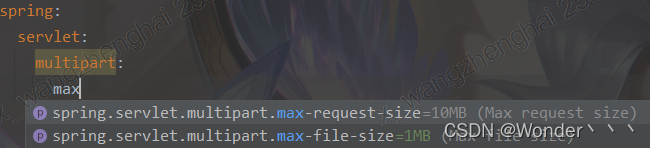
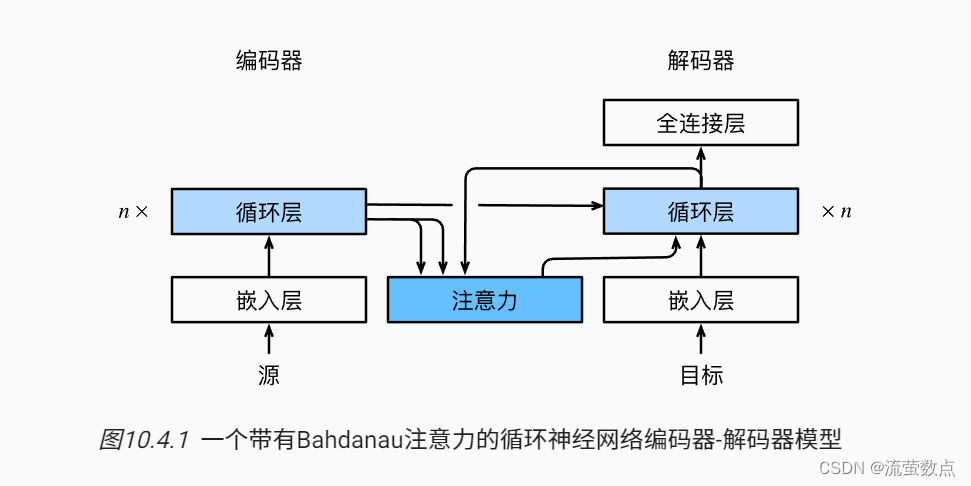
在预测词元时,如果不是所有输入词元都是相关的,那么具有Bahdanau注意力的循环神经网络编码器-解码器会有选择地统计输入序列的不同部分。这是通过将上下文变量视为加性注意力池化的输出来实现的。
在循环神经网络编码器-解码器中,Bahdanau注意力将上一时间步的解码器隐状态视为查询,在所有时间步的编码器隐状态同时视为键和值。
参考10.4. Bahdanau 注意力 — 动手学深度学习 2.0.0 documentation
序列到序列学习(seq2seq,BLEU)_流萤数点的博客-CSDN博客_序列到序列中探讨了机器翻译问题: 通过设计一个基于两个循环神经网络的编码器-解码器架构, 用于序列到序列学习。 具体来说,循环神经网络编码器将长度可变的序列转换为固定形状的上下文变量, 然后循环神经网络解码器根据生成的词元和上下文变量 按词元生成输出(目标)序列词元。 然而,即使并非所有输入(源)词元都对解码某个词元都有用, 在每个解码步骤中仍使用编码相同的上下文变量。 有什么方法能改变上下文变量呢?
