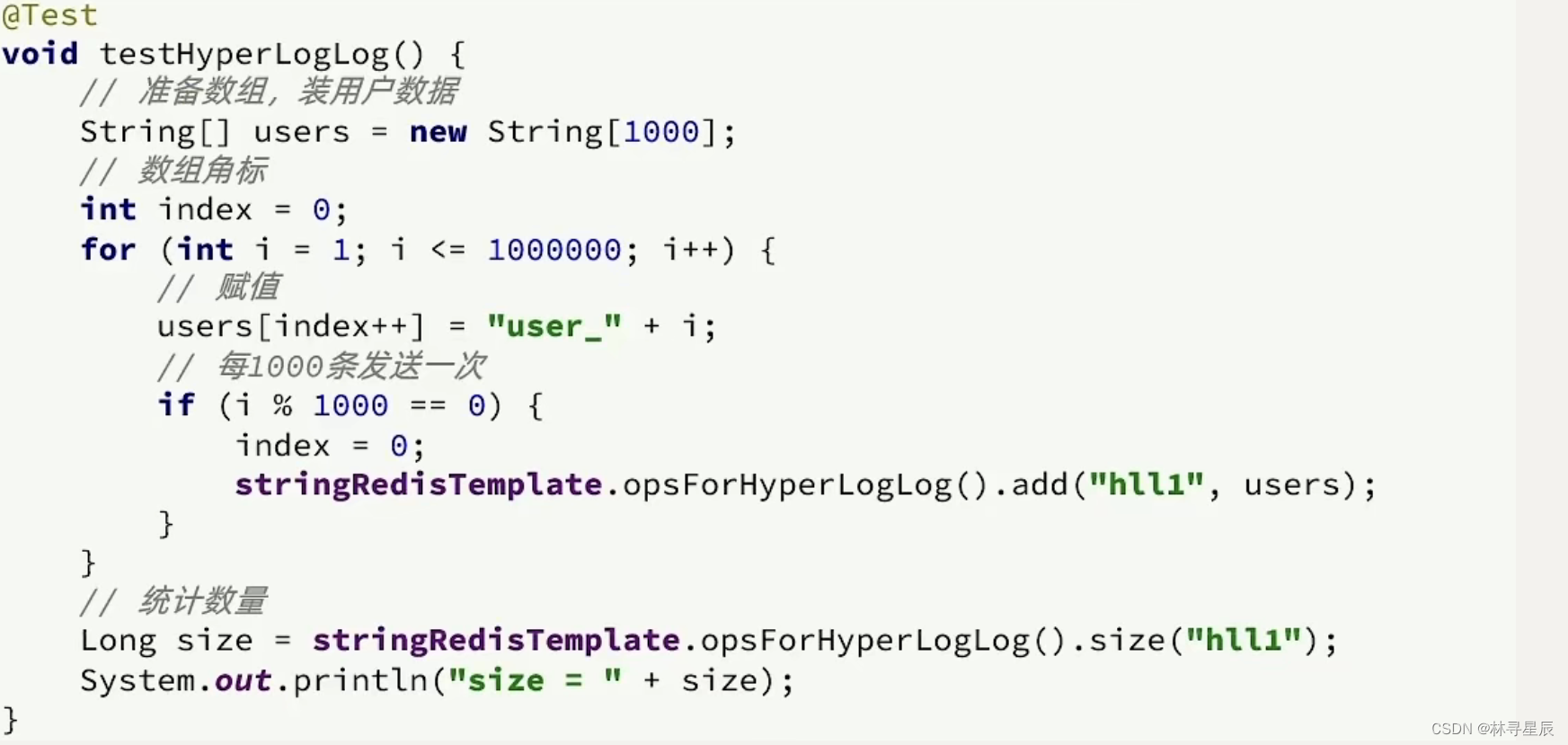
cap理论
- Consistency(一致性)
- Availability(可用性)
- Partition tolerance(分区容忍性)
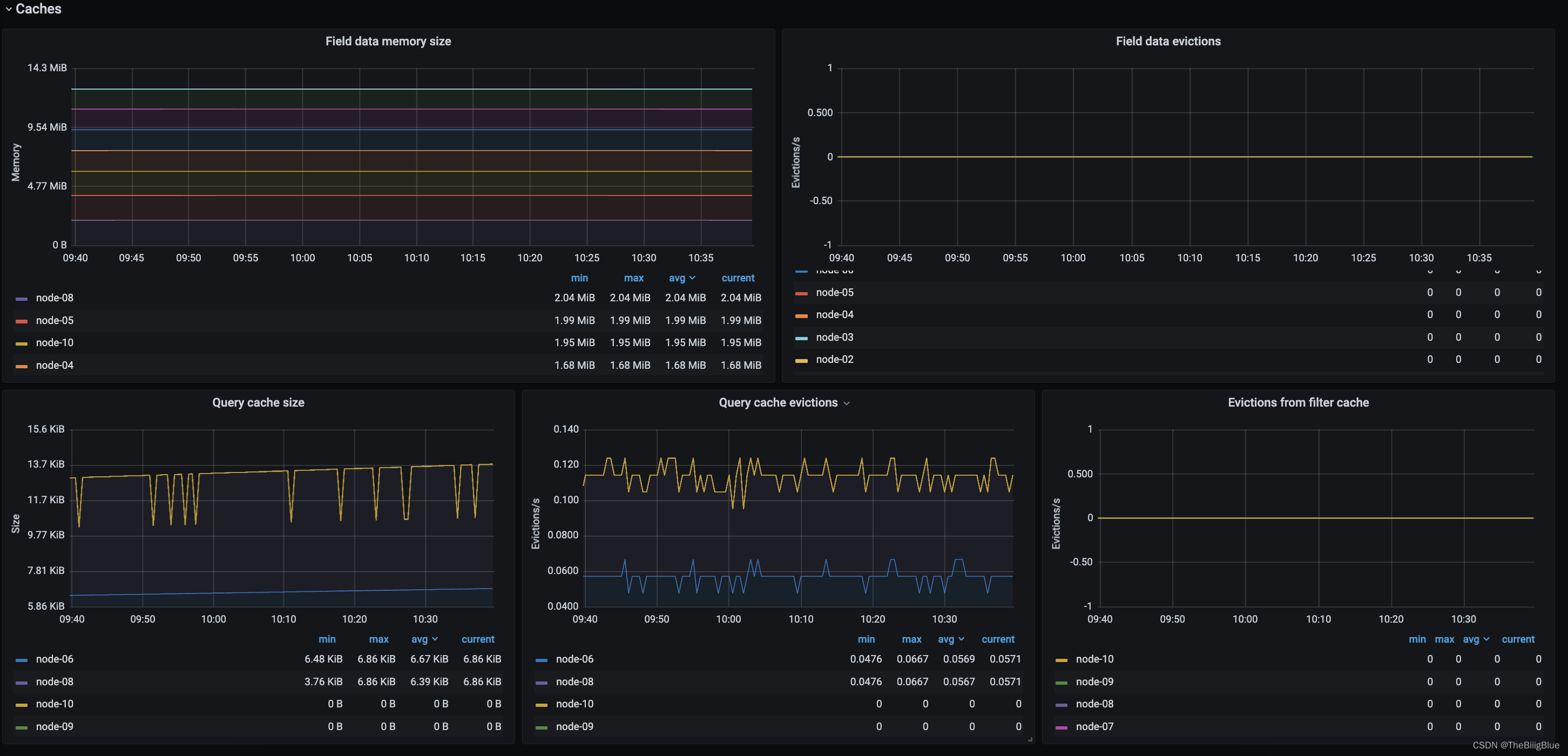
①一致性:对于客户端的每次读操作,要么读到的是最新的数据,要么读取失败。换句话说,一致性是站在分布式系统的角度,对访问本系统的客户端的一种承诺:要么我给您返回一个错误,要么我给你返回绝对一致的最新数据,不难看出,其强调的是数据正确。
②可用性:任何客户端的请求都能得到响应数据,不会出现响应错误。换句话说,可用性是站在分布式系统的角度,对访问本系统的客户的另一种承诺:我一定会给您返回数据,不会给你返回错误,但不保证数据最新,强调的是不出错。
③分区容忍性:由于分布式系统通过网络进行通信,网络是不可靠的。当任意数量的消息丢失或延迟到达时,系统仍会继续提供服务,不会挂掉。换句话说,分区容忍性是站在分布式系统的角度,对访问本系统的客户端的再一种承诺:我会一直运行,不管我的内部出现何种数据同步问题,强调的是不挂掉。
note:其实这里有个关于CAP理论理解的误区。不要以为在所有时候都只能选择两个特性。在不存在网络失败的情况下(分布式系统正常运行时),C和A能够同时保证。只有当网络发生分区或失败时,才会在C和A之间做出选择。
对于一个分布式系统而言,P是前提,必须保证,因为只要有网络交互就一定会有延迟和数据丢失,这种状况我们必须接受,必须保证系统不能挂掉。所以只剩下C、A可以选择。要么保证数据一致性(保证数据绝对正确),要么保证可用性(保证系统不出错)。
当选择了C(一致性)时,如果由于网络分区而无法保证特定信息是最新的,则系统将返回错误或超时。
当选择了A(可用性)时,系统将始终处理客户端的查询并尝试返回最新的可用的信息版本,即使由于网络分区而无法保证其是最新的
轻松理解CAP理论 - 知乎
name server选择ap ,如何实现一致性?
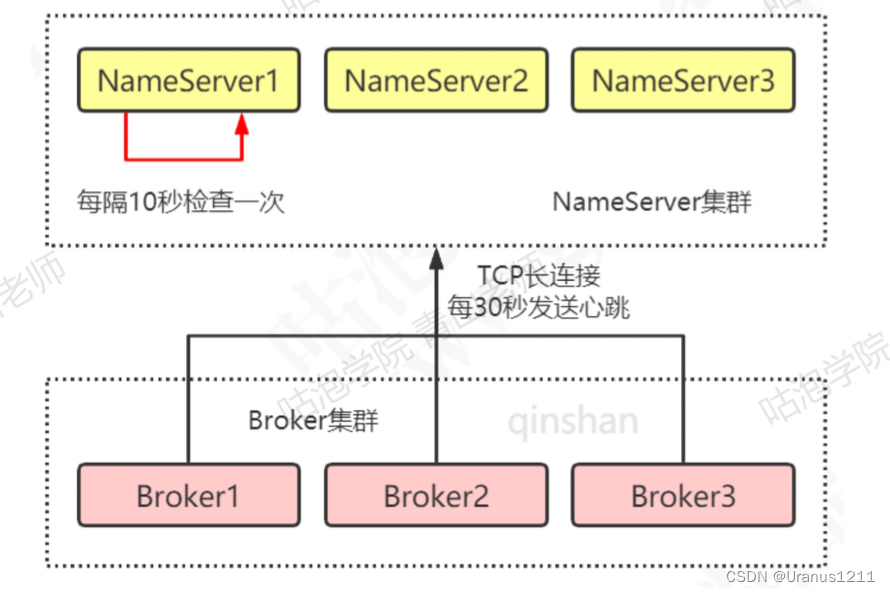
1.服务注册
broke 每隔30s发送心跳包
2.服务剔除
broke挂了:
正常:连接断开,netty通道监听器会监听到连接断开,然后将该broke剔除
异常:name server定时任务每隔10s扫描broke列表,如果broke心跳包最新时间戳超过120s,就会被移除
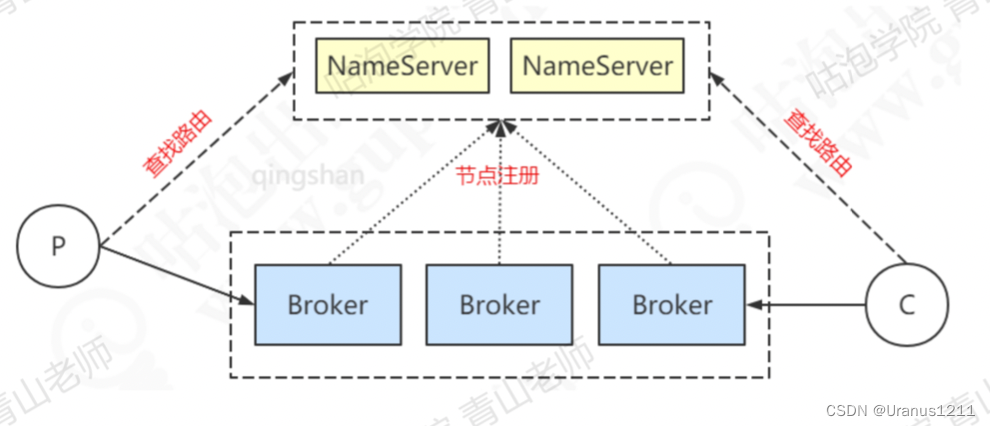
3.路由发现
生产者:第一条消息,根据topic 从ns中获取路由信息
消费者:订阅固定topic,启动的时候获取broke信息
broke更新(增加/减少节点),如何获取最新的broke列表?
ns不会主动推送信息给客户端,客户端也不会发送心跳包给ns,所以建立连接后需要P和C定期更新
生产者 消费者 定时任务 定时更新路由信息 30s
如果broke刚挂 要等30s吗?
1.重试
2.把无法连接的broke隔绝掉,不再连接
3.优先选择延迟小的节点,避免连接到容易挂的broke
如果ns挂掉呢?
客户端要缓存broker信息, 不能完全依赖ns
producer 生产者
定时从ns拉取路由信息,根据路由信息与指定broker建立tcp长连接,将消息发送到broker中
支持批量发送
写数据只能操作master节点
consumer 消费者
通过ns集群获得topic的路由信息,连接到对应的broker消费
master和slave都可以读消息,所以消费者和m,s都建立连接
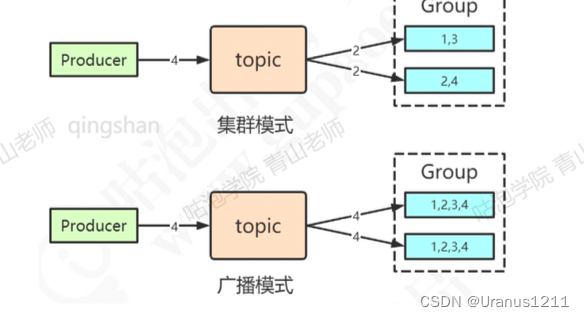
消费者有两种消费模式:集群消费(消息轮询),广播消费(全部收到相同副本)
消费模型:pull 和push 两种模式
pull模式是消费者轮询从broker 拉取消息
pull两种实现方式
1.普通轮询polling
不管服务端数据有无更新 客户端每隔定长时间请求拉取一次数据
缺点:大部分时间没有数据,无效请求浪费服务端资源;定时请求间隔过长,会导致消息延迟
2.rocketmq 的长轮询 long polling