文章目录
- 一、关于 TransformerEngine ?
- 亮点
- 二、使用示例
- PyTorch
- JAX
- Flax
- 三、安装
- 先决条件
- Docker
- pip
- 从源码
- 使用 FlashAttention-2 编译
- 四、突破性的变化
- v1.7: Padding mask definition for PyTorch
- 五、FP8 收敛
- 六、集成
- 七、其它
- 贡献
- 论文
- 视频
- 最新消息
一、关于 TransformerEngine ?
- github : https://github.com/NVIDIA/TransformerEngine
- 官方文档:https://docs.nvidia.com/deeplearning/transformer-engine/user-guide/index.html
- 示例:https://github.com/NVIDIA/TransformerEngine/tree/main/examples
- 版本发行说明:https://docs.nvidia.com/deeplearning/transformer-engine/release-notes/index.html
TransformerEngine (TE)是一个库,用于在NVIDIA GPU上加速 Transformer models ,包括在Hopper GPU上使用8位浮点(FP8)精度,以在训练和推理中以较低的记忆利用率提供更好的性能。
TE为流行的 Transformer 架构提供了一组高度优化的构建块,以及一个自动混合精度类API,可以与您的框架特定代码无缝使用。
TE还包括一个与框架无关的C++API,可以与其他深度学习库集成,以启用FP8对 Transformer 的支持。
随着 Transformer models 中参数数量的不断增长,BERT、GPT和T5等架构的训练和推理变得非常记忆和计算密集型。
大多数深度学习框架默认使用FP32进行训练。
然而,要实现许多深度学习模型的全精度,这并不是必不可少的。
在训练模型时,使用混合精度训练(将单精度(FP32)与较低精度(例如FP16)格式相结合),与FP32训练相比,在精度差异最小的情况下,可以显著提高速度。
通过Hopper GPU架构,引入了FP8精度,它提供了优于FP16的性能,而精度没有下降。
尽管所有主要的深度学习框架都支持FP16,但FP8支持在当今的框架中并不存在。
TE通过提供与流行的大型语言模型(LLM)库集成的API来解决FP8支持问题。
它提供了一个由模块组成的Python应用编程接口,可以轻松构建转换器层,以及一个与框架无关的库,C++包括FP8支持所需的结构和内核。
TE内部提供的模块维护了FP8训练所需的缩放因子和其他值,极大地简化了用户的混合精度训练。
亮点
- 易于使用的模块,用于构建支持FP8的 Transformer 层
- Transformer models 的优化(例如融合内核)
- 在 NVIDIA Hopper 和 NVIDIA Ada GPU 上支持FP8
- 支持 NVIDIA Ampere GPU 架构代及更高版本上所有精度(FP16、BF16)的优化
二、使用示例
PyTorch
import torch
import transformer_engine.pytorch as te
from transformer_engine.common import recipe
# Set dimensions.
in_features = 768
out_features = 3072
hidden_size = 2048
# Initialize model and inputs.
model = te.Linear(in_features, out_features, bias=True)
inp = torch.randn(hidden_size, in_features, device="cuda")
# Create an FP8 recipe. Note: All input args are optional.
fp8_recipe = recipe.DelayedScaling(margin=0, fp8_format=recipe.Format.E4M3)
# Enable autocasting for the forward pass
with te.fp8_autocast(enabled=True, fp8_recipe=fp8_recipe):
out = model(inp)
loss = out.sum()
loss.backward()
JAX
Flax
import flax
import jax
import jax.numpy as jnp
import transformer_engine.jax as te
import transformer_engine.jax.flax as te_flax
from transformer_engine.common import recipe
BATCH = 32
SEQLEN = 128
HIDDEN = 1024
# Initialize RNG and inputs.
rng = jax.random.PRNGKey(0)
init_rng, data_rng = jax.random.split(rng)
inp = jax.random.normal(data_rng, [BATCH, SEQLEN, HIDDEN], jnp.float32)
# Create an FP8 recipe. Note: All input args are optional.
fp8_recipe = recipe.DelayedScaling(margin=0, fp8_format=recipe.Format.HYBRID)
# Enable autocasting for the forward pass
with te.fp8_autocast(enabled=True, fp8_recipe=fp8_recipe):
model = te_flax.DenseGeneral(features=HIDDEN)
def loss_fn(params, other_vars, inp):
out = model.apply({'params':params, **other_vars}, inp)
return jnp.mean(out)
# Initialize models.
variables = model.init(init_rng, inp)
other_variables, params = flax.core.pop(variables, 'params')
# Construct the forward and backward function
fwd_bwd_fn = jax.value_and_grad(loss_fn, argnums=(0, 1))
for _ in range(10):
loss, (param_grads, other_grads) = fwd_bwd_fn(params, other_variables, inp)
三、安装
先决条件
- Linuxx86_64
- 用于 Hopper 的 CUDA 11.8+ 和用于 Ada的CUDA 12.1+
- 支持 CUDA 11.8 或更高版本的NVIDIA驱动程序
- cuDNN 8.1或更高版本
- 对于融合注意力,CUDA 12.1 或更高版本,NVIDIA驱动程序支持 CUDA 12.1 或更高版本,以及 cuDNN 8.9 或更高版本。
Docker
开始使用 TransformerEngine 的最快方法是使用Docker图像 NVIDIA GPU云(NGC)目录。
例如要交互使用NGC PyTorch容器,
docker run --gpus all -it --rm nvcr.io/nvidia/pytorch:23.10-py3
其中23.10是容器版本。例如,2023年10月发布的23.10。
pip
要安装最新稳定版本的Transform Engine,
pip install git+https://github.com/NVIDIA/TransformerEngine.git@stable
这将自动检测是否安装了任何受支持的深度学习框架,并为它们构建 TransformerEngine 支持。
要显式指定框架,请将环境变量NVTE_FRAMEWORK设置为逗号分隔的列表(例如 NVTE_FRAMEWORK=jax,pytorch)。
从源码
请参阅 安装指南。
使用 FlashAttention-2 编译
Transform Engine 版本 v0.11.0 在PyTorch中增加了对 FlashAttention-2 的支持,以提高性能。
已知问题是 FlashAttention-2 编译是资源密集型的,并且需要大量RAM(参见bug),这可能会导致Transform Engine安装过程中出现内存溢出错误。
请尝试在环境中设置 **MAX_JOBS=1**以规避该问题。
请注意,NGC PyTorch 23.08+ 容器包括 FlashAttention-2。
四、突破性的变化
v1.7: Padding mask definition for PyTorch
为了统一Transform Engine中所有三个框架中注意力掩码的定义和使用,填充掩码已从True含义包含注意力中的相应位置更改为在我们的PyTorch实现中排除该位置。
从v1.7开始,所有注意力掩码类型都遵循相同的定义,其中True表示屏蔽相应位置,False表示在注意力计算中包括该位置。
这种变化的一个例子是,
# for a batch of 3 sequences where `a`s, `b`s and `c`s are the useful tokens
# and `0`s are the padding tokens,
[a, a, a, 0, 0,
b, b, 0, 0, 0,
c, c, c, c, 0]
# the padding mask for this batch before v1.7 is,
[ True, True, True, False, False,
True, True, False, False, False,
True, True, True, True, False]
# and for v1.7 onwards it should be,
[False, False, False, True, True,
False, False, True, True, True,
False, False, False, False, True]
五、FP8 收敛
FP8 已经在不同的模型架构和配置中进行了广泛的测试,我们发现FP8和BF16训练损失曲线之间没有显著差异。
FP8 还在目标端LLM任务(例如LAMBADA和WikiText)上进行了精度验证。
以下是在不同框架中测试模型收敛的示例。
| 模型 | 框架 | 来源 |
|---|---|---|
| T5-770M | JAX/T5x | https://github.com/NVIDIA/JAX-Toolbox/tree/main/rosetta/rosetta/projects/t5x#convergence-and-performance |
| MPT-1.3B | Mosaic Composer | https://www.mosaicml.com/blog/coreweave-nvidia-h100-part-1 |
| GPT-5B | JAX/Paxml | https://github.com/NVIDIA/JAX-Toolbox/tree/main/rosetta/rosetta/projects/pax#h100-results |
| GPT-5B | NeMo框架 | 可应要求提供 |
| LLama2-7B | Alibaba Pai | https://mp.weixin.qq.com/s/NQT0uKXLbXyh5031zBdeBQ |
| T5-11B | JAX/T5x | 可应要求提供 |
| MPT-13B | Mosaic Composer | https://www.databricks.com/blog/turbocharged-training-optimizing-databricks-mosaic-ai-stack-fp8 |
| GPT-22B | NeMo框架 | 可应要求提供 |
| LLama2-70B | Alibaba Pai | https://mp.weixin.qq.com/s/NQT0uKXLbXyh5031zBdeBQ |
| GPT-175B | JAX/Paxml | https://github.com/NVIDIA/JAX-Toolbox/tree/main/rosetta/rosetta/projects/pax#h100-results |
六、集成
Transform Engine已与流行的LLM框架集成,例如:
- DeepSpeed
- Hugging Face Accelerate
- Lightning
- MosaicML Composer
- NVIDIA JAX Toolbox
- NVIDIA Megatron-LM
- NVIDIA NeMo Framework
- Amazon SageMaker Model Parallel Library
- Levanter
- Hugging Face Nanotron - Coming soon!
- Colossal-AI - Coming soon!
- PeriFlow - Coming soon!
- GPT-NeoX - Coming soon!
七、其它
贡献
我们欢迎对 TransformerEngine 的贡献!要为 TransformerEngine 做出贡献并提出拉取请求, 遵循CONTRIBUTING. rst指南中概述的指南。
论文
- Attention original paper
- Megatron-LM tensor parallel
- Megatron-LM sequence parallel
- FP8 Formats for Deep Learning
视频
- TransformerEngine 和FP8 训练的新功能 | GTC 2024
- 使用 TransformerEngine 进行FP8训练 | GTC 2023
- 用于深度学习的FP8 | GTC 2023
- Hopper 架构内部
最新消息
- [03/2024]涡轮增压训练:使用FP8优化Database ricks Mosaic AI堆栈
- [03/2024]SageMaker模型并行库中的FP8训练支持
- [12/2023]新的NVIDIA NeMo框架功能和NVIDIA H200
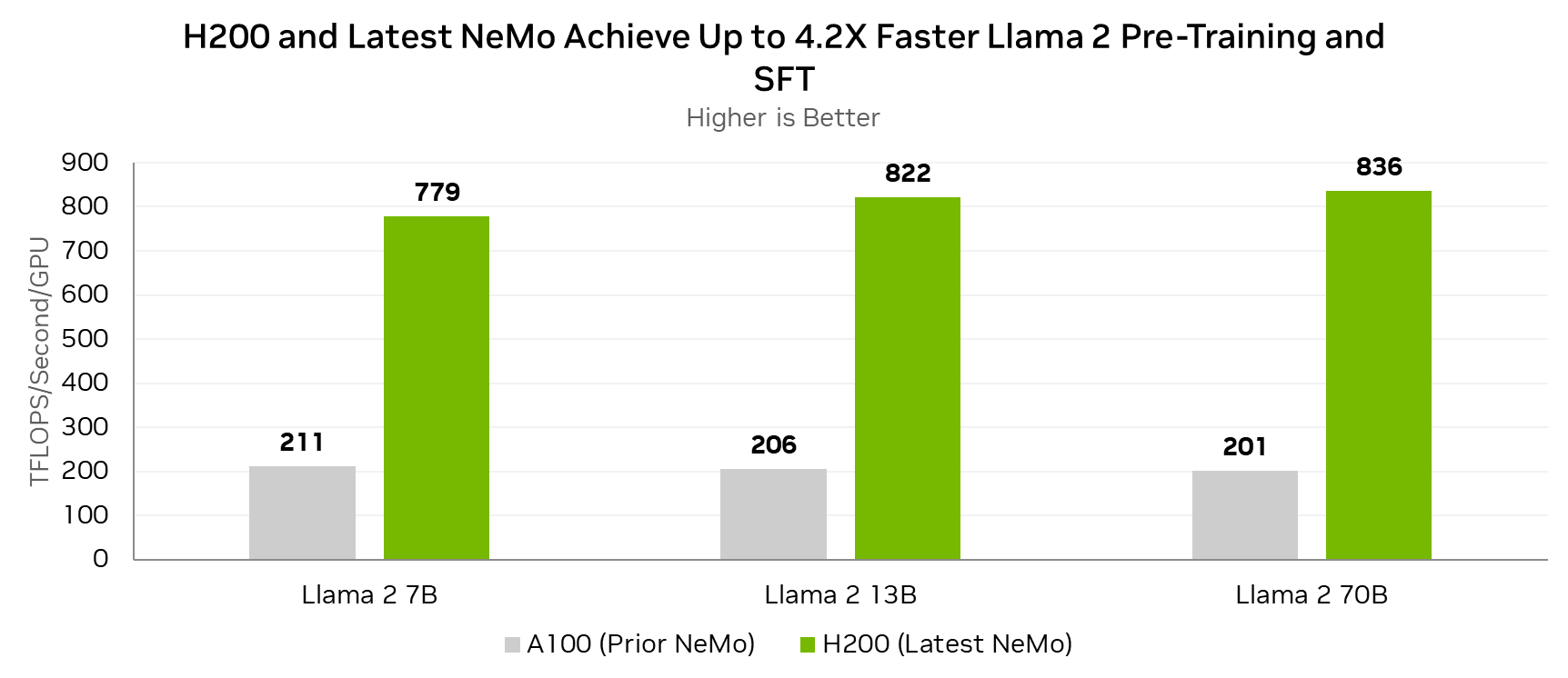
- [11/2023]拐点2:下一步
- [11/2023]利用NVIDIA TransformerEngine 释放 Transformer 的力量
- [11/2023]使用FP8加速PyTorch训练工作负载
- [09/2023] TransformerEngine 添加到AWS DL容器中用于PyTorch培训
- [06/2023]使用NVIDIA H100 GPU打破MLPerf训练记录
- [04/2023]使用CoreWeave在NVIDIA H100 GPU上对大型语言模型进行基准测试(第1部分)
2024-07-26(五)