8.3 深度学习与排序模型发展
学习目标
- 目标
- 了解深度学习排序模型的发展
- 应用
- 无
8.3.1 模型发展
CTR/CVR预估经历了从传统机器学习模型到深度学习模型的过渡。下面先简单介绍下传统机器学习模型(GBDT、LR、到深度模型及应用,然后再详细介绍在深度学习模型的迭代。
LR
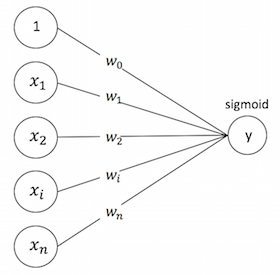
y(\mathbf{x}) = sigmoid(w_0+ \sum_{i=1}^n w_i x_i)y(x)=sigmoid(w0+∑i=1nwixi)
LR可以视作单层单节点的“DNN”, 是一种宽而不深的结构,所有的特征直接作用在最后的输出结果上。模型优点是简单、可控性好,但是效果的好坏直接取决于特征工程的程度,需要非常精细的连续型、离散型、时间型等特征处理及特征组合。通常通过正则化等方式控制过拟合。
FM & FFM
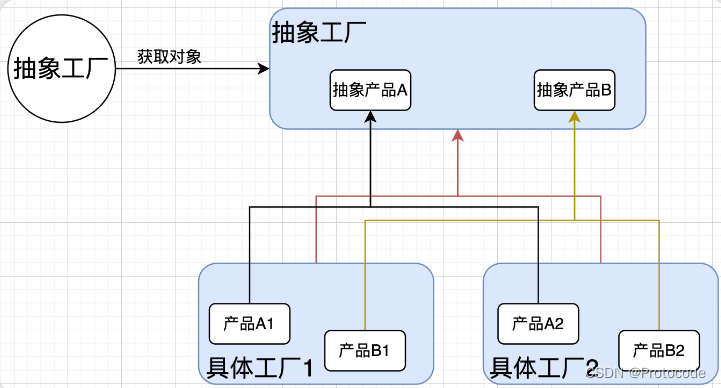
FM可以看做带特征交叉的LR,如下图所示:
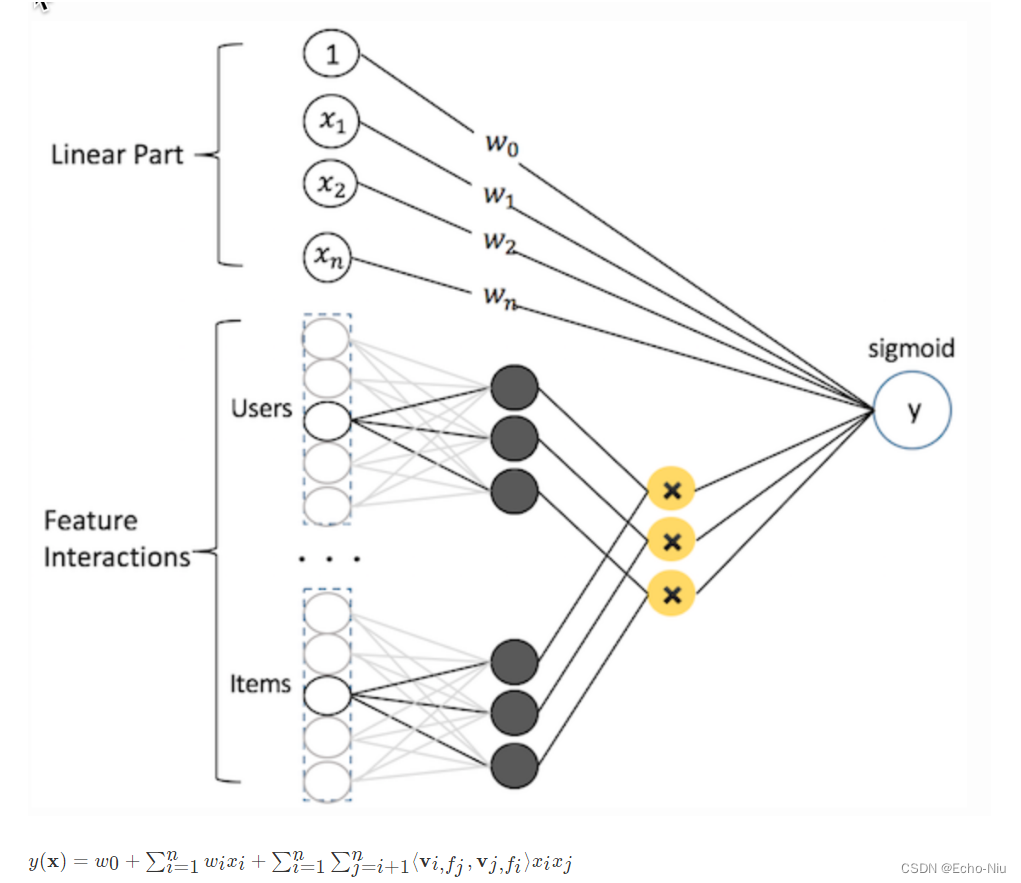
模型覆盖了LR的宽模型结构,同时也引入了交叉特征,增加模型的非线性,提升模型容量,能捕捉更多的信息,对于CTR预估等复杂场景有更好的捕捉。
- 特征交叉:
- 例子:年龄:[1990,2000],[2000,2010]
- 性别:male, female
- 交叉特征:male and [1990,2000],female and [1990,2000] ,male and [2000,2010], female and [2000, 2010]
DNN
实验表明从线性的LR到具备非线性交叉的FM,到具备Field信息交叉的FFM,模型复杂度(模型容量)的提升,带来的都是结果的提升。而LR和FM/FFM可以视作简单的浅层神经网络模型,基于下面一些考虑,我们在把CTR模型切换到深度学习神经网络模型:
- 通过改进模型结构,加入深度结构,利用端到端的结构挖掘高阶非线性特征,以及浅层模型无法捕捉的潜在模式。
- 对于某些ID类特别稀疏的特征,可以在模型中学习到保持分布关系的稠密表达(embedding)。
- 充分利用图片和文本等在简单模型中不好利用的信息。
Wide & Deep
首先尝试的是Google提出的经典模型Wide & Deep Model,模型包含Wide和Deep两个部分(LR+DNN的结合)
