译存储。 区分大小写,而且可以存二进制的内容
utf8_general_ci校对速度快,但准确度稍差。
utf8_unicode_ci准确度高,但校对速度稍慢。
show collation where charset = 'utf8';
show collation where charset = 'gbk';如果字符集选择utf8,则排序规则选择默认的utf8_general_ci
如果字符集选择utf8mb4,则排序规则选择默认的utf8mb4_0900_ai_ci
如果字符集选择gbk,则排序规则选择默认的gbk_chinese_ci
排序规则大小写敏感测试:
create table t_utf8mb4(en1 varchar(100),en2 varchar(100)) DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci;
alter table t_utf8mb4 modify column en2 varchar(100) charset utf8mb4 collate utf8mb4_0900_as_cs ;
insert into t_utf8mb4 values ('a','a');
insert into t_utf8mb4 values ('A','A');
insert into t_utf8mb4 values ('a','A');
insert into t_utf8mb4 values ('A','a');
select * from t_utf8mb4 where en1='a';
select * from t_utf8mb4 where en1='A';
select * from t_utf8mb4 where en2='a';
select * from t_utf8mb4 where en2='A';测试结果:
mysql>
mysql> create table t_utf8mb4(en1 varchar(100),en2 varchar(100)) DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci;
Query OK, 0 rows affected (0.03 sec)
mysql> alter table t_utf8mb4 modify column en2 varchar(100) charset utf8mb4 collate utf8mb4_0900_as_cs ;
Query OK, 0 rows affected (0.07 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql>
mysql>
mysql> insert into t_utf8mb4 values ('a','a');
Query OK, 1 row affected (0.00 sec)
mysql> insert into t_utf8mb4 values ('A','A');
Query OK, 1 row affected (0.01 sec)
mysql> insert into t_utf8mb4 values ('a','A');
Query OK, 1 row affected (0.00 sec)
mysql> insert into t_utf8mb4 values ('A','a');
Query OK, 1 row affected (0.01 sec)
mysql>
mysql>
mysql> select * from t_utf8mb4;
+------+------+
| en1 | en2 |
+------+------+
| a | a |
| A | A |
| a | A |
| A | a |
+------+------+
4 rows in set (0.00 sec)
mysql>
-- 查询不区分大小写的排序规则列,果然全部输出
mysql> select * from t_utf8mb4 where en1='a';
+------+------+
| en1 | en2 |
+------+------+
| a | a |
| A | A |
| a | A |
| A | a |
+------+------+
4 rows in set (0.00 sec)
mysql> select * from t_utf8mb4 where en1='A';
+------+------+
| en1 | en2 |
+------+------+
| a | a |
| A | A |
| a | A |
| A | a |
+------+------+
4 rows in set (0.00 sec)
-- 查询区分大小写的排序规则列,值输出全部是小写或全部是大写的
mysql> select * from t_utf8mb4 where en2='a';
+------+------+
| en1 | en2 |
+------+------+
| a | a |
| A | a |
+------+------+
2 rows in set (0.00 sec)
mysql> select * from t_utf8mb4 where en2='A';
+------+------+
| en1 | en2 |
+------+------+
| A | A |
| a | A |
+------+------+
2 rows in set (0.00 sec)
MySQL字符集相关参数
字符集参数介绍
character_set_client 客户端来源数据使用的字符集,默认值:utf8mb4
character_set_connection 连接层字符集,默认值:utf8mb4
character_set_database 当前选中数据库的默认字符集,默认值:utf8mb4
character_set_results 查询结果字符集,默认值:utf8mb4
character_set_server 默认的内部操作字符集,默认值:utf8mb4
character_set_system 系统元数据(字段名等)字符集,默认值:utf8
也许大家会有疑问,弄一个字符集不好吗,为什么有这6个字符集
我这边来讲讲这6个字符集的使用场景
因为服务器端和客户端,字符集会存在一定的差异。
服务器端总是假设客户端是按照 character_set_client设置的字符来传输数据和SQL语句的。
当服务器收到客户端的SQL语句时,它先将其转换为字符集character_set_connection。它还是用这个设置来决定如何将数据转换成字符串。
当服务器端返回数据或错误信息给客户端时,它会将其转换成character_set_result。
这样就保证了,服务器端和客户端在中转数据的时候,不会出现乱码。
至于character_set_server和character_set_database这两个,一个是系统默认的字符集,一个是创建数据库默认的字符集。
字符集参数修改
备注:character_set_system参数是只读参数,不能修改,其余参数可以通过set命令进行修改
上述5个参数需要保持一致,这样才能避免出现乱码,如果需要修改,可以参考如下:测试
mysql> set character_set_client = utf8;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> set character_set_connection = utf8;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql>
mysql> set character_set_database = utf8;
Query OK, 0 rows affected, 2 warnings (0.00 sec)
mysql>
mysql> set character_set_results = utf8;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> set character_set_server = utf8;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql>
mysql>
mysql> show variables like 'character_set%';
+--------------------------+----------------------------------------------+
| Variable_name | Value |
+--------------------------+----------------------------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | E:\mysql\mysql-8.0.19-winx64\share\charsets\ |
+--------------------------+----------------------------------------------+
8 rows in set, 1 warning (0.00 sec)
mysql>
-- 修改
mysql> set character_set_system = utf8;
ERROR 1238 (HY000): Variable 'character_set_system' is a read only variable
数据库、表、列的字符集
创建数据库时,如不指定字符集,将根据服务器上的character_set_server设置来设定该数据库的默认字符集。
创建表时,如不指定字符集,将根据数据库的字符集设置指定这个表的字符集。
创建列时,如不指定字符集,将根据表的设置指定列的字符集。
我们来演练一个 数据库、表、列的字符集不相同的例子。
-- 数据库字符集是 latin1
mysql> create database test1 charset latin1;
Query OK, 1 row affected (0.03 sec)
mysql> use test1;
Database changed
-- 表的字符集是 utf8mb4 而列的字符集有 utf8也有gbk
mysql> create table t1(id int,name1 varchar(100) charset gbk,name2 varchar(100) charset utf8) default charset = utf8mb4;
Query OK, 0 rows affected, 1 warning (0.06 sec)
mysql> insert into t1 values(1,'张三','张三');
Query OK, 1 row affected (0.01 sec)
mysql> select * from t1;
+------+--------+--------+
| id | name1 | name2 |
+------+--------+--------+
| 1 | 张三 | 张三 |
+------+--------+--------+
1 row in set (0.00 sec)
这样看,数据库、表、列可以有不同的字符集和排序规则。
那么我们如何选择数据库、表、列的字符集和排序规则呢?
最好是先为服务器(数据库)选择一个合理的字符集,然后表和列都遵循这个字符集。
当有特殊需求的时候,可以显式的指定表或列的字符集,让表和列选择自己合适的字符集。
字符集和排序规则如何影响查询
order by collate时 可能导致无法使用索引进行排序
测试数据:
create table t1(name1 varchar(100) charset utf8mb4 ,name2 varchar(100) charset utf8 collate utf8_bin,name3 varchar(100) charset gbk);
insert into t1 values('张三','张三','张三');
insert into t1 values('李四','李四','李四');
-- 创建索引
create index i_t1_02 on t1(name2);
explain select name2 from t1 order by name2;
explain select name2 from t1 order by name2 collate utf8_general_ci;
执行记录:
mysql> create table t1(name1 varchar(100) charset utf8mb4 ,name2 varchar(100) charset utf8 collate utf8_bin,name3 varchar(100) charset gbk);
Query OK, 0 rows affected, 2 warnings (0.03 sec)
mysql> insert into t1 values('张三','张三','张三');
Query OK, 1 row affected (0.01 sec)
mysql> insert into t1 values('李四','李四','李四');
Query OK, 1 row affected (0.01 sec)
mysql> select * from t1;
+--------+--------+--------+
| name1 | name2 | name3 |
+--------+--------+--------+
| 张三 | 张三 | 张三 |
| 李四 | 李四 | 李四 |
+--------+--------+--------+
2 rows in set (0.00 sec)
mysql> create index i_t1_02 on t1(name2);
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> explain select name2 from t1 order by name2;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t1 | NULL | index | NULL | i_t1_02 | 303 | NULL | 2 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
mysql>
mysql> explain select name2 from t1 order by name2 collate utf8_general_ci;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------------+
| 1 | SIMPLE | t1 | NULL | index | NULL | i_t1_02 | 303 | NULL | 2 | 100.00 | Using index; Using filesort |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------------+
1 row in set, 1 warning (0.00 sec)
mysql>
可以看到 order by name2 collate utf8_general_ci 由于排序规则并不是创建时指定的utf8_bin,最后使用了文件排序 Using filesort
参考文章
MySQL字符集小结_只是甲的博客-CSDN博客