文章目录
- 1. 写在前面
- 2. 抓包分析
【🏠作者主页】:吴秋霖
【💼作者介绍】:擅长爬虫与JS加密逆向分析!Python领域优质创作者、CSDN博客专家、阿里云博客专家、华为云享专家。一路走来长期坚守并致力于Python与爬虫领域研究与开发工作!
【🌟作者推荐】:对爬虫领域以及JS逆向分析感兴趣的朋友可以关注《爬虫JS逆向实战》《深耕爬虫领域》
未来作者会持续更新所用到、学到、看到的技术知识!包括但不限于:各类验证码突防、爬虫APP与JS逆向分析、RPA自动化、分布式爬虫、Python领域等相关文章
作者声明:文章仅供学习交流与参考!严禁用于任何商业与非法用途!否则由此产生的一切后果均与作者无关!如有侵权,请联系作者本人进行删除!
1. 写在前面
目前爬虫的领域是非常卷的!经常有很多小伙伴咨询如何学习、或者其他语言的开发者也想要研究学习。多终端采集的需求及要求在很多企业中都会涵盖。本期,用一个之前写的案例来说一下小程序爬虫的基础!小程序端接口如果没有加密的话。是非常简单的!考验的无非就是请求路径的规划,工程化爬虫程序的开发。以及抓包去分析一下需要爬取的数据接口,最后抓取解析持久化。今天,带来一个简单的小程序爬虫,没有任何加密与反爬虫措施,新手小白可以学习一下
当然,爬虫更多的可能不会是一次性采集,大多业务数据的需求都会有增量、更新等此类需求。这个就需要一些经验与技术栈的积累去构建一个7*24持续采集、实时监控、去重增量的爬虫项目
2. 抓包分析
首先,我们打开PC端微信中的小程序,然后搜索一下需要爬取的小程序。这里抓包工具的话大家自行选择即可,我这里使用的是Charles,配置的话很简单,网上的教程很多,大家自行搜索配置即可!

这个小程序的话接口是没有加密参数的,板块比较多我们就尝试抓取考点练习这个类目下的所有数据,点击这个板块可以看到会出现更多的章节,这个也我们可以理解为网站的列表页(如新闻类网站),直接抓包分析一下,如下所示:

如上抓包图,作者分别标记出了1~4的步骤流程,代表的意思就是想要抓取到完整的题目数据,那么就需要请求上面标记的4个接口,分别如下:
- 一级列表栏目
- 二级列表栏目
- 考题概览页面
- 考题解析页面
好的,现在我们先看第一个接口(一级栏目),接口路径study/getUnitlist,需要获取获取这个接口响应JSON数据中的unitid、knowPointList字段,用以请求二级栏目,你可以理解为这是一个唯一的ID,接口抓包数据跟请求参数提交分别如下所示:
data = {
"sessionid": self.sessionid, # 小程序的Session、自行获取(固值)
"uid": self.uid, # 同样固定的、抓包请求头内获取
"courseid": "1543",
"type": "1"
}

拿到unitid、knowPointList字段后,我们开始构建下一次的请求,拿到题目的访问页面参数,请求接口路径study/getLastPaper,这个接口我们需要获取paperid字段来请求具体的试题,接口抓包数据跟请求参数提交分别如下所示:
data = {
"sessionid": self.sessionid, # 小程序的Session、自行获取(固值)
"uid": self.uid, # 同样固定的、抓包请求头内获取
"courseid": "1543",
"type": "17",
"unitid": unitid, # 上面拿到的
"market": "weixinapp_xxzx",
"kpid": kpid # 代表板块ID、每一个都是固定的
}

拿到paperid之后我们就可以拿到试题的具体内容了。这个接口的请求路径study/loadrecordpaper,我们只需拿list内的qid用来查看请求最终的试题解析内容,接口抓包数据跟请求参数分别如下所示:
data = {
"sessionid": self.sessionid,
"uid": self.uid,
"paperid": paperid, # 上级接口拿的
"courseid": "1543",
"unitid": unitid, # 一级接口拿到的、记得传递过来
"type": "31",
"market": "weixinapp_xxzx",
"from": "weixinapp"
}

在上面我们拿到了试题的qid,就可以直接去请求题型解析接口,接口请求路径question/loadQuestion,从这个接口去获取完整的一个数据,它是包含题目、以及答案解析的,接口抓包数据跟请求参数分别如下所示:
data = {
"sessionid": self.sessionid,
"uid": self.uid,
"courseid": "1543",
"unitid": unitid, # 一级接口内、记得传递
"qid": qid, # 上级接口
"paperid": paperid, # 二级接口内、记得传递
"type": "17",
"market": "weixinapp_xxzx",
"videosource": ""
}

其实这个小程序的整个流程接口是比较多的,从列表进去到最终获取到题与解析答案需要多级接口去请求,在请求的过程中还需要携带之前接口响应数据中的某些字段。难度其实是没有的,就是需要在做的时候抓包分析后把接口、响应、请求拿下来捋一下!这样的话就清晰了,最终作者也是放上完整的爬虫请求代码,大家替换一下session跟uid就可以直接运行程序,完整代码如下所示:
# -*- coding: utf-8 -*-
import time
import requests
from loguru import logger
class YtkSpider(object):
def __init__(self):
self.headers = {
"Host": "ytkapi.cnbkw.com",
"Accept": "*/*",
"User-Agent": "", #自行获取
"Referer": "", #自行获取
"Accept-Language": "zh-CN,zh-Hans;q=0.9"
}
self.sessionid = '' #自行获取
self.uid = '' #自行获取
self.count = 0
def get_loadQuestion(self, qid, paperid, unitid, status=None):
url = "https://ytkapi.cnbkw.com/question/loadQuestion"
data = {
"sessionid": self.sessionid,
"uid": self.uid,
"courseid": "1543",
"unitid": unitid,
"qid": qid,
"paperid": paperid,
"type": "17",
"market": "weixinapp_xxzx",
"videosource": ""
}
response = requests.post(url, headers=self.headers, data=data).json()
print(response)
= def loadrecordpaper(self, paperid, unitid):
url = "https://ytkapi.cnbkw.com/study/loadrecordpaper"
data = {
"sessionid": self.sessionid,
"uid": self.uid,
"paperid": paperid,
"courseid": "1543",
"unitid": unitid,
