向导
- 介绍
- 部署
- Prometheus
- 配置
- Grafana
- 下载仪表盘
- 导入仪表盘
- 报警
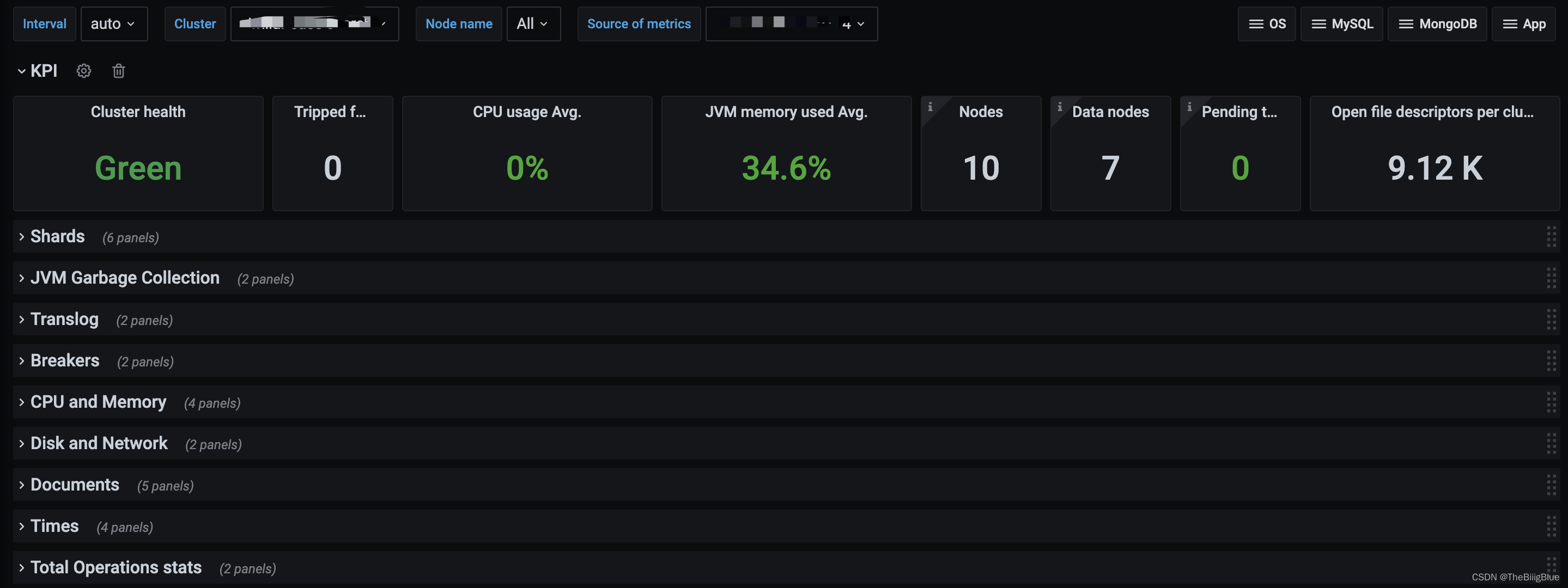
- 核心指标
- 集群健康和节点可用性
- 主机级别的系统和网络指标
- JVM内存和垃圾回收
- 搜索和索引性能
- 资源饱和度
- 注册自动重启
介绍
Prometheus官方提供了ES的exporter:EsExporter

Github地址:elasticsearch_exporter
部署
- 下载压缩包
- 上传服务器,解压
- 启动
nohup ./elasticsearch_exporter --es.uri http://xx.x.xx.xx:9200 --es.all > ./logs 2>&1 &
## 参数说明:
--es.uri 默认http://localhost:9200,连接到的Elasticsearch节点的地址(主机和端口)。 这可以是本地节点(例如localhost:9200),也可以是远程Elasticsearch服务器的地址
