0、任务
今明两天任务,回答以下问题:
1、网络传输延迟有哪些?如何区分传输延迟和排队延迟?
2、如何理解路由器存储转发的过程?
3、拥塞是什么,为什么会发生拥塞,发生拥塞的表现是什么?
4、什么是拥塞控制,拥塞控制和流量控制之间的区别是什么?
5、拥塞控制如何进行?如何检测拥塞?拥塞窗口变化规律是怎么样的?为什么会这样变化?
6、弄明白Reno拥塞控制算法的控制过程。
1、网络传输延迟有哪些?如何区分传输延迟和排队延迟?
(1)网络传输延迟有哪些?
传输延迟包括:结点处理时延、传输时延、传播时延、排队时延。
(2)如何区分传输延迟和排队延迟?
影响排队时延的因素是:
- R链路带宽(bps)
- L分组长度(bits)
- a平均分组到达速率
- 流量强度(traffic intensity)= L a R \frac{La}{R} RLa
传输延迟= L R \frac{L}{R} RL
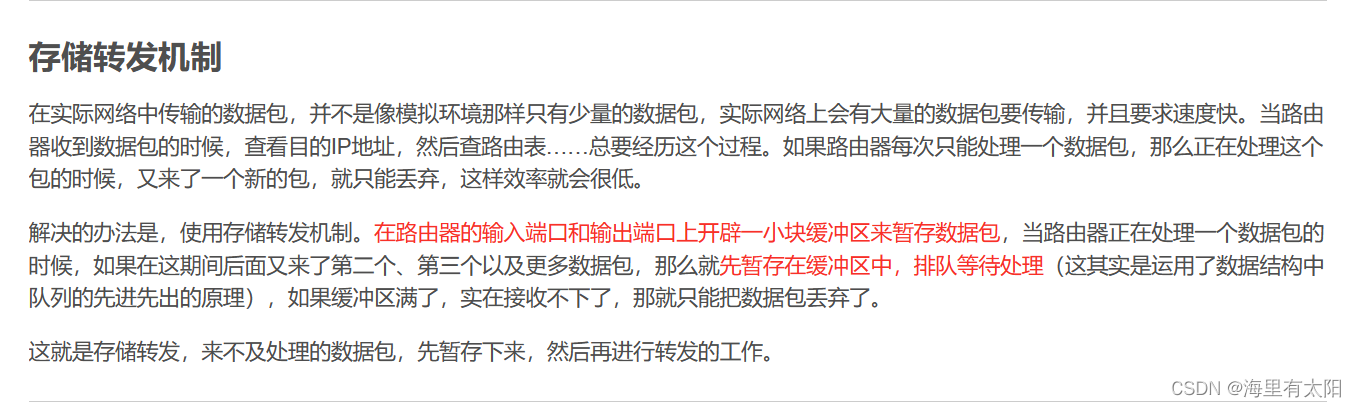
2、如何理解路由器存储转发的过程?
存储转发(stroe-and-forward):报文交换和分组交换均采用存储转发交换方式
(1)报文交换(message switching)
- 报文:源(应用:电报通信方式)发送信息整体
(2)分组交换(package switching)
- 分组:报文分拆出来的一系列相对较小的数据包
- 分组交换需要报文的拆分和重组
- 会产生额外(时间等)的开销
(3)统计多路复用(static stical multiplexing)
按需共享链路
参考链接:存储转发原理
3、拥塞是什么,为什么会发生拥塞,发生拥塞的表现是什么?
参考链接:什么是拥塞
拥塞(congestion) :在某段时间,若对网络中的某一资源的需求超过了该资源所能提供的可用部分,网络的性能就要变差,这种情况就叫拥塞。
(2)为什么会发生拥塞?
- 当某个节点缓存的容量太小时,到达该节点的分组因无存储空间暂存而不得不被丢弃。
好的,现在我们看看上述路人的说法,设想我们将节点的缓存容量扩展到非常大。于是凡到达该节点的分组均可在节点的缓存队列中排队,不受任何限制。
由于输出链路的容量和处理机的速度并未提高,因此在这队列中的绝大多数分组的排队等待时间将会大大增加,结果上层软件只好把它们进行重传(早就超时了)。
由此可见,简单的扩大缓存的存储空间同样会造成网络资源的严重浪费,因此解决不了网络拥塞的问题。
- 处理机的速率太慢而引起的网络拥塞。
简单地处理机速率提高,可能会使上述情况缓解一些,但往往又会将瓶颈转移到其它地方。问题的实质往往是整个系统的各个部分不匹配。只有所有的部分都平衡了,网络拥塞的问题才会得到解决。
(3)拥塞往往是趋于恶化的
当某一个环节开始拥塞,其它的环节就会慢慢的拥塞了起来。
如果一个路由器没有足够的缓存空间,它就会丢弃一些新到的分组。但当分组被丢弃时,发送这一分组的源点没有收到确认,认为超时了,它就会重传这一分组,甚至还有可能要重传多次。这样会引起更多的分组流入网络和被网络中的路由器丢弃。可见拥塞引起的重传并不会缓解网络的拥塞,反而会加剧网络的拥塞。
4、什么是拥塞控制,拥塞控制和流量控制之间的区别是什么?
拥塞控制和流量控制的关系十分密切,十分容易弄混淆,它们之间也存在着一些差别。
(1)拥塞控制
是:防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载 。拥塞控制所要做的都有一个前提,就是 网络能够承受现有的网络负荷 。拥塞控制是一个全局性的控制过程 。
拥塞控制涉及到所有的主机、所有的路由器,以及与降低网络传输性能有关的所有因素。当 TCP 连接的端点只要迟迟不能收到对方的确认信息,就猜想在当前网络中的某处很可能发生了拥塞,但这是却无法知道拥塞到底发生在网络的何处,也无法确认拥塞的具体原因(是访问某个服务器的通信量过大?还是在某个地区出现了自然灾害)。
拥塞控制是发送端?
(2)流量控制
流量控制是接收端?
相反, 流量控制往往指点对点通信量的控制 ,是个 端到端 的问题(接收端控制发送端)。流量控制所要做的就是抑制发送端发送数据的速率,以便使接收端来得及接收。

5、拥塞控制如何进行?如何检测拥塞?拥塞窗口变化规律是怎么样的?为什么会这样变化?
拥塞控制的过程分为四个阶段:慢启动、拥塞避免、拥塞发生(快重传)、快恢复
检测拥塞:通过拥塞事件触发,或者监控RTT等的变化
拥塞窗口变化是:在慢启动阶段加性增,拥塞避免阶段乘性减