说明: 本篇文章主要写了机器学习的流程及一些常用的算法如: 贝叶斯,朴素贝叶斯,线性回归,决策树,随机森林,逻辑斯蒂回归,模型调优和特征工程等(都是使用python的sklearn库实现)
一、概述
二、
一、特征工程
在看下面的算法之前,我们要先对机器学习流程进行一下熟悉!
主要有下面几个步骤:
- 获取数据
- 对数据进行清洗
- 对数据集进行
切割为训练集和测试集 - 根据数据的情况对数据做
特征工程 选择合适算法进行模型训练,然后预测- 使用测试集进行测试数据
- 对模型进行
调优 - 保存模型到文件中
根据数据做特征工程包含如下3个内容:
1. 特征抽取/特征提取
|>字典特征提取, 应用DiceVectorizer实现对类别特征进行数值化、离散化
|>文本特征抽取,应用CounterVertorize/TfIdfVectorize实现对文本特征数值化(注意:这一点我们需要使用中文分词,我平常使用的是jieba分词)
|>图像特征抽取(深度学习)
2. 特征预处理
|_>归一化,应用MaxmixScaler,根据最小最大值进行放缩,默认范围0-1,容易受到异常值的影响,稳定性差,适合小规模
|_>标准化,应用StandardScaler, 数据处理到指定的范围内,默认0~1),异常值影响较小,对空值不敏感,大规模也适合
3. 特征降维
|_>特征选择 :
- 低方差过滤(VarianceThreshold):删除低方差的一些特征
- 特征之间相关性计算(from scipy.stats import pearsonr):计算特征之间的相关性{当0<|r|<1时,表示两变量存在一定程度的相关。且|r|越接近1,两变量间线性关系越密切;|r|越接近于0,表示两变量的线性相关越弱}
|_>PCA(主要成分分析from sklearn.decomposition import PCA): 数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息,在此过程中可能会舍弃原有数据、创造新的变量
代码实现,数据的加载使用的是sklearn的数据,有一些数据文件就不上传了,这里只是提供逻辑思路:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
from sklearn.feature_selection import VarianceThreshold
from sklearn.decomposition import PCA
import jieba
import pandas as pd
from scipy.stats import pearsonr
from sklearn.cluster import KMeans
#使用sklearn加载鸢尾花的数据
def datasets_iris():
#1.获取数据的操作和切割数据集
iris= load_iris()
print("查看数据集:",iris)
print("查看数据集的描述:\n",iris["DESCR"])
print("查看特征的名称:\n",iris.feature_names)
print("查看目标值的名称:\n",iris.target_names)
print("查看数据集的特征值:\n",iris.data)
print("查看数据集的目标值:\n",iris.target)
print("查看数据集的类型:\n",iris.data.shape)
# 训练集和测试机的切割
# 参数值(特征值,目标值,测试集的大小,随机数种子)
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,test_size=0.2,random_state=56)
print("训练集的特征值:",x_train)
print("训练集的目标值:",y_train)
print("测试集的特征值:",x_test)
print("测试集的目标值:",y_test)
print("训练集和测试集的特征值形状:",x_train.shape,x_test.shape)
def feature_demo():
"""
特征提取: 使用字典转换器
:return:
"""
# 创建字典数据========one-hot编码转换实现
data1=[{'city': '北京','temperature':100},{'city': '上海','temperature':60},{'city': '深圳','temperature':30}]
#1.创建特征转化器对象(默认转换成稀疏矩阵)
# 注意: 当特征类别过多的时候,一般都会使用稀疏矩阵来标记位置 如果想取消稀疏矩阵,将sparse=False即可
vectorizer1 = DictVectorizer(sparse=False)
#2.使用fit_transform方法进行转化
transfer = vectorizer1.fit_transform(data1)
print("转换过的特征:\n",transfer)
print("特征的名称:\n",vectorizer1.get_feature_names())
print("=================================================\n")
"""
特征提取: 使用文本转换器
"""
#创建文本数据========文本特征提取 CountVectorizer 使用词频来对文章进行权重标识
data2= ["life is short,i like like python", "life is too long,i dislike python"]
#1.创建转换器对象 (英文特征提取,默认按照空格进行切分)
vectorizer2 = CountVectorizer()
#注意:
# 1.上面的这个转换器,我们可以添加stopwords参数,停用词介绍
# 2.如果数据是中文的话,我们需要使用分词工具jieba进行中文分词,然后再进行特征提取
#2.使用fit_transform方法进行转换特征
transfer_word= vectorizer2.fit_transform(data2)
print("(英文文章)转换过的特征:",transfer_word)
print("(英文文章)特征的名称:",vectorizer2.get_feature_names())
"""
特征提取: 使用tfidf文本转换器
"""
#使用TF-IDF实现中文特征抽取 TfidfVectorizer 使用 TF:词频 和 IDF 逆文档频率(总文件数/出现这个词语的文件个数) 来进行计算权重
data3 = ["一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。",
"我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。",
"如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]
#1.创建TIIDF特征提取转换器
vectorizer3= TfidfVectorizer(stop_words=['一种', '不会', '不要'])
text_list = []
"""
使用jieba 分词将中文进行分词,再组合
"""
for sent in data3:
text_list.append(cut_word(sent))
print(text_list)
transfer_tfidf = vectorizer3.fit_transform(text_list)
print("tfidf特征提取:",transfer_tfidf)
print("tfidf特征名称:",vectorizer3.get_feature_names())
def minmax_demo():
"""
特征预处理: 归一化 缺点: 算法中的最大值最小值容易受到异常点的影响
:return:
"""
#1.读取文件
datingData = pd.read_csv("../datingTestSet2.txt",sep="\t")
print("原始数据:\n",datingData)
#2.创建归一化转化器
minmaxScaler = MinMaxScaler()
#3.使用fit_transform方法
tranfer = minmaxScaler.fit_transform(datingData)
print("归一化后的数据:\n",tranfer)
def stan_demo():
"""
特征预处理: 标准化处理 算法: 对归一化进行了优化,将最大值和最小值改为了平均值,在拥有少量数据量的情况下,对结果的影响不大
:return:
"""
#1.读取数据
datingData= pd.read_csv("../datingTestSet2.txt",sep="\t")
#2.创建标准化转换器对象
stanScaler=StandardScaler()
#3.使用fit_transform方法转换
tranfer = stanScaler.fit_transform(datingData)
print("标准化处理后的特征值:\n",tranfer)
def variance_demo():
"""
特征降维: 低方差过滤
:return:
"""
#1.读取数据文件
factor_data = pd.read_csv("../factor_returns.csv")
pd.set_option("display.max_columns",None)#显示全部列
# pd.set_option("display.max_rows",None)
print(factor_data)
data = factor_data.iloc[:,1:-2]
#2.创建低方差过滤转化器 (可以设置方差阈值,默认方差阈值为0)
variance = VarianceThreshold(10)#
#3.使用fit_transform方法转换
tranfer = variance.fit_transform(data)
print("低方差过滤后的特征:\n",tranfer,"\n形状:\n",tranfer.shape)
def pearsonr_demo():
"""
特征降维: 相关性计算 说明:计算出两个特征之间的相关性
:return:
"""
#1.读取数据
data = pd.read_csv("../factor_returns.csv").iloc[:,1:-2]
pd.set_option("display.max_columns",None)
print(data)
#2.计算相关性 #pearsonr返回的第一个值是相关性 其返回的数据越接近1越正相关,-1反相关 接近0的相关性最低
print("这两个特征之间的相关性是:\n",pearsonr(data["revenue"], data["total_expense"])[0])
def pca_demo():
"""
特征降维: 主要成分分析
:return:
"""
#1.创建数据列表
data=[[2,8,3,2],[5,9,8,1],[7,5,8,2],[1,7,2,4],[1,2,1,5],[1,8,4,8],[1,8,2,7],[2,8,17,5],[1,8,22,5],[1,8,23,5]]
#2.创建主要成分分析转换器对象 n_components如果是整数就是保留的特征数,如果是小数,则是按照百分比进行保留数据
pca=PCA(n_components=0.98)
#3.使用fit_transform方法进行转换
tranfer= pca.fit_transform(data)
print("PCA转换后的特征:\n",tranfer)
#4. 使用k-means进行聚类
forecast = KMeans(n_clusters=3)
forecast.fit(tranfer)
pre = forecast.predict(tranfer)
print(pre)
def cut_word(text):
"""
对中文进行分词
"我爱北京天安门"————>"我 爱 北京 天安门"
:param text:
:return: text
"""
# 用结巴对中文字符串进行分词
text = " ".join(list(jieba.cut(text)))
return text
if __name__ =="__main__":
# 1.获取数据的操作和切割数据集sadd
#datasets_iris()
# 2.字典的特征抽取
# feature_demo()
# 3.归一化处理
# minmax_demo()
# 4.标准化处理方式
# stan_demo()
# 5.低方差过滤,设置阈值
# variance_demo()
# 6.相关性计算
# pearsonr_demo()
# 7.主要成分分析
pca_demo()
二丶算法部分讲解
说明: 机器学习分为监督学习和无监督学习,下面我们所说的不管是分类算法还是回归算法都属于监督学习,不过后面的聚类算法k-means属于无监督学习,是否是监督学习的关键点在于我们的数据是否有目标值
我们先来看一下数据集的划分,将数据集划分为训练集和测试集:
#使用的是sklearn的model_selection模块下的方法
from sklearn.model_selection import train_test_split
#1.读取数据集是鸢尾花数据
iris_data = load_iris()
# 划分训练集和测试集
x_train,x_test,y_train,y_test=train_test_split(iris_data.data,iris_data.target,random_state=15)
2.1估计器(sklearn机器学习算法的实现)
在sklearn中,估计器(estimator)是一个重要的角色,是一类实现了算法的API
1、用于分类的估计器:
sklearn.neighbors.KNeighborsClassifier k-近邻算法
sklearn.naive_bayes.MultinomialNB 贝叶斯
sklearn.linear_model.LogisticRegression 逻辑回归
sklearn.tree.DecisionTreeClassifier 决策树
sklearn.tree.RandomForestClassifier 随机森林
2、用于回归的估计器:
sklearn.linear_model.LinearRegression 线性回归
sklearn.linear_model.Ridge 岭回归
3、用于无监督学习的估计器
sklearn.cluster.KMeans 聚类
2.2转换器
想一下之前做的特征工程的步骤?
1、实例化 (实例化的是一个转换器类(Transformer))
2、调用fit_transform(对于文档建立分类词频矩阵,不能同时调用)
我们把特征工程的接口称之为转换器,其中转换器调用有这么几种形式
fit_transform
fit
transform
2.3k近邻算法(KNN)
定义: 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
计算点之间的距离公式为(欧式距离):

参数说明:
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm=‘auto’)
n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数
algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’},可选用于计算最近邻居的算法:‘ball_tree’将会使用 BallTree,‘kd_tree’将使用 KDTree。‘auto’将尝试根据传递给fit方法的值来决定最合适的算法。 (不同实现方式影响效率)
K-近邻的总结:
优点:
简单,易于理解,易于实现,无需训练
缺点:
懒惰算法,对测试样本分类时的计算量大,内存开销大
必须指定K值,K值选择不当则分类精度不能保证
使用场景:小数据场景,几千~几万样本,具体场景具体业务去测试
2.4 朴素贝叶斯(分类)
定义: 什么叫做贝叶斯? 其实就是分类的时候,通过计算概率得到哪一类别的概率大,就选择哪一个类别,朴素贝叶斯其实就是事先假设特征之间相互独立
看公式之前我们需要先了解一下条件概率和联合概率:
联合概率:包含多个条件,且所有条件同时成立的概率
记作:P(A,B)
特性:P(A, B) = P(A)P(B)
条件概率:就是事件A在另外一个事件B已经发生条件下的发生概率
记作:P(A|B)
特性:P(A1,A2|B) = P(A1|B)P(A2|B)
注意:此条件概率的成立,是由于A1,A2相互独立的结果(记忆)
贝叶斯公式:

为了避免出现概率为0的情况,朴素贝叶斯又增加了一个拉普拉斯平滑系数:

小总结:朴素贝叶斯其实就是在贝叶斯情况下, 假设各条件之间相互独立,又增加了拉普拉斯系数
参数说明:
sklearn.naive_bayes.MultinomialNB(alpha = 1.0)朴素贝叶斯分类
alpha:拉普拉斯平滑系数
总结:
优点:
朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
对缺失数据不太敏感,算法也比较简单,常用于文本分类。
分类准确度高,速度快
缺点:
由于使用了样本属性独立性的假设,所以如果特征属性有关联时其效果不好
2.5决策树(分类)
定义:
决策树思想的来源非常朴素,程序设计中的条件分支结构就是if-then结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法,
决策顺序是根据说明进行选择的?
信息增益? 计算信息增益公式,
得到的值越大,就说明对数据的作用就越大,在决策树中,我们就可以先进行选择
信息增益公式(只需要理解即可):
当然决策树的原理不止信息增益这一种,还有其他方法。但是原理都类似,我们就不去举例计算。

参数说明:
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)
决策树分类器
criterion:默认是’gini’系数,也可以选择信息增益的熵’entropy’
max_depth:树的深度大小
random_state:随机数种子
其中会有些超参数:max_depth:树的深度大小
其它超参数我们会结合随机森林讲解
总结:
优点:
简单的理解和解释,树木可视化。
缺点:
决策树学习者可以创建不能很好地推广数据的过于复杂的树,这被称为过拟合。
改进:
减枝cart算法(决策树API当中已经实现,随机森林参数调优有相关介绍)
随机森林
注:企业重要决策,由于决策树很好的分析能力,在决策过程应用较多, 可以选择特征
2.6随机森林(分类)
定义:
在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
随机森林原理:
用N来表示训练用例(样本)的个数,M表示特征数目。
1、一次随机选出一个样本,重复N次, (有可能出现重复的样本)
2、随机去选出m个特征, m <<M,建立决策树
采取bootstrap(随机有放回的)抽样
为什么要使用bootstrap抽样?
为什么要随机抽样训练集?
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的
为什么要有放回地抽样?
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是“有偏的”,都是绝对“片面的”(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决。
注意: 我认为随机森林里面树,最后就像是召开会议,最终投票决定数据是属于哪一个分类
参数说明:
class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, bootstrap=True, random_state=None, min_samples_split=2)
随机森林分类器
n_estimators:integer,optional(default = 10)森林里的树木数量120,200,300,500,800,1200
criteria:string,可选(default =“gini”)分割特征的测量方法
max_depth:integer或None,可选(默认=无)树的最大深度 5,8,15,25,30
max_features="auto”,每个决策树的最大特征数量
If “auto”, then max_features=sqrt(n_features).
If “sqrt”, then max_features=sqrt(n_features) (same as “auto”).
If “log2”, then max_features=log2(n_features).
If None, then max_features=n_features.
bootstrap:boolean,optional(default = True)是否在构建树时使用放回抽样
min_samples_split:节点划分最少样本数
min_samples_leaf:叶子节点的最小样本数
超参数:n_estimator, max_depth, min_samples_split,min_samples_leaf
总结:
在当前所有算法中,具有
极好的准确率
能够有效地运行在大数据集上,处理具有高维特征的输入样本,而且不需要降维
能够评估各个特征在分类问题上的重要性
2.7线性回归(回归)
定义:
线性回归(Linear regression)是利用回归方程(函数)对一个或多个自变量(特征值)和因变量(目标值)之间关系进行建模的一种分析方式
损失函数:

优化的两种方式: 正规方程和梯度下降


参数说明:
sklearn.linear_model.LinearRegression(fit_intercept=True)
通过正规方程优化
fit_intercept:是否计算偏置
LinearRegression.coef_:回归系数
LinearRegression.intercept_:偏置
sklearn.linear_model.SGDRegressor(loss=“squared_loss”, fit_intercept=True, learning_rate =‘invscaling’, eta0=0.01)
SGDRegressor类实现了随机梯度下降学习,它支持不同的loss函数和正则化惩罚项来拟合线性回归模型。
loss:损失类型
loss=”squared_loss”: 普通最小二乘法
fit_intercept:是否计算偏置
learning_rate : string, optional
学习率填充
‘constant’: eta = eta0
‘optimal’: eta = 1.0 / (alpha * (t + t0)) [default]
‘invscaling’: eta = eta0 / pow(t, power_t)
power_t=0.25:存在父类当中
对于一个常数值的学习率来说,可以使用learning_rate=’constant’ ,并使用eta0来指定学习率。
SGDRegressor.coef_:回归系数
SGDRegressor.intercept_:偏置
sklearn提供给我们两种实现的API, 可以根据选择使用
关于优化方法:
5.1 GD
梯度下降(Gradient Descent),原始的梯度下降法需要计算所有样本的值才能够得出梯度,计算量大,所以后面才有会一系列的改进。
5.2 SGD
随机梯度下降(Stochastic gradient descent)是一个优化方法。它在一次迭代时只考虑一个训练样本。
SGD的优点是:
高效
容易实现
SGD的缺点是:
SGD需要许多超参数:比如正则项参数、迭代数。
SGD对于特征标准化是敏感的。
5.3 SAG
随机平均梯度法(Stochasitc Average Gradient),SAG其实每次计算时,利用了两个梯度的值,一个是前一次迭代的梯度值,另一个是新的梯度值。当然这两个梯度值都只是随机选取一个样本来计算。
直观上看,利用的信息量大了,收敛速度就应该比单纯用一个样本估计梯度值的SGD要快。但是SAG带来的问题就是需要内存来维护(保存)每一个旧梯度值。以空间换时间
Scikit-learn:SGDRegressor、岭回归、逻辑回归等当中都会有SAG优化
总结:
线性回归的损失函数-均方误差
线性回归的优化方法
正规方程
梯度下降
线性回归的性能衡量方法-均方误差
2.8岭回归
定义:
岭回归,其实也是一种线性回归。只不过在算法建立回归方程时候,加上正则化的限制,从而达到解决过拟合的效果
参数说明:
sklearn.linear_model.Ridge(alpha=1.0, fit_intercept=True,solver=“auto”, normalize=False)
岭回归也叫具有l2正则化的线性回归
alpha:正则化力度,也叫 λ
λ取值:0~1 1~10
solver:会根据数据自动选择优化方法
sag:如果数据集、特征都比较大,选择该随机梯度下降优化
normalize:数据是否进行标准化
normalize=False:可以在fit之前调用preprocessing.StandardScaler标准化数据
Ridge.coef_:回归权重
Ridge.intercept_:回归偏置
注意:
1.Ridge方法相当于SGDRegressor(penalty='l2', loss="squared_loss"),只不过SGDRegressor实现了一个普通的随机梯度下降学习,推荐使用Ridge(实现了SAG)
2.正则化力度越大,权重系数会越小 正则化力度越小,权重系数会越大
2.9逻辑回归(分类)
定义:
逻辑回归(Logistic Regression)是机器学习中的一种分类模型,逻辑回归是一种分类算法,虽然名字中带有回归,但是它与回归之间有一定的联系。由于算法的简单和高效,在实际中应用非常广泛。
逻辑回归解决的问题? 解决的问题是二分类问题
原理1输入:
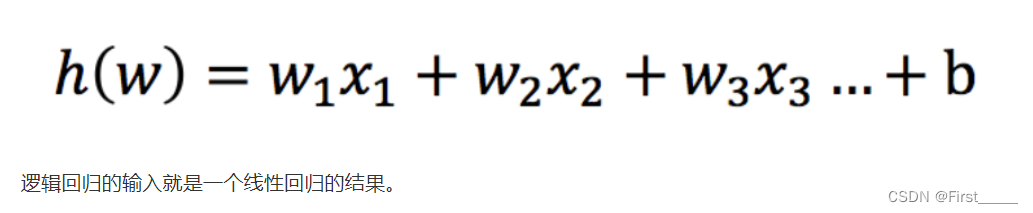
原理2激活函数:
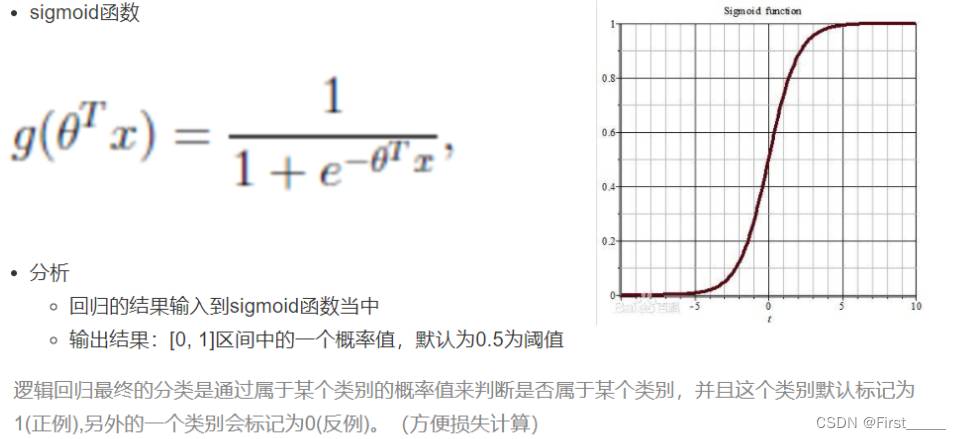
原理3损失函数:
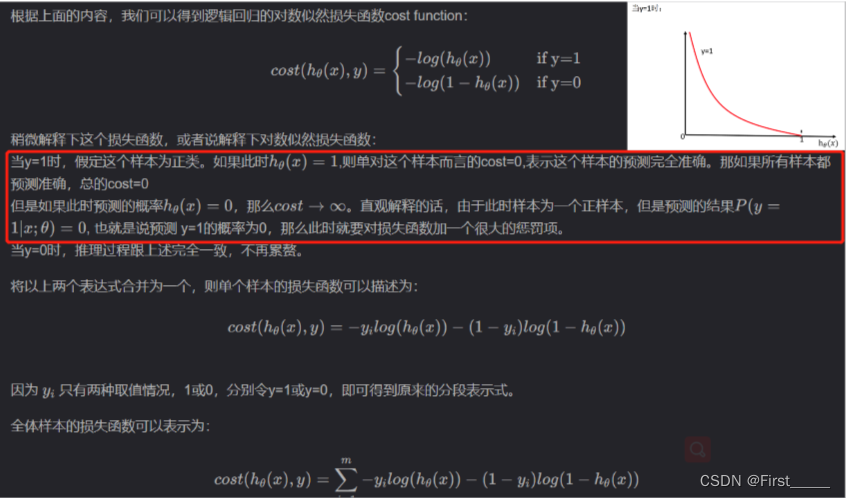
优化:
同样使用梯度下降优化算法,调节wb的权重值, 去减少损失函数的值。这样去更新逻辑回归前面对应算法的权重参数,提升原本属于1类别的概率,降低原本是0类别的概率。
参数说明:
sklearn.linear_model.LogisticRegression(solver=‘liblinear’, penalty=‘l2’, C = 1.0)
solver:优化求解方式(默认开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数)
sag:根据数据集自动选择,随机平均梯度下降
penalty:正则化的种类
C:正则化力度
注意: 默认将类别数量少的当做正例
总结:
优点:
实现简单,广泛的应用于工业问题上;
分类时计算量非常小,速度很快,存储资源低;
便利的观测样本概率分数;
对逻辑回归而言,多重共线性并不是问题,它可以结合L2正则化来解决该问题;
计算代价不高,易于理解和实现。
缺点:
当特征空间很大时,逻辑回归的性能不是很好;
容易欠拟合,一般准确度不太高;
不能很好地处理大量多类特征或变量;
只能处理两分类问题(在此基础上衍生出来的softmax可以用于多分类),且必须线性可分;
对于非线性特征,需要进行转换。
注意: 比如对于癌症患者分类,我们并不想知道他预测的准确率,而是想知道癌症患者是否都被预测出来了
2.10k-means算法(聚类属于无监督学习的一种)
定义:
k-means算法是一个聚类的算法 也就是clustering 算法。是属于无监督学习算法,也是就样本没有label(标签)的算分,然后根据某种规则进行“分割”, 把相同的或者相近的objects 物体放在一起。 在这里K就是我们想要分割的的聚类的个数。
原理:(k-means聚类步骤)
1、随机
设置K个特征空间内的点作为初始的聚类中心
2、对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
3、接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
4、如果计算得出的新中心点与原中心点一样,那么结束,否则重新进行第二步过程
参数说明:
sklearn.cluster.KMeans(n_clusters=8,init=‘k-means++’)
k-means聚类
n_clusters:开始的聚类中心数量
init:初始化方法,默认为’k-means ++’
labels_:默认标记的类型,可以和真实值比较(不是值比较)
Kmeans性能评估指标:
轮廓系数:

详解:
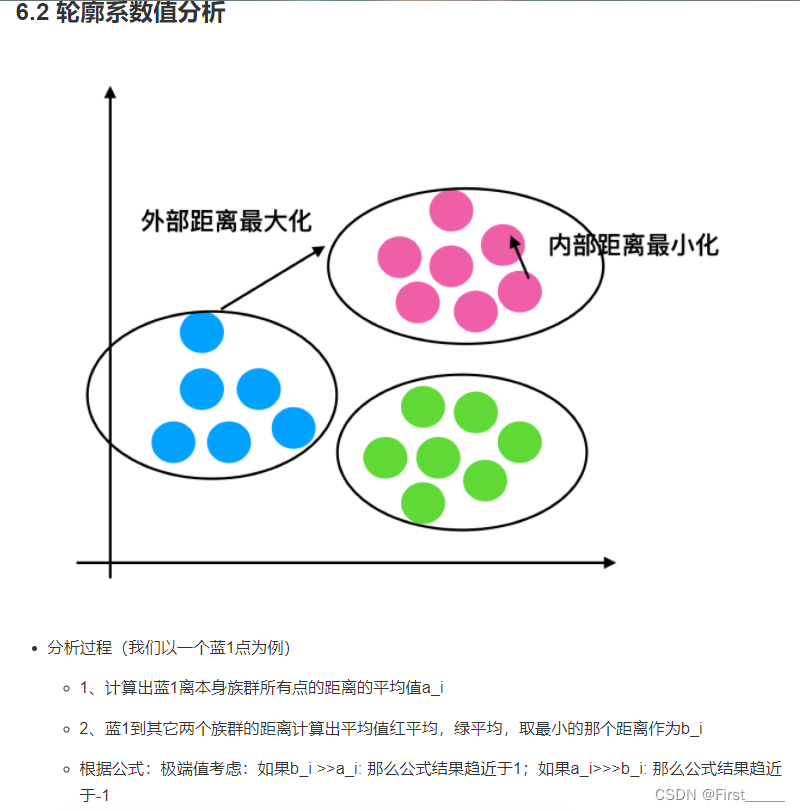
轮廓系数结论分析:如果b_i>>a_i:
趋近于1效果越好, b_i<<a_i:趋近于-1,效果不好。轮廓系数的值是介于 [-1,1],越趋近于1代表内聚度和分离度都相对较优。
轮廓系数参数说明:
sklearn.metrics.silhouette_score(X, labels)
计算所有样本的平均轮廓系数
X:特征值
labels:被聚类标记的目标值
k-means总结:
特点分析:采用迭代式算法,直观易懂并且非常实用
缺点:容易收敛到局部最优解(多次聚类)
注意:聚类一般做在分类之前
2.11附代码
import plotly.io
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.tree import DecisionTreeClassifier
from sklearn.feature_extraction import DictVectorizer
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import export_graphviz
from sklearn.tree import plot_tree
import pandas as pd
import matplotlib.pyplot as plt
"""
分类算法
"""
def knn_iris():
"""
使用knn算法实现鸢尾花的分类
:return:
"""
#1.读取数据集,并进行划分
iris_data = load_iris()
# 划分训练集和测试集
x_train,x_test,y_train,y_test=train_test_split(iris_data.data,iris_data.target,random_state=15)
#2.进行特征工程,标准化
stan = StandardScaler()
x_train = stan.fit_transform(x_train)
x_test = stan.fit_transform(x_test)
#3.使用knn算法进行计算
knn= KNeighborsClassifier(n_neighbors=3)
knn.fit(x_train,y_train)
y_predict = knn.predict(x_test)#测试集预测的y值结果
#4.查看计算后的预测准确性
print("是否相等:\n",y_predict==y_test)
score = knn.score(x_test,y_test)
print("准确率为:\n",score)
def knn_iris_grcv():
"""
使用交叉验证和网格搜索进行 模型的调优选择
:return:
"""
#1.读取数据集,并进行划分
iris_data = load_iris()
# 划分训练集和测试集
x_train,x_test,y_train,y_test=train_test_split(iris_data.data,iris_data.target,random_state=15)
#2.进行特征工程,标准化
stan = StandardScaler()
x_train = stan.fit_transform(x_train)
x_test = stan.fit_transform(x_test)
#3.使用knn算法进行计算
# knn= KNeighborsClassifier(n_neighbors=3)
knn= KNeighborsClassifier()
# 进行使用交叉验证和网格搜索进行模型调优
params={"n_neighbors":[1,2,3,5,7,8,15,22]} #这个字典的key要和所对应的算法的参数名相同
grcv = GridSearchCV(knn,param_grid=params,cv=2)
grcv.fit(x_train,y_train)
y_predict = grcv.predict(x_test)#测试集预测的y值结果
print(y_predict)
print("比对预测值和真实数据:\n",y_predict== y_test)
#4.查看计算后的预测准确性
print("选择了某个模型测试集当中预测的准确率为:", grcv.score(x_test, y_test))
# 训练验证集的结果
print("最佳参数:", grcv.best_params_)
print("在交叉验证当中验证的最好结果:", grcv.best_score_)
print("gc选择了的模型K值是:", grcv.best_estimator_)
print("每次交叉验证的结果为:", grcv.cv_results_)
def news_nb():
"""
使用朴素贝叶斯对新闻数据进行分类
:return:
"""
#1.读取数据
print(1)
newsdata = fetch_20newsgroups(subset="all")
print(2)
#2.划分训练集和测试集
x_train,x_test,y_train,y_test= train_test_split(newsdata.data,newsdata.target,random_state=22)
#3.做特征工程:Tfids
tv = TfidfVectorizer()
x_train = tv.fit_transform(x_train)
# 注意:这里的测试集不能使用fit_transform
# 我们在训练集上调用fit_transform(),其实找到了均值μ和方差σ^2,即我们已经找到了转换规则,我们把这个规则利用在训练集上,
# 同样,我们可以直接将其运用到测试集上(甚至交叉验证集),所以在测试集上的处理,我们只需要标准化数据而不需要再次拟合数据
x_test = tv.transform(x_test)
#4.使用朴素贝叶斯进行分类
nb = MultinomialNB()
nb.fit(x_train,y_train)
y_predict = nb.predict(x_test)
#5.进行准确值结果比对
print("比对真实值与预测值数据:\n",y_predict==y_test)
print("准确值:\n",nb.score(x_test,y_test))
def tree_iris():
"""
使用决策树对鸢尾花数据进行分类
:return:
"""
#1.加载数据
iris_data = load_iris()
#2.切割数据
x_train,x_test,y_train,y_test=train_test_split(iris_data.data,iris_data.target,random_state=14)
#3.特征工程: 标准化,这里其实不做也行
tranfer = StandardScaler()
x_train = tranfer.fit_transform(x_train)
x_test = tranfer.fit_transform(x_test)
#4.使用决策树预估器进行计算
forecast = DecisionTreeClassifier(criterion="entropy",random_state=11)
forecast.fit(x_train,y_train)
y_predict = forecast.predict(x_test)
#5.计算准确率
print("决策树的真实值与预测值比对:\n",y_predict==y_test)
print("决策树的准确率:\n",forecast.score(x_test,y_test))
def tree_titanic():
"""
1.使用决策树对泰坦尼克号做是否生存预测分析(分类)
2.使用随机森林进行优化 泰坦尼克号生存预测
:return:
"""
#1.获取数据
path="./titanic.csv"
titanic_data = pd.read_csv(path)
pd.set_option("display.max_columns",None)
print(titanic_data.head())
x=titanic_data[["pclass","age","sex"]]
y=titanic_data["survived"]
print(x)
print(y)
#2.对数据进行处理
#缺失值填补,使用平均值填补 inplace参数为True是指原数据发生改变
x["age"].fillna(x["age"].mean(),inplace=True)
# print("将age缺失的字段进行填补:\n",x)
#特征转换为字典
x= x.to_dict(orient="records")
print("将特征转为字典形式:\n",x)
#4.划分数据集
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=11)
#5.特征工程:字典抽取
tranfer = DictVectorizer()
x_train = tranfer.fit_transform(x_train)
x_test = tranfer.fit_transform(x_test)
#6.决策树预估器计算流程
forecast = DecisionTreeClassifier(criterion="entropy",random_state=11)
forecast.fit(x_train,y_train)
#7.评估模型准确性
y_predict = forecast.predict(x_test)
print("目标值的真实值与预测值比对:\n",y_predict==y_test)
print("准确率为:\n",forecast.score(x_test,y_test))
#8.可视化树型结构
plt.figure(figsize=(50, 50))
plot_tree(forecast, filled=True, feature_names=tranfer.feature_names_, class_names=y.name)
plt.show()
# export_graphviz(forecast, out_file="./tree.dot", feature_names=tranfer.feature_names_)
#===============================================上面是决策树实现,下面是随机森林实现=====================================================
"""
使用随机森林来实现预测
"""
# # 6.使用随机森林预估器计算流程 , 使用交叉验证来进行评估模型
# forecast = RandomForestClassifier()
# #选择配置的超参数
# params={"n_estimators":[120,200,300,500,800,1200],
# "criterion":["gini","entropy"],
# "max_depth":[5,8,15,25,30]}
# gscv = GridSearchCV(forecast,param_grid=params,cv=4)
# gscv.fit(x_train,y_train)
# y_predict = gscv.predict(x_test)
#
# print("目标值的真实值与预测值比对:\n",y_predict==y_test)
# print("准确率为:\n",gscv.score(x_test,y_test))
#
# print("最佳参数:", gscv.best_params_)
# print("在交叉验证当中验证的最好结果:", gscv.best_score_)
# print("gc选择了的模型K值是:", gscv.best_estimator_)
if __name__ == "__main__":
#1.k近邻算法实现鸢尾花分类
# knn_iris()
#2.k近邻使用模型选择优化
# knn_iris_grcv()
#3.朴素贝叶斯对新闻数据进行分类
# news_nb()
#4.决策树实现对鸢尾花数据进行分类
# tree_iris()
#5.决策树实现对泰坦尼克号进行分类 随机森林实现对泰坦尼克号的分类
tree_titanic()
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression, SGDRegressor, Ridge, LogisticRegression
from sklearn.metrics import mean_squared_error, classification_report,roc_auc_score
import pandas as pd
import numpy as np
import joblib
def linear1():
"""
线性回归: 使用正规方程优化线性回归预测波士顿房价
:return:
"""
# 1.获取波士顿数据
boston = load_boston()
# 2.划分数据为训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=22)
# 3.特征预处理: 无量纲化: 标准化
standard = StandardScaler()
x_train = standard.fit_transform(x_train)
x_test = standard.fit_transform(x_test)
# 4.使用线性回归转换器进行转换(正规方程)
forecast = LinearRegression()
forecast.fit(x_train, y_train)
# 预测值
y_predict = forecast.predict(x_test)
# 5.预测真实值
print("正规方程预测值为:", y_predict)
print("正规方程的权重参数为:", forecast.coef_)
print("正规方程的偏置:", forecast.intercept_)
print("正规方程的均方误差为:", mean_squared_error(y_test, y_predict))
return None
def linear2():
"""
线性回归: 使用梯度下降优化线性回归预测波士顿房价
:return:
"""
# 1.获取波士顿数据
boston = load_boston()
# 2.划分数据为训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=22)
# 3.特征预处理: 无量纲化: 标准化
standard = StandardScaler()
x_train = standard.fit_transform(x_train)
x_test = standard.fit_transform(x_test)
# 4.使用线性回归转换器进行转换(梯度方程) max_iter: 是指的迭代次数
forecast = SGDRegressor(eta0=0.01, max_iter=10000)
forecast.fit(x_train, y_train)
# 预测值
y_predict = forecast.predict(x_test)
# 5.预测真实值
print("梯度下降预测值为:", y_predict)
print("梯度下降的权重参数为:", forecast.coef_)
print("梯度下降的偏置:", forecast.intercept_)
print("梯度下降的均方误差为:", mean_squared_error(y_test, y_predict))
return None
def linear3():
"""
线性回归: 使用岭回归优化线性回归预测波士顿房价
:return:
"""
# 1.获取波士顿数据
boston = load_boston()
# 2.划分数据为训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=22)
# 3.特征预处理: 无量纲化: 标准化
standard = StandardScaler()
x_train = standard.fit_transform(x_train)
x_test = standard.fit_transform(x_test)
# 4.使用线性回归转换器进行转换(岭回归) max_iter: 是指的迭代次数
forecast = Ridge(alpha=0.2, max_iter=10000)
forecast.fit(x_train, y_train)
# 预测值
y_predict = forecast.predict(x_test)
# 5.预测真实值
print("岭回归预测值为:", y_predict)
print("岭回归的权重参数为:", forecast.coef_)
print("岭回归的偏置:", forecast.intercept_)
print("岭回归的均方误差为:", mean_squared_error(y_test, y_predict))
return None
def logistic():
"""
逻辑斯蒂回归实现癌症预测
:return:
"""
# 1.得到数据
column_name = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape',
'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin',
'Normal Nucleoli', 'Mitoses', 'Class']
data = pd.read_csv(
"https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data",
names=column_name)
pd.set_option("display.max_columns", 100)
pd.set_option("display.max_rows", 100)
# print(data)
# 2.对数据进行缺失值处理,取出特征值x和目标值y
data = data.replace(to_replace='?', value=np.nan) # 将?替换为Nan
data = data.dropna() # 将Nan值进行删除
x = data.iloc[:, 1:-1]
y = data["Class"]
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
# 3.将数据进行标准化
standard = StandardScaler()
x_train = standard.fit_transform(x_train)
x_test = standard.fit_transform(x_test)
# 4.创建逻辑斯蒂回归转换器进行转换
forecast = LogisticRegression()
forecast.fit(x_train, y_train)
# 5.进行模型评估
y_predict = forecast.predict(x_test)
print("准确率为:", forecast.score(x_test, y_test))
"""计算精确率和召回率"""
print("精确率和召回率为:",
classification_report(y_test, y_predict, labels=[2, 4], target_names=['良性', '恶性']))
y_test = np.where(y_test > 2.5, 1, 0)
print("AUC指标:", roc_auc_score(y_test, forecast.predict(x_test)))
def model_save_Load():
"""
模型的保存与加载
注意:后缀必须为pkl
"""
# 保存:joblib.dump(模型对象, 'test.pkl')
# 加载:estimator = joblib.load('test.pkl')
if __name__ == "__main__":
# 1.正规方程优化线性回归预测波士顿房价
# linear1()
# 2.梯度下降优化线性回归预测波士顿房价
# linear2()
# 3.岭回归优化线性回归预测波士顿房价
# linear3()
# 4.使用逻辑斯蒂对癌症进行预测
logistic()
三、模型的调优
3.1模型的选择与调优(X折交叉验证,超参数)
3.2分类的评估方法
精确率与召回率
ROC曲线与AUC指标
3.3欠拟合与过拟合
l2正则化