B站地址
文章目录
- 一、MySQL的系统框架
- 1. 连接池
- 1.1 连接模块
- 1.2 连接池
- 2. SQL接口、SQL解析器、SQL优化器
- 3. 存储引擎
- 二、MySQL数据写入原理
- 三、MySQL存储结构
- 1. 使用InnoDB创建表
- 2. 详述ibd文件中的存储结构
- 2.1 页的数据连续存储
- 2.2 行的结构
- 2.3 区的结构
- 2.4 组的结构
- 2.5 段的结构
- 四、数据是如何被查询的呢?
- 1. 查询缓存
- 2. SQL解析器
- 2.1 词法分析
- 2.2 语法分析
- 3. 预处理器
- 五、数据页结构详解
- 1. 页头File Header
- 2. 页尾File Trailer
- 3. 数据行
- 5. 页目录
- 六、行结构
- 1. 真实数据区
- 2. 额外信息区
- 七、索引
- 八、所有数据页映射到B+ Tree上
- 九、聚簇索引与非聚簇索引
- 1. 聚簇索引
- 2. 非聚簇索引
- 3. 聚簇索引与非聚簇索引的合作查询
一、MySQL的系统框架
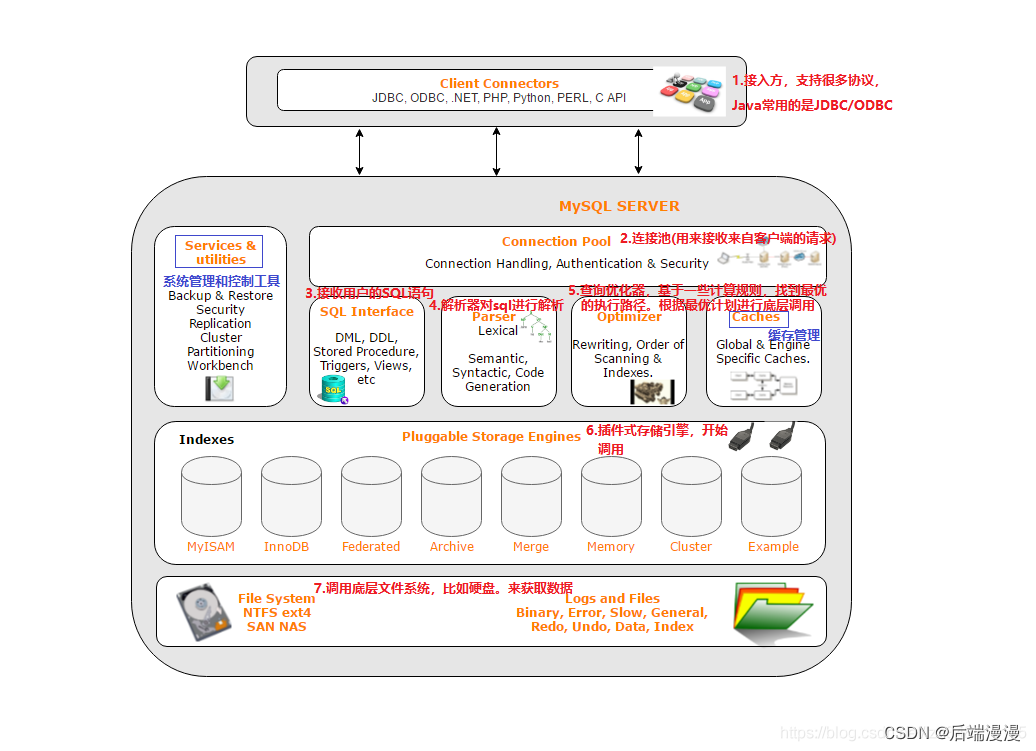
1. 连接池
1.1 连接模块
MySQL说:专门负责和我程序猿大哥们交流的是“连接模块”,程序猿大哥们通常使用一种叫“客户端连接驱动”的东西连接到我的体内。一旦对接成功就会,那我体内所保管的数据将会毫无保留的贡献给我大哥。但是程序猿大哥会频繁的和我产生对接,身体单薄的我在对接断开、对接断开的反复折磨下,已经不堪重负了。在痛定思痛后,终于进化出了一个叫“连接池”的器官

1.2 连接池
MySQL说:这个“连接池”可以让我和大哥的对接保持一段时间,不会快速断开,而可以反复利用。这个连接池的器官就成为了我与外界连接的唯一门户。这个器官非常注重自我保护,所以它构建了很多自我保护的参数,其中最重要的两个参数
# 最大连接数
SHOW VARIABLES LIKE 'max_connections';
# 设置max_connections
SET GLOBAL max_connections = 1000;
# 单次最大数据报文
SHOW VARIABLES LIKE 'max_allowed_packet';
# 设置max_allowed_packet
SET GLOBAL max_allowed_packet = 8388608;

2. SQL接口、SQL解析器、SQL优化器
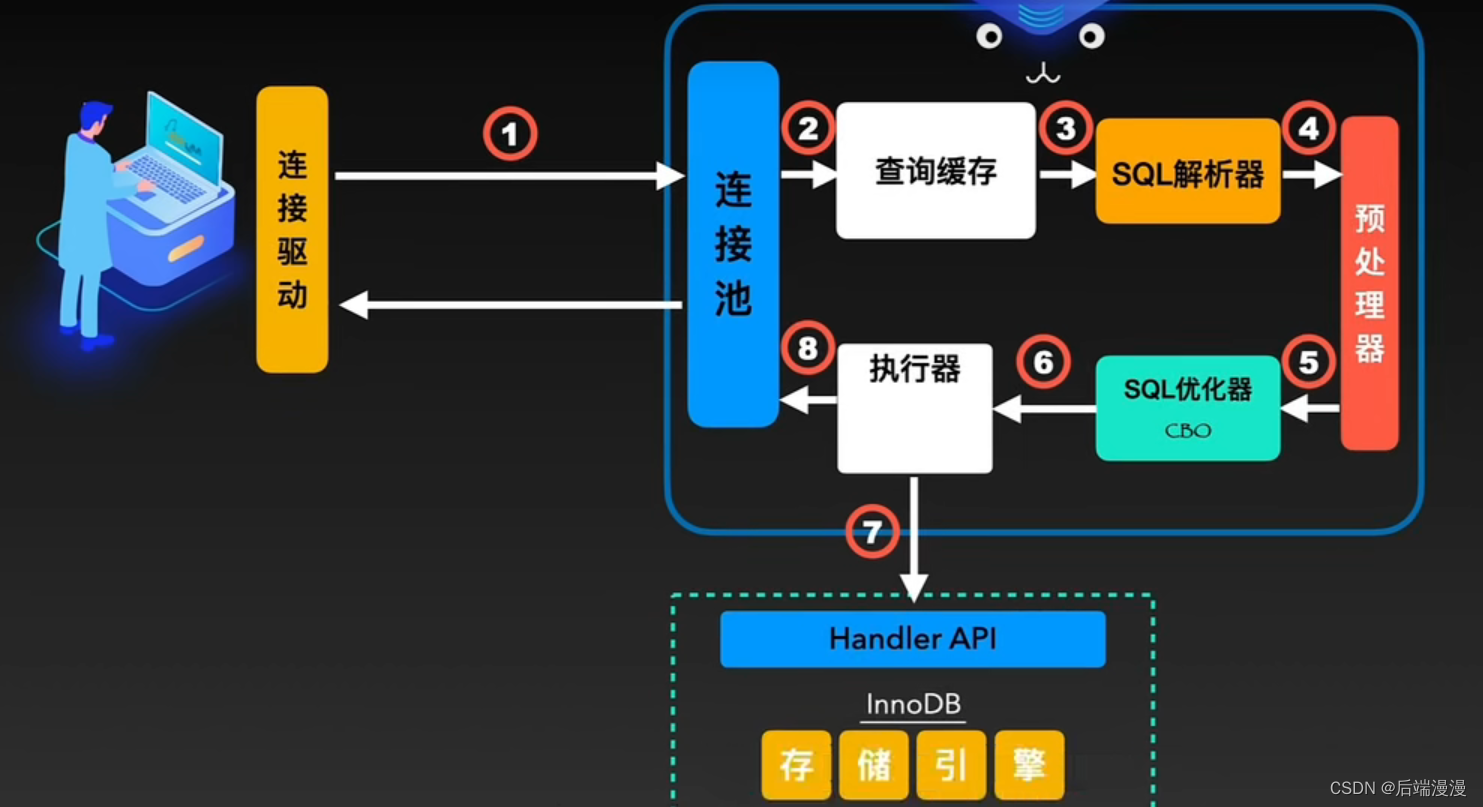
MySQL说:程序猿大哥会通过“连接池”和我建立连接,然后给我发送SQL语句,SQL接口接收了SQL语句,SQL解析器会解析SQL语句,如果我发现了SQL语句错误就会通过SQL接口把错误的信息告诉程序猿大哥。之后SQL优化器就会根据MySQL自身情况、体内数据以及索引等信息来选择最优方案重组SQL,让其达到最大效率
