在数据驱动的时代,企业如何高效、安全地获取互联网上的宝贵信息?定制化爬虫管理服务应运而生,成为解锁专属数据宝藏的金钥匙。本文将深入探讨定制化爬虫管理如何为企业量身打造数据抓取方案,揭秘其在海量信息中精准捕获价值数据的奥秘。
摘要:
定制化爬虫管理通过深入了解企业需求,设计并实施个性化数据抓取策略,有效应对复杂网页结构,确保数据采集的高效率与准确性。本文将围绕如何实现高效、安全的数据采集,介绍定制化爬虫的优势、实施步骤以及如何通过智能化管理提升数据处理能力,助力企业智慧决策。
一、为何选择定制化爬虫管理?
在大数据的洪流中,定制化爬虫不再是技术爱好者的专属玩具,而是转型为企业不可或缺的数据采集利器。它能够根据企业的特定需求,灵活调整抓取规则,针对性地收集市场动态、竞品分析、用户反馈等关键信息,为企业的战略规划提供坚实的数据支持。
二、定制化爬虫的核心优势
2.1 高效采集,精准匹配需求
不同于通用爬虫的“广撒网”策略,定制化爬虫直击企业需求靶心。通过精细化配置,高效采集目标网站的特定数据,大幅减少无用信息的干扰,确保数据的相关性和质量。
2.2 灵活适应,应对复杂环境
互联网环境多变,定制化爬虫能快速调整策略,应对网页结构变化、反爬虫机制等挑战,保证数据抓取的持续性和稳定性。
2.3 数据安全,合规采集
在数据保护法规日益严格的今天,定制化爬虫管理还内置合规性检查机制,确保采集过程合法、安全,避免侵犯版权或隐私风险。
三、定制化爬虫实施步骤
3.1 需求分析
首先明确企业数据需求,包括目标网站、所需数据类型、采集频率等,为定制化设计奠定基础。
3.2 规则制定与测试
依据需求设计爬虫规则,模拟抓取环境进行测试,不断调试直至达到预期效果。
3.3 实施部署与监控
在确保规则无误后,部署爬虫至服务器,利用如监控告警、运行日志查看等功能,实时跟踪采集状态,及时响应异常情况。
3.4 数据处理与分析
采集到的数据经过清洗、整合后,导入企业内部系统或第三方数据分析工具,为决策提供依据。
四、智能管理,提升数据处理能力
借助先进的算法和技术,如机器学习,定制化爬虫管理不仅能自动化处理重复任务,还能智能识别数据模式,优化抓取策略,进一步提升数据处理的效率和精准度。
常见问题与解答
Q: 定制化爬虫是否违法? A: 合法使用爬虫的关键在于遵守目标网站的robots.txt规则及当地法律法规,确保采集行为正当合理。
Q: 如何保证数据抓取的时效性? A: 通过设置合理的采集频率和高效的调度机制,确保数据新鲜度,同时利用技术手段应对网站动态变化。
Q: 数据采集后的处理流程是怎样的? A: 一般包括数据清洗、格式化、存储及分析几个环节,最终目的是让数据可读、可用。
Q: 如何保障数据抓取过程中的数据安全? A: 加密传输、访问控制、数据脱敏等措施是保障数据安全的关键。
Q: 对于初学者,如何快速入门定制化爬虫开发? A: 推荐从Python语言开始学习,利用Scrapy、BeautifulSoup等库实践,逐步深入掌握爬虫开发技巧。
强烈推荐
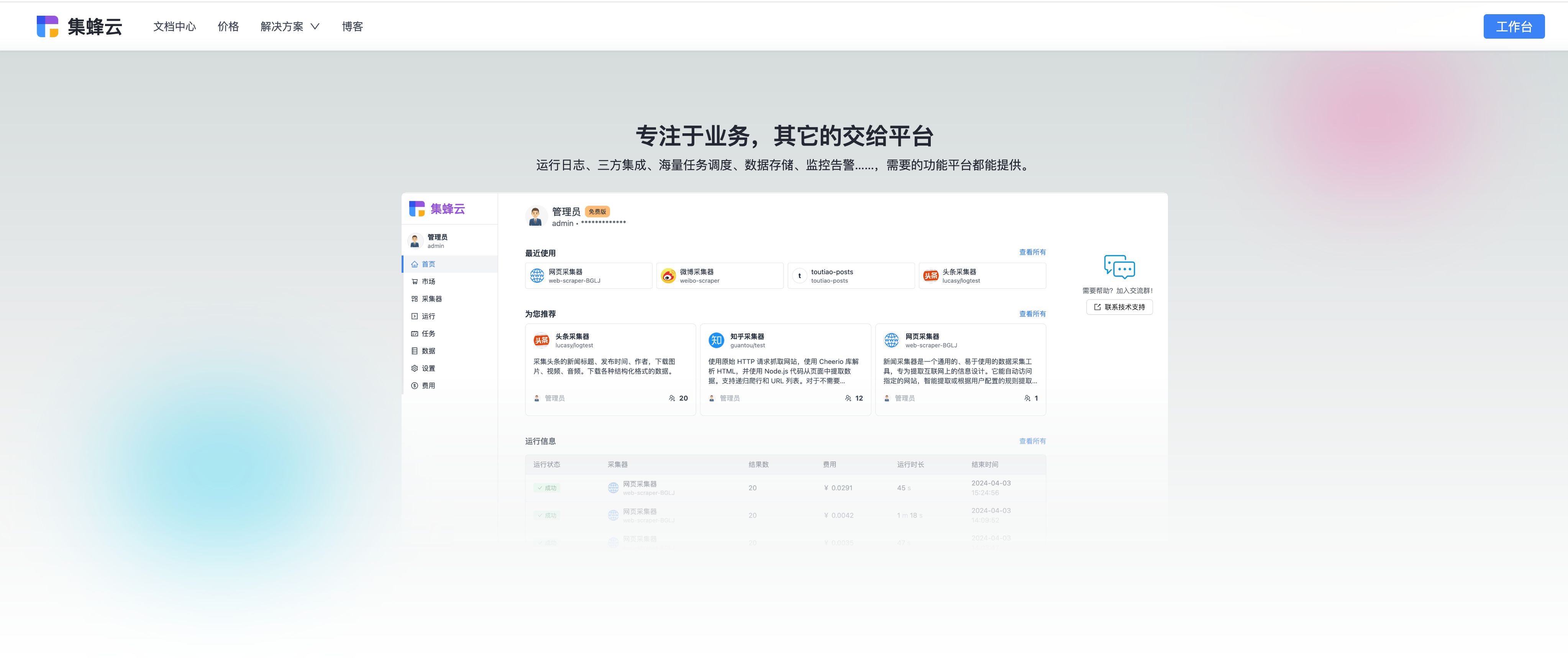
对于希望快速部署并管理高效数据采集任务的企业与开发者,集蜂云平台 提供了全面的解决方案,支持海量任务调度、三方应用集成、数据存储等功能,简化技术栈,加速数据驱动的业务进程。