我们试着从 (Graves, 2013)中找到灵感: 在为给定文本序列生成手写的挑战中, Graves设计了一种可微注意力模型, 将文本字符与更长的笔迹对齐, 其中对齐方式仅向一个方向移动。 受学习对齐想法的启发,Bahdanau等人提出了一个没有严格单向对齐限制的 可微注意力模型 (Bahdanau et al., 2014)。 在预测词元时,如果不是所有输入词元都相关,模型将仅对齐(或参与)输入序列中与当前预测相关的部分。这是通过将上下文变量视为注意力集中的输出来实现的。
目录
1.模型
2.定义注意力解码器
3.训练
1.模型
下面描述的Bahdanau注意力模型 将遵循 序列到序列学习(seq2seq,BLEU)_流萤数点的博客-CSDN博客_序列到序列中的相同符号表达。 这个新的基于注意力的模型与 9.7节中的模型相同, 只不过 (9.7.3)中的上下文变量c 在任何解码时间步t′都会被ct′替换。

假设输入序列中有T个词元, 解码时间步t′的上下文变量是注意力集中的输出:

其中,时间步t′−1时的解码器隐状态是查询, 编码器隐状态ht既是键,也是值, 注意力权重α是使用 注意力评分函数(掩蔽softmax操作,加性注意力,缩放点积注意力)_流萤数点的博客-CSDN博客所定义的加性注意力打分函数计算的。
与 图9.7.2中的循环神经网络编码器-解码器架构略有不同, 图10.4.1描述了Bahdanau注意力的架构。

pip install mxnet==1.7.0.post1pip install d2l==0.15.0d2l的版本有点低,有些模块库里面没有,需要手动加入代码。
from mxnet import np, npx
from mxnet.gluon import nn, rnn
from d2l import mxnet as d2l
npx.set_np()2.定义注意力解码器
下面看看如何定义Bahdanau注意力,实现循环神经网络编码器-解码器。 其实,我们只需重新定义解码器即可。 为了更方便地显示学习的注意力权重, 以下AttentionDecoder类定义了带有注意力机制解码器的基本接口。
#@save
class AttentionDecoder(d2l.Decoder):
"""带有注意力机制解码器的基本接口"""
def __init__(self, **kwargs):
super(AttentionDecoder, self).__init__(**kwargs)
@property
def attention_weights(self):
raise NotImplementedError接下来,让我们在接下来的Seq2SeqAttentionDecoder类中 实现带有Bahdanau注意力的循环神经网络解码器。 首先,初始化解码器的状态,需要下面的输入:
编码器在所有时间步的最终层隐状态,将作为注意力的键和值;
上一时间步的编码器全层隐状态,将作为初始化解码器的隐状态;
编码器有效长度(排除在注意力池中填充词元)。
在每个解码时间步骤中,解码器上一个时间步的最终层隐状态将用作查询。 因此,注意力输出和输入嵌入都连结为循环神经网络解码器的输入。
class Seq2SeqAttentionDecoder(AttentionDecoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqAttentionDecoder, self).__init__(**kwargs)
self.attention = AdditiveAttention(num_hiddens, dropout) #这里做了修改,后面加了代码
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = rnn.GRU(num_hiddens, num_layers, dropout=dropout)
self.dense = nn.Dense(vocab_size, flatten=False)
def init_state(self, enc_outputs, enc_valid_lens, *args):
# outputs的形状为(num_steps,batch_size,num_hiddens)
# hidden_state[0]的形状为(num_layers,batch_size,num_hiddens)
outputs, hidden_state = enc_outputs
return (outputs.swapaxes(0, 1), hidden_state, enc_valid_lens)
def forward(self, X, state):
# enc_outputs的形状为(batch_size,num_steps,num_hiddens).
# hidden_state[0]的形状为(num_layers,batch_size,
# num_hiddens)
enc_outputs, hidden_state, enc_valid_lens = state
# 输出X的形状为(num_steps,batch_size,embed_size)
X = self.embedding(X).swapaxes(0, 1)
outputs, self._attention_weights = [], []
for x in X:
# query的形状为(batch_size,1,num_hiddens)
query = np.expand_dims(hidden_state[0][-1], axis=1)
# context的形状为(batch_size,1,num_hiddens)
context = self.attention(
query, enc_outputs, enc_outputs, enc_valid_lens)
# 在特征维度上连结
x = np.concatenate((context, np.expand_dims(x, axis=1)), axis=-1)
# 将x变形为(1,batch_size,embed_size+num_hiddens)
out, hidden_state = self.rnn(x.swapaxes(0, 1), hidden_state)
outputs.append(out)
self._attention_weights.append(self.attention.attention_weights)
# 全连接层变换后,outputs的形状为
# (num_steps,batch_size,vocab_size)
outputs = self.dense(np.concatenate(outputs, axis=0))