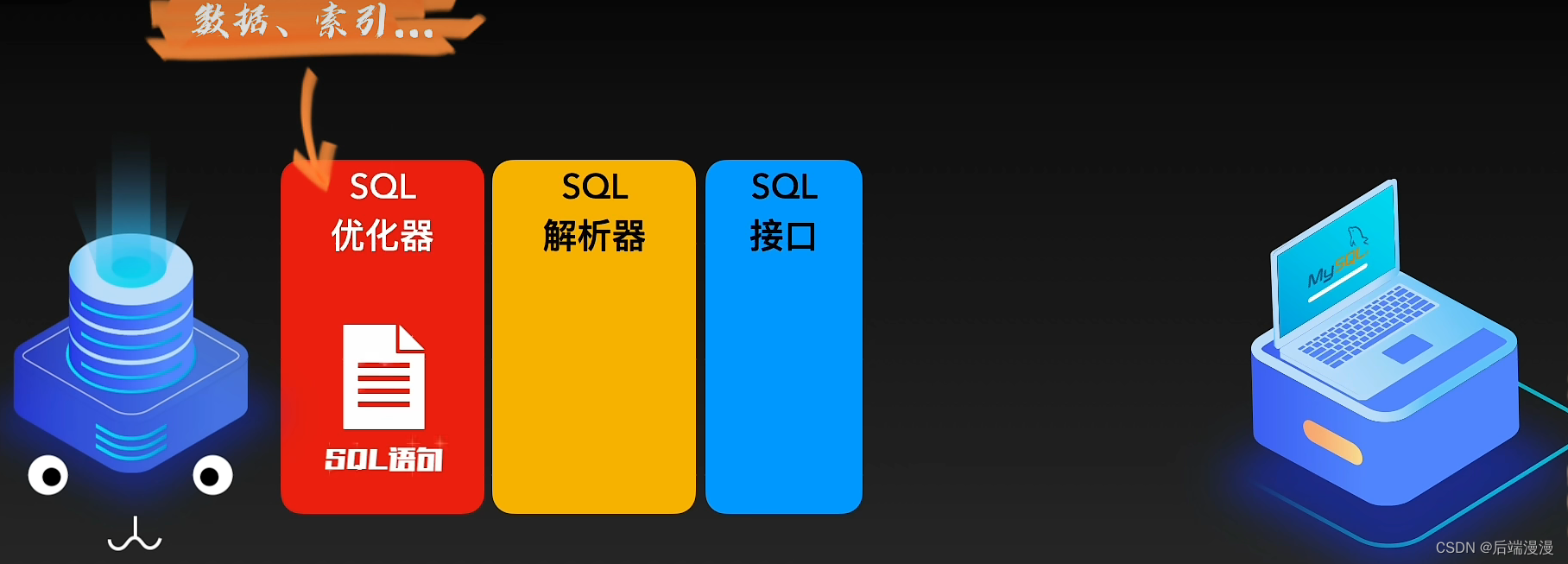
3. 存储引擎
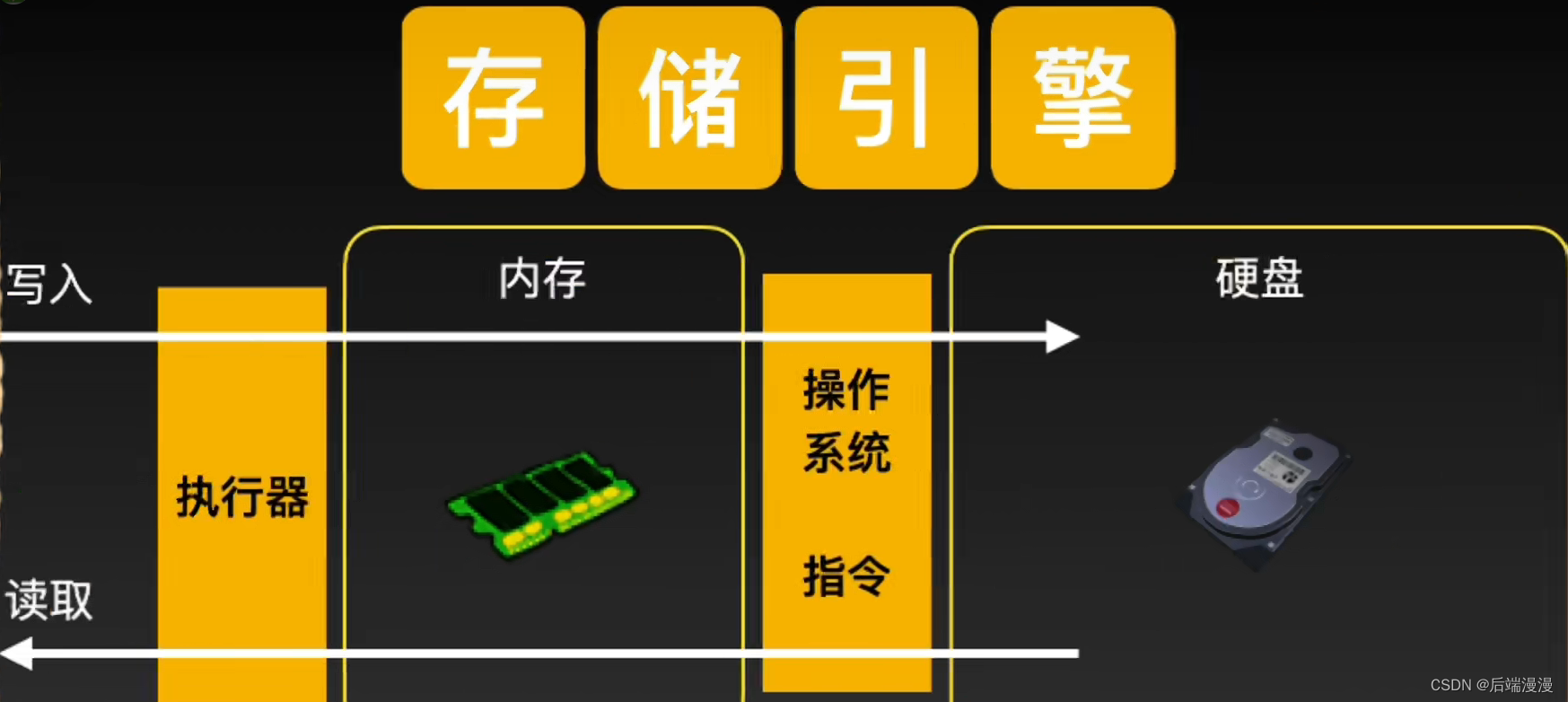
MySQL说:存储引擎就像是我的大脑,会负责处理“SQL解析器”优化后的SQL执行计划,对我体内的数据进行写入或读取。和人类大脑不同的是,我
的大脑可以根据程序猿大哥的不同场景,做不同的选择。其中InnoDB作为默认的存储引擎。下面是存储引擎的内部结构
二、MySQL数据写入原理
MySQL说:MySQL深深地知道一切的逻辑处理和读取写入都只操作内存中的数据,这个内存缓存区被称为Buffer Pool。InnoDB会把它需要写入的数据插入或更新到Buffer Pool中。
MySQL说:当然,为了能够让已经写入的数据支持回滚,就需要在这之前将数据的旧值记录到另一个地方,那就是Undo Log文件。
MySQL说:将数据写到Buffer Pool内存之后,InnoDB就会让它的小线程们在一些特定的时机从内存中把需要更新写入的数据读出来,同时写入磁盘。
MySQL说:一旦MySQL断电或者服务挂掉睡着,那么处在内存区Buffer Pool中的数据就会随着内存失效而永久丢失。为了应对这种突发情况,我的大脑InnoDB研发了一套redo Log体系。这套体系在数据进入Buffer Pool之后会将“更新写入信息”放入内存的另一个区域Redo Log Buffer,然而光写入内存也无法解决刚才的问题,为了保险起见还是要把它刷到磁盘中。我的InnoDB提供了多种Redo Log的刷盘机制。
# 将“更新写入信息”写入到操作系统Page cache和Redo Log Buffer,并立刻刷新到磁盘中
innoDB_flush_log_at_trx_commit = 1;
# 将“更新写入信息”写入到Redo Log Buffer,每隔一秒钟才进行系统内存放入和刷盘操作
innoDB_flush_log_at_trx_commit = 0;
# 将“更新写入信息”写入到操作系统Page cache和Redo Log Buffer,每隔一秒钟才进行系统内存放入和刷盘操作
innoDB_flush_log_at_trx_commit = 2;
MySQL说:上述一系列操作都集成在MySQL内存,我的程序猿大哥是不能直接操作的,当我的程序猿大哥执行了错误的SQL语句就不能回复如初的。为了帮程序猿大哥解决这个问题,我进化出了Bin Log文件。它可以给程序猿大哥提供变更历史查询、数据库备份和恢复、主从复制等功能,我会在Redo日志写入的同时,对Bin Log进行刷盘操作,在Bin Log刷盘成功后,我会告知Redo日志事务“已提交”这个信息,Redo日志也会打入commit标志。
这样,一次数据写入的流程就完成啦。
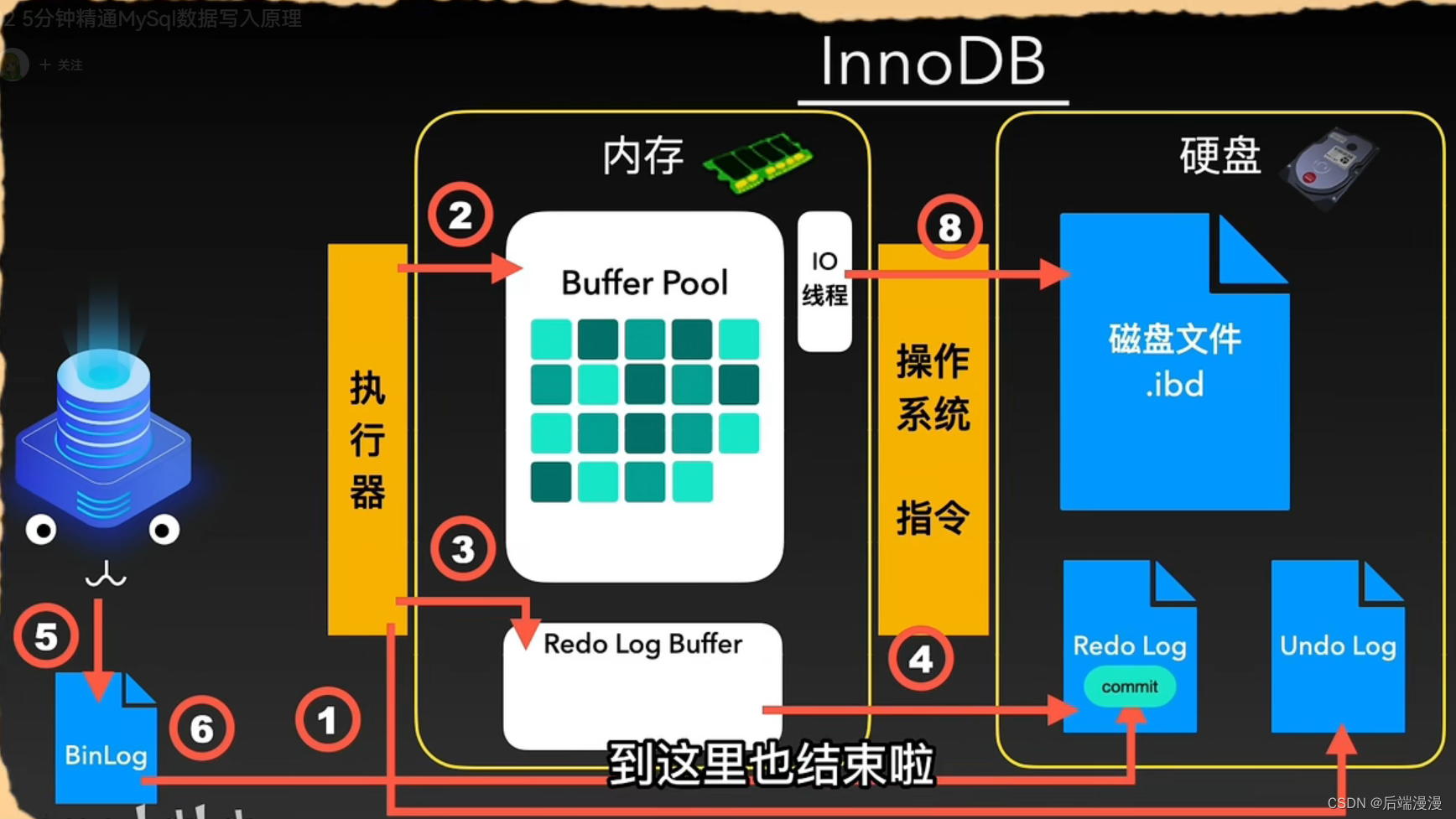
提问:既然为了防止断电,redolog会立刻写入硬盘,那为什么不干脆直接将buffer pool中的数据写入硬盘呢?
一个事务可能包含多个语句,数据不太可能都连续,从bufferpool刷盘就需要大量磁盘io,性能很低。而redolog日志本身不记录真实数据而是一些偏移量、页号之类的很小,刷盘机制也都是顺序io,所以效率高。
三、MySQL存储结构
参考B站视频:总体概括
参考B站视频:详细讲解
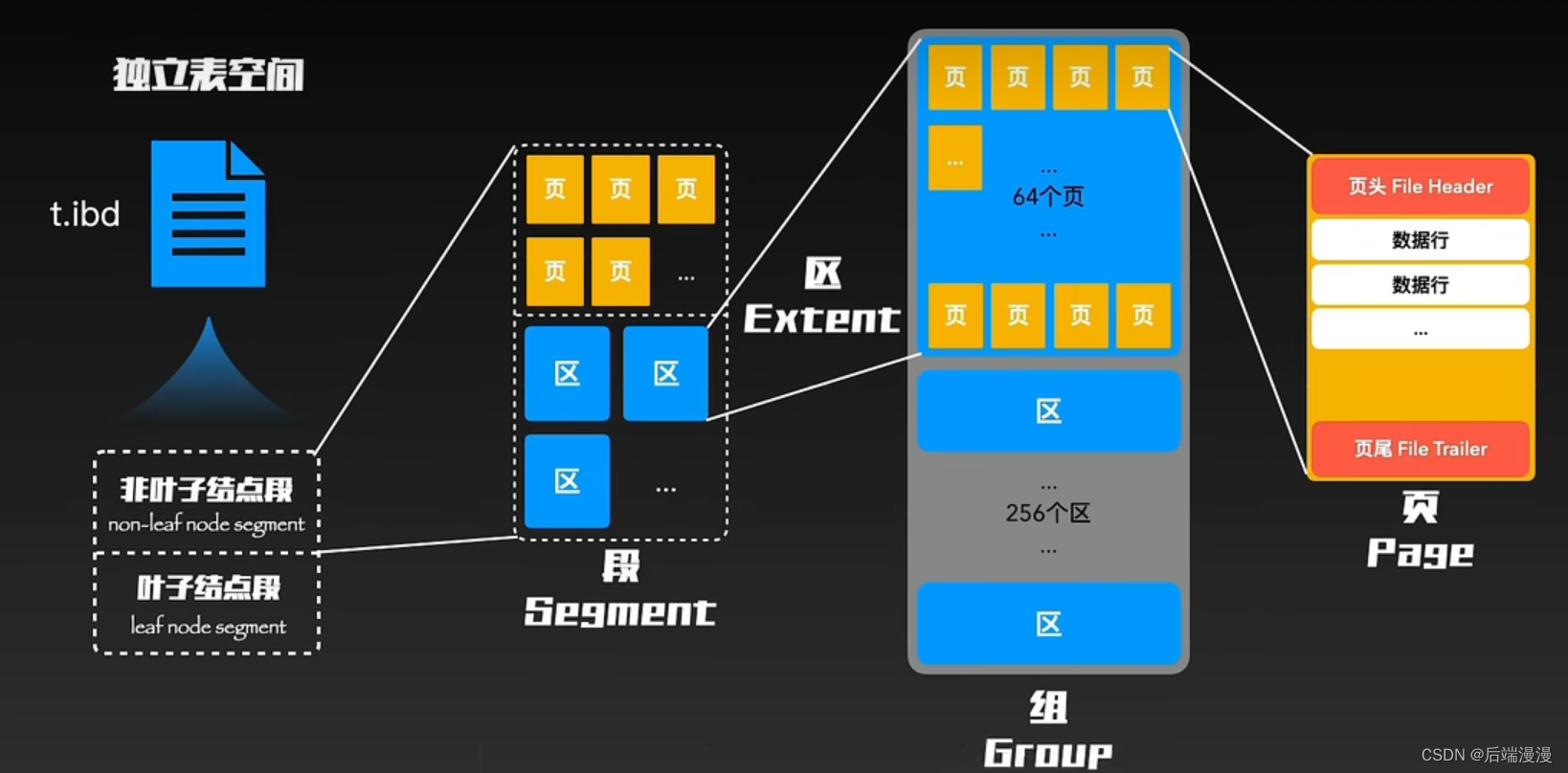
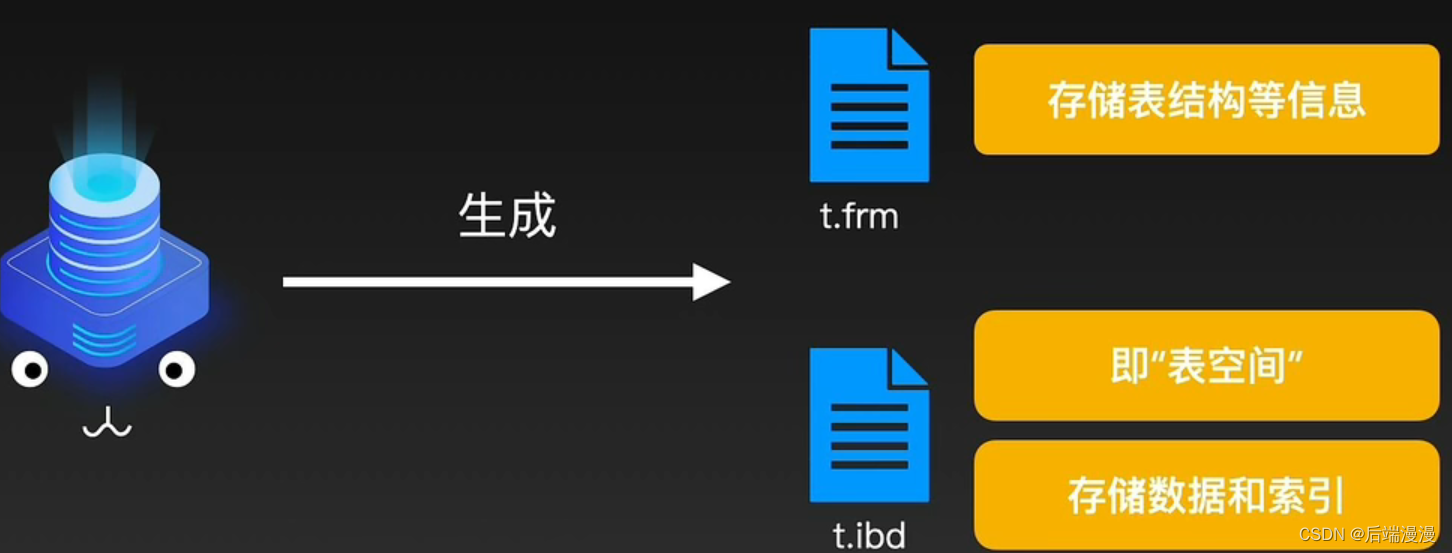
1. 使用InnoDB创建表
MySQL说:在使用InnoDB创建表时候,会生成两个文件,.frm和.ibd文件。特别的,只有在我5.7版本之后,InnoDB才会为每个表生成一个ibd文件,称为独立表空间,在此之前所有表的数据和索引都会存储在“系统表空间”中,因此“系统表空间”也称为“共享表空间”,即所有表共享一个物理表空间文件。(InnoDB有五类表空间)
MySQL说:可以通过全局参数innodb file per table来进行设置,控制是否为每个表独立创建ibd文件
# 开启每个表都创建表空间文件
SET @@GLOBAL.innodb_file_per_table = ON;
#查看每个表都创建表空间文件状态
SHOW VARIABLES LIKE 'innodb_file_per_table';

2. 详述ibd文件中的存储结构
2.1 页的数据连续存储
MySQL说:从磁盘中读取一段连续的数据放入内存,后续的查询大概率就可以直接从内存中找到(空间局部性原理),这样就通过减少了磁盘的访问次数,大大提升了访问效率。
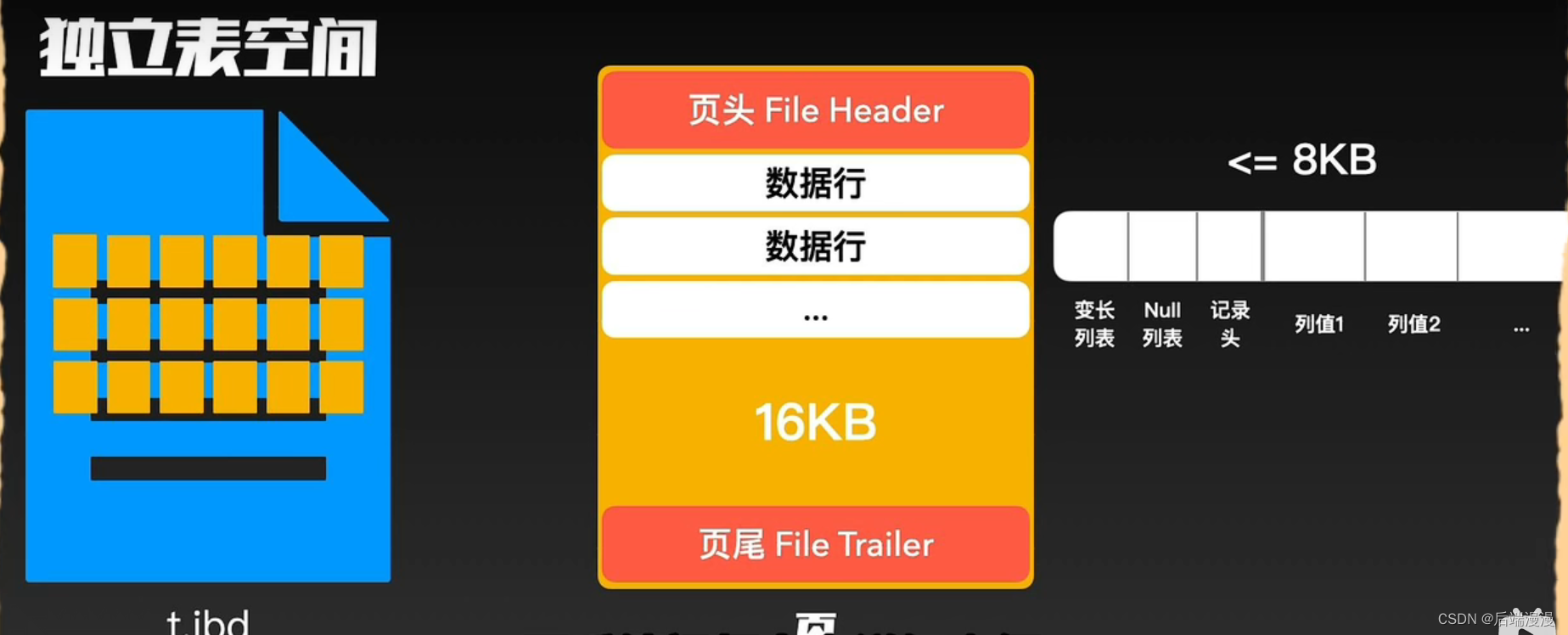
MySQL说:页的大小默认为16KB,同时与我们熟知的B+树中节点对应。
MySQL说:不同的场景会使用不同的页,不同的页也会有不同的结构,当然它们都包含页头和页尾,介于这两种之间的主体信息会根据不同类型有不同的结构。最为常用的就是用来存储数据和索引的索引页。

2.2 行的结构
MySQL说:数据行内部主要包括表里某一行的真实数据和一些额外信息,最大为8KB。
2.3 区的结构
MySQL说:当程序猿大佬的业务量暴增的时候,跨页读取(数据在不同页,离需要从离散的存储空间内获取数据)那就再平常不过了。如果页之间的距离过大,那多份数据在磁盘中很有可能不在同一个磁道。为了读取数据就会发生磁头移动。这种移动是物理摆动,相比磁片每分钟几千上万次的旋转读取要缓慢的多,所以磁头移动会大大降低性能。为了减少磁头移动,我体内进化出了一个叫做“区”的结构。
MySQL说:每个区默认为1M,即存放64个地址连续的页。这样的话,即使是跨页读取数据,大概率也是在附近的地址,即数据大概率在同一条磁道,很少出现磁头移动。与此同时,如果频繁读取这个区的页,那么我们可以把整个区都读取出来放入内存中。
MySQL说:当程序猿大哥创建新表时,我也不知道这个表的数据量级,为了不至于一次性占用过大的磁盘空间而导致浪费,所以我在新建表时,只会创建6个页(连续存放),而不是一个完整的区,共占用6*16=96KB大小。这6个页存放在“碎片区”的地方。其中前4个分别记录了表空间和区组条目信息、Change Buffer相关信息、段信息、索引根信息
MySQL说:当我大哥们要存储的数据越来越多,6个初始页空间已经不够用了,就需要一个一个的新增“页”来满足存储需求。直到我们构建了32个零散页之后,后续每次都会直接申请完整的区。
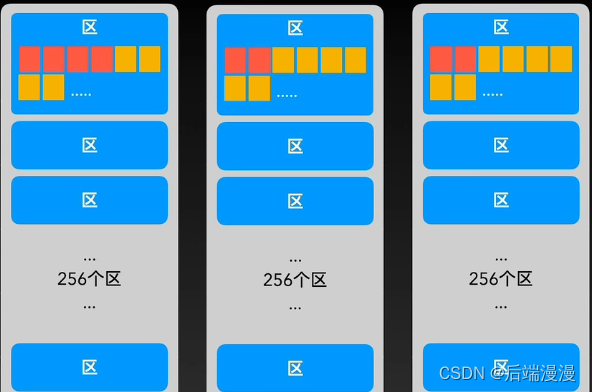
2.4 组的结构
MySQL说:为了有效管理区,我又进化了“组”结构,每个组默认为256区。
2.5 段的结构
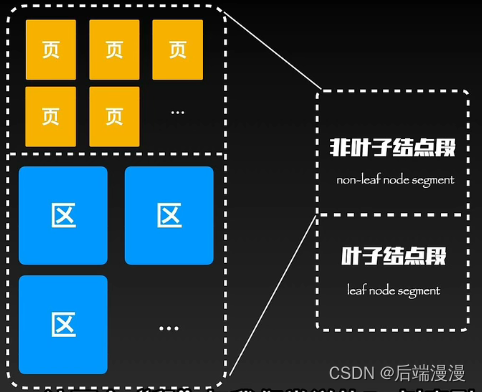
MySQL说:段属于一个逻辑结构,主要作用是区分不同功能的区和在碎片区中的页,分为叶子结点段和非叶子结点段。这两个段与我们常说的B+树索引中的叶子、非叶子结点相对应。
MySQL说:“非叶子结点段”存储和管理索引树,“叶子结点段”存储和管理实际数据
MySQL说:最终由“叶子结点段”和“非叶子结点段”构成了最终的表空间ibd文件
四、数据是如何被查询的呢?
1. 查询缓存
MySQL说:查询缓存在5.7版本里是默认关闭的,可以通过query cache type参数查看和设置。
# 查询缓存开关
SHOW VARIABLES LIKE 'query_cache_type';
# 设置缓存开关
SET query_cache_type = 0;
#query_cache_type=2时,代表按需使用,用SQL_CACHE对某表开启缓存
SELECT SQL_CACHE * FROM test;
MySQL说:到了MySQL8.0,整个缓存都删除了,为什么官方都不建议使用这个看上去还不错的功能呢?首先每次进来查询都要经过查询缓存,加上每次查询条件不同,导致命中率低,那就非常消耗性能了。其次在没有命中缓存,那就要创建新的缓存,也会造成一定的消耗。最后,为了保证数据一致,会添加表级锁,当表内数据更新后需要将这个表对应的缓存均设为失效,又是一波不小的消耗。综上所述,很多情况下“查询缓存”并不能为我们带来实质的效率提升。(最终原因就是缓存命中率低)。
2. SQL解析器
2.1 词法分析
MySQL说:通过sql/sql_lex.cc代码将SQL语句切分为各种Token词,通过其中一个定义了各类关键字、操作符的数组symbols[]进行关键字、非关键字的标记。

2.2 语法分析
MySQL说:使用bison这个语法分析器,通过sql/sql_yacc.cc规则代码将语句解析为一个语法树。
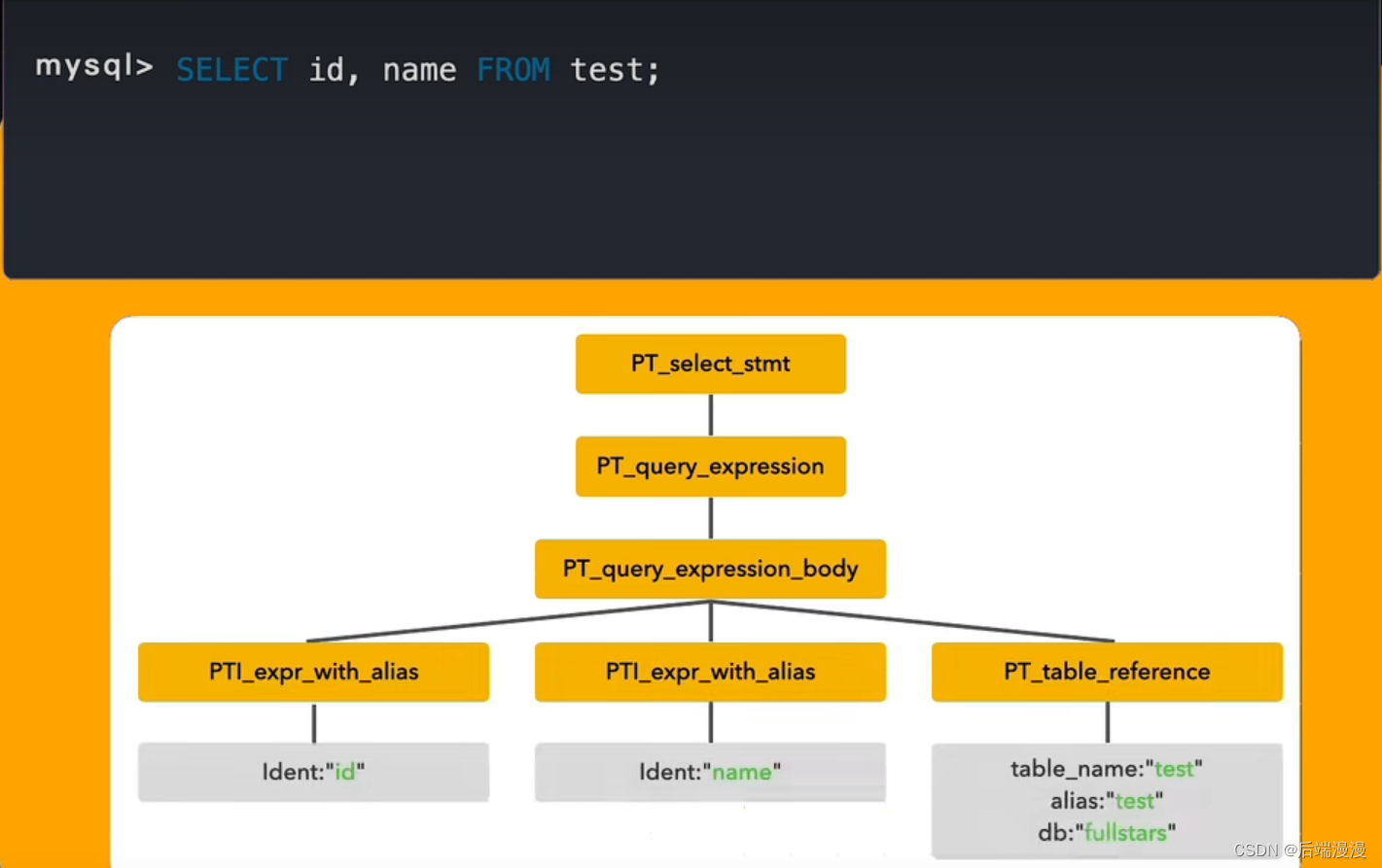
3. 预处理器
MySQL说:预处理器将请求进行拆分,先提交SQL模板语句,然后再提交参数并进行执行。通过这种方式,对于重复执行的语句来说,可以提交并处理一次模板即可,然后不断的提交参数就可以实现多次执行,从而提高执行的效率。
五、数据页结构详解
MySQL说:我的大脑InnoDB为了应对各种场景划分了不同类型的页,每种页的数据结构都不相同。其中最需要我们关注的莫过于数据页。
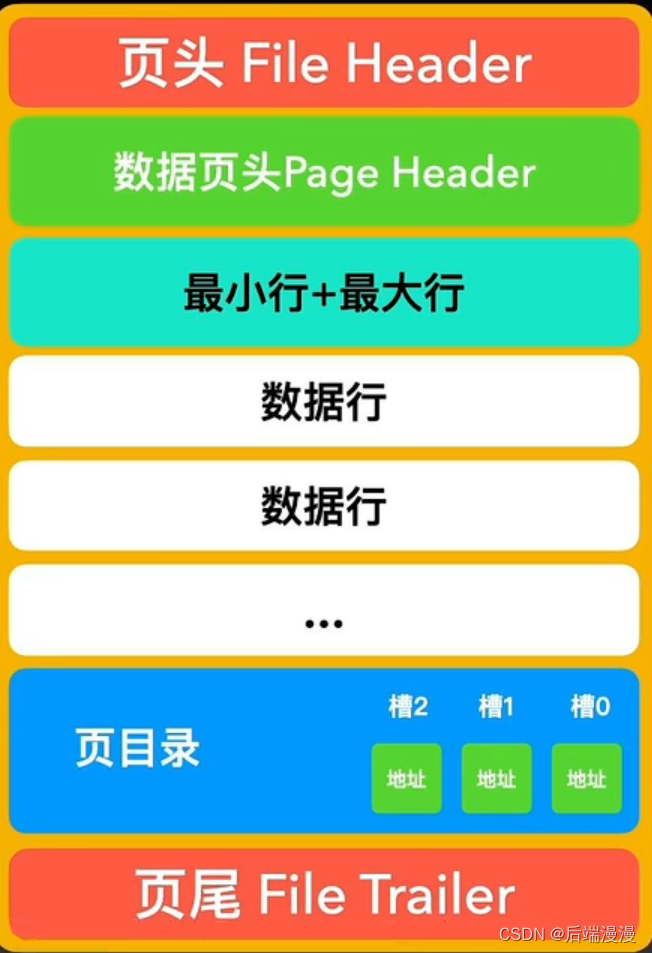
1. 页头File Header
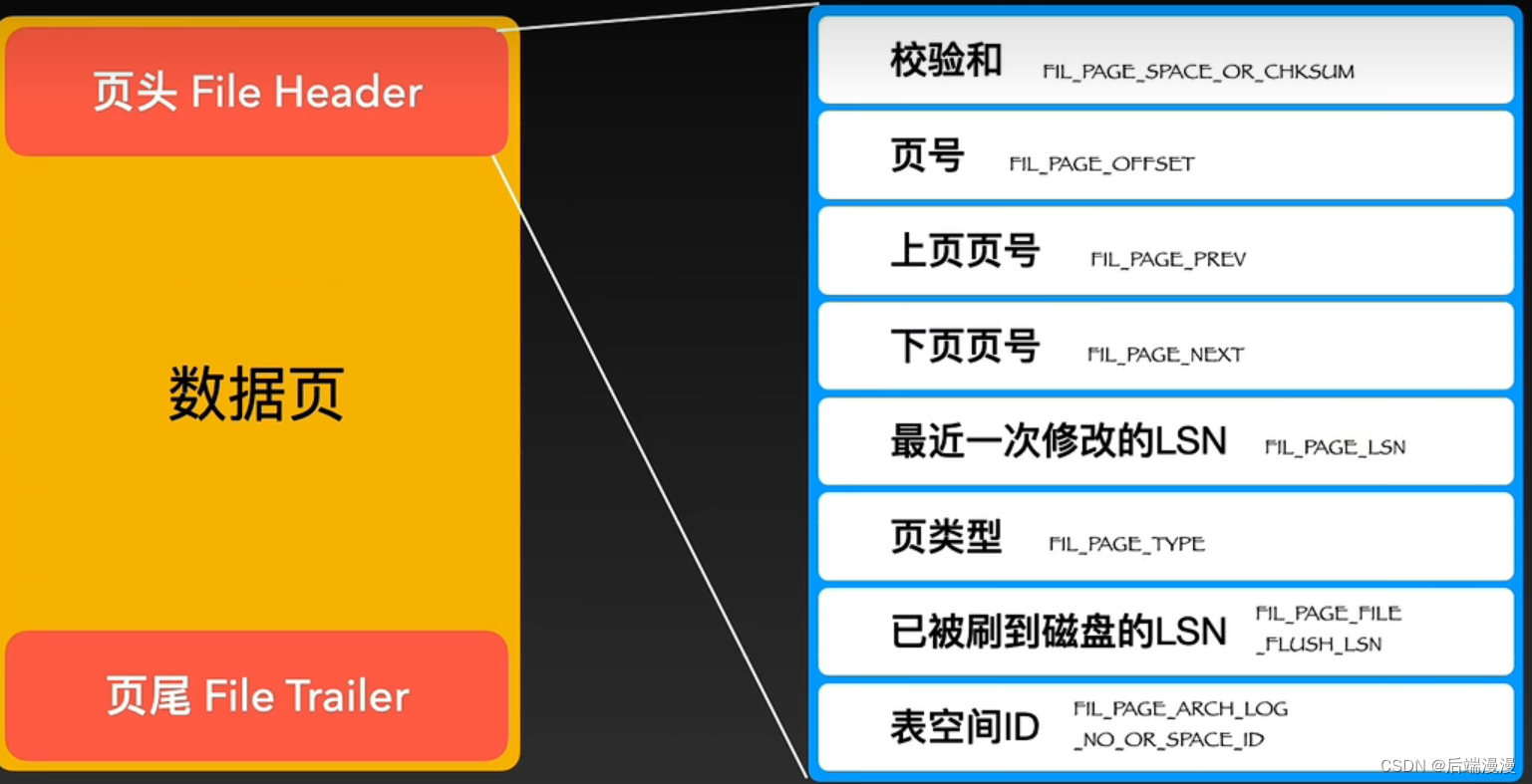
2. 页尾File Trailer
MySQL说:页头和页尾的校验和相对应,由于我们的操作系统传输单元数据块通常是4KB,一个页是4个数据块。如果碰到我断电的情况,那么一些不走运的页,可能只传输了一两个数据块,并没有完整传输,这种不完整就需要用页头和页尾的校验和通过一些验证算法进行验证。默认使用crc32.
磁盘数据交换的基本单位(数据块)是4KB,一个数据页包含4个数据块,为16KB

3. 数据行
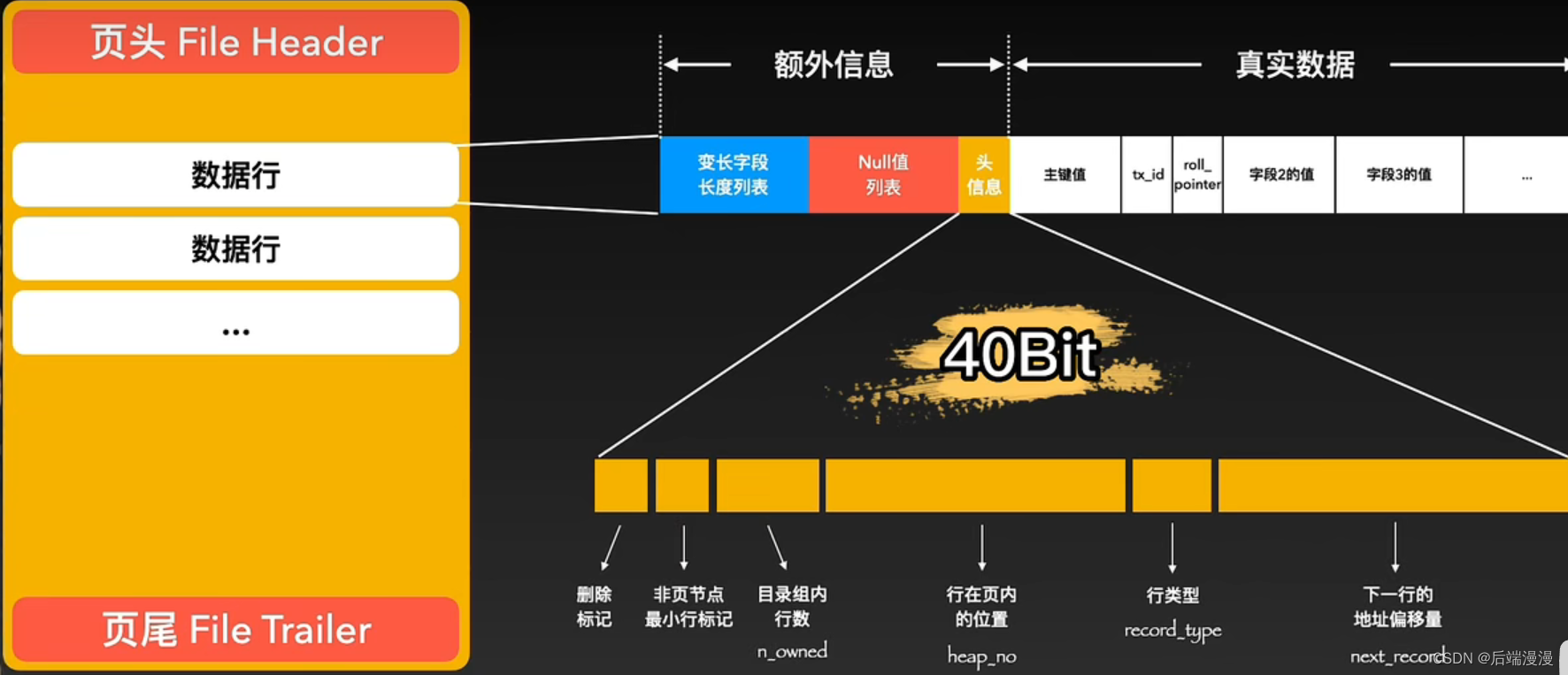
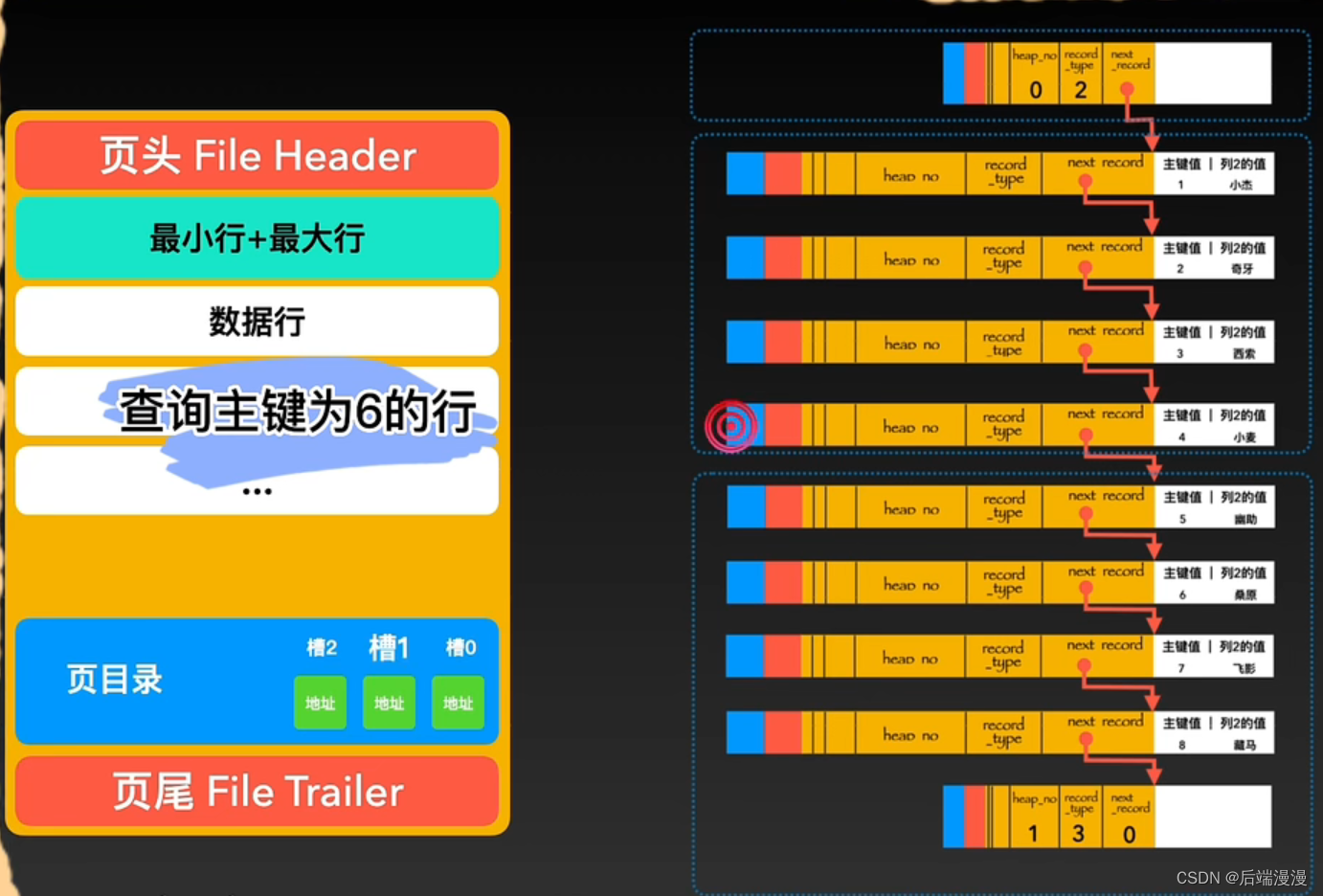
MySQL说:下一行的地址偏移量指向的是下一个行中真实数据的起始地址
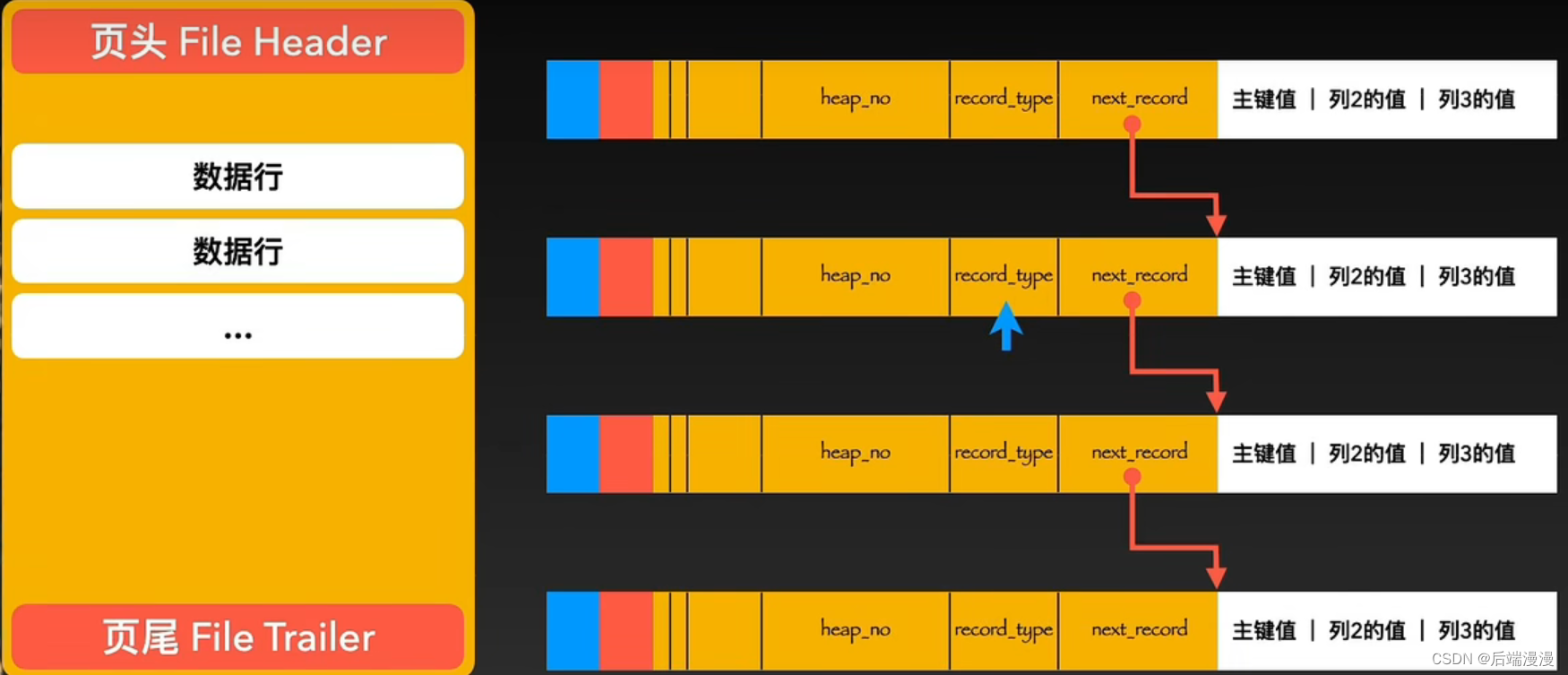
MySQL说:每当我体内创建一个新页,都会自动分配两个行。一个行类型为2的最小行Infimum,固定在0号heap_no位置。一个行类型为3的最大行Supremum,固定在1号heap_no位置。这两个行并不存储真实的信息,而是作为数据行链表的头和尾。
MySQL说:当我插入一个新的数据时,会从2号heap_no位置开始占据。如果是真实数据则record_type为0,如果是索引目录数据则record_type为1。然后根据单链表的规则来插入。 更多的行数据插入后会将其按照主键从小到大的顺序进行链接。
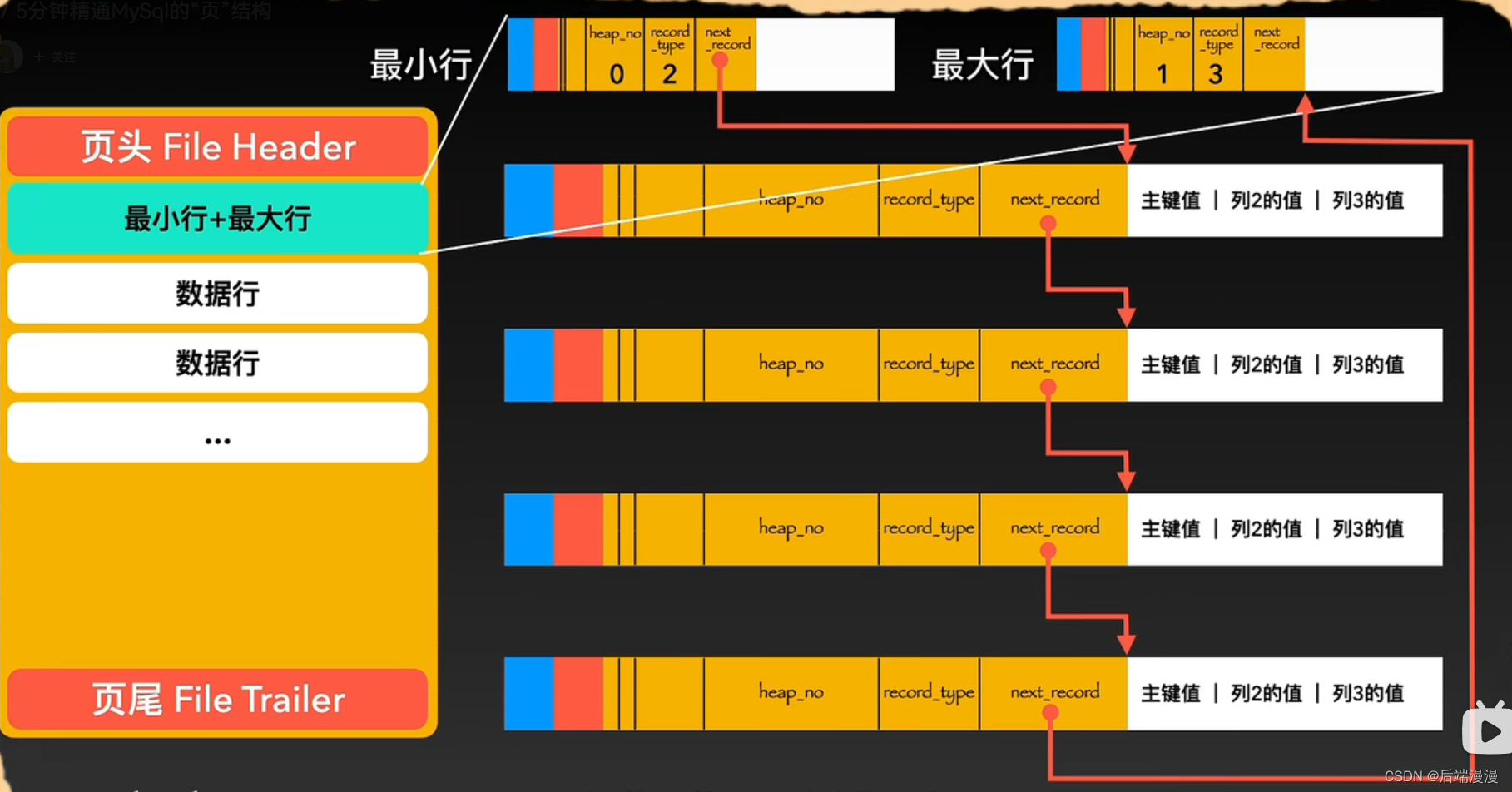
5. 页目录
MySQL说:当程序猿大哥想要查询数据时,需要沿着链表顺序一个个比对查找,这样显然是不行的。所以我进化出了一个页目录的器官,它会将页内包括头行、尾行在内的所有行进行分组,约定头行为单独为一组,其他每个组最多有8条数据。同时把每个组最后一个行在页中的地址,按照主键从小到大的顺序记录到页中,这个区域叫做页目录,页目录的每一个位置称为一个槽,每个槽对应一个分组。