"type": "31",
"market": "weixinapp_xxzx",
"from": "weixinapp"
}
response = requests.post(url, headers=self.headers, data=data).json()
data_list = response.get('list', [])
if data_list:
for data in data_list:
qid = data.get('qid', '')
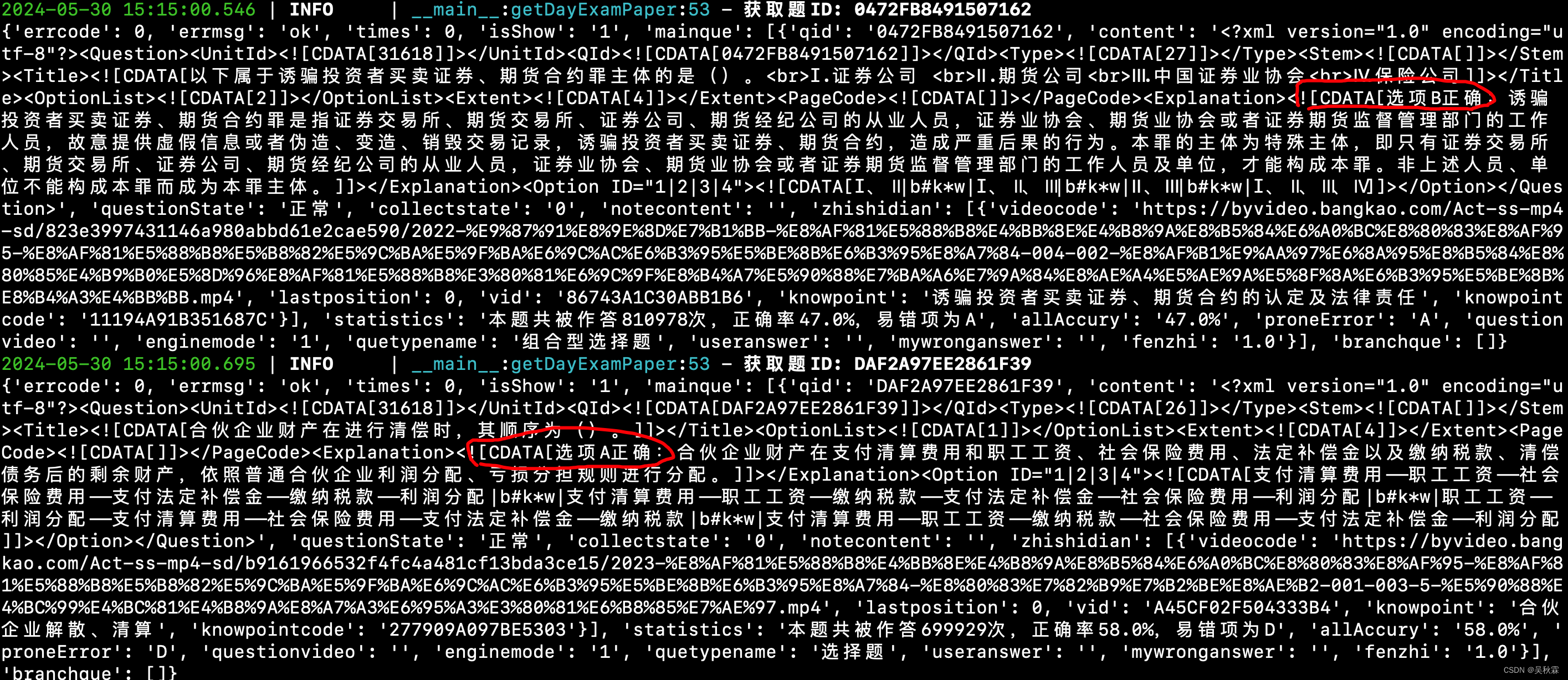
logger.info(f'获取题ID: {qid}')
self.get_loadQuestion(qid, paperid, unitid, status=True)
# 考点练习列表
def getUnitlist(self):
url = "https://ytkapi.cnbkw.com/study/getUnitlist"
data = {
"sessionid": self.sessionid,
"uid": self.uid,
"courseid": "1543",
"type": "1"
}
response = requests.post(url, headers=self.headers, data=data).json()
unitlist = response.get('unitlist', [])
for data in unitlist:
knowPointList = data.get('knowPointList', [])
unitid = data.get('unitid', [])
for kpid in knowPointList:
knowPointId = kpid.get('knowPointId')
self.getLastPaper(knowPointId, unitid)
# 考点练习题
def getLastPaper(self, kpid, unitid):
url = "https://ytkapi.cnbkw.com/study/getLastPaper"
data = {
"sessionid": self.sessionid,
"uid": self.uid,
"courseid": "1543",
"type": "17",
"unitid": unitid,
"market": "weixinapp_xxzx",
"kpid": kpid
}
response = requests.post(url, headers=self.headers, data=data).json()
paperid = response.get('paperid', '')
if paperid:
self.loadrecordpaper(paperid, unitid)
else:
logger.error(f'请导入题库: {response}')
if __name__ == '__main__':
obj = YtkSpider()
obj.getUnitlist()
最后,我们直接本地运行上面的爬虫程序,即可爬取到所有考题的相关完整数据信息,可以看到它将正确的选项放在了XML文本内,这个自己提取即可,如下所示: