文章目录
- 一、LoRA工作原理
- 1.1 基本原理
- 1.2 实现步骤
- 二、LoRA 实现
- 2.1 PEFT库:高效参数微调
- LoraConfig类:配置参数
- 2.2 TRL库
- SFTTrainer 类
- 三、代码实现
- 3.1 核心代码
- 3.2 完整代码
- 参考资料
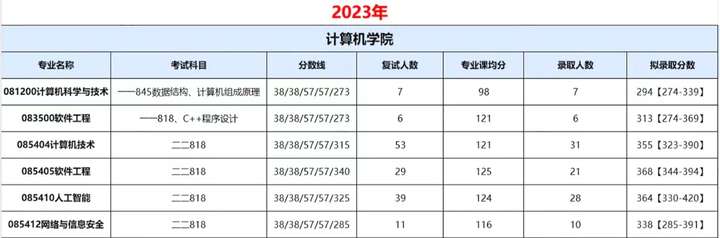
大模型微调技术有很多,如P-Tuning、LoRA 等,我们在之前的博客中也介绍过,可以参考:大模型高效参数微调技术(Prompt-Tuning、Prefix Tuning、P-Tuning、LoRA…)
在本篇文章中,我们就 LoRA (Low-Rank Adaptation) 即低秩适应的微调方法工作原理及代码实践进行介绍。
完整的微调步骤可以参考我们的博客:【大模型】基于LoRA微调Gemma大模型(2)
一、LoRA工作原理
1.1 基本原理
LoRA 是 Low-Rank Adaptation 或 Low-Rank Adaptors的首字母缩写词,它提供了一种高效且轻量级的方法,用于微调预先训练好的的大语言模型。
LoRA的核心思想是用一种低秩的方式来调整这些参数矩阵。LoRA通过保持预训练矩阵(即原始模型的参数)冻结(即处于固定状态),并且只在原始矩阵中添加一个小的增量,其参数量比原始矩阵少很多。
例如,考虑矩阵 W,它可以是全连接层的参数,也可以是来Transformer中计算自注意力机制的矩阵之一:

显然,如果 W o r i g W_{orig} Worig 的维数为 n×m,而假如我们只是初始化一个具有相同维数的新的增量矩阵进行微调,虽然我们也实现类似的功能,但是我们的参数量将会加倍。 LoRA使用的Trick就是通过训练低维矩阵 B 和 A ,通过矩阵乘法来构造 ΔW ,来使 ΔW 的参数量低于原始矩阵。

这里我们不妨定义秩 r,它明显小于基本矩阵维度 r≪n 和 r≪m。则矩阵 B 为 n×r,矩阵 A 为 r×m。将它们相乘会得到一个维度为 nxm的W 矩阵,但构建的参数量减小了很多。
LoRA原理见下图:具体来说就是固定原始模型权重,然后定义两个低秩矩阵作为新增weight参与运算,并将两条链路的结果求和后作为本层的输出,而在微调时,只梯度下降新增的两个低秩矩阵。

此外,我们希望我们的增量ΔW在训练开始时为零,这样微调就会从原始模型一样开始。因此,B通常初始化为全零,而 A初始化为随机值(通常呈正态分布)。
1.2 实现步骤
(1)选择目标层
首先,在预训练神经网络模型中选择要应用LoRA的目标层。这些层通常是与特定任务相关的,如自注意力机制中的查询Q和键K矩阵。
值得注意的是,原则上,我们可以将LoRA应用于神经网络中权矩阵的任何子集,以减少可训练参数的数量。在Transformer体系结构中,自关注模块(Wq、Wk、Wv、Wo)中有四个权重矩阵,MLP模块中有两个权重矩阵。我们将Wq(或Wk,Wv)作为维度的单个矩阵,尽管输出维度通常被切分为注意力头。
(2)初始化映射矩阵和逆映射矩阵
为目标层创建两个较小的矩阵A和B,然后进行变换。
参数变换过程:将目标层的原始参数矩阵W通过映射矩阵A和逆映射矩阵B进行变换,计算公式为: W ′ = W + A ∗ B W' = W + A * B W′=W+A∗B,这里W’是变换后的参数矩阵。
其中,矩阵的大小由LoRA的秩(rank)和alpha值确定。

(3)微调模型
使用新的参数矩阵替换目标层的原始参数矩阵,然后在特定任务的训练数据上对模型进行微调。
(4)梯度更新
在微调过程中,计算损失函数关于映射矩阵A和逆映射矩阵B的梯度,并使用优化算法(如Adam、SGD等)对A和B进行更新。
注意:在更新过程中,原始参数矩阵W保持不变。其实也就是训练的时候固定原始PLM的参数,只训练降维矩阵A与升维矩阵B (W is frozen and does not receive gradient updates, while A and B contain trainableparameters )
(5)重复更新
在训练的每个批次中,重复步骤3-5,直到达到预定的训练轮次(epoch)或满足收敛条件。
且当需要切换到另一个下游任务时,可以通过减去B A然后添加不同的B’ A’来恢复W,这是一个内存开销很小的快速操作。
When we need to switch to another downstream task, we can recover W0 by subtracting BA andthen adding a different B0A0, a quick operation with very little memory overhead.
总之,LoRA的详细步骤包括:选择目标层、初始化映射矩阵和逆映射矩阵、进行参数变换和模型微调。在微调过程中,模型会通过更新映射矩阵U和逆映射矩阵V来学习特定任务的知识,从而提高模型在该任务上的性能。
二、LoRA 实现
这里主要介绍几个与 LoRA 实现相关的类库。
2.1 PEFT库:高效参数微调
Huggingface公司推出的 PEFT (Parameter-Efficient Fine-Tuning,即高效参数微调之意) 库封装了LoRA这个方法,PEFT库可以使预训练语言模型高效适应各种下游任务,而无需微调模型的所有参数,即仅微调少量(额外)模型参数,从而大大降低了计算和存储成本。
peft:全称为Parameter-Efficient Fine-Tuning,PEFT。peft是一种专门为高效调参而设计的深度学习库,其使用了类似于只是蒸馏的技术,通过在预训练模型上添加少量数据来进行微调,从而实现将预训练模型的知识迁移到新的微调模型中。
Github地址:https://github.com/huggingface/peft
LoraConfig类:配置参数
from peft import LoraConfig
LoraConfig是Hugging Face transformers库中用于配置LoRA(Low-Rank Adaptation)的类。LoraConfig允许用户设置以下关键参数来定制LoRA训练:
- r: 低秩矩阵的秩,即添加的矩阵的第二维度,控制了LoRA的参数量。
- alpha: 权重因子,用于在训练后将LoRA适应的权重与原始权重相结合时的缩放。
- lora_dropout: LoRA层中的dropout率,用于正则化。
- target_modules: 指定模型中的哪些模块(层)将应用LoRA适应。这允许用户集中资源在对任务最相关的部分进行微调。
- bias: 是否在偏置项上应用LoRA,通常设置为’none’或’all’。
- task_type: 指定任务类型,如’CAUSAL_LM’,以确保LoRA适应正确应用到模型的相应部分。
2.2 TRL库
trl 库:全称为Transformer Reinforcement Learning,TRL是使用强化学习的全栈Transformer语言模型。trl 是一个全栈库,其中我们提供一组工具,用于通过强化学习训练Transformer语言模型和稳定扩散模型,从监督微调步骤(SFT)到奖励建模步骤(RM)再到近端策略优化(PPO)步骤。该库建立在Hugging Face 的 transformers 库之上。
Github地址:TRL - Transformer Reinforcement Learning
SFTTrainer 类
from trl import SFTTrainer
SFTTrainer 是 transformers.Trainer的子类,增加了处理PeftConfig的逻辑,可轻松在自定义数据集上微调语言模型或适配器。
三、代码实现
3.1 核心代码
(1)训练阶段
- LoraConfig:定义LoRA微调参数
from peft import LoraConfig
lora_config = LoraConfig(
r=8,
# lora_alpha=16,
target_modules=["q_proj", "o_proj", "k_proj", "v_proj", "gate_proj", "up_proj", "down_proj"],
# lora_dropout=0.05,
task_type="CAUSAL_LM", # 因果语言模型
)
- SFTTrainer:基于Lora进行微调
from trl import SFTTrainer
trainer = SFTTrainer(
model=model,
train_dataset=data["train"],
args=transformers.TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
warmup_steps=2,
max_steps=10, # 最大迭代次数
learning_rate=2e-4,
fp16=True,
logging_steps=1,
output_dir="./outputs/gemma-new", # 微调后模型的输出路径
optim="paged_adamw_8bit"
),
peft_config=lora_config,
formatting_func=formatting_func,
)
# 开始训练
trainer.train()
(2)推理阶段
训练完成后,我们需要将 LoRA 模型 与 基础模型 进行合并,来进行推理。核心代码如下:
base_model_path = "./model/gemma-2b"
peft_model_path = "./outputs/gemma-new/checkpoint-500"
base_model = AutoModelForCausalLM.from_pretrained(base_model_path, return_dict=True, device_map=device, torch_dtype=torch.float16)
tokenizer = AutoTokenizer.from_pretrained(base_model_path)
# print(model)
# 加载LoRA模型(基础模型+微调模型)
merged_model = PeftModel.from_pretrained(base_model, peft_model_path)
# print(model)
3.2 完整代码
这里,我们以微调gemma-2b 模型为例,完整的微调步骤可以参考博客:【大模型】基于LoRA微调Gemma大模型(2)
主要包含 train.py 和 infer.py 两个文件,具体代码如下:
- train.py
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '1'
import torch
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from datasets import load_dataset
from peft import LoraConfig
from trl import SFTTrainer
device = "cuda:0"
# 定义量化参数
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # 启用4位加载
bnb_4bit_quant_type="nf4", # 指定用于量化的数据类型。支持两种量化数据类型: fp4 (四位浮点)和 nf4 (常规四位浮点)
bnb_4bit_compute_dtype=torch.bfloat16 # 用于线性层计算的数据类型
)
model_path = "./model/gemma-2b" # chatglm2-6b, gemma-2b
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True, device_map=device) # quantization_config=bnb_config
# 测试原始模型的输出
text = "Quote: Imagination is more"
inputs = tokenizer(text, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_new_tokens=30)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
# 加载微调数据集
# data = load_dataset(data_path) # 加载远程数据集
data_path = "./data/english_quotes/quotes.jsonl" # 本地数据文件路径
data = load_dataset('json', data_files=data_path) # 加载本地数据文件
data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)
print(data)
# 定义格式化函数
def formatting_func(example):
raise RuntimeError("if you can read this, formatting_func was called")
text = f"Quote: {example['quote'][0]}\nAuthor: {example['author'][0]}<eos>"
return [text]
print(formatting_func(data["train"]))
# 定义LoRA微调参数
lora_config = LoraConfig(
r=8,
# lora_alpha=16,
target_modules=["q_proj", "o_proj", "k_proj", "v_proj", "gate_proj", "up_proj", "down_proj"],
# lora_dropout=0.05,
task_type="CAUSAL_LM", # 因果语言模型
)
# 基于Lora进行微调
trainer = SFTTrainer(
model=model,
train_dataset=data["train"],
args=transformers.TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
warmup_steps=2,
max_steps=10, # 最大迭代次数
learning_rate=2e-4,
fp16=True,
logging_steps=1,
output_dir="./outputs/gemma-new", # 微调后模型的输出路径
optim="paged_adamw_8bit"
),
peft_config=lora_config,
formatting_func=formatting_func,
)
trainer.train()
# trainer.save_model(trainer.args.output_dir)
- infer.py
import torch
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda:1"
base_model_path = "./model/gemma-2b" # chatglm2-6b, gemma-2b
peft_model_path = "./outputs/gemma-new/checkpoint-500"
base_model = AutoModelForCausalLM.from_pretrained(base_model_path, return_dict=True, device_map=device, torch_dtype=torch.float16)
tokenizer = AutoTokenizer.from_pretrained(base_model_path)
# print(model)
# 加载LoRA模型(基础模型+微调模型)
merged_model = PeftModel.from_pretrained(base_model, peft_model_path)
# print(model)
# 测试1
text = "Quote: Imagination is more"
inputs = tokenizer(text, return_tensors="pt").to(device)
参考资料
-
google/gemma-7b官方示例:https://huggingface.co/google/gemma-7b/blob/main/examples/notebook_sft_peft.ipynb
-
使用 Hugging Face 微调 Gemma 模型
-
【AI大模型】Transformers大模型库(八):大模型微调之LoraConfig
-
【机器学习】QLoRA:基于PEFT亲手量化微调Qwen2大模型