MySQL说:在页目录中根据二分法查找到组,再在组里面遍历八个数据行即可找到。
六、行结构

MySQL说:数据行有4种格式:DYNAMIC,REDUNDANT,COMPACT,COMPRESSED,默认为DYNAMIC,可以通过innodb_default_row_format进行查询和变更。
1. 真实数据区
MySQL说:第一个就是主键位置,如果是复合主键,那也会依序排在这里。如果没有主键,就会优先用一个NOT NULL、UNIQUE的列作为主键,如果这个都没有的话,我的innoDB就会构建一个6B的DB_ROW_ID字段存储在这里。
MySQL说:紧接着是6B的事务ID字段DB_TX_ID,7B的回滚指针字段DB_ROLL_PTR
MySQL说:继续向右就记录除了主键和值为null的列之外的真实数据了,因为值为null的列会用其他方法表示,目的就是为了节省空间。
2. 额外信息区
下一行:下一个数据行真实数据的地址。
行类型:0代表普通数据行,1代表索引目录行,2是最小行,3是最大行。
位置:用13bit的heap_no来标记该行在整个页的位置
组行数:如果这个行是分组的最后一行,则在这里标记该组的行数
每层最小:不懂,但是在后面视频有详细讲解
删除标记:在删除数据行时并不会直接移除,而是修改这个标记。同时将这行的next_record指向一个称为垃圾链表的地方,这个链表会用于事务回滚。
NULL值列表:用来记录值为NULL的列,根据列的个数来开辟合适的长度。
可变字段长度列表:记录了数据行里所有变成字段的实际长度。
七、索引
在我的另一篇博客已经讲解得很清晰了,请读者移步
八、所有数据页映射到B+ Tree上
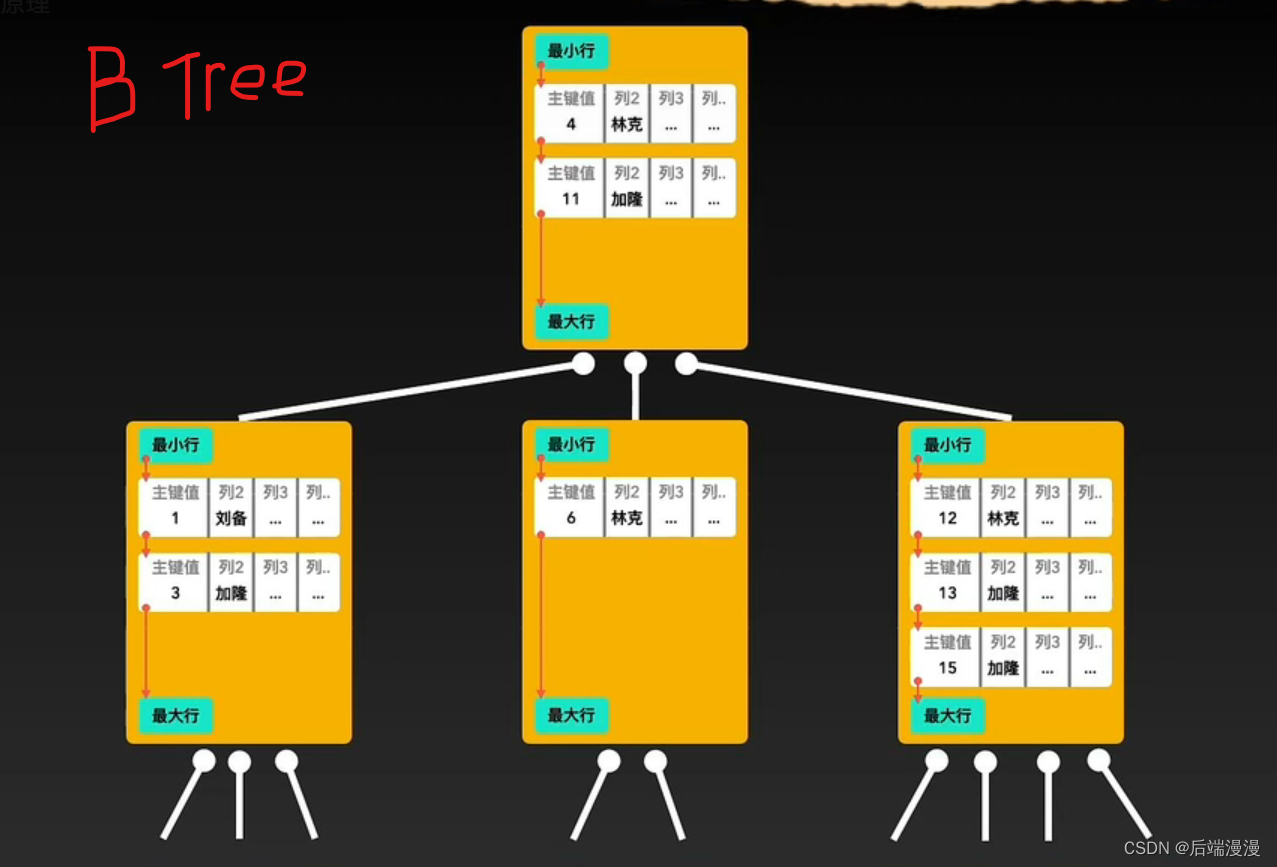
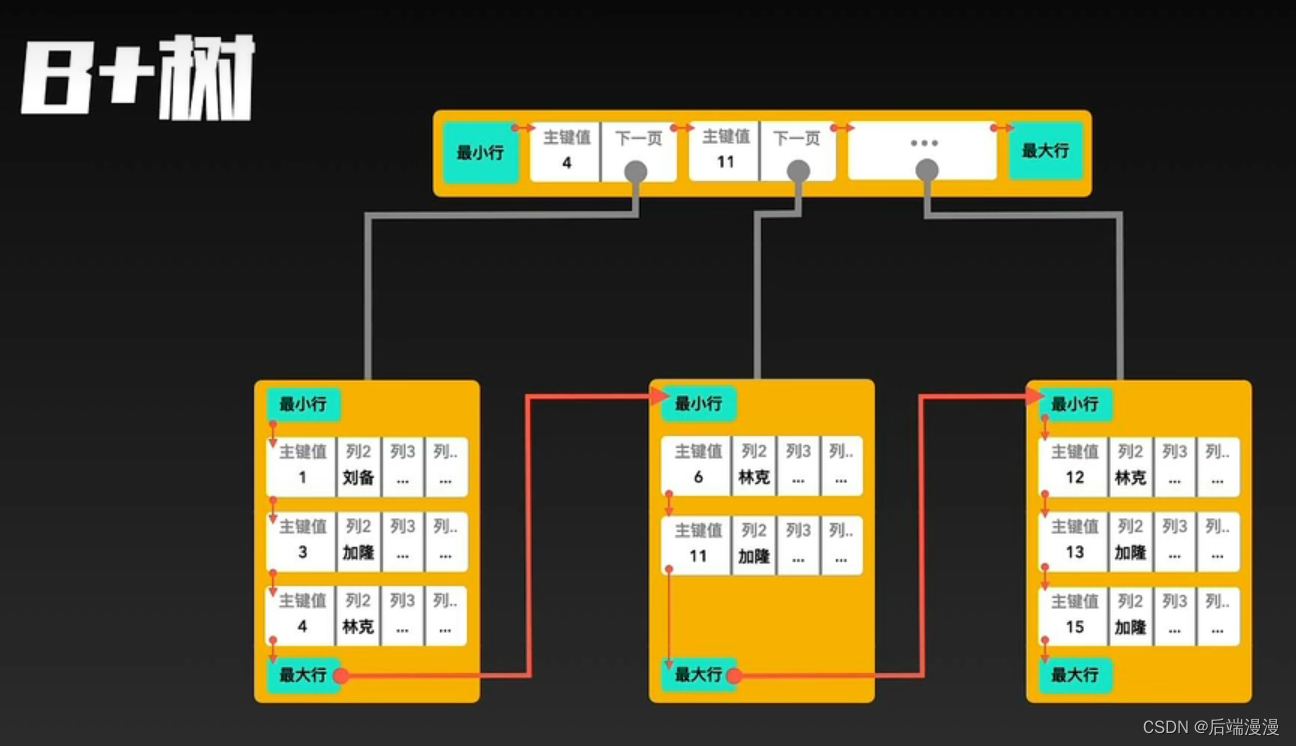
MySQL说:由于主键,所有数据行都会根据主键的升序进行排序,所以才会出现B+ Tree的排列。
B-Tree查询单个值效率并不低,但是如果要搜索大于10小于15这样一个范围,或者要遍历所有数据,那么B树就力不从心了。
B- Tree中,要查找的数据离根节点近查找的快,离根节点远查找的慢。这样不稳定的搜索时间并不利于我为程序猿大哥们做执行成本的估算。
B- Tree虽然已经降低了树的高度,但是仍然有下降空间
对比B Tree,B+Tree在哪里具有优势
- B- Tree对于范围查询效率较低,B+ Tree对于范围查询效率较高
- B- Tree搜索时间不稳定,B+ Tree数据节点深度一致,搜索时间稳定,方便做执行成本的估算
- 由于B+ Tree的非叶子结点不需要存储数据,所以可以存储更多数据行,这样就可以比B- Tree的高度更小。
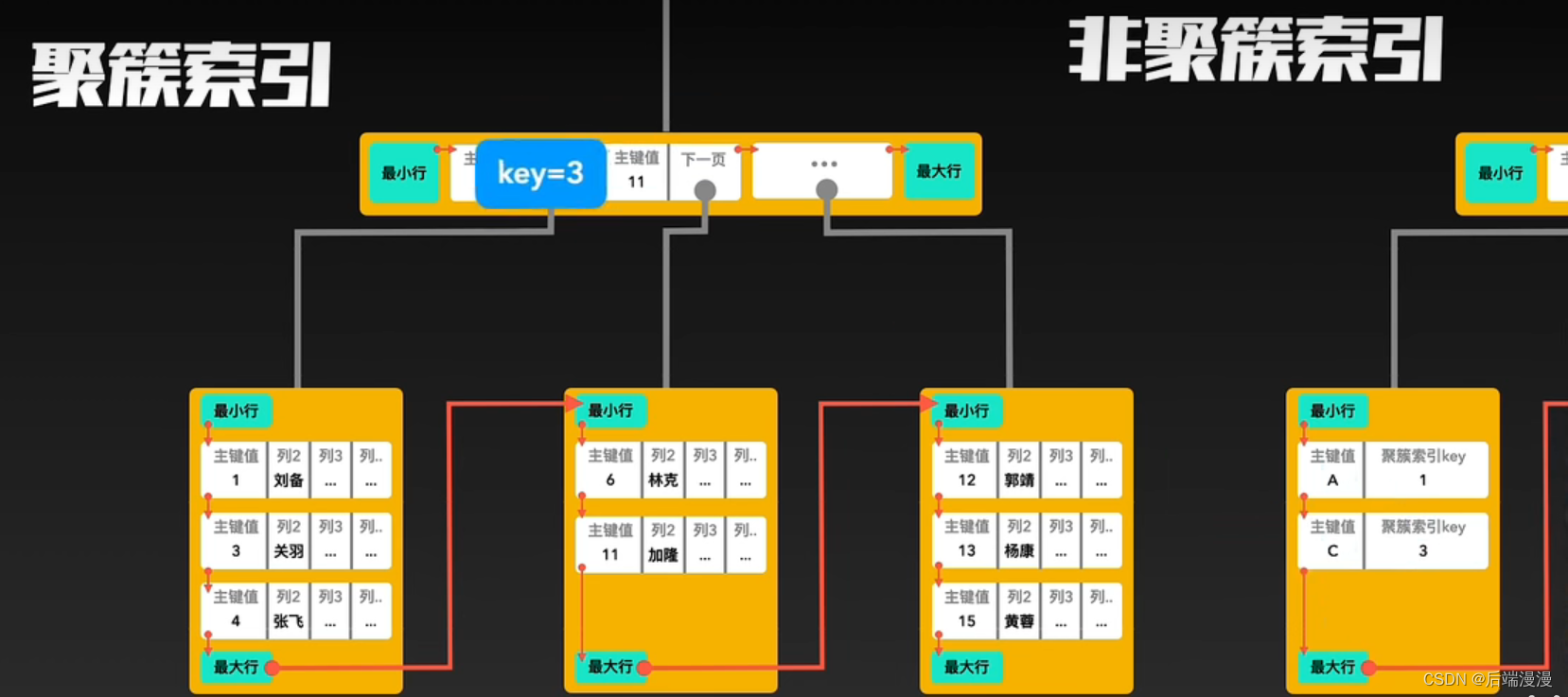
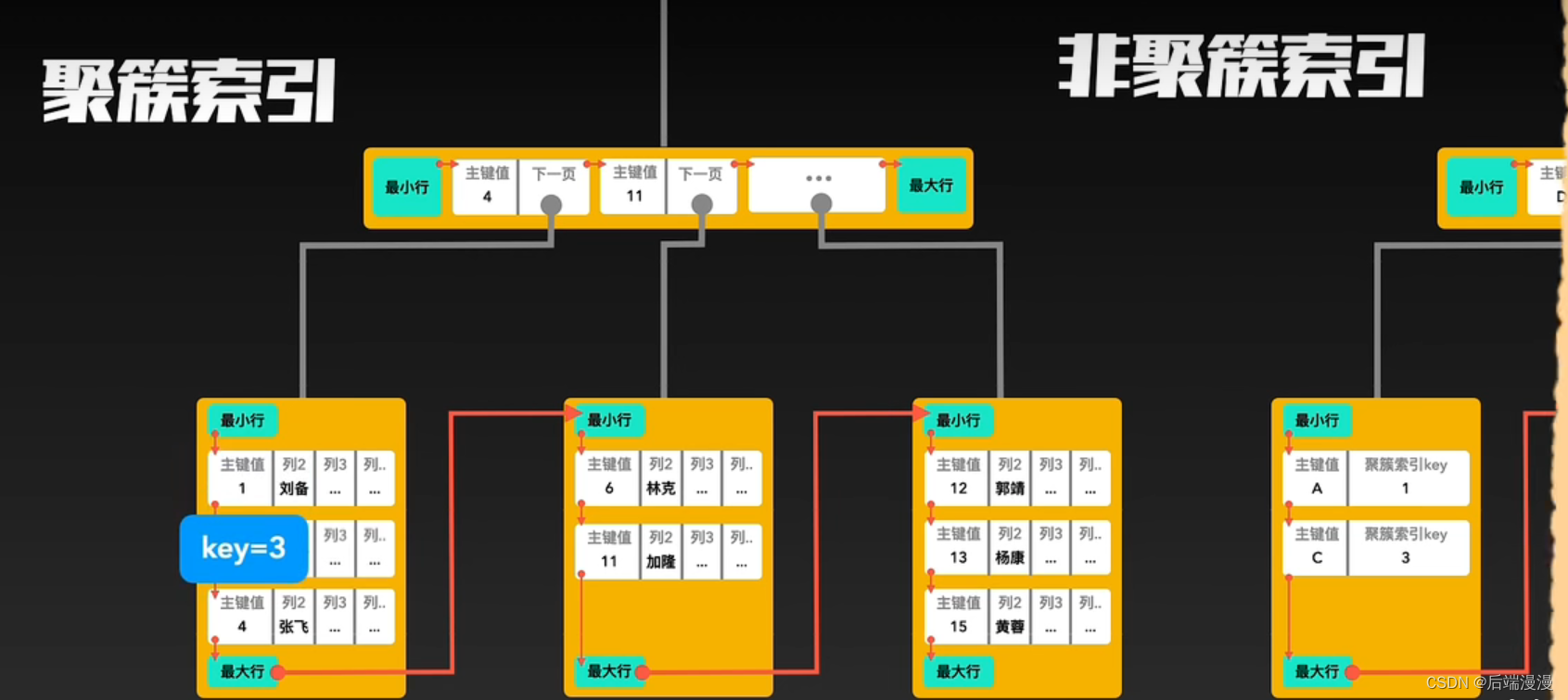
九、聚簇索引与非聚簇索引
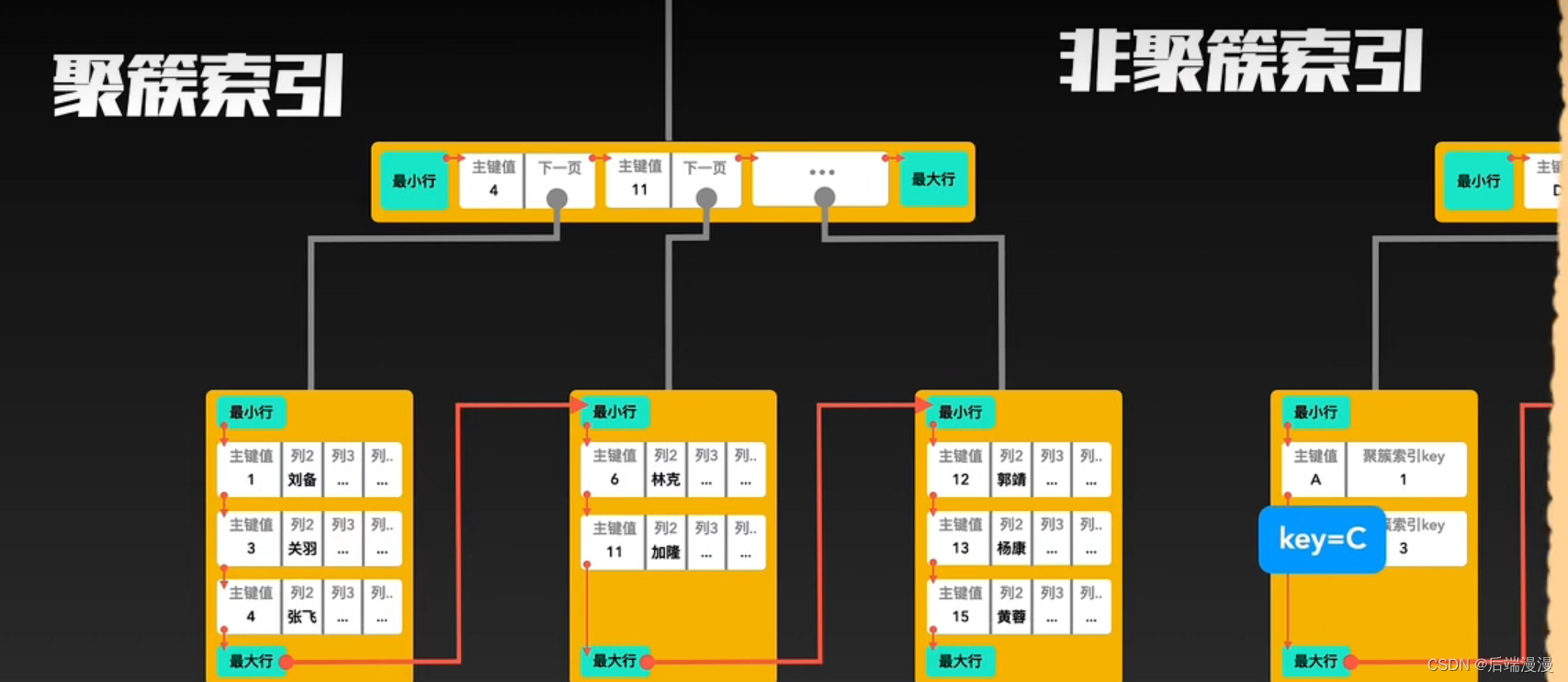
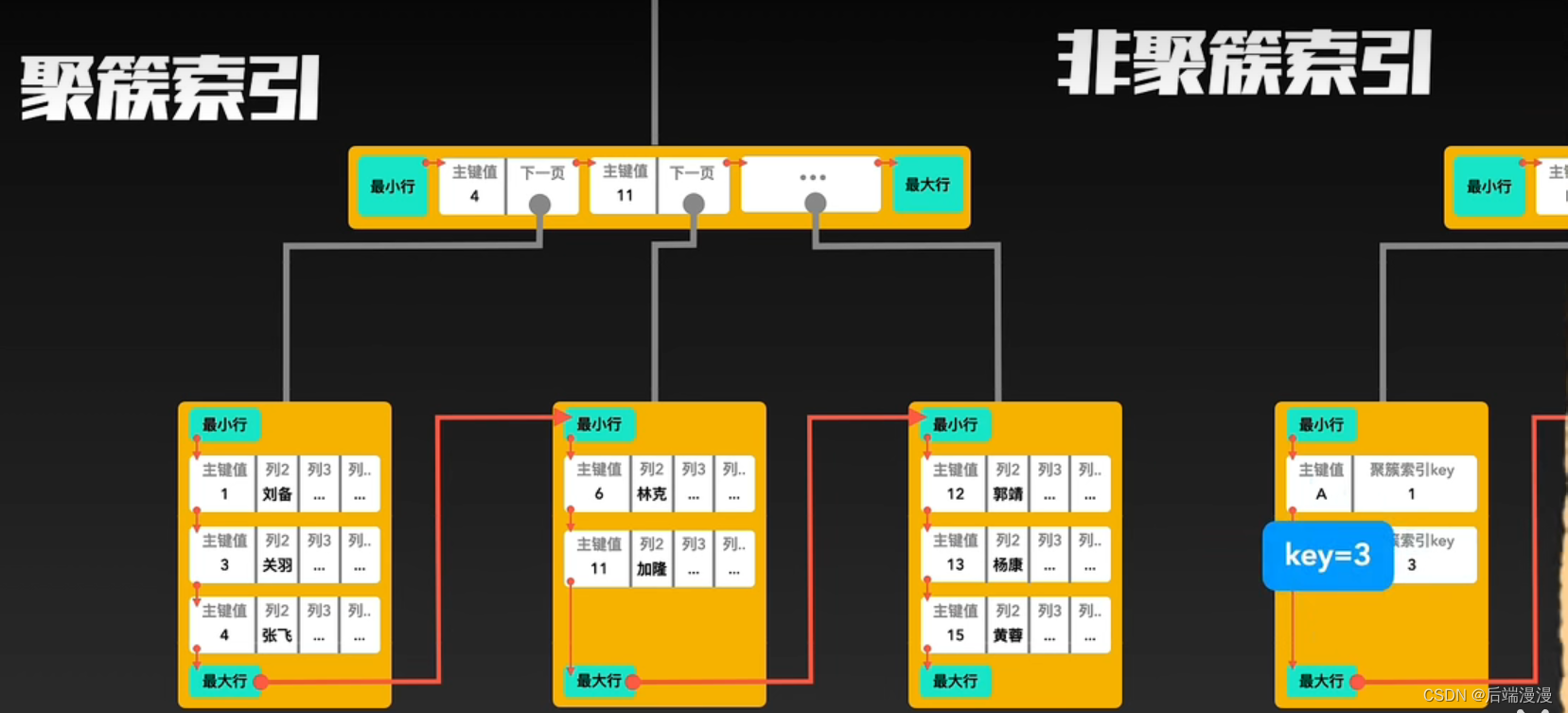
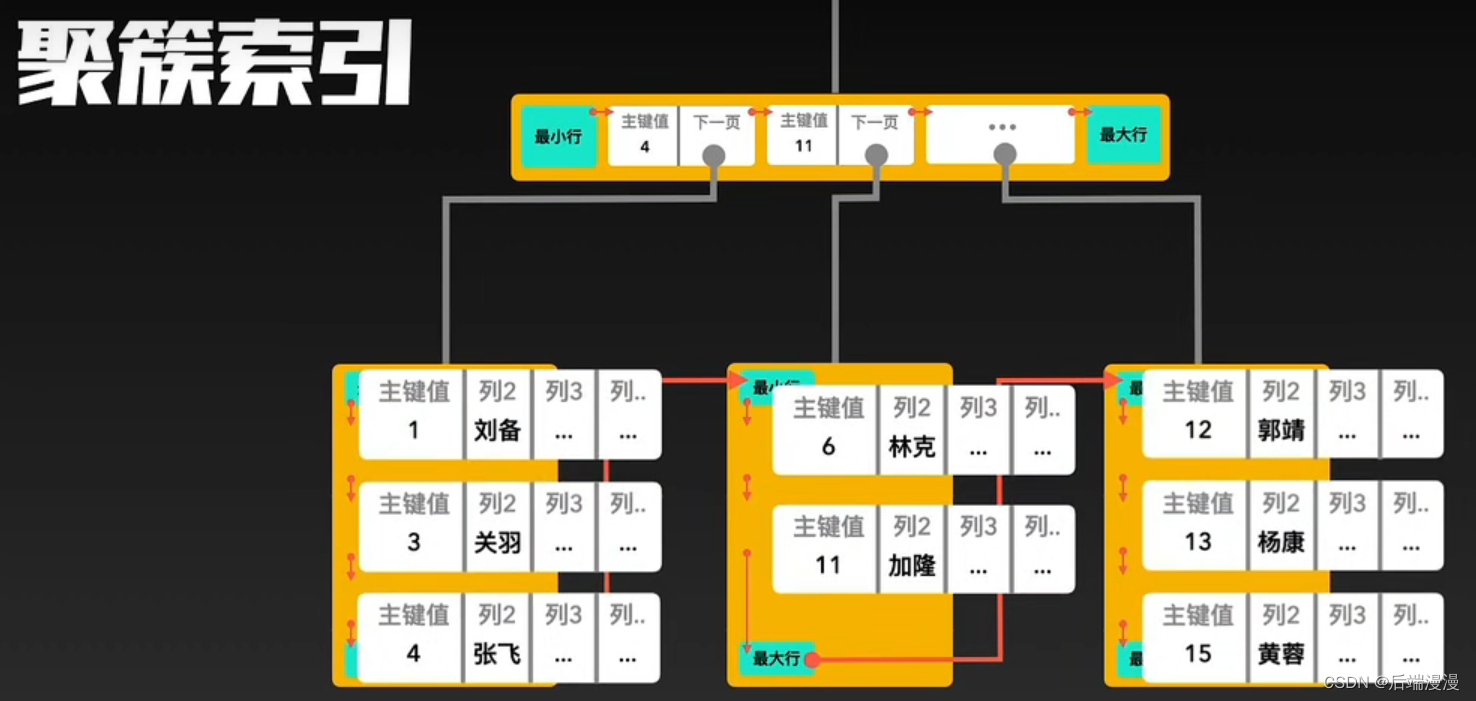
1. 聚簇索引
- 每个表至多只能创建一个聚簇索引
- 每个表可以有多个主键索引,但是只能选择其中一个作为聚簇索引
- 聚簇索引即是索引目录,又是真实数据。即非叶子结点记录索引目录,叶子结点记录真实数据。
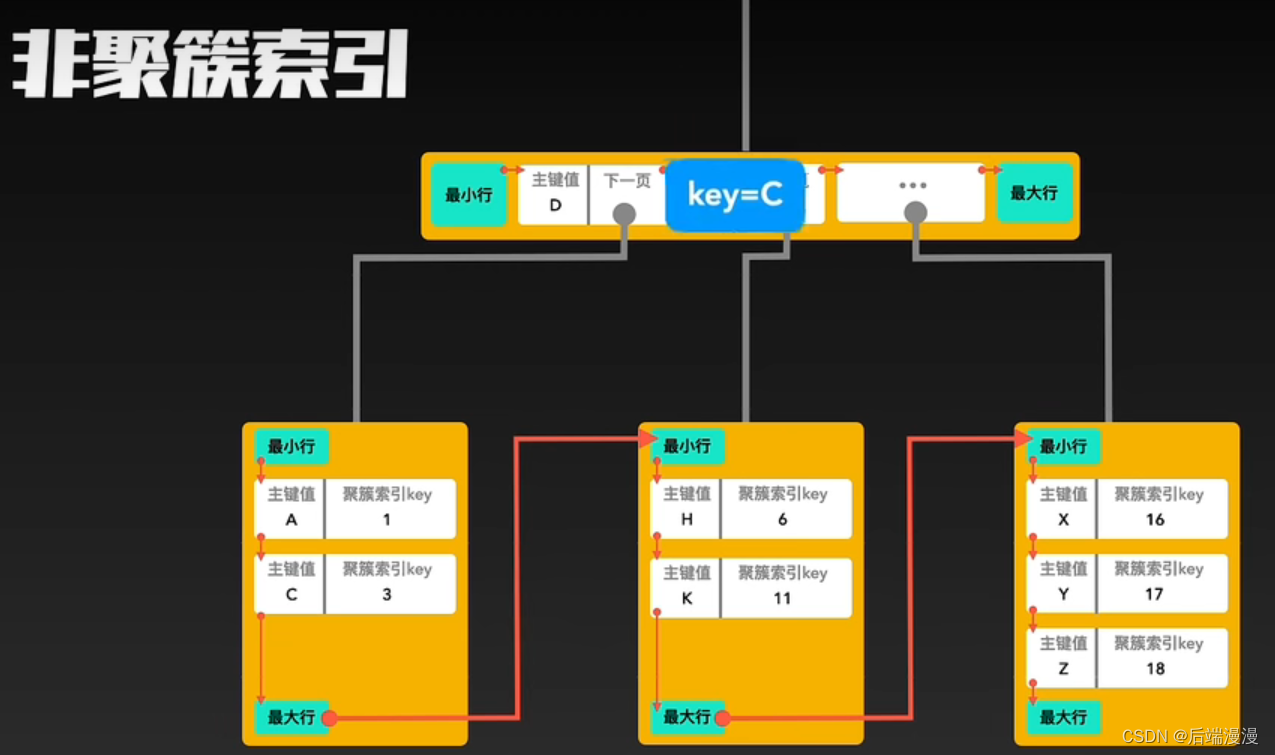
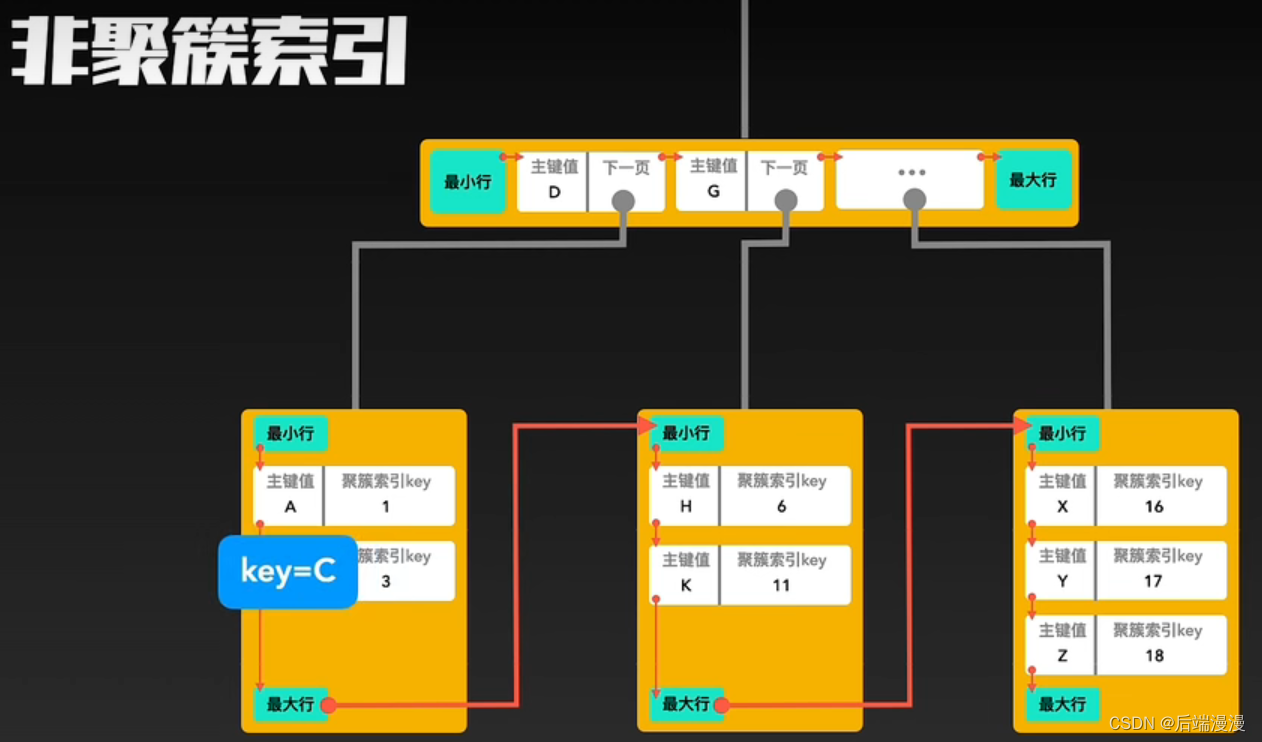
2. 非聚簇索引
- MySQL说:除了构成聚簇索引的索引项之外的其他每个索引,都会构成一颗非聚簇索引树。树的Key就是这些索引对应的列,树的非叶子结点与聚簇索引一样,只记录行里的这个索引值,作为目录存在。而树最底层的叶子结点,记录该“行”中聚簇索引的Key,并不记录其他内容。
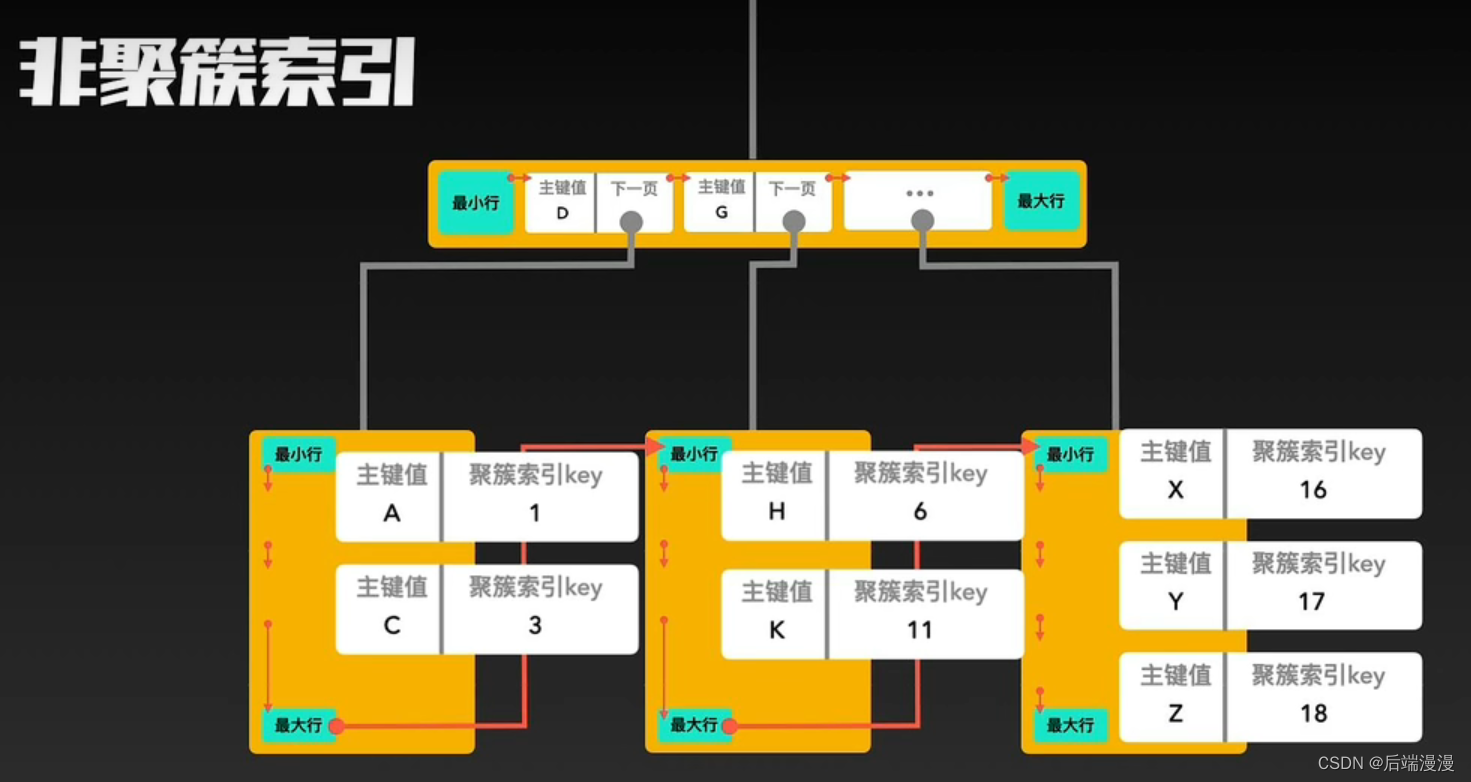
3. 聚簇索引与非聚簇索引的合作查询
MYSQL说:如果通过非聚簇索引查询,首先会在这棵“非聚簇索引”树种快速找到叶子结点,叶子结点中有聚簇索引的key,拿着这个key再去聚簇索引中查询一遍,就可以拿到真实数据了。