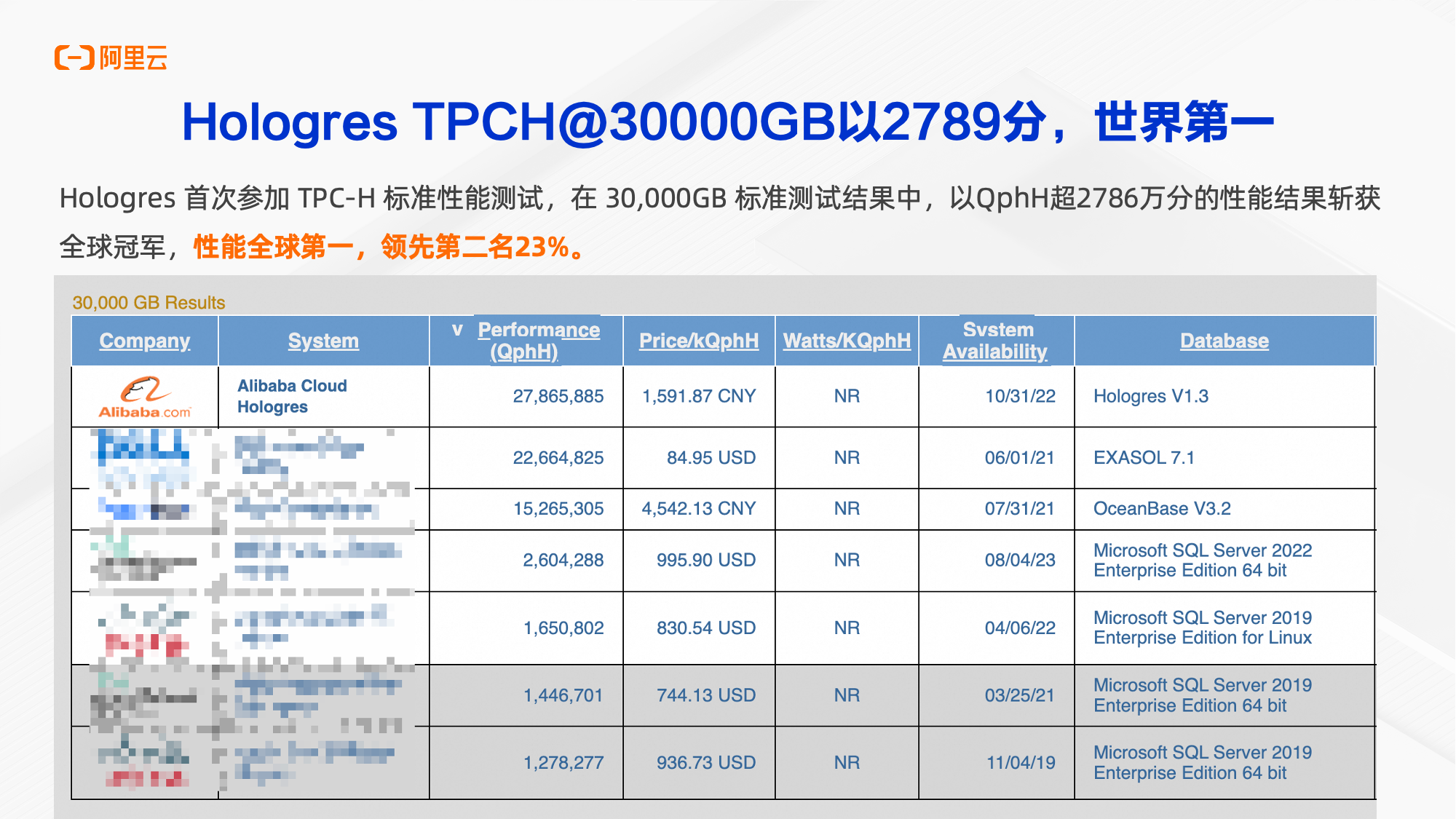
实时数仓Hologres是阿里云自研一站式实时数仓引擎,提供统一、实时、弹性、易用的一站式实时数仓引擎,分析性能打破TPC-H世界记录,一份数据可同时支持多维分析(OLAP)、即席分析(Ad Hoc)、点查(Servering)、向量计算等多种场景,替换各类OLAP 引擎(ClickHouse/Doris/Greenplum/Presto/Impala等)、KV 数据库(HBase/Redis等)。本次开箱测试主要通过96CU进行OLAP场景的TPC标准查询测试以及Serving场景会包含例如insert场景、update的场景,如果您也需要测试可以在官网购买59元150000CU时进行测试(1个96CU实例1小时消耗96CU时)

一、Hologres测试流程
OLAP场景通常主要会选用TPC标准查询测试。Serving场景会包含例如insert场景、update的场景,按照主键去进行整行更新、按照进主键去做部分列的更新以及key value的这种点查的性能测试。

Hologres现在仍然是TPCH-30000榜单的全球第一,领先第二名高达23%。OLAP的场景会选用TPCH数据集的数据和SQL进行测试。
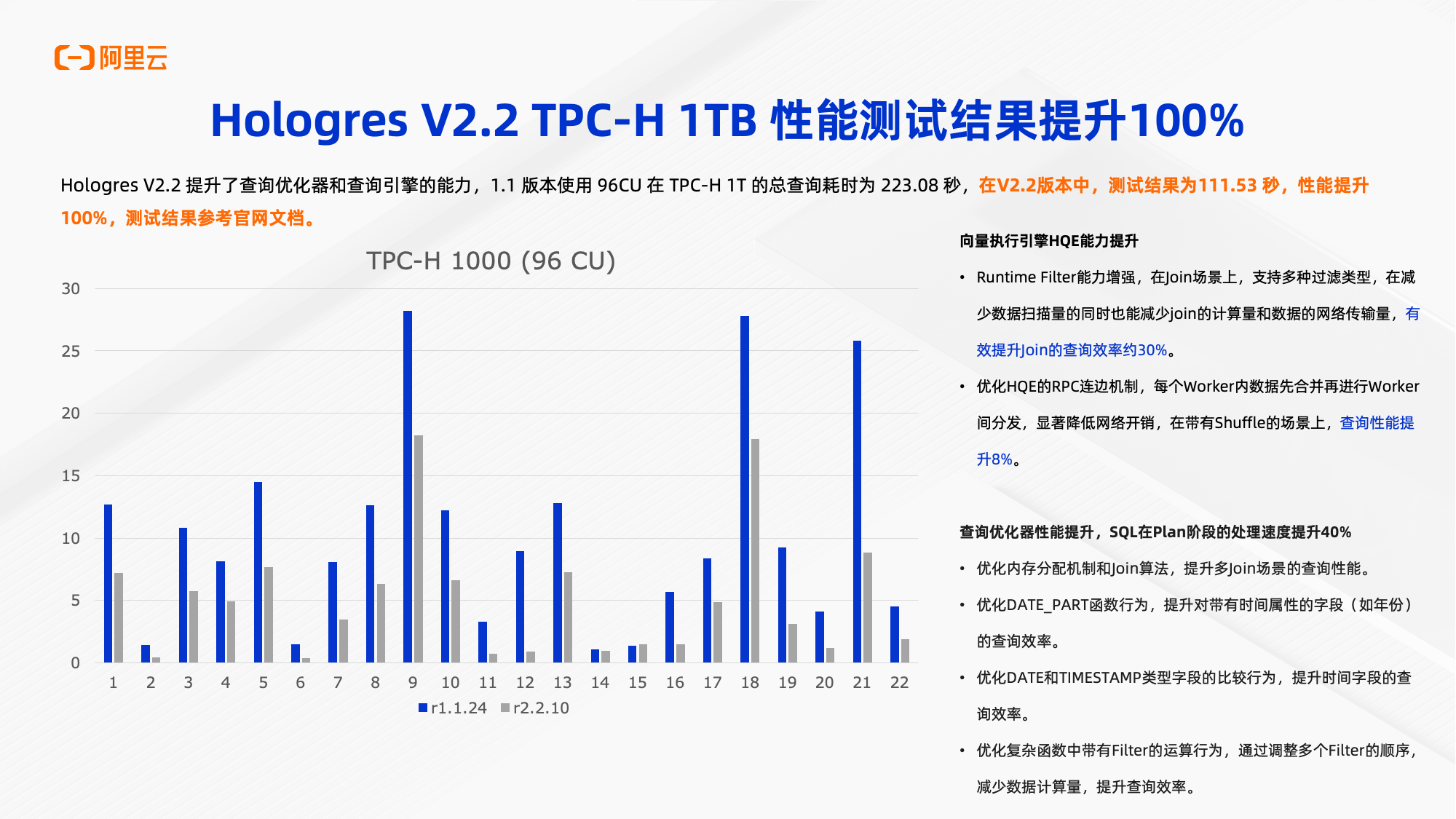
最新发布的2.2版本重构了QO和QE,相比之前的1.x的版本性能大约提升100%。1.x的版本约为200秒左右,在2.2的版本约为110秒左右,性能提升非常明显。其中2.2版本也引入了很多优化,包括runtime filter的全场景支持。在支持local的runtime filter、global的runtime filter、HQE的RPC的连接的机制,以及worker内数据先进行合并,再进行worker的分发。包括QO在Plan的生成阶段,处理阶段都有一些新的优化,才能达到现在这个性能的这个效果。
以下为性能测试的流程及说明

1.1 创建实例
Hologres是存储计算分离的架构。存储使用高性能的盘古的DFS的存储,同时支持直读maxcomputer中的数据,实现高性能的透明加速,同时支持冷热数据分离的能力,支持多种的存储格式,包括适合serving场景的行存,以及适合OLAP场景的列存,以及行列共存。 计算层使用容器化的部署,Hologres是16CU 1个容器的节点,例如购买实例的时候,32CU是两个节点。扩容为计算资源的扩容。

这是购买实例的界面。那么购买实例的时候,选择这个计算资源的信息,选择网络等信息即可创建实例。如果您也需要测试可以在官网购买59元150000CU时进行测试(1个96CU实例1小时消耗96CU时)
1.2 管控台
创建完毕之后,在实例的管控台上可以找到实例。点击具体的这个实例名称就可以进入实例详情页面。在这个页面上可以看到实现实例所在的可用区,实例的规格,计算资源有多少网络信息。例如比如说VPC的域名是什么.在测试的时候,需要购买一台VPC的ECS,需要从这个VPC的域名去连接实例。同时我们可以在管控台或者云监控里面去查询实例相关的这种监控信息。
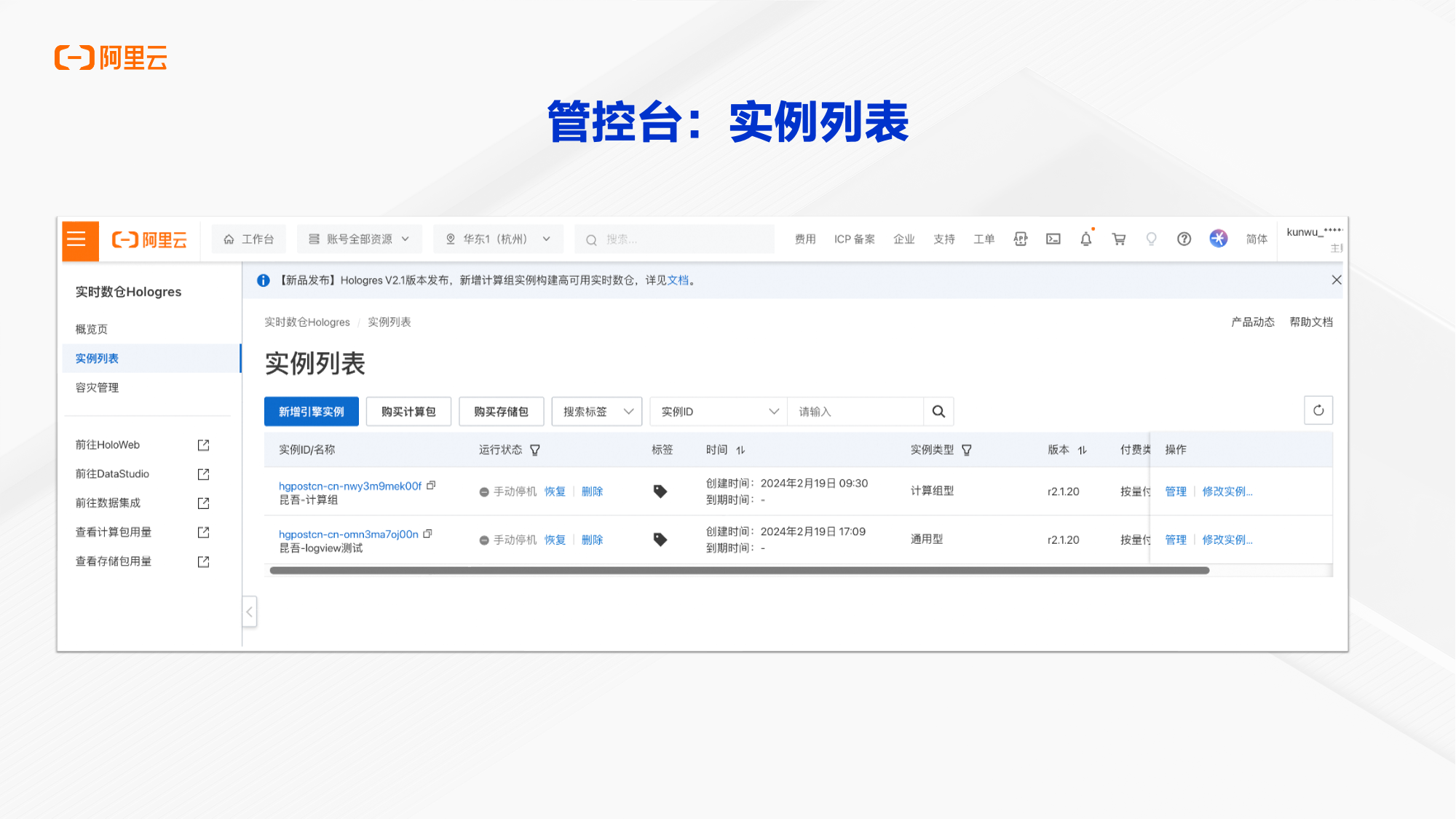

1.2.1监控Metrics
每种类型的实例都提供15个以上的这种监控Metrics。其中包括不同引擎的QPS、RPS、latency, 还有binlog、serverless等等的这些运行情况,以便及时的了解例如任务的负载等等的一些情况。同时也提供锁、analyze等等健康度的指标,可以帮助大家快速的观察业务实例的运行状况以及发现异常,以便出现问题可以尽快去处理。

1.3 连接数据库
支持psql等PostgreSQL生态工具连接实例,同时我们提供了多种工具去开发和管理。 对于开发的场景、调度的场景, 推荐使用DataWorks 中的DataStudio作为开发和运维开发的这种平台。HoloWeb更适合作为运维平台、实例诊断。

1.3.1 创建表
Hologres里面有多种的表的存储格式。Hologres存在两种表,一种叫内表,一种叫外表。
内表
-
列存表:用于服务OLAP查询场景,默认建表类型
-
行存表:用于服务Key / Value查询场景、Flink的维度表场景
-
行列共存表:用于既有点查,又有OLAP查询的场景、非主键点查场景。
外表
-
外表:MaxCompute外表、OSS外表

建表语句示例

Hologres 从第一天起就支持了主键模型,支持主键的去重以及高性能的这种更新场景。建表时就可以设置主键,同时还支持多种存储格式,支持行存、列存、行列共存等等。可以设置聚簇索引 Clustering key 以及 Segment key 分段的键以及 Distribution key,数据会按照 Distribution key 打散数据变成一个分片。还有Bitmap和 字典编码以及数据的生命周期。当然也支持设置表的注释,字段的注释等等。 Hologres是兼容PostgreSQL生态,建表语法与PostgreSQL相同,但是索引与PostgreSQL不同,Hologres支持的索引请参见设置表属性和索引。建表时选择合适的索引,能够使SQL在执行时快速命中数据,减少IO消耗,以更少的计算资源,实现更快的查询性能。下图是一个SQL从发起到获取数据的执行流程,可以通过下图理解每个索引的作用,以方便实际业务中更加方便高效的为表选择合适的索引。
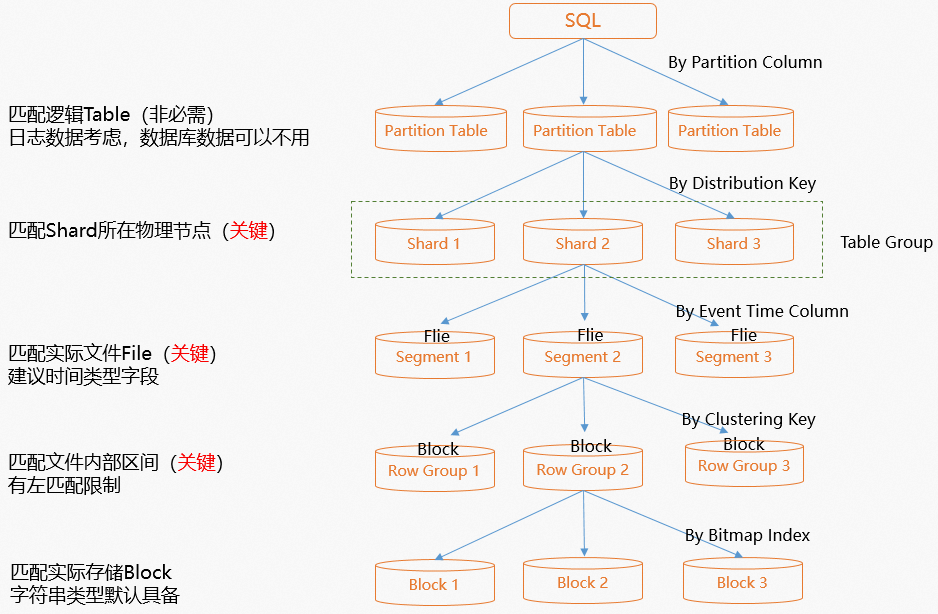
-
SQL执行时,如果是分区表,那么会通过分区裁剪,定位到所在分区。
-
通过Distribution Key快速定位到数据所在的数据分片(Shard)。
-
通过Event Time Column(原Segment Key)快速定位到数据所在的文件。
-
Clustering Key为数据在文件内的排序,可以通过Clustering Key快速定位到所在的文件块。
-
位图索引Bitmap是文件内的索引,可以通过Bitmap快速定位到符合条件的数据所在的行号。
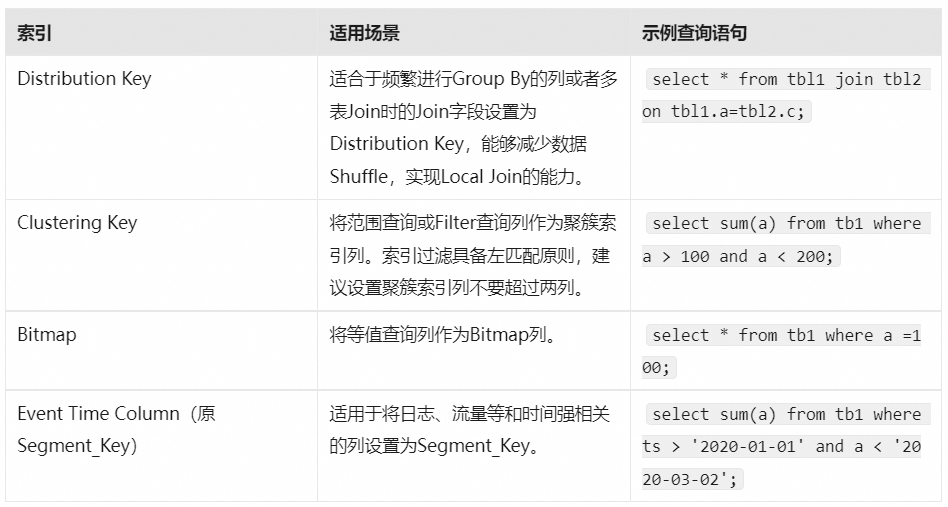
索引适用的场景如下。
数据导入模式其实有多种,例如本地文件的导入,使用 copy 的方式把本地文件导入到对应 DB 的表中。当然也支持 MaxCompute 的外表数据导入的模式。下面列出了在公网 VPC 网络下使用本地文件上传的预估时间,以及使用 MaxComputer 外表上传的预估时间。
1.3.2 导入数据模式
以下为在公网、VPC网络下使用本地文件上传的时间,以及使用maxcompute外表上传的时间。推荐尽量使用在VPC的网络下进行测试,带宽会更高。如果使用公网的话,话费时间会更长,网络也会有更多的抖动,不适合用来做性能测试。

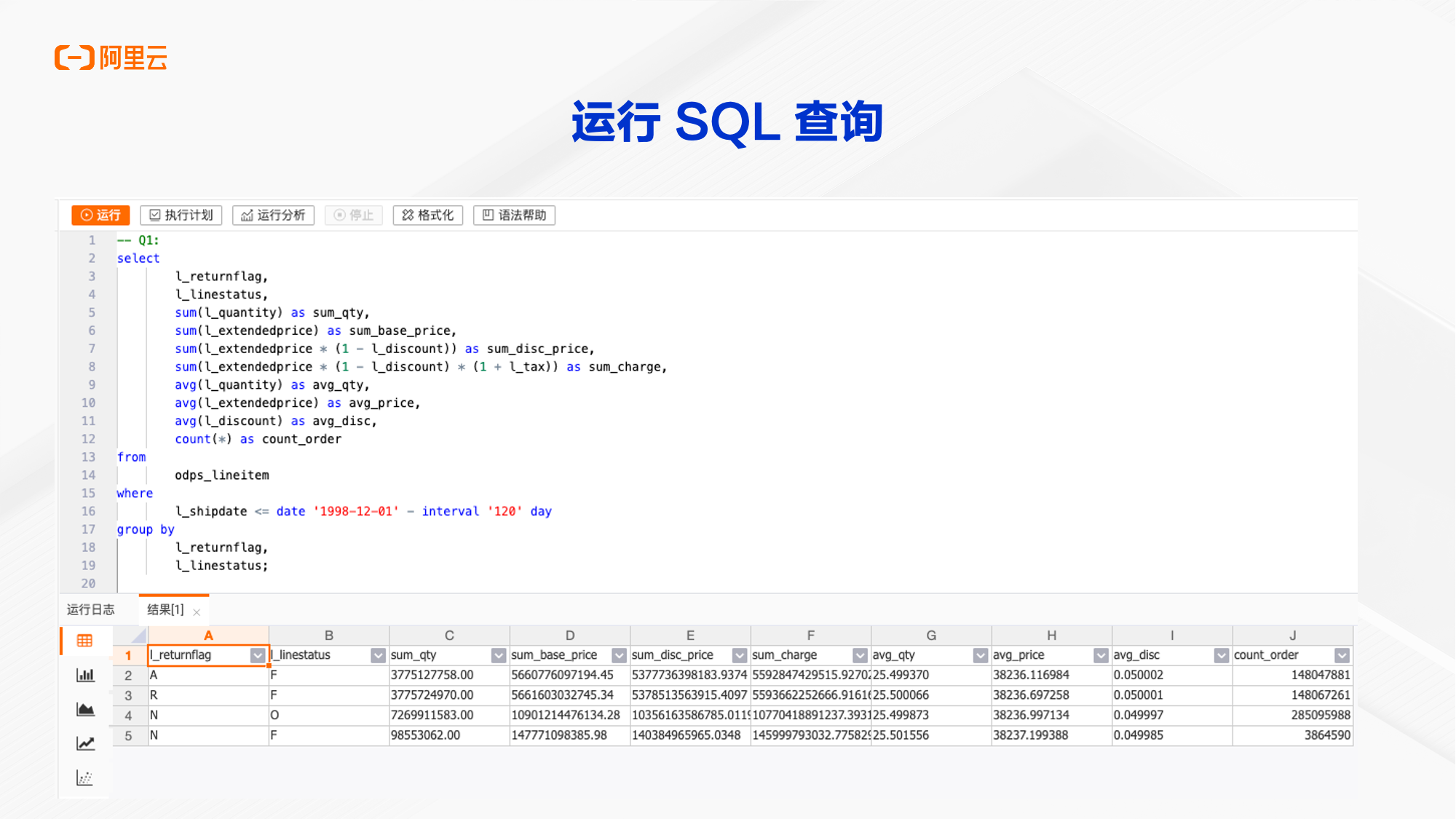
1.3.3运行SQL语句
使用HoloWeb执行SQL语句
图形化执行计划界面,可以有效的帮助我们分析查询中间的瓶颈。节点颜色越深,扫描节点花费时间更多
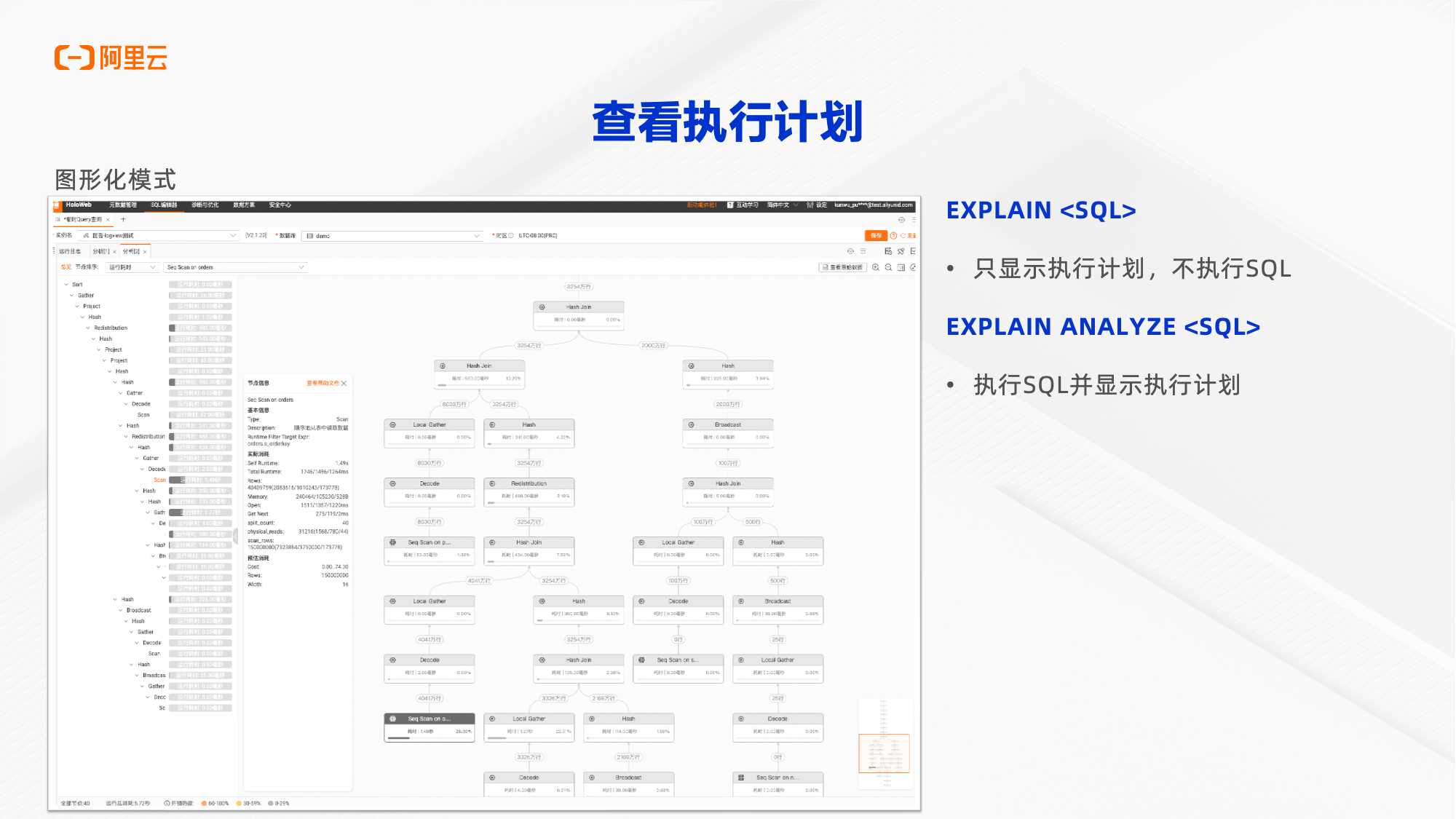
二、测试
2.1 Demo:场景介绍
-
TPC-H书记OLAP场景
-
写入、更新、点差场景压测
2.2Demo: 环境准备
基础环境准备
创建ECS实例,用于客户端测试。建议ECS规格如下:
• 实例规格:ecs.g6.4xlarge。
• 操作系统:Alibaba Cloud Linux 3.2104 LTS 64位。
• 存储:ESSD云盘。
• ECS与Hologres实例需在相同地域,使用相同的VPC网络,并处于同一服务可用区。
创建Hologres实例。
创建测试数据库。
测试工具准备
在ECS实例中安装JDK,详情请参见安装JDK。
在ECS实例中安装psql客户端,yum install postgresql-server -y
下载测试工具holo-e2e-performance-tool,用于写入、更新、点查场景压测
下载测试工具hologres_benchmark_for_tpch,用于TPC-H 数据集场景测试。
将测试工具导入ECS实例
2.3 测试
2.3.1 OLAP测试
-
解压工具包,进入到hologres_benchmark文件夹,编辑group_vars文件
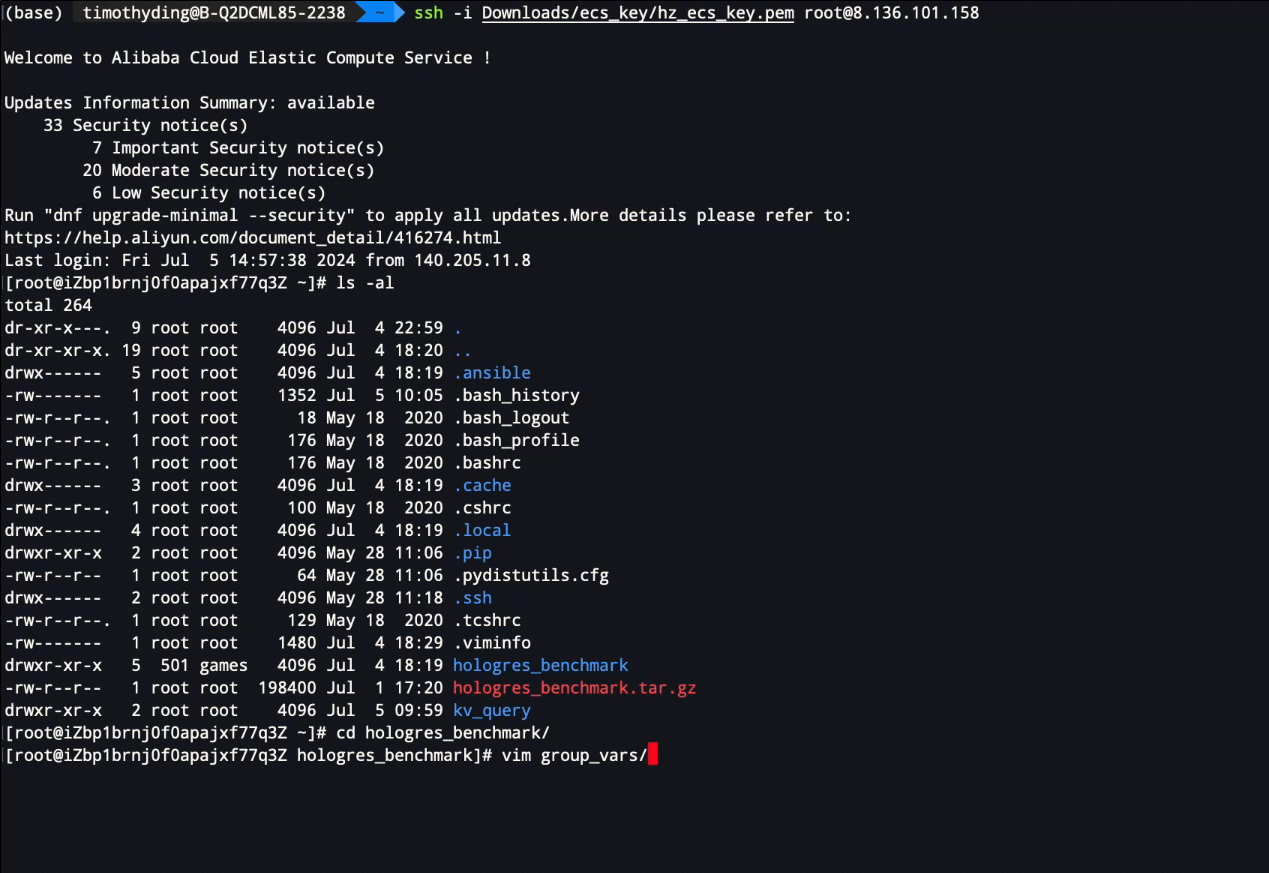
-
填写相关信息

要填几个信息,
-
实例的 VPC 的endpoint,
-
填写账号的AK,以及端口号。
-
需要两个路径用来存放生成的 TPC-H 数据的文件,以及相关的一些工作文件包括生成的SQL、查询的结果等等都会放在该文件夹中。
-
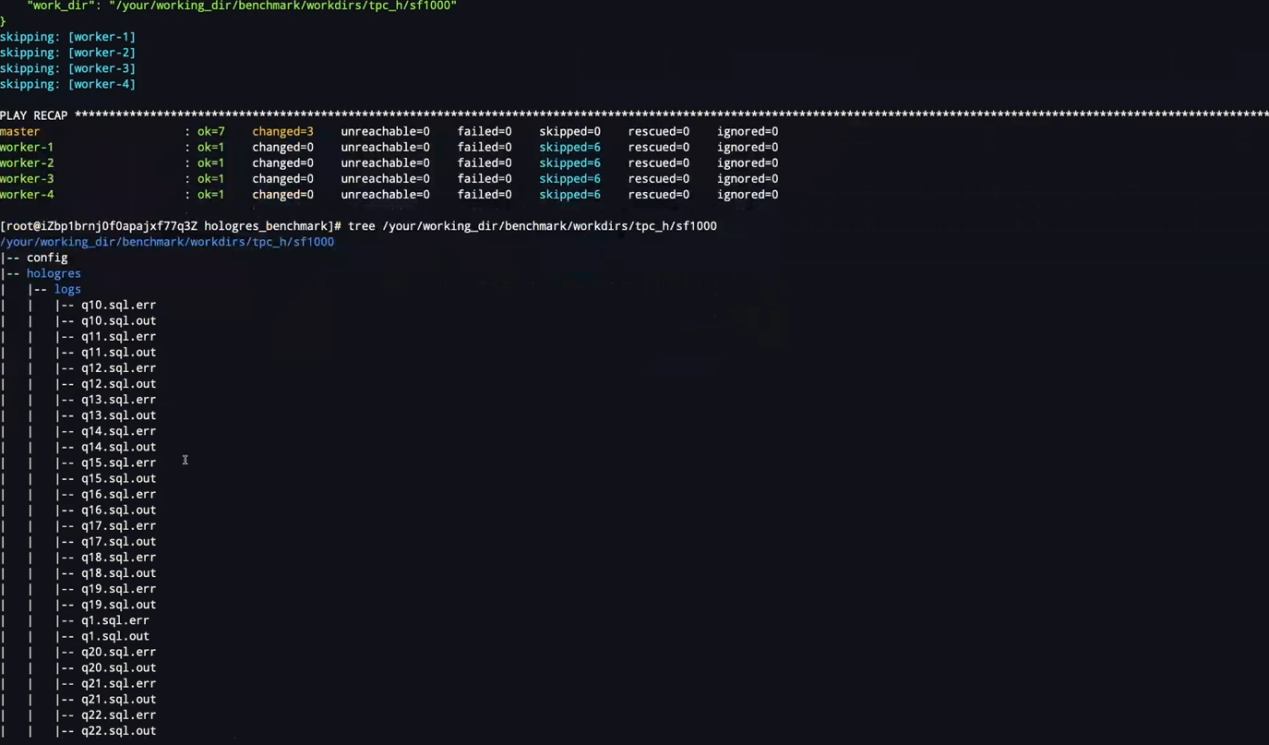
执行bin目录下面的 TPC-H脚本,系统就会默认的开始生成这些相关的数据,并在实例下面创建一个TPC-H数据库
-
执行run_tpch.sh query 会开始运行,进行查询测试,查询为随机生成。运行完毕后会生成一个文件并保存在本地
-
查询结果:会打印每一条查询的时间以及总的running时间。

查询的结果会保存在对应的目录中。
2.3.2 KV查询
-
在官网下载文件包以及官方工具并上传到ECS
-
安装Java的JDK环境、配置文件。配置文件中包括连到的实例,以及用户名,密码,多少个进程等等。表使用fixed copy写入数据,写入完成之后会启动
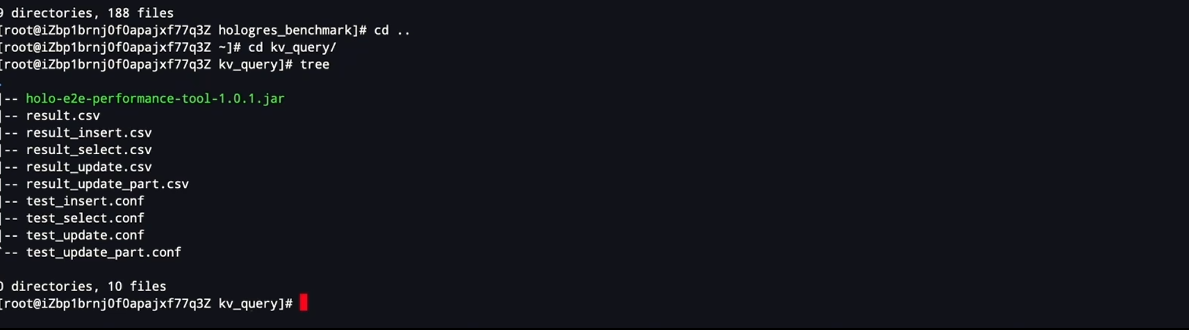
-
查询结果会保存在result文件下,面会有开始时间、结束时间、多少行,QPS,以及平均的这个延迟,P99的延迟等等
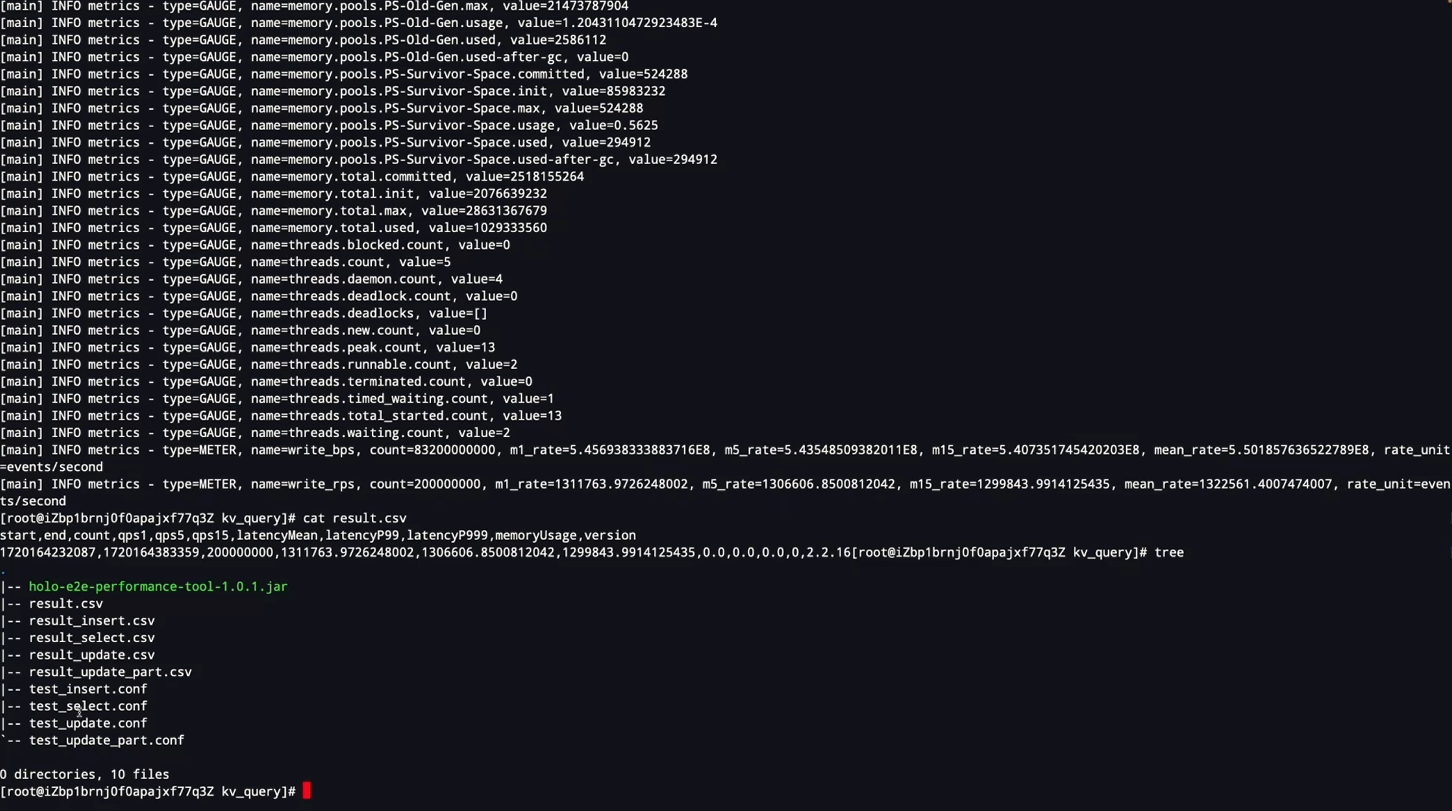
-
其他select 的场景,update 场景和部分更新的场景都类似,按照官方手册上的描述可以直接进行相关的测试。手册上也列出了一些相关结果,例如20 列场景下 64 CU 是什么样的测试结果,例如在 50 列的情况下是什么样的结果,在100 列的情况下是什么样的结果。
2.3.3 后台监控数据
可以在后台监控到各项数据,例如时间、QPS等等。压测时推荐也查看这些信息。

最后进行总结。今天做了两个场景的演示,一个是 OLAP 场景的压测演示,一个是点查场景的压测演示,欢迎大家访问 Hologres 的官网进行了解。






![[玄机]流量特征分析-蚁剑流量分析](https://i-blog.csdnimg.cn/direct/0f13ff0745e04a2680c4a0f505899a93.jpeg)