--es.all 默认flase,如果为true,则查询群集中所有节点的统计信息,而不仅仅是查询我们连接到的节点。
--es.cluster_settings 默认flase,如果为true,请在统计信息中查询集群设置
--es.indices 默认flase,如果为true,则查询统计信息以获取集群中的所有索引。
--es.indices_settings 默认flase,如果为true,则查询集群中所有索引的设置统计信息。
--es.shards 默认flase,如果为true,则查询集群中所有索引的统计信息,包括分片级统计信息(意味着es.indices = true)。
--es.snapshots 默认flase,如果为true,则查询集群快照的统计信息。
- 启动成功后,可以访问 http://xx.xx.xxx.xx:9114/metrics/ ,看抓取的指标信息:
Prometheus
配置
- 修改prometheus组件的prometheus.yml加入elasticsearch节点(targets即是上面机器的连接信息):

- 重启prometheus服务:
sudo systemctl restart prometheus-9090.service
该命令需提前注册系统服务:
cat /etc/systemd/system/prometheus-9090.service
[Unit]
Description=prometheus service
After=syslog.target network.target remote-fs.target nss-lookup.target
[Service]
LimitNOFILE=1000000
LimitSTACK=10485760
User=tidb
ExecStart=/bin/bash -c '/data/tidb-deploy/prometheus-8249/scripts/run_prometheus.sh'
ExecReload=/bin/bash -c 'kill -HUP $MAINPID $(pidof /data/tidb-deploy/prometheus-8249/bin/ng-monitoring-server)'
Restart=always
RestartSec=15s
[Install]
WantedBy=multi-user.target
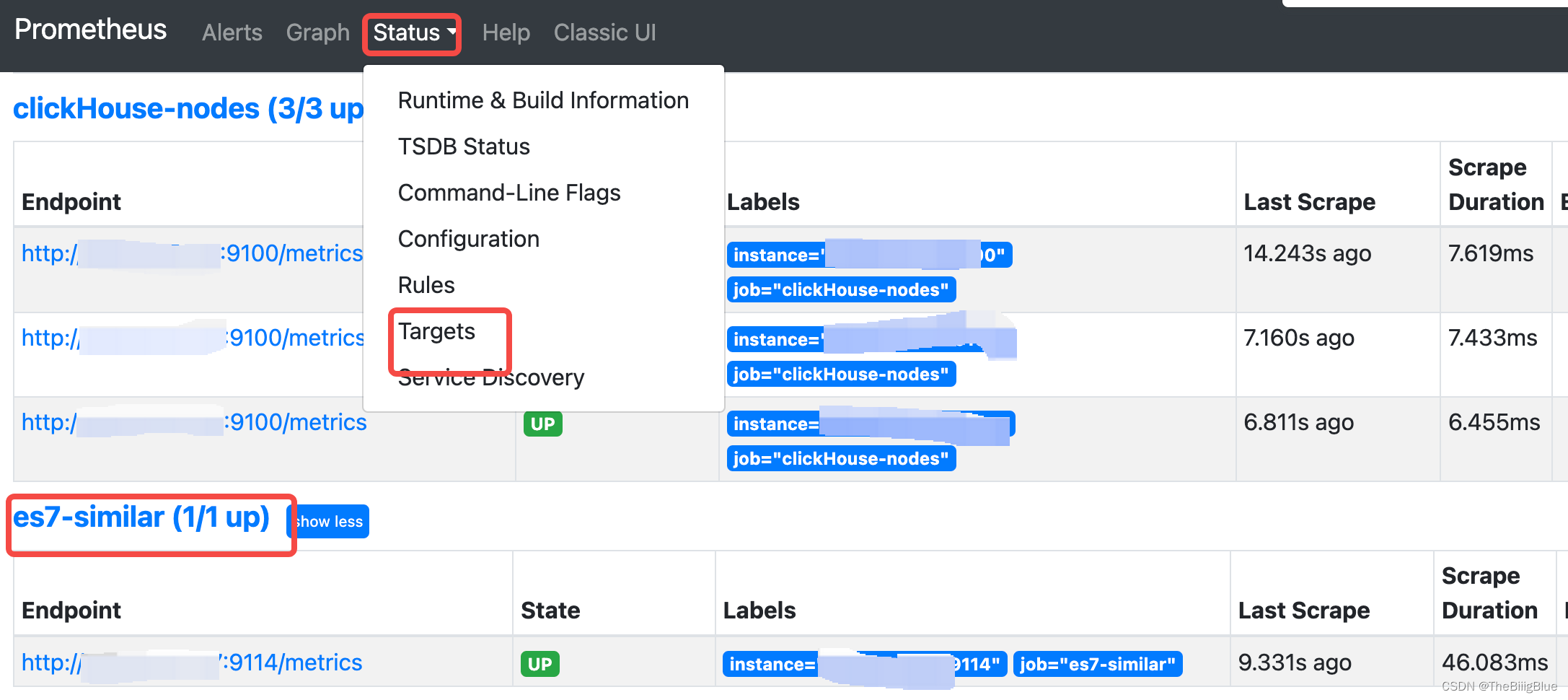
- prometheus服务中验证, 注:State=UP,说明成功:
Grafana
下载仪表盘
下载地址:https://grafana.com/grafana/dashboards/2322
导入仪表盘
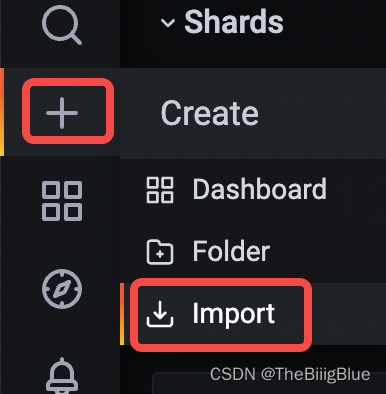
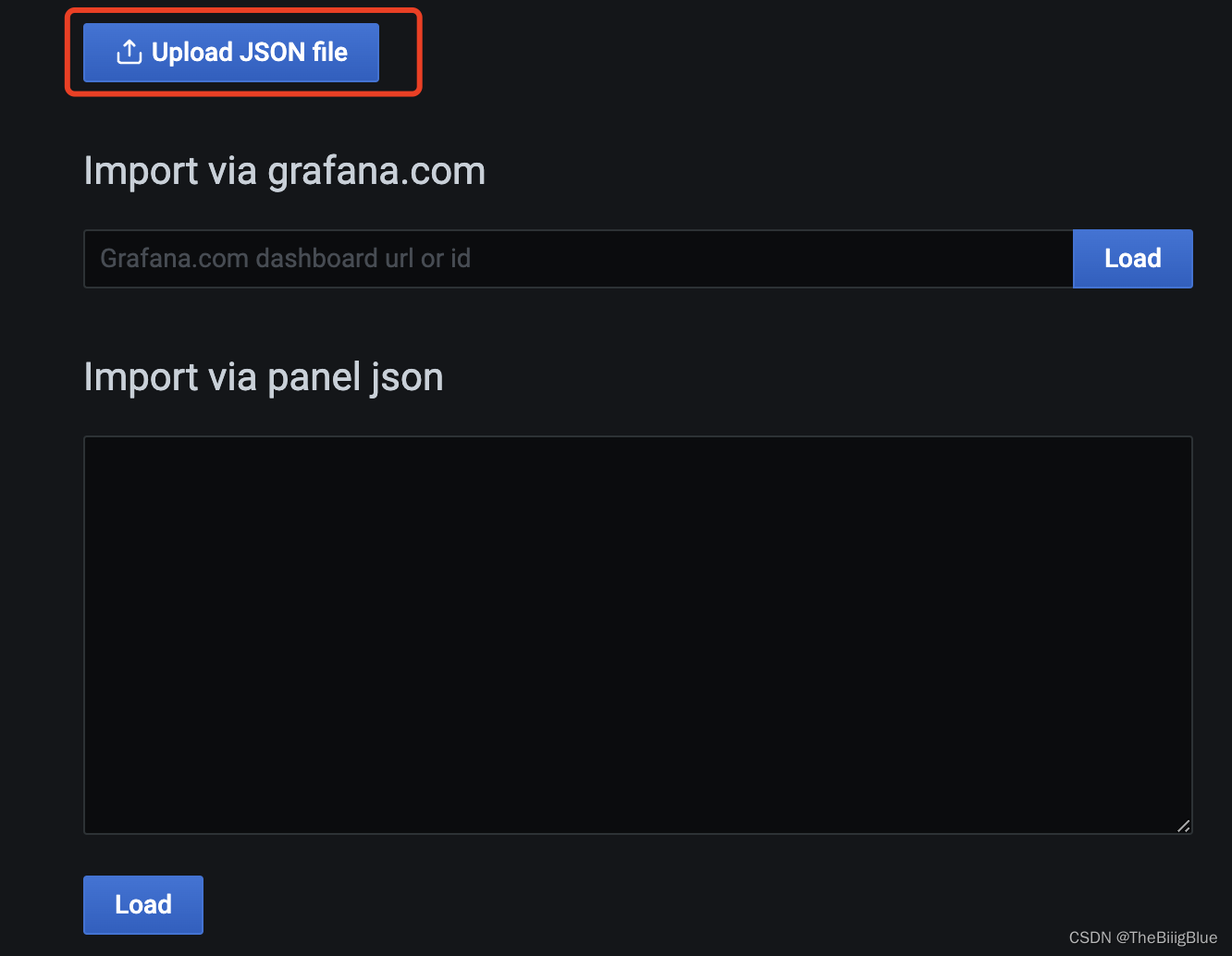
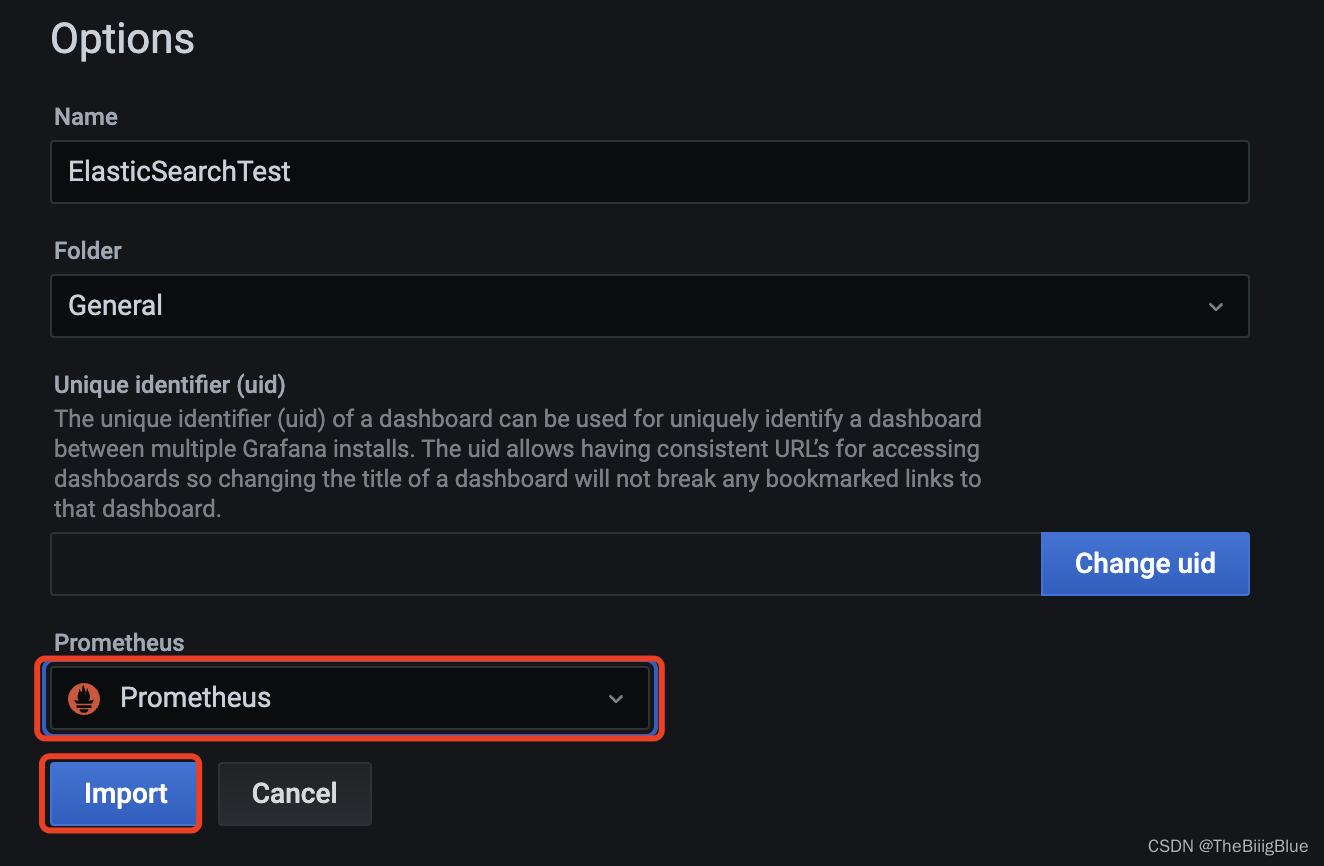
报警
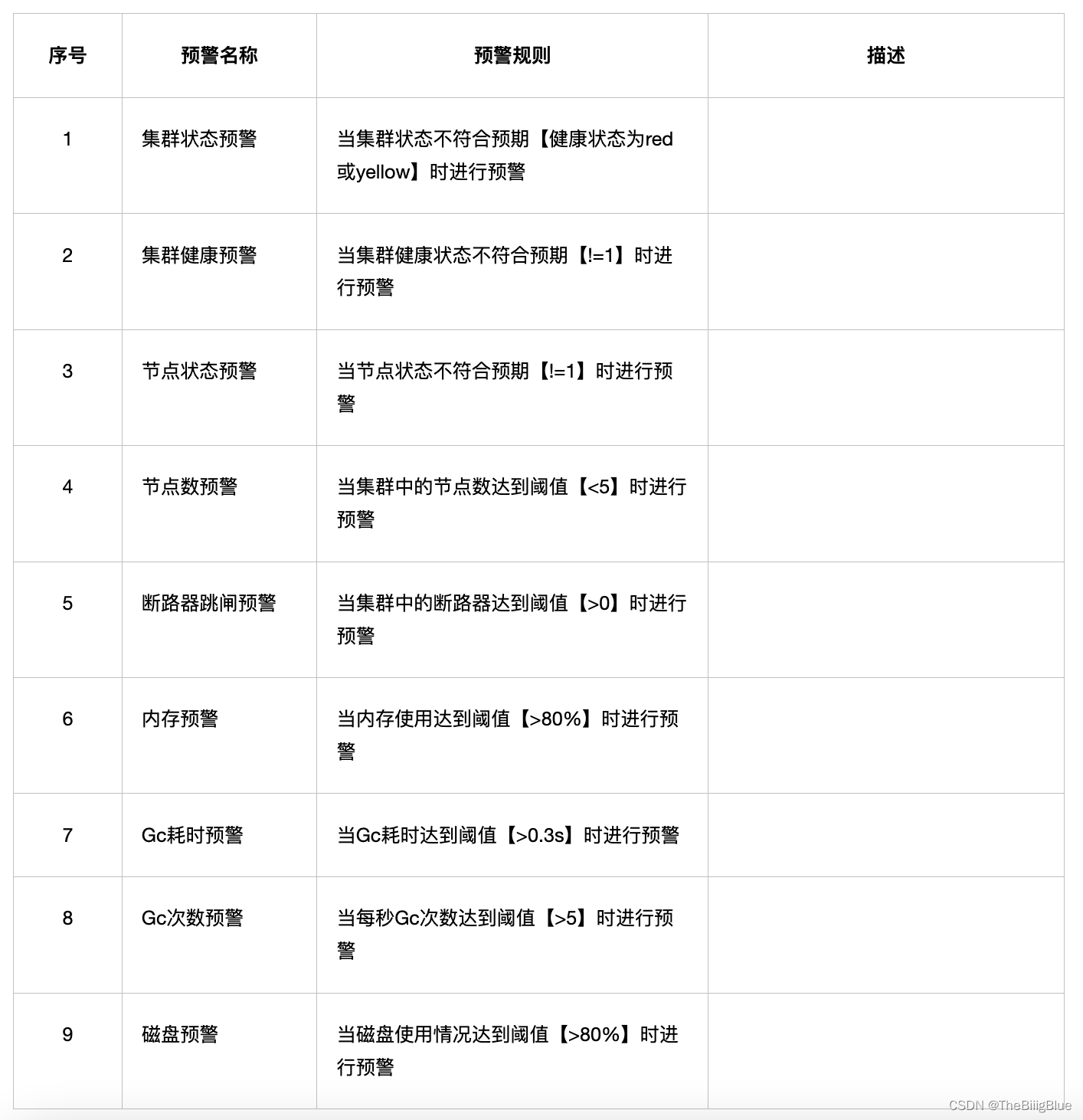
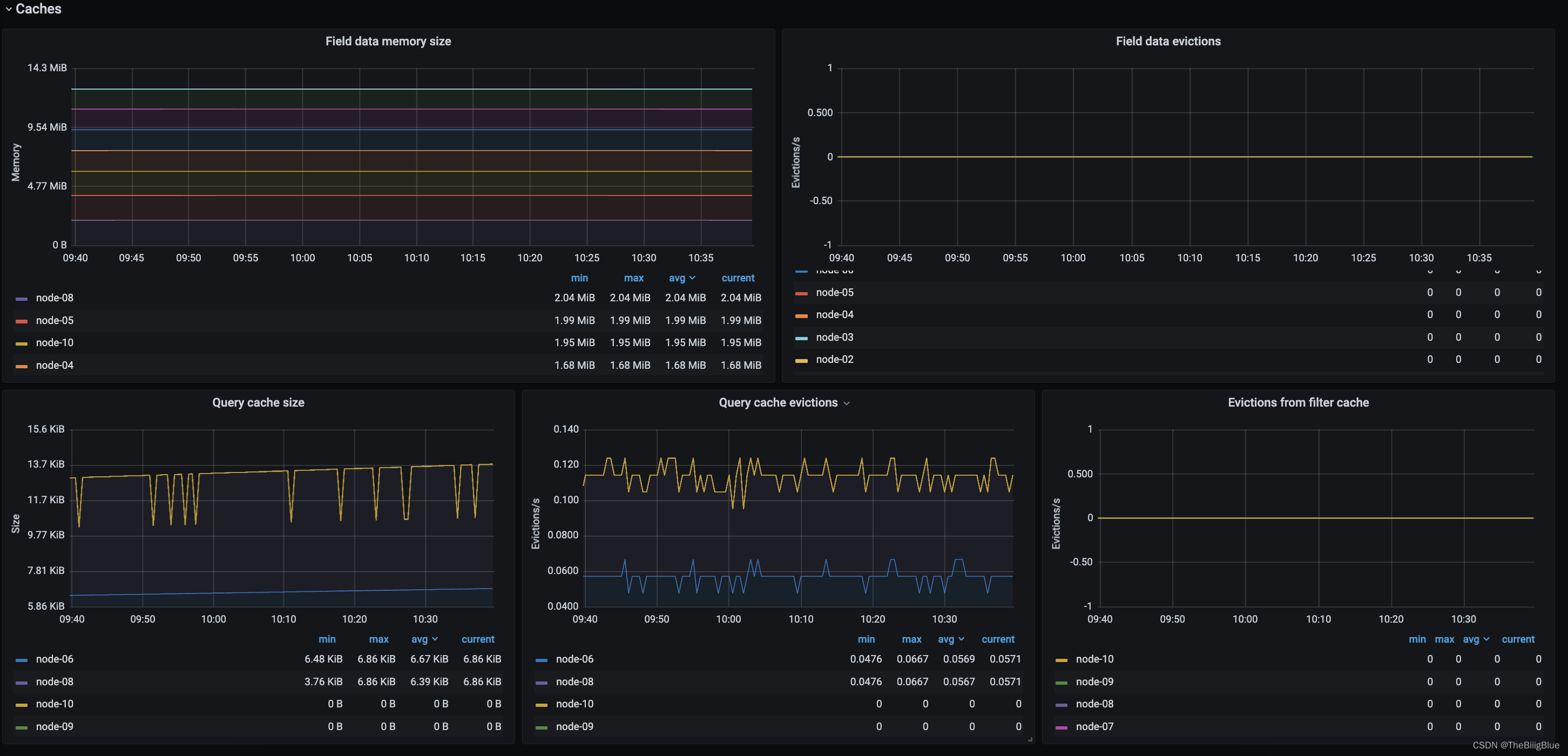
核心指标
集群健康和节点可用性
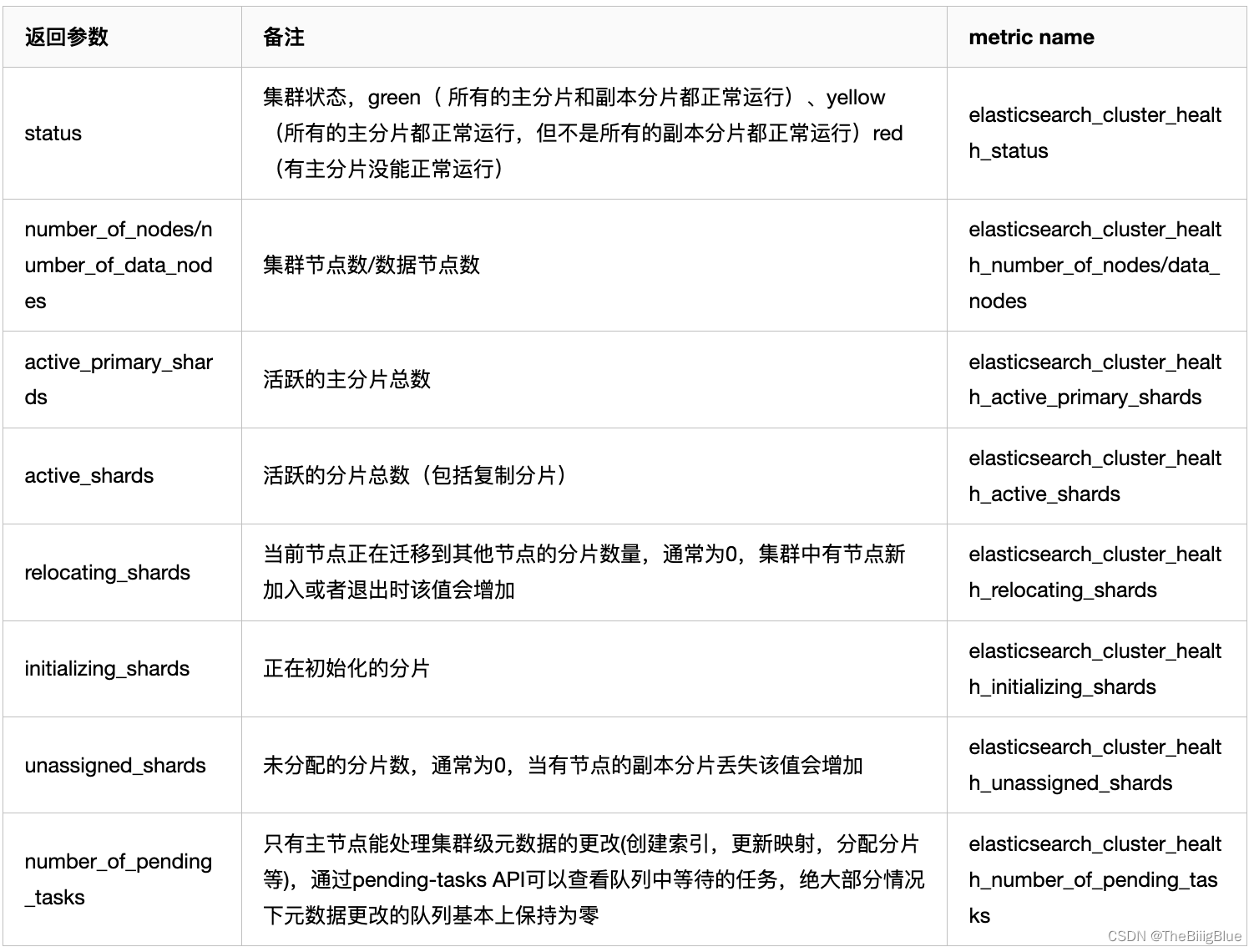
通过cluster healthAPI可以获取集群的健康状况,可以把集群的健康状态当做是集群平稳运行的重要信号,一旦状态发生变化则需要引起重视;API返回的一些重要参数指标及对应的prometheus监控项如下:
主机级别的系统和网络指标
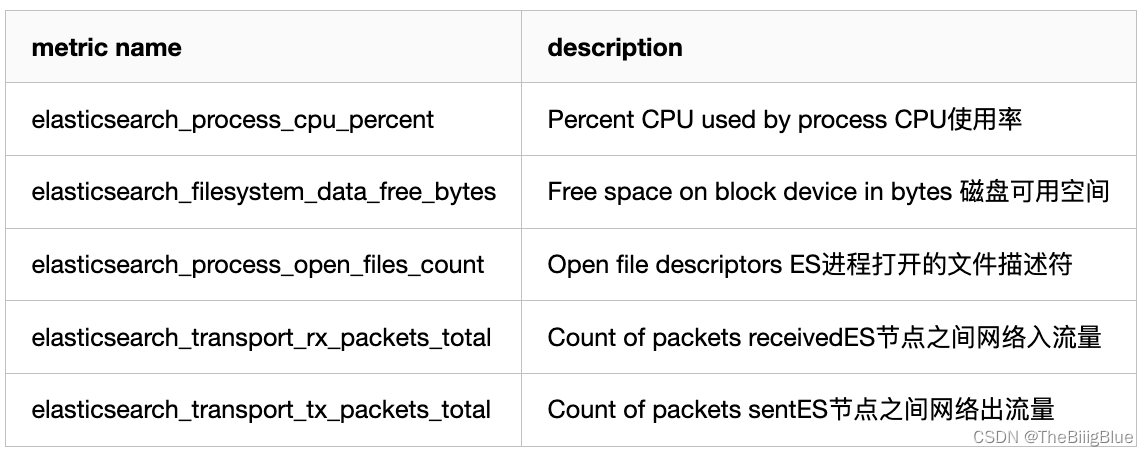
如果CPU使用率持续增长,通常是由于大量的搜索或索引工作造成的负载。可能需要添加更多的节点来重新分配负载。
文件描述符用于节点间的通信、客户端连接和文件操作。如果打开的文件描述符达到系统的限制(一般Linux运行每个进程有1024个文件描述符,生产环境建议调大65535),新的连接和文件操作将不可用,直到有旧的被关闭。
如果ES集群是写负载型,建议使用SSD盘,需要重点关注磁盘空间使用情况。当segment被创建、查询和合并时,Elasticsearch会进行大量的磁盘读写操作。
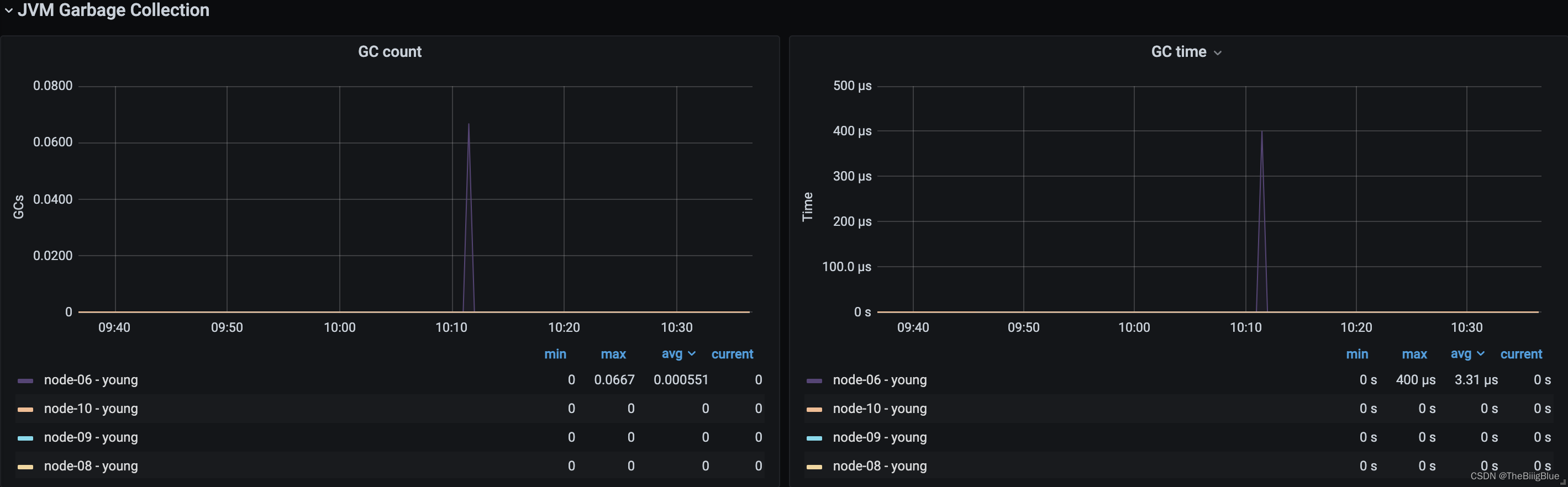
JVM内存和垃圾回收

主要关注JVM Heap 占用的内存以及JVM GC 所占的时间比例,定位是否有 GC 问题。Elasticsearch依靠垃圾回收来释放堆栈内存,默认当JVM堆栈使用率达到75%的时候启动垃圾回收,添加堆栈设置告警可以判断当前垃圾回收的速度是否比产生速度快,若不能满足需求,可以调整堆栈大小或者增加节点。
搜索和索引性能
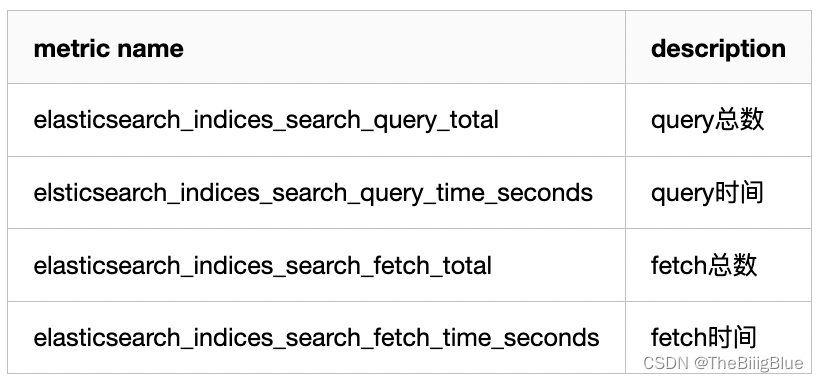
搜索部分:
索引部分:
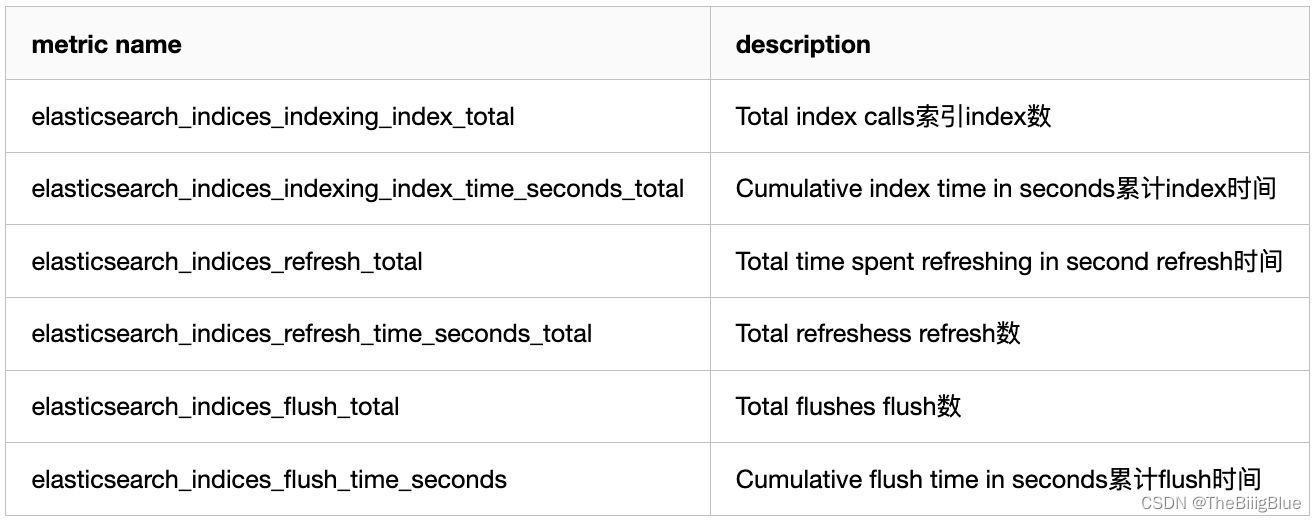
将时间和操作数画在同一张图上,左边y轴显示时间,右边y轴显示对应操作计数,ops/time查看平均操作耗时判断性能是否异常。通过计算获取平均索引延迟,如果延迟不断增大,可能是一次性bulk了太多的文档。
Elasticsearch通过flush操作将数据持久化到磁盘,如果flush延迟不断增大,可能是磁盘IO能力不足,如果持续下去最终将导致无法索引数据。
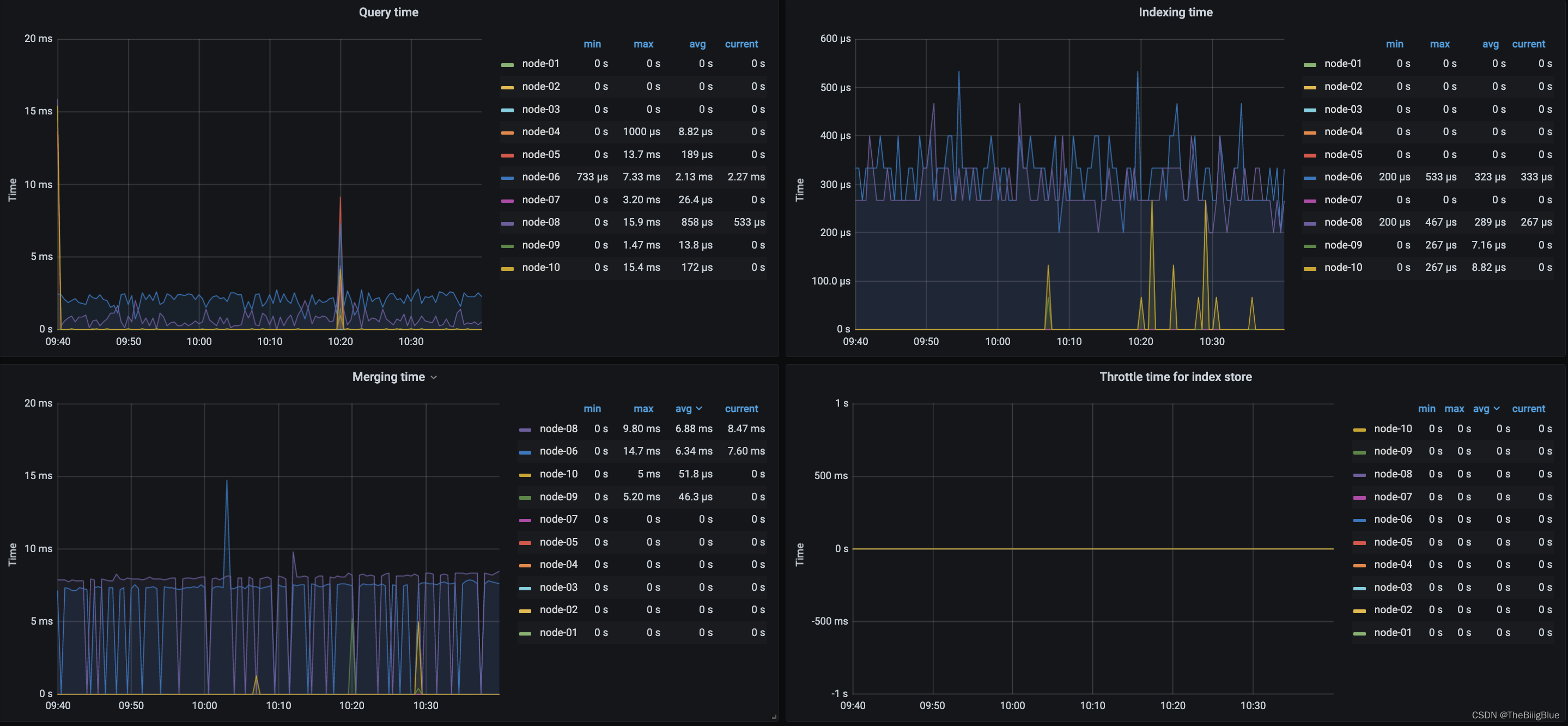
资源饱和度
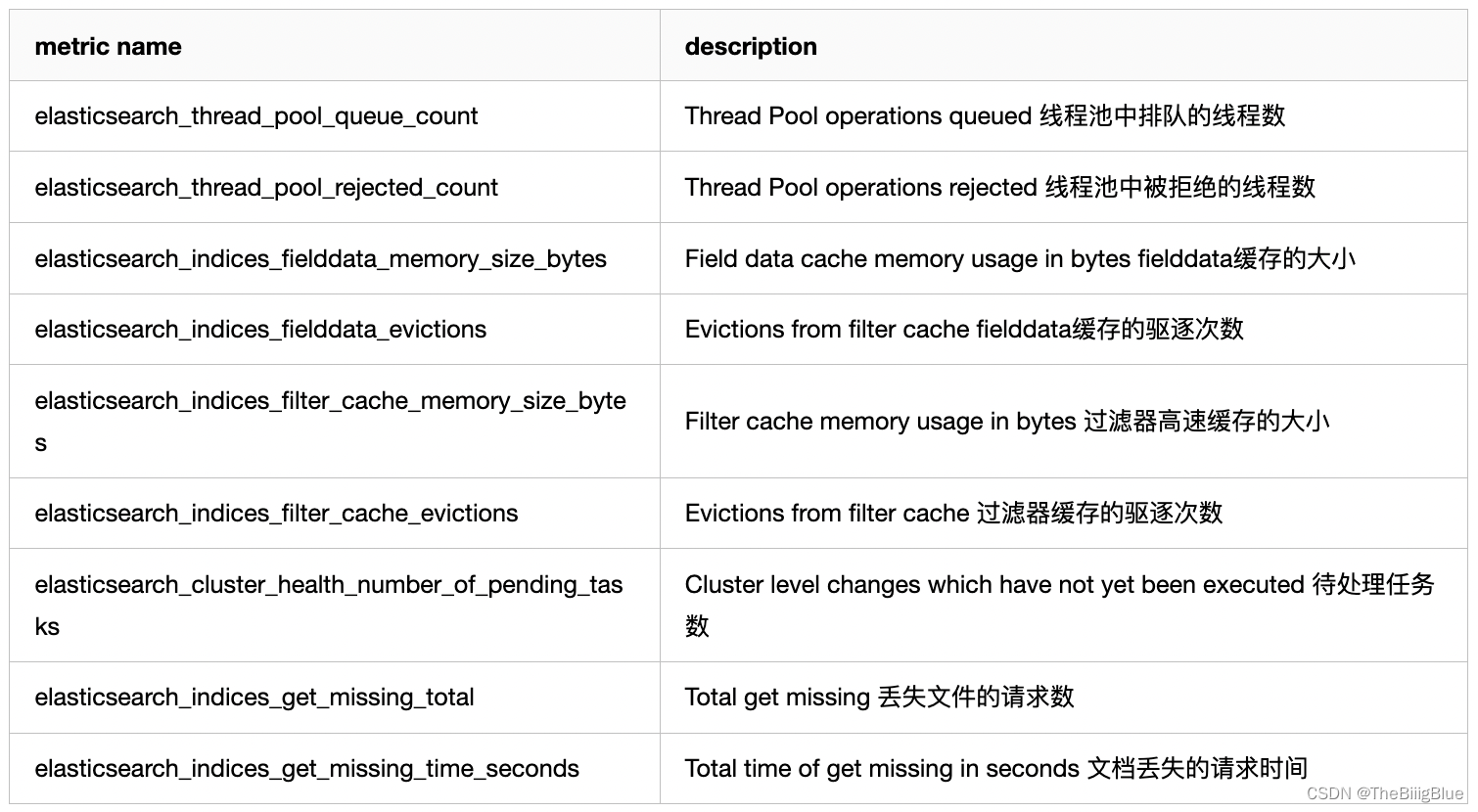
通过采集以上指标配置视图,Elasticsearch节点使用线程池来管理线程对内存和CPU使用。可以通过请求队列和请求被拒绝的情况,来确定节点是否够用。
每个Elasticsearch节点都维护着很多类型的线程池。一般来讲,最重要的几个线程池是搜索(search),索引(index),合并(merger)和批处理(bulk)。
每个线程池队列的大小代表着当前节点有多少请求正在等待服务。一旦线程池达到最大队列大小(不同类型的线程池的默认值不一样),后面的请求都会被线程池拒绝。
注册自动重启
注册为系统服务开机自动启动:
## 准备配置文件
cat <<\EOF >/etc/systemd/system/elasticsearch_exporter.service
[Unit]
Description=Elasticsearch stats exporter for Prometheus
Documentation=Prometheus exporter for various metrics about ElasticSearch, written in Go.
[Service]
User=hadoop
ExecStart=/data/services/elasticsearch_exporter-1.4/elasticsearch_exporter --es.uri http://xxx.xx.xx.xx:9200 --es.all
ExecReload=/bin/bash -c 'kill -HUP $MAINPID $(pidof /data/services/elasticsearch_exporter-1.4/elasticsearch_exporter)'
Restart=always
RestartSec=15s
[Install]
WantedBy=multi-user.target
EOF
## 启动并设置为开机自动启动
systemctl daemon-reload
systemctl enable elasticsearch_exporter.service
systemctl stop elasticsearch_exporter.service
systemctl start elasticsearch_exporter.service
systemctl status elasticsearch_exporter.service