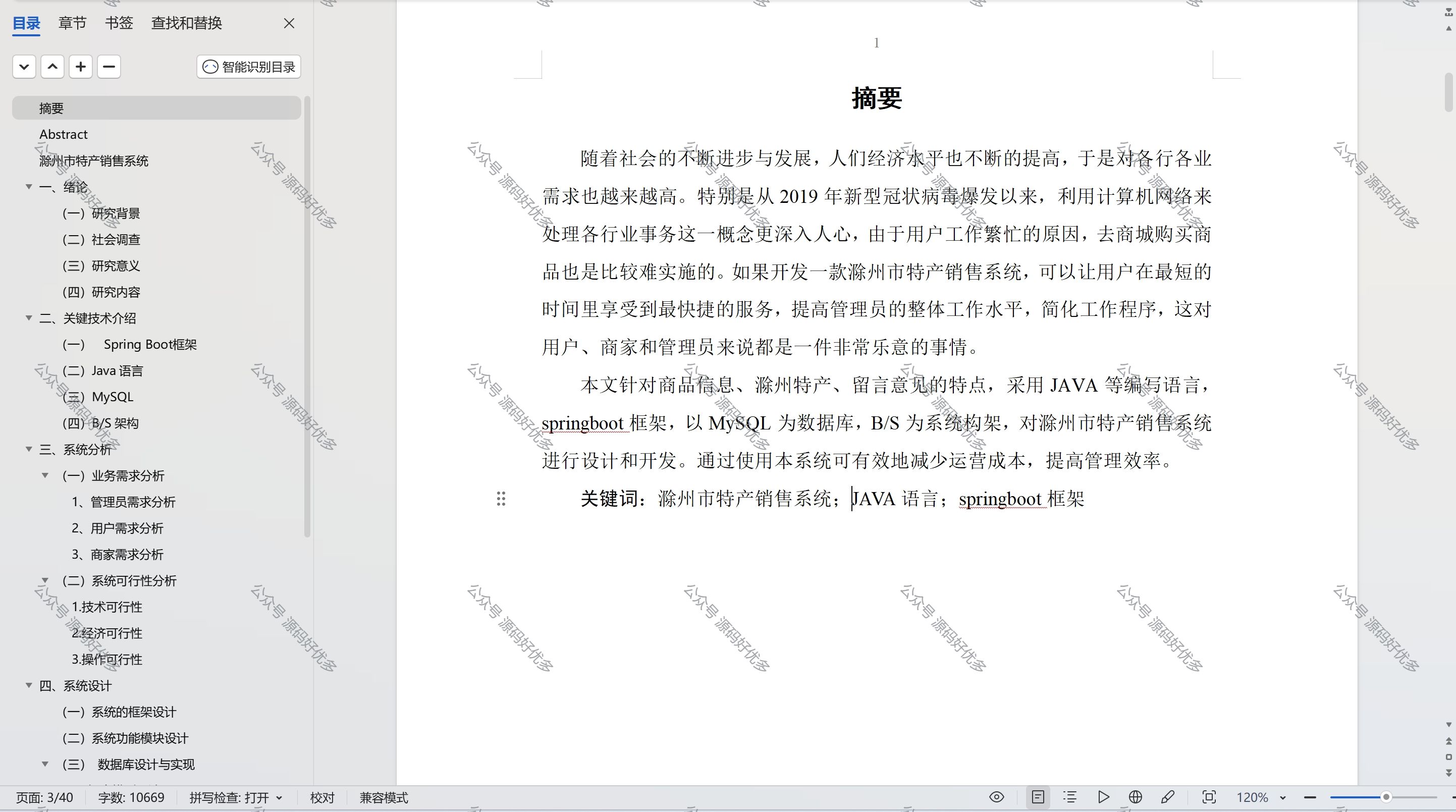
Redis 提供了丰富且高效的数据结构,支持多种类型的操作,可以满足不同场景下的存储需求。以下是 Redis 中的主要数据结构及其应用场景和特点:
1. 字符串(String)
字符串是 Redis 中最基础的数据类型,所有键值最终都可以以字符串的形式存储。
- 特点:单个字符串值最大可达 512 MB。
- 常用命令:
SET、GET、INCR、DECR、APPEND、STRLEN。 - 应用场景:计数器、简单的 key-value 存储、缓存 JSON 数据、分布式锁(通过
SETNX实现)。
例子:
SET myKey "Hello, Redis!"
GET myKey # 返回 "Hello, Redis!"
INCR myCounter # 将 myCounter 的值加 1
2. 列表(List)
列表是一种链表结构,可以在列表的头部和尾部快速插入和删除元素。
- 特点:适合按照顺序存储一组元素,支持双向链表的操作。
- 常用命令:
LPUSH、RPUSH、LPOP、RPOP、LRANGE、LLEN。 - 应用场景:消息队列(可使用
LPUSH和RPOP实现队列)、任务列表、时间序列数据存储。
例子:
LPUSH myList "Redis"
LPUSH myList "is"
LPUSH myList "awesome"
LRANGE myList 0 -1 # 返回 ["awesome", "is", "Redis"]
3. 集合(Set)
集合是一种无序的集合数据结构,元素唯一且不重复。
- 特点:Redis 会自动去重,适合存储唯一性要求的集合。
- 常用命令:
SADD、SREM、SMEMBERS、SISMEMBER、SUNION、SINTER。 - 应用场景:标签系统、共同好友、去重操作、社交网络中的共同关注者。
例子:
SADD mySet "apple"
SADD mySet "banana"
SADD mySet "apple" # "apple" 已存在,不会重复添加
SMEMBERS mySet # 返回 ["apple", "banana"]
4. 有序集合(Sorted Set)
有序集合与集合类似,但每个元素都会关联一个分数(score),Redis 根据分数自动排序。
- 特点:可以按分数排序,适合实现排名系统。
- 常用命令:
ZADD、ZRANGE、ZRANGEBYSCORE、ZREM、ZCOUNT。 - 应用场景:排行榜、延时队列、带权重的排序任务(如排行榜中用户的分数排序)。
例子:
ZADD mySortedSet 100 "Alice"
ZADD mySortedSet 200 "Bob"
ZRANGE mySortedSet 0 -1 WITHSCORES # 返回 ["Alice", 100, "Bob", 200]
5. 哈希(Hash)
哈希是一种键值对集合,适合存储对象属性(类似于 JSON 对象)。
- 特点:每个哈希键下可以存储多个字段,适合存储对象的多属性值。
- 常用命令:
HSET、HGET、HGETALL、HDEL、HINCRBY。 - 应用场景:用户信息存储、配置项、对象的字段值(如用户ID、用户名、用户年龄等)。
例子:
HSET user:1001 name "Alice"
HSET user:1001 age "30"
HGETALL user:1001 # 返回 {"name": "Alice", "age": "30"}
6. 位图(Bitmap)
位图是基于字符串的特殊数据结构,可以进行位操作,每个位可以存储 0 或 1。
- 特点:使用位操作存储布尔状态,能有效节省空间。
- 常用命令:
SETBIT、GETBIT、BITCOUNT、BITOP。 - 应用场景:用户签到、活跃用户统计、布尔标记存储(如用户是否在线)。
例子:
SETBIT user_activity 1 1 # 设置用户 1 活跃
SETBIT user_activity 2 1 # 设置用户 2 活跃
BITCOUNT user_activity # 返回活跃用户数量
7. HyperLogLog
HyperLogLog 是一种用于基数统计的概率性数据结构,可以用极少的内存(12 KB)来估算独立元素的数量,适合大规模数据去重统计。
- 特点:内存占用小,但会有一定误差,误差率约为 0.81%。
- 常用命令:
PFADD、PFCOUNT、PFMERGE。 - 应用场景:UV 统计、页面访问去重、唯一性统计(比如每天有多少唯一用户访问)。
例子:
PFADD myHyperLogLog "user1"
PFADD myHyperLogLog "user2"
PFCOUNT myHyperLogLog # 返回去重后的用户数
8. 地理位置(GEO)
GEO 是 Redis 中用于存储地理位置数据的结构,支持地理坐标存储和基于位置的查询。
- 特点:可以存储经纬度并计算位置间的距离,支持基于半径的范围查询。
- 常用命令:
GEOADD、GEODIST、GEORADIUS、GEOPOS。 - 应用场景:查找附近的用户或地点、基于地理位置的推荐系统。
例子:
GEOADD myGeoSet 116.407526 39.90403 "Beijing"
GEOADD myGeoSet 121.473701 31.230416 "Shanghai"
GEODIST myGeoSet "Beijing" "Shanghai" km # 返回两地距离
9. 流(Stream)
流是 Redis 5.0 之后引入的一种消息队列数据结构,支持高效的消息存储和处理。
- 特点:支持消息队列的生产与消费,可以用于实时数据流处理。
- 常用命令:
XADD、XREAD、XGROUP、XDEL。 - 应用场景:消息队列、事件存储、实时数据处理(如日志收集、订单系统)。
例子:
XADD myStream * sensor_id 1 temperature 22.5
XADD myStream * sensor_id 2 temperature 23.1
XREAD COUNT 2 STREAMS myStream 0 # 读取消息流中的数据
总结
Redis 提供的多种数据结构不仅丰富而且高效,适合多种应用场景:
- 字符串(String):最基础的键值对数据结构,适合简单的数据存储。
- 列表(List):适合需要有序的队列和栈操作。
- 集合(Set):适合去重和集合运算。
- 有序集合(Sorted Set):适合排名和排序需求。
- 哈希(Hash):适合存储对象的属性。
- 位图(Bitmap):适合布尔值存储,节省空间。
- HyperLogLog:适合大规模基数统计。
- 地理位置(GEO):适合基于地理位置的服务。
- 流(Stream):适合实时数据流处理和消息队列。
Redis 的多种数据结构,使得它不仅仅是一个简单的键值对数据库,更是一个功能强大的内存数据存储系统,可以应用于缓存、排行榜、消息队列、实时分析等多种场景。