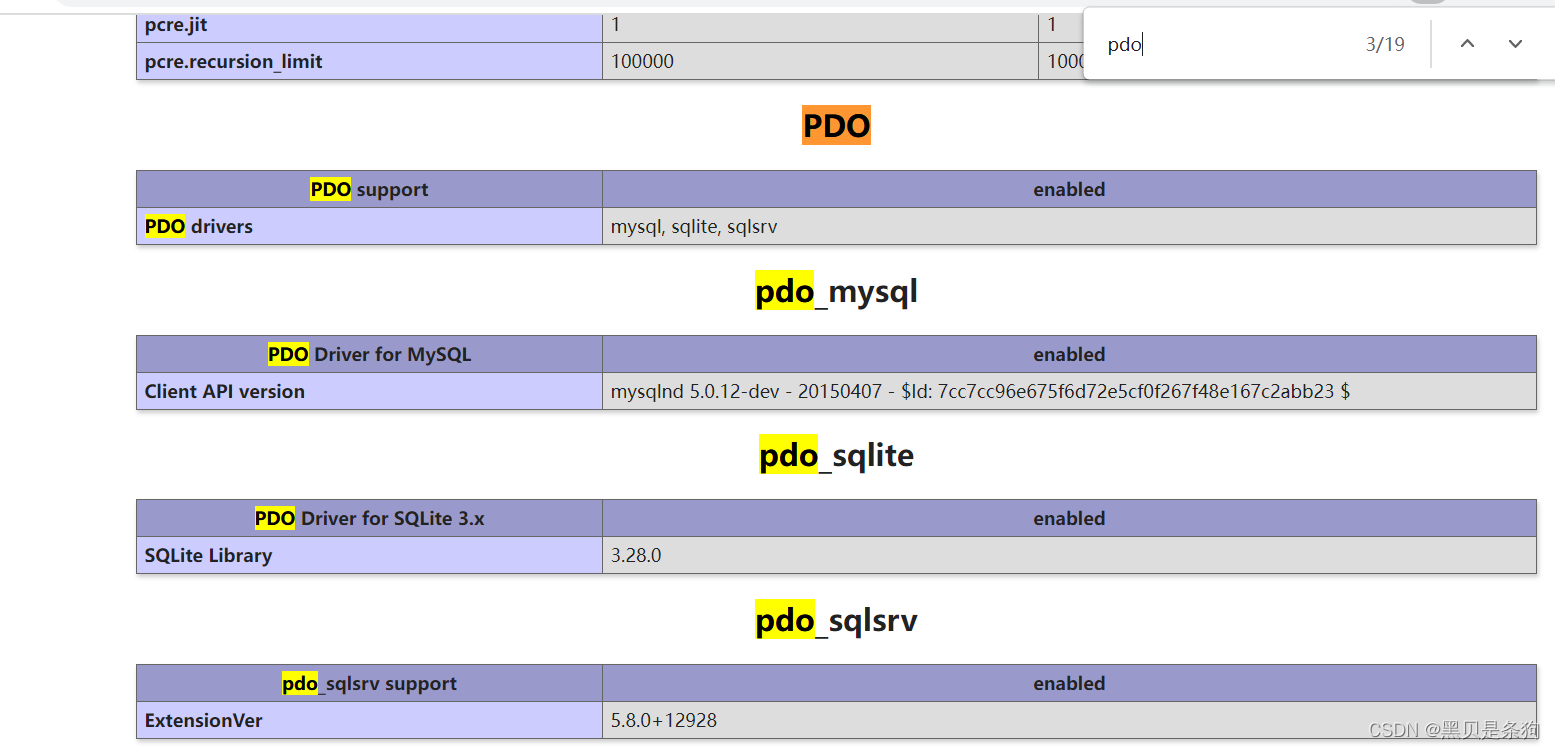
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.Cv、cs.LG
1.Compositional Prompt Tuning with Motion Cues for Open-vocabulary Video Relation Detection(ICLR 2023)

标题:通过基于错误的隐性神经表征的上下文修剪实现高效的元学习
作者: Kaifeng Gao, Long Chen, Hanwang Zhang, Jun Xiao, Qianru Sun
文章链接:https://arxiv.org/abs/2302.00268v1
项目代码:https://github.com/dawn-lx/openvoc-vidvrd

摘要:
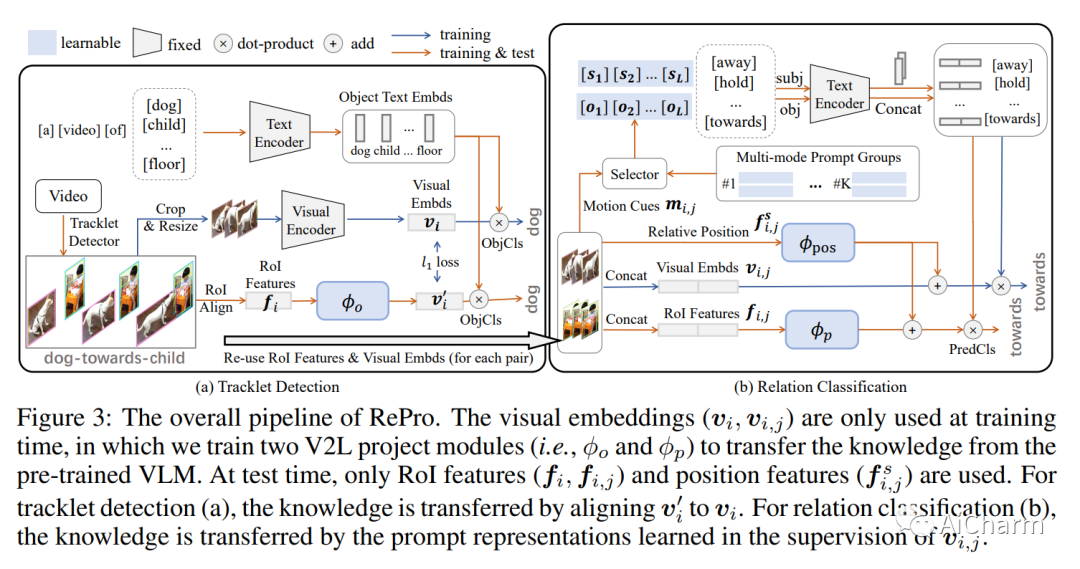
用大规模预训练的视觉语言模型进行提示调谐,可以增强在有限的基础类别上训练的开放式词汇预测,例如物体分类和检测。在本文中,我们提出了带有运动线索的合成提示调谐:一种用于视频数据合成预测的扩展提示调谐范式。特别是,我们提出了用于开放词汇视频视觉关系检测(Open-VidVRD)的关系提示(RePro),传统的提示调谐很容易偏向于某些主客体的组合和运动模式。为此,RePro解决了Open-VidVRD的两个技术难题:1)提示标记应尊重主语和宾语这两个不同的语义角色;2)调整应考虑到主客体组合的不同时空运动模式。在没有任何附加条件的情况下,我们的RePro在两个VidVRD基准上取得了新的最先进的性能,不仅是基本的训练对象和谓词类别,而且还有未见过的类别。广泛的消融也证明了所提出的提示语的组成和多模式设计的有效性。
Prompt tuning with large-scale pretrained vision-language models empowers open-vocabulary predictions trained on limited base categories, e.g., object classification and detection. In this paper, we propose compositional prompt tuning with motion cues: an extended prompt tuning paradigm for compositional predictions of video data. In particular, we present Relation Prompt (RePro) for Open-vocabulary Video Visual Relation Detection (Open-VidVRD), where conventional prompt tuning is easily biased to certain subject-object combinations and motion patterns. To this end, RePro addresses the two technical challenges of Open-VidVRD: 1) the prompt tokens should respect the two different semantic roles of subject and object, and 2) the tuning should account for the diverse spatio-temporal motion patterns of the subject-object compositions. Without bells and whistles, our RePro achieves a new state-of-the-art performance on two VidVRD benchmarks of not only the base training object and predicate categories, but also the unseen ones. Extensive ablations also demonstrate the effectiveness of the proposed compositional and multi-mode design of prompts. Code is available at this https URL.
2.Stable Target Field for Reduced Variance Score Estimation in Diffusion Models(ICLR 2023)

标题:扩散模型中用于降低方差的分数估计的稳定目标场
作者:Yilun Xu, Shangyuan Tong, Tommi Jaakkola
文章链接:https://arxiv.org/abs/2302.00670v1
项目代码:https://github.com/newbeeer/stf
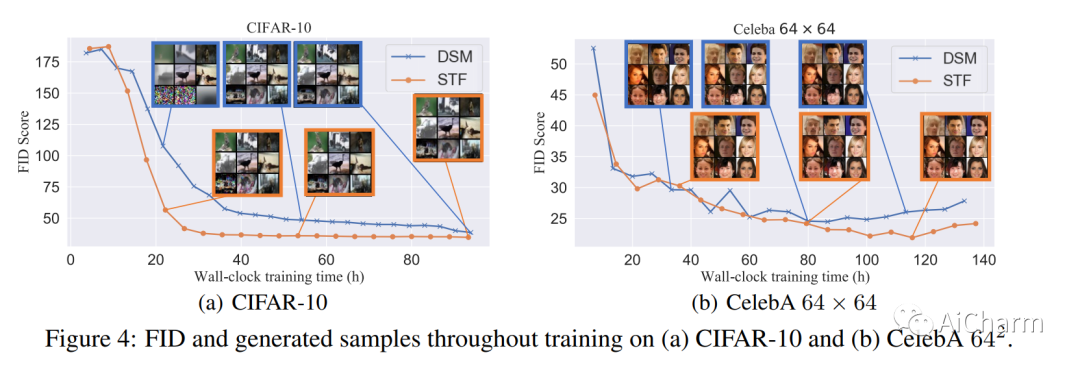
摘要:
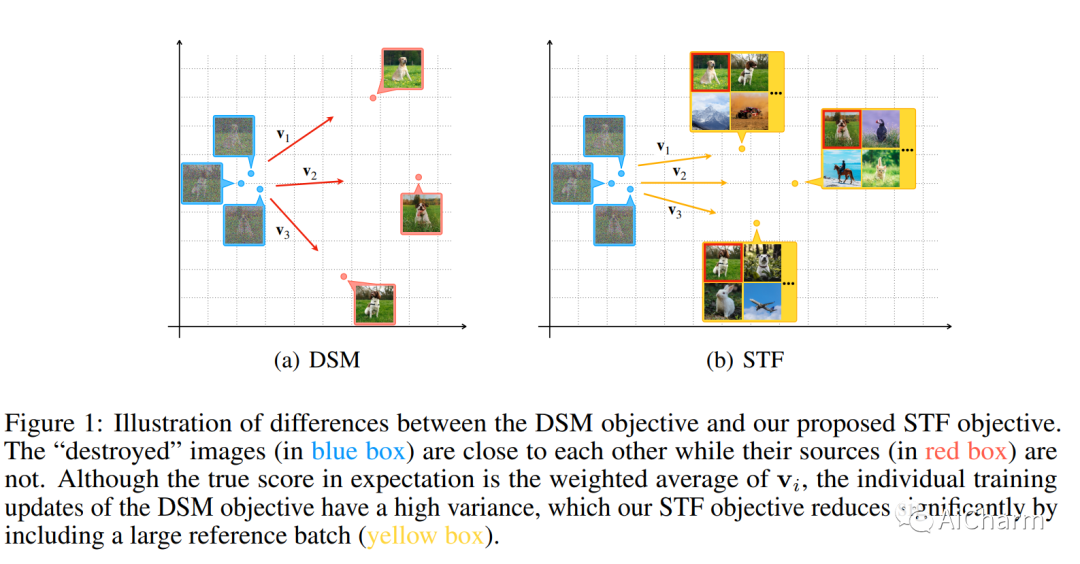
扩散模型通过逆转一个固定的前向扩散过程产生样本。尽管已经提供了令人印象深刻的经验结果,但这些扩散模型算法可以通过减少其去噪分数匹配目标中训练目标的方差而进一步改进。我们认为,这种方差的来源在于对中间噪声-方差尺度的处理,其中数据中的多种模式会影响反向路径的方向。我们建议通过纳入一个参考批次来补救这个问题,我们用它来计算加权条件分数作为更稳定的训练目标。我们表明,该程序通过减少训练目标的协方差(痕迹),确实有助于挑战性的中间制度。新的稳定目标可以被看作是用偏差来换取降低的方差,其中偏差会随着参考批次大小的增加而消失。经验表明,新的目标改善了各种流行的扩散模型的图像质量、稳定性和训练速度,这些模型都是用一般的ODE和SDE求解器。当与EDM结合使用时,我们的方法在无条件的CIFAR-10生成任务上进行了35次网络评估,产生了1.90的当前SOTA FID。
Diffusion models generate samples by reversing a fixed forward diffusion process. Despite already providing impressive empirical results, these diffusion models algorithms can be further improved by reducing the variance of the training targets in their denoising score-matching objective. We argue that the source of such variance lies in the handling of intermediate noise-variance scales, where multiple modes in the data affect the direction of reverse paths. We propose to remedy the problem by incorporating a reference batch which we use to calculate weighted conditional scores as more stable training targets. We show that the procedure indeed helps in the challenging intermediate regime by reducing (the trace of) the covariance of training targets. The new stable targets can be seen as trading bias for reduced variance, where the bias vanishes with increasing reference batch size. Empirically, we show that the new objective improves the image quality, stability, and training speed of various popular diffusion models across datasets with both general ODE and SDE solvers. When used in combination with EDM, our method yields a current SOTA FID of 1.90 with 35 network evaluations on the unconditional CIFAR-10 generation task. The code is available at this https URL
Subjects: cs.AI、cs.CL
For the Underrepresented in Gender Bias Research: Chinese Name Gender Prediction with Heterogeneous Graph Attention Network

标题:为性别偏见研究中代表不足的人:用异质图注意网络预测中文名字的性别
作者: Zihao Pan, Kai Peng, Shuai Ling, Haipeng Zhang
文章链接:https://arxiv.org/abs/2302.00419v1
项目代码:https://github.com/zhangdatalab/chgat
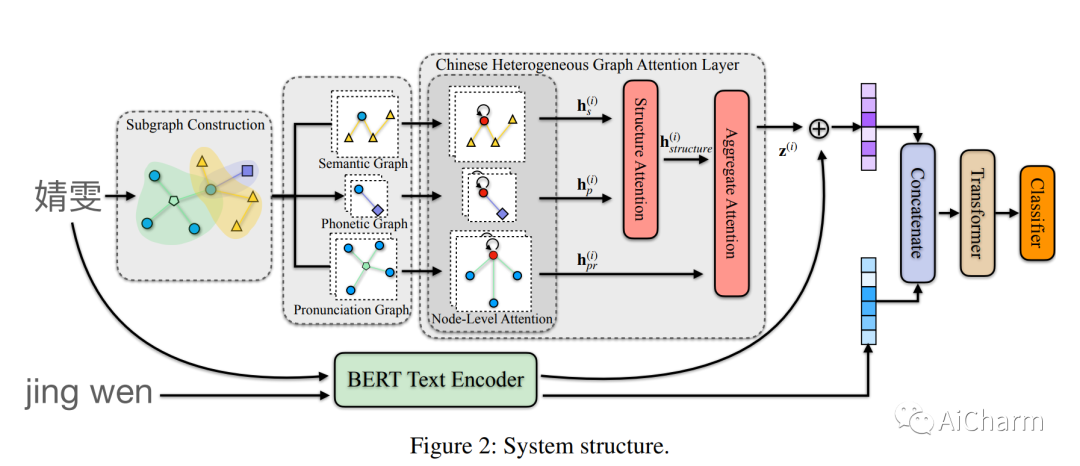

摘要:
实现性别平等是人类可持续未来的一个重要支柱。开创性的数据驱动的性别偏见研究是基于大规模的公共记录,如科学论文、专利和公司注册,涵盖女性研究人员、发明家和企业家等。由于相关数据集中的性别信息经常缺失,研究依赖于从名字中推断性别的工具。然而,现有的开源中文性别猜测工具还不适合科学用途,这可能是女性中文在主流性别偏见研究中代表性不足的部分原因,也影响了其普遍性。具体来说,这些工具只关注字词层面的信息,而忽略了多字名中的汉字组合,以及字词的组成和读音传达了重要信息。作为第一项努力,我们设计了一个中文异质图注意(CHGAT)模型,以捕捉部件关系的异质性,并纳入字符的发音。我们的模型在很大程度上超过了目前的工具,也超过了最先进的算法。最后但并非最不重要的是,最流行的中文姓名性别数据集是基于单字的,其女性覆盖率远远低于不可靠的来源,自然阻碍了相关研究。我们将一个更平衡的多字数据集和我们的代码一起开源,希望能帮助未来的研究促进性别平等。
Achieving gender equality is an important pillar for humankind's sustainable future. Pioneering data-driven gender bias research is based on large-scale public records such as scientific papers, patents, and company registrations, covering female researchers, inventors and entrepreneurs, and so on. Since gender information is often missing in relevant datasets, studies rely on tools to infer genders from names. However, available open-sourced Chinese gender-guessing tools are not yet suitable for scientific purposes, which may be partially responsible for female Chinese being underrepresented in mainstream gender bias research and affect their universality. Specifically, these tools focus on character-level information while overlooking the fact that the combinations of Chinese characters in multi-character names, as well as the components and pronunciations of characters, convey important messages. As a first effort, we design a Chinese Heterogeneous Graph Attention (CHGAT) model to capture the heterogeneity in component relationships and incorporate the pronunciations of characters. Our model largely surpasses current tools and also outperforms the state-of-the-art algorithm. Last but not least, the most popular Chinese name-gender dataset is single-character based with far less female coverage from an unreliable source, naturally hindering relevant studies. We open-source a more balanced multi-character dataset from an official source together with our code, hoping to help future research promoting gender equality.
更多Ai资讯:公主号AiCharm