return outputs.swapaxes(0, 1), [enc_outputs, hidden_state,
enc_valid_lens]
@property
def attention_weights(self):
return self._attention_weights接下来,使用包含7个时间步的4个序列输入的小批量测试Bahdanau注意力解码器。(参考注意力评分函数(掩蔽softmax操作,加性注意力,缩放点积注意力)_流萤数点的博客-CSDN博客加性注意力、掩蔽softmax部分)
#下一段代码用的到
#@save
def masked_softmax(X, valid_lens):
"""通过在最后一个轴上掩蔽元素来执行softmax操作"""
# X:3D张量,valid_lens:1D或2D张量
if valid_lens is None:
return npx.softmax(X)
else:
shape = X.shape
if valid_lens.ndim == 1:
valid_lens = valid_lens.repeat(shape[1])
else:
valid_lens = valid_lens.reshape(-1)
# 最后一轴上被掩蔽的元素使用一个非常大的负值替换,从而其softmax输出为0
X = npx.sequence_mask(X.reshape(-1, shape[-1]), valid_lens, True,
value=-1e6, axis=1)
return npx.softmax(X).reshape(shape)#@save
class AdditiveAttention(nn.Block):
"""加性注意力"""
def __init__(self, num_hiddens, dropout, **kwargs):
super(AdditiveAttention, self).__init__(**kwargs)
# 使用'flatten=False'只转换最后一个轴,以便其他轴的形状保持不变
self.W_k = nn.Dense(num_hiddens, use_bias=False, flatten=False)
self.W_q = nn.Dense(num_hiddens, use_bias=False, flatten=False)
self.w_v = nn.Dense(1, use_bias=False, flatten=False)
self.dropout = nn.Dropout(dropout)
def forward(self, queries, keys, values, valid_lens):
queries, keys = self.W_q(queries), self.W_k(keys)
# 在维度扩展后,
# queries的形状:(batch_size,查询的个数,1,num_hidden)
# key的形状:(batch_size,1,“键-值”对的个数,num_hiddens)
# 使用广播的方式进行求和
features = np.expand_dims(queries, axis=2) + np.expand_dims(
keys, axis=1)
features = np.tanh(features)
# self.w_v仅有一个输出,因此从形状中移除最后那个维度。
# scores的形状:(batch_size,查询的个数,“键-值”对的个数)
scores = np.squeeze(self.w_v(features), axis=-1)
self.attention_weights = masked_softmax(scores, valid_lens)
# values的形状:(batch_size,“键-值”对的个数,值的维度)
return npx.batch_dot(self.dropout(self.attention_weights), values)encoder = d2l.Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16,
num_layers=2)
encoder.initialize()
decoder = Seq2SeqAttentionDecoder(vocab_size=10, embed_size=8, num_hiddens=16,
num_layers=2)
decoder.initialize()
X = np.zeros((4, 7)) # (batch_size,num_steps)
state = decoder.init_state(encoder(X), None)
output, state = decoder(X, state)
output.shape, len(state), state[0].shape, len(state[1]), state[1][0].shape((4, 7, 10), 3, (4, 7, 16), 1, (2, 4, 16))
3.训练
我们在这里指定超参数,实例化一个带有Bahdanau注意力的编码器和解码器, 并对这个模型进行机器翻译训练。 由于新增的注意力机制,训练要比没有注意力机制的 序列到序列学习(seq2seq,BLEU)_流萤数点的博客-CSDN博客_序列到序列慢得多。库版本有点低,需要加入编码器、解码器、MaskedSoftmaxCELoss、train_seq2seq部分,才能运行成功。
#@save
class Seq2SeqEncoder(d2l.Encoder):
"""用于序列到序列学习的循环神经网络编码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqEncoder, self).__init__(**kwargs)
# 嵌入层
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = rnn.GRU(num_hiddens, num_layers, dropout=dropout)
def forward(self, X, *args):
# 输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X)
# 在循环神经网络模型中,第一个轴对应于时间步
X = X.swapaxes(0, 1)
state = self.rnn.begin_state(batch_size=X.shape[1], ctx=X.ctx)
output, state = self.rnn(X, state)
# output的形状:(num_steps,batch_size,num_hiddens)
# state的形状:(num_layers,batch_size,num_hiddens)
return output, stateencoder = Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16,
num_layers=2)
encoder.initialize()
X = np.zeros((4, 7))
output, state = encoder(X)
output.shapeclass Seq2SeqDecoder(d2l.Decoder):
"""用于序列到序列学习的循环神经网络解码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = rnn.GRU(num_hiddens, num_layers, dropout=dropout)
self.dense = nn.Dense(vocab_size, flatten=False)
def init_state(self, enc_outputs, *args):
return enc_outputs[1]
def forward(self, X, state):
# 输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X).swapaxes(0, 1)
# context的形状:(batch_size,num_hiddens)
context = state[0][-1]
# 广播context,使其具有与X相同的num_steps
context = np.broadcast_to(context, (
X.shape[0], context.shape[0], context.shape[1]))
X_and_context = np.concatenate((X, context), 2)
output, state = self.rnn(X_and_context, state)
output = self.dense(output).swapaxes(0, 1)
# output的形状:(batch_size,num_steps,vocab_size)
# state的形状:(num_layers,batch_size,num_hiddens)
return output, statedecoder = Seq2SeqDecoder(vocab_size=10, embed_size=8, num_hiddens=16,
num_layers=2)
decoder.initialize()
state = decoder.init_state(encoder(X))
output, state = decoder(X, state)
output.shape, len(state), state[0].shape#@save
class MaskedSoftmaxCELoss(gluon.loss.SoftmaxCELoss):
"""带遮蔽的softmax交叉熵损失函数"""
# pred的形状:(batch_size,num_steps,vocab_size)
# label的形状:(batch_size,num_steps)
# valid_len的形状:(batch_size,)
def forward(self, pred, label, valid_len):
# weights的形状:(batch_size,num_steps,1)
weights = np.expand_dims(np.ones_like(label), axis=-1)
weights = npx.sequence_mask(weights, valid_len, True, axis=1)
return super(MaskedSoftmaxCELoss, self).forward(pred, label, weights)loss = MaskedSoftmaxCELoss()
loss(np.ones((3, 4, 10)), np.ones((3, 4)), np.array([4, 2, 0]))
#加入这段,dl库里面没有
#@save
def train_seq2seq(net, data_iter, lr, num_epochs, tgt_vocab, device):
"""训练序列到序列模型"""
net.initialize(init.Xavier(), force_reinit=True, ctx=device)
trainer = gluon.Trainer(net.collect_params(), 'adam',
{'learning_rate': lr})
loss = MaskedSoftmaxCELoss()
animator = d2l.Animator(xlabel='epoch', ylabel='loss',
xlim=[10, num_epochs])
for epoch in range(num_epochs):
timer = d2l.Timer()
metric = d2l.Accumulator(2) # 训练损失求和,词元数量
for batch in data_iter:
X, X_valid_len, Y, Y_valid_len = [
x.as_in_ctx(device) for x in batch]
bos = np.array([tgt_vocab['<bos>']] * Y.shape[0],
ctx=device).reshape(-1, 1)
dec_input = np.concatenate([bos, Y[:, :-1]], 1) # 强制教学
with autograd.record():
Y_hat, _ = net(X, dec_input, X_valid_len)
l = loss(Y_hat, Y, Y_valid_len)
l.backward()
d2l.grad_clipping(net, 1)
num_tokens = Y_valid_len.sum()
trainer.step(num_tokens)
metric.add(l.sum(), num_tokens)
if (epoch + 1) % 10 == 0:
animator.add(epoch + 1, (metric[0] / metric[1],))
print(f'loss {metric[0] / metric[1]:.3f}, {metric[1] / timer.stop():.1f} '
f'tokens/sec on {str(device)}')embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 250, d2l.try_gpu()
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = Seq2SeqEncoder(
len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqAttentionDecoder(
len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device) #做了修改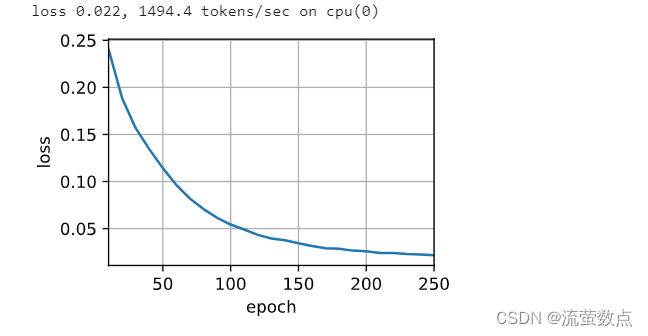
模型训练后,我们用它将几个英语句子翻译成法语并计算它们的BLEU分数。dl库里面没有predict_seq2seq,需要加进去。
#@save
def predict_seq2seq(net, src_sentence, src_vocab, tgt_vocab, num_steps,
device, save_attention_weights=False):
"""序列到序列模型的预测"""
src_tokens = src_vocab[src_sentence.lower().split(' ')] + [
src_vocab['<eos>']]
enc_valid_len = np.array([len(src_tokens)], ctx=device)
src_tokens = d2l.truncate_pad(src_tokens, num_steps, src_vocab['<pad>'])
# 添加批量轴
enc_X = np.expand_dims(np.array(src_tokens, ctx=device), axis=0)
enc_outputs = net.encoder(enc_X, enc_valid_len)
dec_state = net.decoder.init_state(enc_outputs, enc_valid_len)
# 添加批量轴
dec_X = np.expand_dims(np.array([tgt_vocab['<bos>']], ctx=device),
axis=0)
output_seq, attention_weight_seq = [], []
for _ in range(num_steps):
Y, dec_state = net.decoder(dec_X, dec_state)
# 我们使用具有预测最高可能性的词元,作为解码器在下一时间步的输入
dec_X = Y.argmax(axis=2)
pred = dec_X.squeeze(axis=0).astype('int32').item()
# 保存注意力权重(稍后讨论)
if save_attention_weights:
attention_weight_seq.append(net.decoder.attention_weights)
# 一旦序列结束词元被预测,输出序列的生成就完成了
if pred == tgt_vocab['<eos>']:
break
output_seq.append(pred)
return ' '.join(tgt_vocab.to_tokens(output_seq)), attention_weight_seqengs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):
translation, dec_attention_weight_seq = predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps, device, True)
print(f'{eng} => {translation}, ',
f'bleu {d2l.bleu(translation, fra, k=2):.3f}')go . => va !, bleu 1.000 i lost . => j’ai gagné ., bleu 0.000 he's calm . => il est mouillé ., bleu 0.658 i'm home . => je suis chez moi ., bleu 1.000
attention_weights = np.concatenate([step[0][0][0] for step in dec_attention_weight_seq], 0
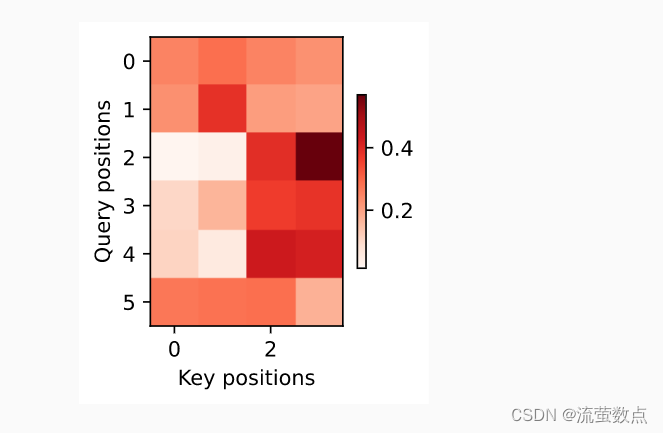
).reshape((1, 1, -1, num_steps))训练结束后,下面通过可视化注意力权重 会发现,每个查询都会在键值对上分配不同的权重,这说明 在每个解码步中,输入序列的不同部分被选择性地聚集在注意力池中。
#@save
def show_heatmaps(matrices, xlabel, ylabel, titles=None, figsize=(2.5, 2.5),
cmap='Reds'):
"""显示矩阵热图"""
d2l.use_svg_display()
num_rows, num_cols = matrices.shape[0], matrices.shape[1]
fig, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize,
sharex=True, sharey=True, squeeze=False)
for i, (row_axes, row_matrices) in enumerate(zip(axes, matrices)):
for j, (ax, matrix) in enumerate(zip(row_axes, row_matrices)):
pcm = ax.imshow(matrix.asnumpy(), cmap=cmap)
if i == num_rows - 1:
ax.set_xlabel(xlabel)
if j == 0:
ax.set_ylabel(ylabel)
if titles:
ax.set_title(titles[j])
fig.colorbar(pcm, ax=axes, shrink=0.6);# 加上一个包含序列结束词元
show_heatmaps(
attention_weights[:, :, :, :len(engs[-1].split()) + 1],
xlabel='Key positions', ylabel='Query positions')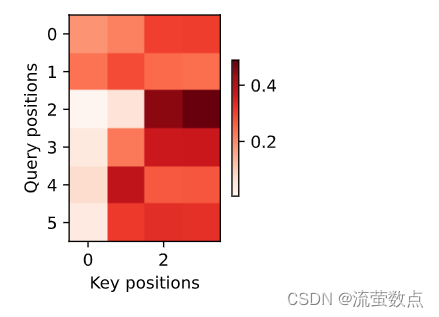
和书上的略有不同,书上这样的: