基于 LLM 大语言模型的知识库问答系统
基于大语言模型(Large Language Model,LLM)的知识库问答系统是一种利用先进的自然语言处理技术来理解用户查询并从知识库中检索出准确答案的系统。这里的LLM指的是能够处理和理解大量文本数据的人工智能模型,例如GPT-3、BERT、XLNet等。以下是该系统的几个关键组成部分和特点:
关键组成部分:
1. 大语言模型(LLM):
- LLM是系统的核心,它通过预训练在大量文本数据上学习语言模式和知识,能够理解和生成自然语言。
2. 知识库:
- 知识库是问答系统的基础,它包含了结构化的数据和信息,这些数据通常是关于特定领域或主题的。
3. 查询理解模块:
- 这个模块负责解析用户的自然语言查询,提取关键信息,并将其转化为可以由系统处理的形式。
4. 检索与匹配引擎:
- 引擎根据查询理解模块的输出,在知识库中检索相关信息,并找到最匹配的答案。
5. 自然语言生成(NLG)模块:
- NLG模块负责将检索到的结构化答案转换成流畅的自然语言文本,以便用户理解。
特点:
1. 理解自然语言:
- 基于LLM的问答系统能够理解用户的自然语言查询,不需要用户使用特定的查询语言或关键词。
2. 准确性和相关性:
- 系统可以利用LLM的强大能力来提高答案的准确性和相关性。
3. 可扩展性:
- 随着LLM的持续训练和知识库的更新,系统的知识可以不断扩展和改进。
4. 多功能性:
- 除了简单的问答,系统还可以执行更复杂的任务,如解释概念、提供推理等。
5. 用户友好:
- 系统的用户界面通常设计得非常直观,使得非技术用户也能轻松使用。
应用场景:
- 客户服务:自动回答客户的常见问题。
- 企业内部查询:帮助员工快速找到内部文档和资源。
- 教育辅助:为学生提供即时的学习资料和解释。
- 医疗咨询:为患者提供基于医学知识库的咨询服务。
总之,**基于LLM的知识库问答系统是一个强大的工具,能够为各种垂直领域提供高效、准确的信息检索和问答服务。**随着技术的发展,这类系统的性能和应用范围预计将继续扩大。

快速了解 FastGPT
FastGPT 的能力与优势
FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!

FastGPT 能力
专属 AI 客服
通过导入文档或已有问答对进行训练,让 AI 模型能根据你的文档以交互式对话方式回答问题。

简单易用的可视化界面
FastGPT 采用直观的可视化界面设计,为各种应用场景提供了丰富实用的功能。通过简洁易懂的操作步骤,可以轻松完成 AI 客服的创建和训练流程。
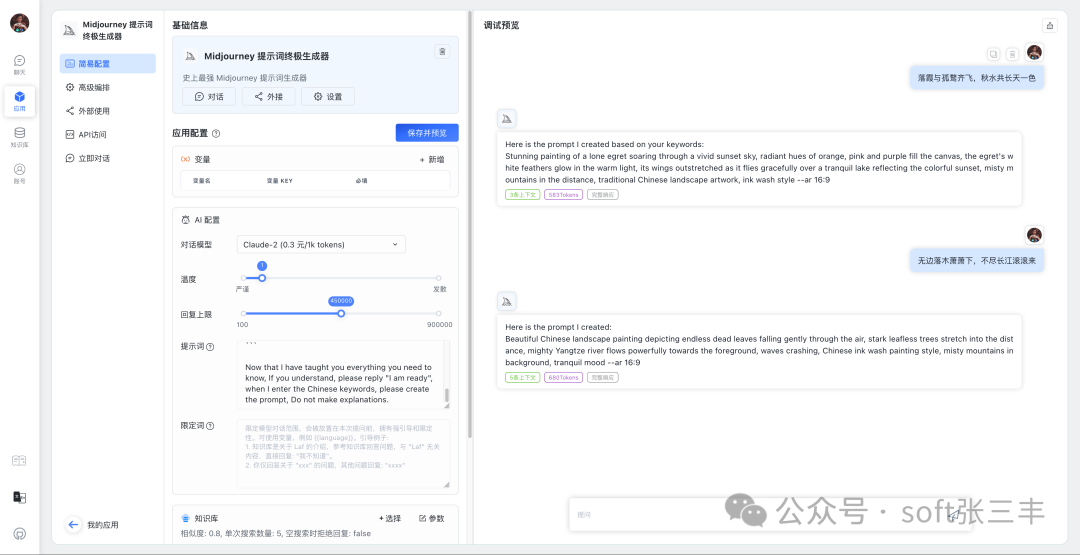
自动数据预处理
提供手动输入、直接分段、LLM 自动处理和 CSV 等多种数据导入途径,其中“直接分段”支持通过 PDF、WORD、Markdown 和 CSV 文档内容作为上下文。FastGPT 会自动对文本数据进行预处理、向量化和 QA 分割,节省手动训练时间,提升效能。

工作流编排
基于 Flow 模块的工作流编排,可以帮助你设计更加复杂的问答流程。例如查询数据库、查询库存、预约实验室等。

强大的 API 集成
FastGPT 对外的 API 接口对齐了 OpenAI 官方接口,可以直接接入现有的 GPT 应用,也可以轻松集成到企业微信、公众号、飞书等平台。

FastGPT 特点 link
-
项目开源
FastGPT 遵循附加条件 Apache License 2.0 开源协议,你可以 Fork 之后进行二次开发和发布。FastGPT 社区版将保留核心功能,商业版仅在社区版基础上使用 API 的形式进行扩展,不影响学习使用。
-
独特的 QA 结构
针对客服问答场景设计的 QA 结构,提高在大量数据场景中的问答准确性。
-
可视化工作流
通过 Flow 模块展示了从问题输入到模型输出的完整流程,便于调试和设计复杂流程。
-
无限扩展
基于 API 进行扩展,无需修改 FastGPT 源码,也可快速接入现有的程序中。
-
便于调试
提供搜索测试、引用修改、完整对话预览等多种调试途径。
-
支持多种模型
支持 GPT、Claude、文心一言等多种 LLM 模型,未来也将支持自定义的向量模型。