- 其中Wide部分可以很好地学习样本中的高频部分,在LR中使用到的特征可以直接在这个部分使用,但对于没有见过的ID类特征,模型学习能力较差,同时合理的人工特征工程对于这个部分的表达有帮助。
- 根据人工经验、业务背景,将我们认为有价值的、显而易见的特征及特征组合,喂入Wide侧。
- Deep部分可以补充学习样本中的长尾部分,同时提高模型的泛化能力。Wide和Deep部分在这个端到端的模型里会联合训练。
- 通过embedding将tag向量化,变tag的精确匹配,为tag向量的模糊查找,使自己具备了良好的“扩展”能力。
8.3.2 类别特征在推荐系统中作用
注:深度学习的这一波热潮,发源于CNN在图像识别上所取得的巨大成功,后来才扩展到推荐、搜索等领域。但是实际上,推荐系统中所使用的深度学习与计算机视觉中用到的深度学习有很大不同。其中一个重要不同,就是图像都是稠密特征,而推荐、搜索中大量用到的是稀疏的类别/ID类特
优点:
- LR, DNN在底层还是一个线性模型,但是实际工业中,标签y与特征x之间较少存在线性关系,而往往是分段的。以“点击率~历史曝光次数”之间的关系为例,之前曝光过1、2次的时候,“点击率~历史曝光次数”之间一般是正相关的,再多曝光1、2次,用户由于好奇,没准就点击了;但是,如果已经曝光过8、9次了,由于用户已经失去了新鲜感,越多曝光,用户越不可能再点,这时“点击率~历史曝光次数”就表现出负相关性。因此,categorical特征相比于numeric特征,更加符合现实场景。
- 推荐、搜索一般都是基于用户、商品的标签画像系统,而标签大多数都是categorical的
- 稀疏的类别/ID类特征,可以稀疏地存储、传输、运算,提升运算效率。
缺点:
稀疏的categorical/ID类特征,也有着单个特征表达能力弱、特征组合爆炸、分布不均匀导致受训程度不均匀的缺点。为此,一系列的新技术被提出来:
- 算法上,FTRL这样的算法,充分利用输入的稀疏性在线更新模型,训练出的模型也是稀疏的,便于快速预测。
- TensorFlow Feature Column类,除了一个numeric_column是处理实数特征的,其实的都是围绕处理categorical特征的,封装了常见的分桶、交叉、哈希等操作。
- 深度学习与交叉特征的应用也会增加效果
](https://img-blog.csdnimg.cn/9712415c3add452f943c523eadc6605a.png)